
转载: redis中的bigkey问题
reference: https://www.modb.pro/db/459810
什么是bigkey
bigkey就是redis key/value体系中的大value问题。我们知道redis的底层数据存储结构中,有多种数据结构的实现。
String: 简单动态字符串
List: 双向链表、压缩列表
Hash: 哈希表、压缩列表
Sorted Set: 跳表、压缩列表
Set: 整数列表
一般来说,bigkey在value是字符串类型时,表现为字符串的长度过长;value为复合类型(hash、list、set、zset)时,表现为包含的元素个数过多,或者成员总大小过大。
bigkey的危害
-
超时阻塞。由于redis单线程的特性,操作bigkey通常比较耗时,也就意味着阻塞redis的可能性很大,这样会造成客户端阻塞,造成慢查。
-
网络拥塞。bigkey意味着每次获取数据产生的网络流程较大。假设一个bigkey为1MB,客户端每秒访问1000,那么每秒产生1000MB的流量,对于千兆网卡(128MB/s)的服务器来说,可以说是灾难了。
-
内存空间不均匀。在集群模式下,由于bigkey的存在,会造成主机节点的内存不均匀,这样不利于集群对于内存的统一管理。
-
阻塞删除。删除一个大key造成主库较长时间的阻塞。
bigkey产生的原因
主要原因:程序设计地不合理。
常见的几种业务场景
社交类:粉丝列表,如果某些明星或者大V不精心设计的情况下,就是bigkey。
统计类:例如按天存储某项功能或者网站的用户集合,除非没几个人用,否则也会是bigkey。
缓存类:将数据从数据库load出来序列化放在redis里,这个方式经常用,但是有两个地方需要注意:第一,是不是要把所有字段都缓存;第二,有没有关联的数据。
怎么应对:在程序设计中,我们要对数据量的增长和边界有一个基本性的评估,做好技术选型和技术架构。
bigkey的发现和监控
痛点:监控程序带来redis性能损耗。
redis内置命令
debug object:阻塞其他请求
MEMORY USAGE:时间复杂度O(N)
获取key长度命令:STRLEN、HLEN、SCARD、ZCARD、LLEN、XLEN
MEMORY USAGE
给出一个key和它在RAM中占用的字节数,是一种内存维度的抽样算法, 计算key大小是通过抽样部分field来估算总大小。
时间复杂度O(N),N是抽样的个数。
返回的结果是key的值以及为管理该key分配的内存总字节数。
127.0.0.1:6379> MEMORY usage runoobkey samples 5
(integer) 160
memory usage默认抽样5个field来循环累加计算整个key的内存大小,样本的数量决定了key的内存大小的准确性和计算成本,样本越大,循环次数越多,计算结果更精确,性能消耗也越多。
redis-cli客户端
redis-cli --bigkeys
Redis提供了bigkeys参数能够使redis-cli以遍历的方式分析整个Redis实例中的所有Key并汇总以报告的方式返回结果。
优点:在线扫描,不阻塞服务。缺点:分析结果不可定制化。只能计算每种数据结构的top1。
bigkeys仅能分别输出Redis六种数据结构中的最大Key,如果你想只分析STRING类型或是找出全部成员数量超过10的HASH Key,那么bigkeys在此类需求场景下将无能为力。
开源工具
RDB文件扫描
redis-rdb-tools
https://github.com/sripathikrishnan/redis-rdb-tools?spm=a2c6h.12873639.article-detail.7.6e225a65k3bqC8
使用redis-rdb-tools工具以定制化方式找出大Key。
redis-rdb-tools 是一个 python 的解析 rdb 文件的工具,在分析内存的时候,我们主要用它生成内存快照。
主要有以下三个功能:
生成内存快照
转储成 json 格式
使用标准的 diff 工具比较两个 dump 文件
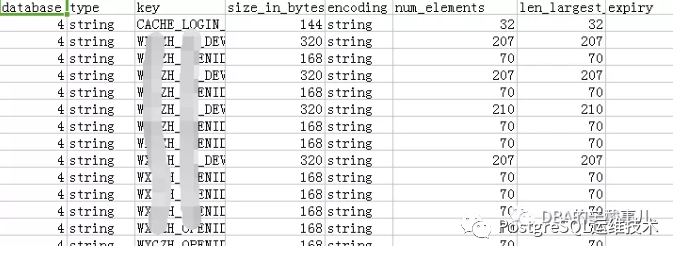
图片来源:https://www.cnblogs.com/cheyunhua/p/10598181.html
可以将CSV的数据导入到MySQL,这样就可以利用sql语句对Redis的内存数据进行各种分析。
rdr
https://github.com/xueqiu/rdr
./rdr show -p 8080 *.rdb
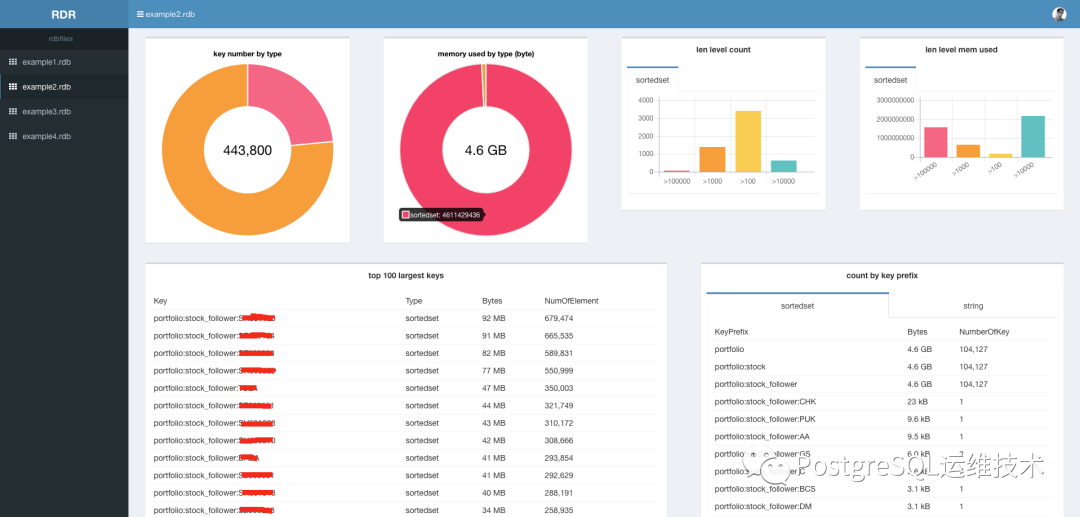
redis-rdb-cli
https://github.com/leonchen83/redis-rdb-cli
RDB持久化:是一种内存快照的形式,按照一定的频次进行快照落盘。
优点:这是一种理想化的选择,不会影响redis服务的进行。缺点:有些redis服务没有采用RDB持久化,不具有普遍性。时效性更差。
定制化
手动使用SCAN + TYPE并配合STRLEN等命令自己实现一个Redis实例级的大Key分析工具。
支持固定key值和key patten。在key patten中,通过scan pattern得到一定范围的key,再通过length函数对每种类型的key("HLEN""LLEN""SCARD""ZCARD""PFCOUNT""STRLEN")取值,得到对应的key的length。
如何优化big key?
1.合理优化数据结构。拆:将大的key,拆成小的key。压缩:对较大的数据进行压缩处理。
2.选择其他存储方案。比如文档性数据库MongoDB。
如何删除big key
推荐使用 UNLINK 命令,异步删除 bigkey,不影响主线程执行其他命令。在业务的低峰期使用 scan 命令查找 big key,对于类型为集合的key,可以使用脚本逐一删除里面的元素。
参考:
https://segmentfault.com/a/1190000039953951
https://github.com/sripathikrishnan/redis-rdb-tools?spm=a2c6h.12873639.article-detail.7.6e225a65k3bqC8
https://github.com/xueqiu/rdr
https://github.com/leonchen83/redis-rdb-cli



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)