
赛题:基于遥感影像和用户行为的城市区域功能分类 (解析)
网址:https://dianshi.baidu.com/competition/30/rank
初赛:第一
复赛:第二
决赛:并列第一
github: https://github.com/zhuqunxi/Urban-Region-Function-Classification
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
感受
第一次参加这么大型还有奖金的比赛,有点感想哈。作为一名应用数学专业(学的贼烂T﹏T)的3年级直博生(马上4年级了,老了),最近陷入了学术的针扎中,心中的滋味也就自己能体会。偶然间,不知是从哪里,发现了这个比赛,看着标题和奖金感觉挺有吸引力的。仔细想了想,要不去玩一玩,算是排解下压力,转移下注意力吧。这次比赛,当然要感谢队友华师大NLP周杰(一个热爱在知乎回答问题和github上开源的的少年),以及开源baseline_1, baseline_2的大佬们,以及赛事主办方联合国教科文组织国际工程科技知识中心(IKCEST)、中国工程科技知识中心(CKCEST)、百度公司及西安交通大学的大力支持。最后也祝贺各个进决赛的队伍,希望能从你们那学到点东西。
初赛和复赛
由于我发现这个比赛的时候已经是5月底6月初了,比赛好像已经过去一半时间(4月30日开始)。这时候,网上已经有两个baseline了,我也就拿着baseline的代码开始跑分了,发现当时好像什么都不改,大概能进前50。不过之后就发现,baseline的访问数据的特征都是统计上的特征,没有用户在时间轴上的特征,后来就加了点这放面的特征,分数也就上去了点,当时排名应该在25左右了。 由于自己经验毕竟不足,知道自己一个人单挑,即使进了复赛,也没法搞的。然后就找了我的一个同学,就是上面说的NLP大佬周杰。那时已经6月10日了,离复赛结束应该也就半个月了。后面我们就不断的在想,为什么第一名(植物大佬,原谅我是小白,后来才在群里听说的)的分数和后面的人的分数差那么多呢,难道有什么大家没发现的特征么。后来,我们就发现了同一个用户可以出现在不同的地区。随后,我们就开始了一连串的这方面的特征提取,最后在初赛截至的时候超到了第一。
到了复赛,我们花了10天左右的时间,把初赛用到的特征都提取完了,之后也加了点其余的特征,这里我们把初赛的4万数据也加进去了,一共44w数据。后来我们也简单试了试给测试集打标签,然后重新提取特征,发现也能上分,但是不是很高。所以我们偷懒了,提取特征太费时间废精力了。 也就是说10号左右的时候,我们已经罢工了。
细节
我们分别得到下面的5-fold的训练和测试集的概率特征
1. 图像特征(5-fold, Dense 121, 线下准确率:0.566375)
利用imagenet的预训练模型densenet121进行微调
2. 访问数据7*26*24特征 (5-fold, DPN, 线下准确率:0.643914)
利用无预训练的dpn26网络
3. 访问地区用户特征 + 访问用户夸地区特征 (5-flod, LightGBM, 线下准确率:0.905048)
至于第3个特征,下面详细捋一捋, 我们考虑的时间段主要是
1)节假日 -- 国庆,元旦,过年, 双十一等,具体细分

2)工作日 -- 周一到周五
3)休息日 -- 周六周日
4)0点-8点, 8点-18点, 18点-24点
访问地区用户特征(basic 特征)
给定一个地区的访问数据,我们提取该地区不同时间段的统计特征(包括 sum, mean, std, max, min, 分位数25,50, 75这8个统计量)
不区分用户的特征:24小时,24小时相邻小时人数比值,节假日,工作日,休息日,等等
区分用户的特征:1) 一天中,最早几点出现,最晚几点出现,最晚 减去 最早, 一天中相邻的最大间隔小时数。 2)沿着天数的,每个小时的统计特征。 等等
由于初赛写的代码太乱,后来又重新写了一份代码,然后把两个代码提取的特征进行拼接,然后用RF删选了部分特征。
访问用户夸地区特征(UserID 特征)
训练数据:44w
训练和测试数据的一共有多少次用户记录: (train_users, test_users) = (48164,0058, 10669,5157)
训练和测试数据的一共有多少个不同用户(去重后): unique -- (train_users, test_users) = (9598,7868, 5079,1399)
测试集中,与训练集共同的用户:common user = 4448,1460
测试集中,与训练集不同的用户:different users = 630,9939
1. local 特征
假设一共有N_user个用户,为每个用户开 9 * N_local_feature的特征, 9代表label的种类,N_local_feature为用户特征。
- step 1:希望得到每个用户的local特征张量 tmp = (N_user, 9, N_local_feature)。假设user_0, 出现在label_0的地区,特征会feature_0, 那么tmp[user_0, label_0, :] += feature_0
- step 2:为每个地区(样本,包括测试样本)提取特征。假设该地区有N_0个用户,那么我就可以从上面的tmp中得到特征res = (N_0, 9, N_local_feature),由于此时的res包含自身的label信息,所以我们得减去自身的feature特征, i.e., 假设user_0, 出现在label_0的地区,特征会feature_0, 那么 res[user_0, label_0, :] -= feature_0.
- step 3:进行reshape, 使得res = (N_0, 9*N_local_feature),然后为每一列提取之前的8个统计量特征,从而得到该地区(样本)的特征,特征维度9*N_local_feature*8
现在说下N_local个维度的特征feature_0,包括,
a)用户的时间轴上的天数,小时数,一天中最早出现和最晚消失的时间以及其时间差,一天中相邻时间的最大间隔小时数;
b)以及节假日的相应特征(由于内存限制,我们对于节假日的特征,只提取了部分特征,天数,小时数), 这边我们节假日分的稍微粗糙点,
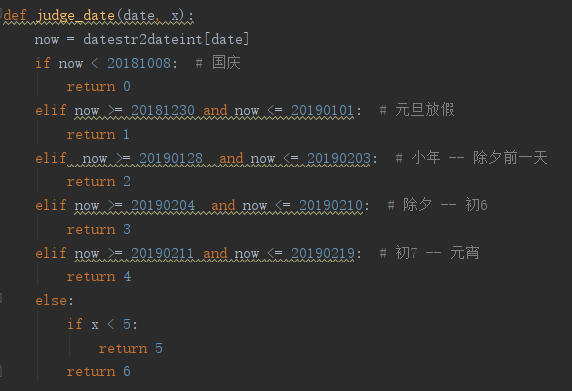
2. global 特征
这边所谓的global特征,指的就是之前说的basic特征(为了避免后面提取的特征维度太大,这里我们指删选出部分basic特征)。
- step 1:希望得到每个用户的global特征张量 tmp = (N_user, 9, N_global_feature)。假设user_0, 出现在label_0的地区,特征为feature_0 (PS:feature_0为该地区的basic的部分特征,所以对这个地区的用户的特征,都是一样的,就是feature_0), 那么tmp[user_0, label_0, :] += feature_0
- step 2:为每个地区(样本,包括测试样本)提取特征。假设该地区有N_0个用户,那么我就可以从上面的tmp中得到特征res = (N_0, 9, N_global_feature),由于此时的res包含自身的label信息,所以我们得减去自身的feature特征, i.e., 假设user_0, 出现在label_0的地区,特征会feature_0, 那么 res[user_0, label_0, :] -= feature_0.
- step 3:进行reshape, 使得res = (N_0, 9*N_global_feature),然后为每一列提取之前的8个统计量特征,从而得到该地区(样本)的特征,特征维度9*N_local_feature*8
ps: 至于,为什么会想到global特征,主要原因是我们观察很多visit的样本,里面的用户特别少,信息不够,即使我们跨样本提取了用户的特征,但是很有可能跨用户的信息还是不够,所以有一天骑车回家的路上,就想到了,为什么不用整个样本的特征(gloal特征)来跨样本建立用户之间的联系。这样即使,一个用户在别的样本中,自身的信息很少,但我们还是可以有整个样本的信息。我们也想过尝试给样本之间建图或用户之间建图,但是感觉不是很trival的事情,所以也没搞,希望有人有尝试,学习下哈。
至此,基本上最重要的特征都提取完了。然后用LightGBM进行训练即可。
Stack Model
把上面的三个5-fold得到的概率特征,再次放入LightGBM进行训练即可。最终线下5-fold的准确率在0.910786左右,线上的准确率为0.90203。
github: https://github.com/zhuqunxi/Urban-Region-Function-Classification

 浙公网安备 33010602011771号
浙公网安备 33010602011771号