Linux实战教学笔记26:http协议原理
第二十六节 http协议原理
标签(空格分隔): Linux实战教学笔记-陈思齐
---本教学笔记是本人学习和工作生涯中的摘记整理而成,此为初稿(尚有诸多不完善之处),为原创作品,允许转载,转载时请务必以超链接形式标明文章原始出处,作者信息和本声明。否则将追究法律责任。http://www.cnblogs.com/chensiqiqi/
第1章 Web服务基础
1.1 http服务重要基础
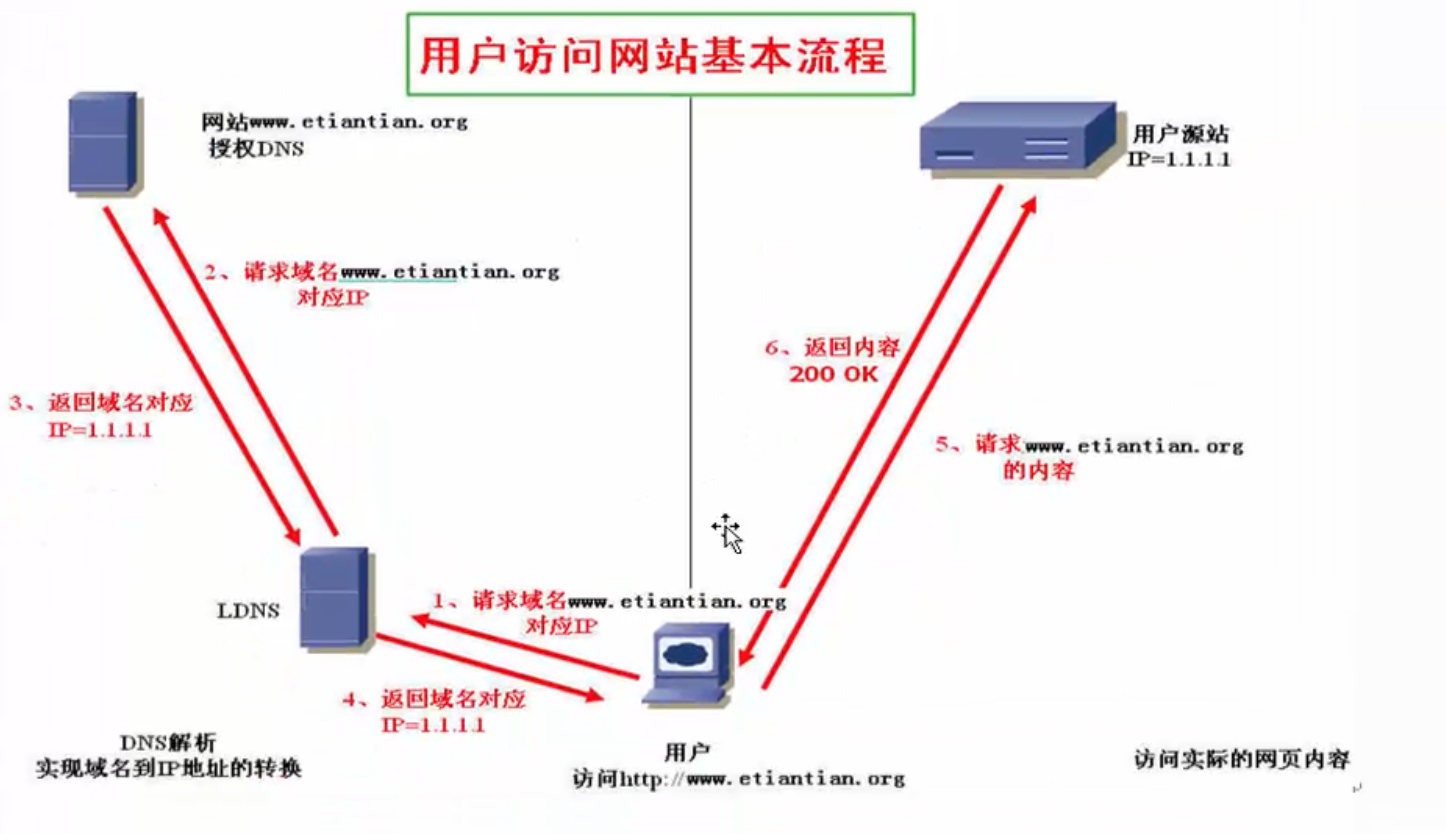
1.1.1 用户访问网站基本流程
- 我们每天都会使用Web客户端上网浏览网页。最常见的Web客户端就是Web浏览器,如通用的微软Internet Explorer(IE)以及技术人员偏爱的火狐浏览器,谷歌浏览器等。当我们在Web浏览器里输入网站地址(例如:www.baidu.com)时,很快就会看到网站的内容。这看起来很神奇的背后,到底是怎样的实现流程呢?也许普通的上网者无需关注,但作为一个IT技术人员,特别是合格的Linux运维人员,就需要清晰的掌握了。
-
下面就给大家介绍从客户端用户在Web浏览器里输入网站地址,到看到网站内容的完整访问流程。
-
[x] 第一步:客户端用户从浏览器里输入www.baidu.com网站地址,回车后,系统首先会查找系统本地的DNS缓存及hosts文件信息,查找是否存在www.baidu.com域名对应的IP解析记录,如果有就直接获取IP地址,然后去访问这个IP地址对应域名www.baidu.com的服务器,一般第一次请求时,DNS缓存是没有解析记录的,而hosts多在内部临时测试时使用。
-
[x] 第二步:如果客户端本地hosts及DNS缓存及hosts文件没有www.baidu.com域名对应的解析记录,那么,系统会把浏览器的解析请求发送给客户端本地设置的DNS服务器地址(通常称此DNS为LDNS,即Local DNS)解析,如果LDNS服务器的本地缓存有对应的解析记录就会直接返回IP地址给客户端,如果没有,则LDNS会负责继续请求其他的DNS服务器。
-
[x] 第三步:LDNS会从DNS系统的(.)开始请求www.baidu.com域名的解析,针对各个层级的DNS服务器系统进行一系列的查找,最终会查找到baidu.com域名对应的授权DNS服务器,而这个授权DNS服务器正是企业购买域名时用于管理域名解析的服务器,这个授权服务器会有www.baidu.com对应的IP解析记录,如果此时没有,就表示企业的域名管理人员没有为www.baidu.com域名做解析设置,即网站还没架设好。
-
[x] 第四步:baidu.com域名的授权DNS服务器会把www.baidu.com对应的最终IP解析记录发给LDNS。
-
[x] 第五步:LDNS把收到的来自授权DNS服务器www.baidu.com对应的IP解析记录发给客户端浏览器,并且再LDNS把本地域名和IP的对应解析缓存起来,以便下一次更快的返回相同解析请求的记录,这些缓存记录在指定的时间(DNS TTL值控制)内不会过期。
-
[x] 第六步:客户端浏览器获取到了www.etiantian.org的对应IP地址,接下来,浏览器会请求获得的IP地址对应的网站服务器,网站服务器接收到客户端的请求并响应处理(此处的处理可能是数百台集群的服务器系统,也可能是一台云主机),将客户请求的内容返回给客户端浏览器,至此,一次访问浏览网页的完整过程就完成了。
提示:
上述仅仅是客户端用户第一次访问网站的基本过程,连续访问后,系统本地和LDNS层级都会有缓存记录,再访问时流程就会有些变化,会直接取本地缓存记录,这样访问过程就很快了。在上述整个访问流程里,包含了DNS的解析流程以及HTTP协议的通信原理等重要的技术点。
1.1.2 DNS系统解析基本流程
- 了解完用户访问网站的基本流程后,再来了解下DNS解析的基本流程,这是企业针对运维岗位进行招聘时经常会面试的问题,因此,必须要熟练掌握了。
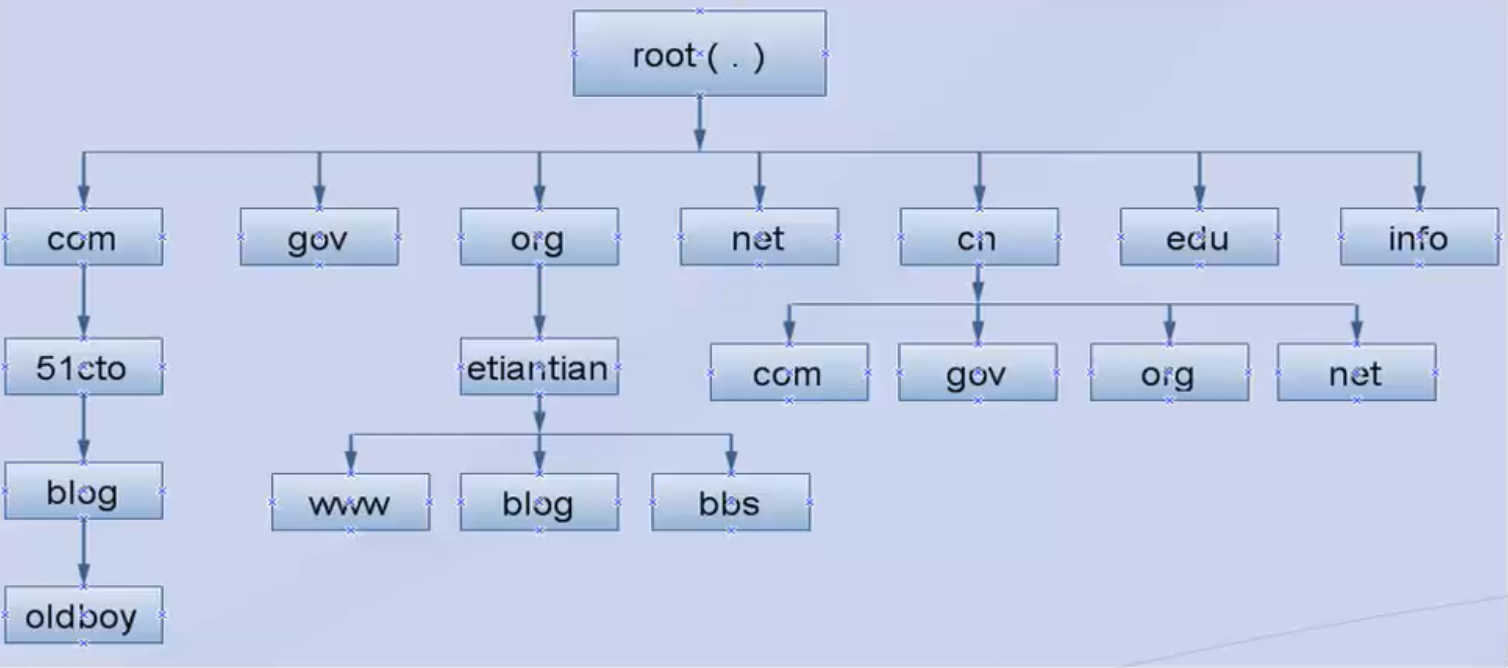
- DNS,全称Domain Name System/Serve,它在一个网站运行中起来了至关重要的作用,它的主要作用是负责把网站域名解析为对应的IP地址,例如:把www.baidu.com解析为对应的IP地址记录如1.1.1.1,这个从域名到IP的解析过程,称作A记录,即Address Record。
- DNS系统除了负责这个最重要的A记录解析外,还有很多的功能。例如:
- 设置CNAME别名记录,这个别名解析功能常被CDN加速服务商应用。
- 设置MX邮件记录,这个MX记录功能,在购买或搭建邮件服务时会被用到。
- 设置PTR记录,反向解析,即把IP地址解析为对应的域名,和A记录的解析相反,邮件服务等业务中会用到。
- DNS 系统的架构类似于一颗倒挂着的树(和Linux系统目录结构类似),它的顶点也是根("."),只不过这个根是用点(.)来表示的,不是目录的根斜线(/)。
DNS解析原理流程
(1)DNS解析流程说明
- 在“用户访问网站基本流程”一节,我们了解了用户访问网站的基本实现过程,那么客户端是怎样一步步通过各个层级的DNS,获取到域名对应的IP的呢?这里给大家做一个较为详细的说明。
- DNS的解析流程实际上就是从用户在客户端浏览器中输入网站地址并按回车开始的,一直持续到获取域名对应的IP,整个过程可分为如下几个步骤。
- [x] 第一步:客户端用户从浏览器里输入www.baidu.com网站地址后回车,系统首先会查找系统本地的DNS缓存及hosts文件信息,确定是否存在www.baidu.com域名对应的IP解析记录,如果有就直接获取到IP地址,然后去访问这个IP地址对应的www.baidu.com域名的服务器,一般第一次请求时,DNS缓存是没有解析记录的,而hosts多为内部临时测试使用。
- [x] 第二步:如果客户端DNS缓存及本地hosts文件没有www.baidu.com域名对应的解析记录,那么,系统会把浏览器的解析请求发送给在客户端本地设置的DNS服务器地址(通常称此DNS为LDNS,即:Local DNS)解析,如果LDNS服务器的本地缓存有对应的解析记录就会直接返回IP地址给客户端:如果没有,则LDNS会负责继续请求其他的DNS服务器。
- [x] 第三步:LDNS会从DNS系统的(.)根开始请求www.baidu.com域名的解析,根DNS服务器在全球一共有13台,根服务器下面是没有www.baidu.com域名解析记录的,但是根下面有www.baidu.com对应的顶级域.org的解析记录,因此,根会把.org对应的DNS服务器地址返回给LDNS。
- [x] 第四步:LDNS获取到.org对应的DNS服务器地址后,就会去.org服务器请求www.baidu.com域名的解析,而.org服务器下面也没有www.baidu.com域名对应的解析记录,但是有baidu.com域名的解析记录,因此,.org服务器会把baidu.com对应的DNS服务器地址返回给LDNS
- [x] 第五步:同理,LDNS获取到baidu.com对应的DNS服务器地址后,就会去baidu.org服务器请求www.baidu.com域名的解析,baidu.com域名对应的DNS服务器是该域名的授权DNS服务器,这个DNS服务器正是企业购买域名时管理解析所在的服务器(也可能是自建的授权DNS服务器),这个服务器会有www.baidu.com对应的IP解析记录,如果此时没有,就表示企业的域名人员没有为www.baidu.com域名做解析,即网站还没架设好。
- [x] 第六步:baidu.com域名DNS服务器会把www.baidu.com对应的IP解析记录发给LDNS
- [x] 第七步:LDNS把收到的来自授权DNS服务器www.baidu.com对应的IP解析记录发给客户端浏览器,并且LDNS会把本地域名和IP的对应解析记录缓存起来,以便下一次更快的返回相同解析请求的记录。至此,整个DNS的解析流程就完成了。
(2)DNS解析流程图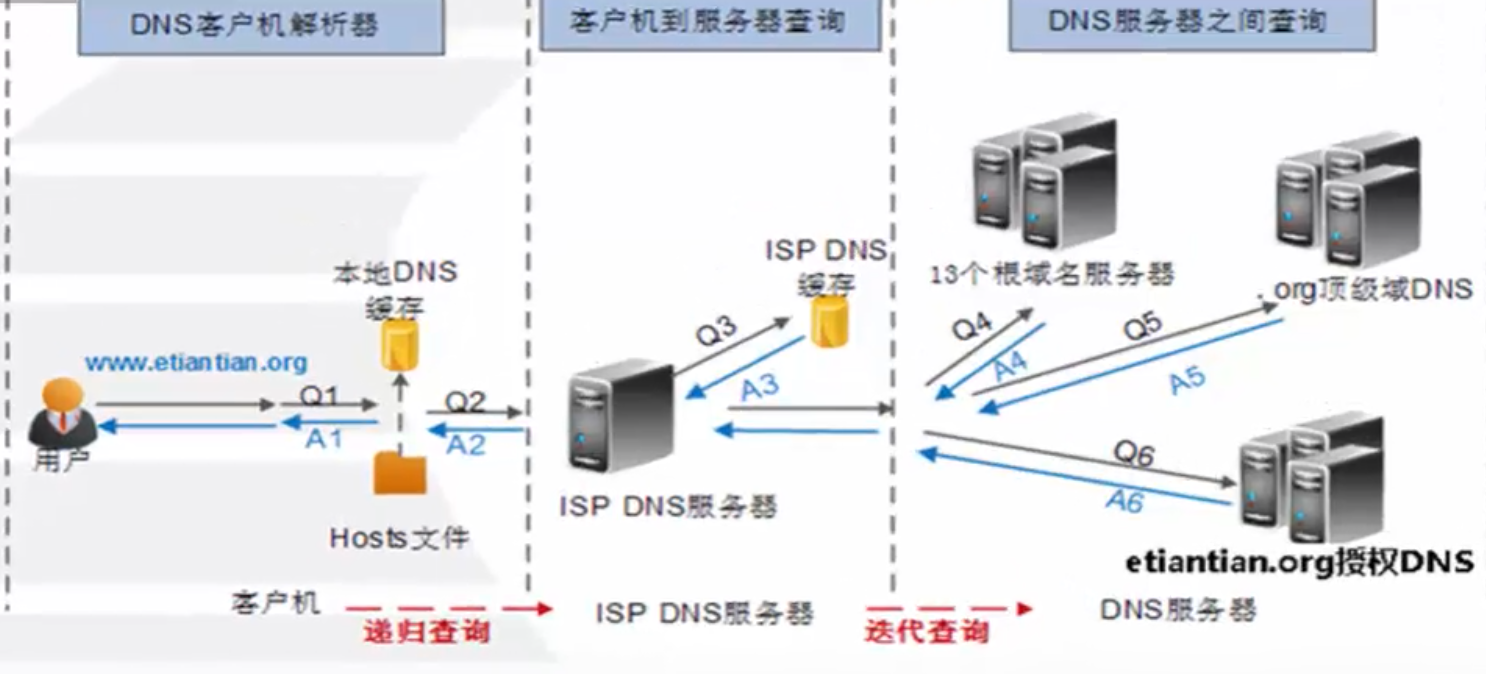
1.2 HTTP协议
1.2.1 HTTP协议简介
- HTTP协议,全称HyperText Transfer Protocol,中文名为超文本传输协议,是互联网中最常用的一种网络协议。HTTP的重要应用之一是WWW服务。设计HTTP协议最初目的就是提供一种发布和接收HTML(一种页面标记语言)页面的方法(请求返回)。
- HTTP协议是互联网上常用的通信协议之一。它有很多的应用,但最流行的就是用于Web浏览器和Web服务器之间的通信,即WWW应用或称Web应用。
- WWW,全称World Wide Web,常称为Web,中文译为“万维网”。它是目前互联网上最受用户欢迎的信息服务形式。HTTP协议的WWW服务应用的默认端口为80(端口的概念),另外的一个加密的WWW服务应用https的默认端口为443,主要用于网银,支付等和钱相关的业务。当今,HTTP服务,WWW服务,Web服务三者的概念已经混淆了,都是指当下最常见的网站服务应用。
1.2.2 常见的HTTP请求方法
| HTTP方法 | 作用描述 |
|---|---|
| GET | 客户端请求指定资源信息,服务器返回指定资源 |
| HEAD | 只请求响应报文中的HTTP首部 |
| POST | 将客户端的数据提交到服务器,例:注册表单 |
| PUT | 从客户端向服务器传送的数据取代指定的文档内容 |
| DELETE | 请求服务器删除Request-URI所标识的资源 |
| MOVE | 请求服务器将制定的页面移至另一个网络地址 |
1.2.3 HTTP状态码
- HTTP状态码(HTTP Status Code)是用来表示Web服务器响应http请求状态的数字代码。每当Web客户端向Web服务器发送一个HTTP请求时,Web服务器都会返回一个状态响应代码。这个状态码是一个三位数字代码,作用是告知Web客户端此次的请求是否成功,或者是否要采取其他的动作方式。
- HTTP协议1.1版本中的状态吗可以分为五大类,如下表:
| 状态码范围 | 作用描述 |
|---|---|
| 100-199 | 用于指定客户端相应的某些动作 |
| 200-299 | 用于表示请求成功 |
| 300-399 | 用于已经移动的文件并且常被包含在定位头信息中指定新的地址信息 |
| 400-499 | 用于指出客户端的错误 |
| 500-599 | 用于指出服务器端的错误 |
提示:
http响应的状态码种类很多,但是在实际工作场景中,经常遇到的状态码却不多,我把生产场景常见的重要状态码及对应的作用整理为下表。
生产场景常见的状态吗及其对应的作用
| 状态代码 | 详细描述说明 |
|---|---|
| 200~OK | 服务器成功返回网页,这是成功的http请求,返回的标准状态码 |
| 301-Moved Permanently | 永久跳转,所有请求的网页将永久跳转到被设定的新的位置,例如:从baidu.com跳转到www.baidu.com |
| 403-Forbidden | 禁止访问,这个请求是合法的,但是服务器端因为匹配了预先设置的规则而拒绝响应客户端的请求,此类问题一般为服务器或服务权限配置不当所致。 |
| 404-Not Found | 服务器找不到客户端请求的指定页面,可能是客户端请求了服务器上不存在的资源导致 |
| 500-Internal Server Error | 内部服务器错误,服务器遇到了意料不到的情况,不能完成客户的请求。这是一个较为笼统地报错,一般为服务器的设置或者内部程序问题导致。例如SElinux开启,而又没有为http设置规则许可,客户端访问就是500 |
| 502-Bad Gateway | 坏的网关,一般是代理服务器请求后端服务时,后端服务不可用或没有完成响应网关服务器。一般为反向代理服务器下面的节点出问题导致。 |
| 503-Service Unavailable | 服务当前不可用,可能因为服务器超载或停机维护导致,或者是反向代理服务器后面没有可以提供服务的节点 |
| 504-Gateway Timeout | 网关超时,一般是网关代理服务器请求后端服务时,后端服务没有在特定的时间内完成处理请求,一般是服务器过载导致没有在指定的时间内返回数据给前端代理服务器。 |
1.2.4 HTTP响应报文介绍
HTTP响应报文由起始行,响应头部,空行和响应报文主体几个部分组成,和HTTP请求报文格式类似。报文如下表:
| 报文格式 | 报文信息 |
|---|---|
| 起始行 | 协议及版本号 数字状态码 状态信息 |
| 响应头部 | 字段1:值1 字段2:值2 |
| 空行 | 空白内容 |
| 响应报文主体 | 就是html的网页 |
下面对响应报文的每个部分逐一阐述:
(1)起始行
响应报文的起始行,也叫状态行,用来说明服务器响应客户端请求的状况。一般为协议及版本号,数字状态码,状态情况。例如:HTTP/1.1 200 OK
(2)响应头部
和请求报文类似,起始行的后面一般有若干个头部字段。每个头部字段都包含一个名字和一个值,两者之间用冒号分隔。头部结尾也是以一个空行结束。常见的头部信息有:
(3)空行
最后一个响应头部信息之后是一个空行,发送回车符和换行符,通知客户端空行下文无头部信息。
(4)响应报文主体
响应报文主体中装载了要返回给客户端的数据。这些数据可以是文本,也可以是二进制的(图片,视频)。
1.2.5 HTTP协议原理及重点分析
回顾:数据包,传输过程
HTTP协议属于OSI模型中的第七层应用层协议,HTTP协议的重要应用就是WWW服务应用,下面就以WWW服务应用为例介绍HTTP协议的通信原理了,HTTP协议进行通信时,需要有客户端(即终端用户)和服务端(即Web服务器),在Web客户端向Web服务器发送请求报文之前,先要通过TCP/IP协议在Web客户端和服务器之间建立一个TCP/IP连接。整个http协议请求的工作流程如下:
1)终端客户在Web浏览器地址栏输入访问地址http://www.baidu.com
2)Web浏览器请求DNS服务器把域名www.baidu.com转换成Web服务器的IP地址,此处的解析过程就是DNS解析的原理流程,前面已经讲过了,此处不再叙述。
3)Web浏览器将端口号(默认80)从访问地址(URL)中解析出来。
4)Web浏览器通过解析后的IP地址及端口号于Web服务器之间建立一条TCP连接
5)建立TCP连接后,Web浏览器向Web服务器发送一条HTTP请求报文,请求报文内容格式及信息细节前面已经讲过了,此处不在叙述。
6)Web服务器响应并读取浏览器的请求信息,然后返回一条HTTP响应报文,响应报文内容格式及信息细节前文也已经讲过了,此处不在叙述。
7)Web服务器关闭http连接,关闭TCP连接,Web浏览器显示访问的网站内容到屏幕。
上述就是HTTP协议通信原理过程,整个通信原理的重要知识点有:
- [x] 用户访问网站的流程
- [x] DNS解析流程细节
- [x] 建立TCP连接过程(TCP/IP三次握手原理知识)(11种状态)
- [x] 发送HTTP报文及HTTP请求报文内容细节。
- [x] Web服务器响应客户端请求处理细节(网站集群架构细节)
- [x] 响应HTTP报文及HTTP响应报文的细节
- [x] 关闭TCP连接,涉及TCP/IP协议四次挥手原理
事实上,DNS解析原理,http协议原理,tcp/ip协议原理都是高薪面试的重点,是高级运维必备知识,这里对其中的重要知识点进行汇总,如下:
- [x] http协议位于OSI模型中第7层应用层
- [x] http协议的重要应用是www服务。
- [x] 用户上网流程,DNS解析原理流程
- [x] DNS解析获取的IP后,建立TCP连接,然后发送http请求细节和服务器响应细节。
- [x] HTTP请求报文与HTTP响应报文知识
- [x] 到达HTTP服务后请求后端集群节点流程为Nginix-->fastcgi-->PHP-->(数据库,存储等)
- [x] TCP/IP协议三次握手和四次挥手原理。
1.3 HTTP资源
1.3.1 媒体类型
- 互联网上的数据有很多不同的数据类型,Web服务器会把通过Web传输的每个对象都打上名为MIME类型(MIME Type)的数据格式标签。最初涉及MIME(Multipurpose Internet Mail Extension 多用途因特网邮件扩展)是为了解决在不同的电子邮件系统之间搬移报文时存在的问题。MIME在电子邮件系统中工作的非常好,后来,HTTP也支持了这个功能,用它来把数据描述并标记不同的数据内容类型。
- 当Web服务器响应HTTP请求时,会为每一个HTTP对象数据加一个MIME类型,当Web浏览器获取到服务器返回的对象时,会去查看相关的MIME类型,进行相应处理。
- MIME类型存在于HTTP响应豹纹的响应头部信息里,它是一种文本标记,表示一种主要的对象类型和一个特定的子类型,中间由一条斜杠来分隔。
| MIME类型 | 文件类型 |
|---|---|
| text/html | html htm shtml文本类型 |
| text/css | css文本类型 |
| text/xml | xml文本类型 |
| image/gif | gif图像类型 |
| image/jpeg | jpeg jpg图像类型 |
| application/javascript | js文本类型 |
| text/plain | txt文本类型 |
| application/json | json文本类型 |
| text.plain | txt文本类型 |
| application/json | json文本类型 |
| video/mp4 | mp4视频类型 |
| video/quicktime | mov视频类型 |
| video/x-flv | flv视频类型 |
| video/x-ms-wmv | wmv视频类型 |
| video/x-msvideo | avi视频类型 |
可以从www的重要服务软件Nginx的配置文件conf目录下,查看其支持的媒体(MIME)类型,相关命令及内容为:
[root@chensiqi conf]# head -10 mime.types
types {
text/html html htm shtml;
text/css css;
text/xml xml;
image/gif gif;
image/jpeg jpeg jpg;
application/javascript js;
application/atom+xml atom;
application/rss+xml rss;
以下内容省略....1.3.2 URL介绍
URL,全称Uniform Resource Location,中文翻译为统一资源定位符,也被称为网页地址(网址)。如同在网络上的门牌,它是因特网上标准的资源唯一地址。通俗地说,URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户端和服务器程序上。采用URL可以用一种统一的格式来描述各种信息资源,包括文件,服务器的地址和目录等。严格的说,每个URL都是一个URI,它标识一个互联网资源,并指定对其进行操作或取得该资源的方法。
URL的格式由下列三部分组成:
- [x] 第一部分是协议,例如:http
- [x] 第二部分是主机资源服务器IP地址或域名(端口号),例如:www.baidu.com
- [x] 第三部分是主机资源的具体地址,如目录和文件名等,例如:chensiqi/index.html
提示:
第一部分和第二部分之间用“://”符号隔开,第二部分和第三部分用"/"符号隔开。第一部分和第二部分是不可缺少的,第三部分可以省略。
标准的URL及说明
| 协议 | 分隔符号 | IP地址域名 | 分隔符号 | 资源目录地址 |
|---|---|---|---|---|
| http | :// | www.chensiqi.com | / | chensiqi/index.html |
| http | :// | www.chensiqiedu.com | / | video/index.html |
1.3.3 URI介绍
- URI,全称Uniform Resource Identifier,中文翻译为统一资源标识符,是一个用于标识某一互联网资源名称的字符串。这个字符串在世界范围内唯一标识并定位某一个信息资源。互联网上每个可用的数据资源,如HTML,图片,视频等皆通过统一资源标识符进行定位。
网站URL说明
| 协议 | 分隔符号 | IP地址域名 | 分隔符号 | 资源目录地址 |
|---|---|---|---|---|
| http | :// | www.chensiqi.com | / | chensiqi/index.html |
| http | :// | www.chensiqiedu.com | / | video/index.html |
指向一个用户邮箱的URI
| 协议(服务形式) | 分隔符号 | 用户名 | 分隔符号 | 域名 |
|---|---|---|---|---|
| mailto | : | chensiqi | @ | chensiqi.com |
大多数同学都熟悉URL,而不是URI。URL是URI命名机制的一个子集
1.3.4 静态网页资源
静态网页资源介绍
在网站设计中,纯粹HTML格式的网页(可以包含图片,视频,JS(前端功能实现),CSS(样式)等)通常被称为“静态网页”,早期的网站大多都是静态的。静态网页是相对于动态网页而言的,是指没有后台数据库,不含程序(如php,jsp,asp)和可交互的网页。
静态网页资源特点
- 静态网页资源的特点是,开发者编写的是什么,它显示的就是什么,一旦编写完成,就不会有任何改变。静态网页的维护和更新相对比较麻烦,每个不同的网页都需要单独编集更新,静态网页一般适用于更新较少的宣传展示型网站(例如:酒,家具,猪饲料等的宣传网站),是早期很多中小网站展示的形式。
- 静态网页资源的对应程序及资源文件的常见扩展名为:
- 纯文本类程序或文件,如htm,html,xml,shtml,js,css等
- 图片类文件或数据文档,如jpg,gif,png,bmp,txt,doc,ppt等
- 视频类流媒体文件,如mp4,swf,avi,wmv,flv等
静态网页资源有几个重要的特征:
- [x] 每个网页都有一个固定的URL地址,且URL一般以.html,.html,shtml等常见形式为后缀,而且地址中不含邮问号“?”或“&”等特殊符号。
- [x] 网页内容一经发布到网站服务器上,无论是否有用户访问,每个网页的内容都是保存在网站服务器文件系统上的,也就是说,静态网页是实实在在保存在服务器上的文件实体,每个网页都是一个独立的文件。
- [x] 网页内容是固定不变的,因此,容易被搜索引擎收录(容易被用户找到)(优点)
- [x] 网页没有数据库支持,在网站制作和维护方面工作量较大,因此当网站信息量很大时完全依靠静态网页制作的方式比较困难(缺点)
- [x] 网页的交互性较差,在程序功能实现方面有较大的限制(缺点)
- [x] 网页程序在用户浏览器端解析,如IE浏览器,程序解析效率很高,由于服务端不进行解析,并且不需要读取数据库,因此服务器端可以接受更多的并发访问。当客户端向服务器请求数据时,服务器直接把数据从磁盘文件系统上返回(不做任何解析),待客户端拿到数据后,在浏览器端解析展现出来(优点)
网站静态页面的特点就相当于在餐馆吃火锅,餐馆把原材料和工具都给你准备好,你自己只需要涮着吃就行,不需要饭店大厨给你炒菜做菜了,因此,对于饭店来讲,服务顾客的效率大大提高了。而对于静态页面来讲就是不需要服务器端解析,因此提供网站方服务器的压力也大大减轻了。
静态网页语言
常见的静态网页语言有html,js,css,xml,shtml等,具体语言的特点不在这里细说。
回顾一下静态网页的核心特点,如下:
1)程序在客户浏览器端解析,不读取后端数据库,因此性能和效率很高。
2)因为后端没有数据库支持,所以和用户的交互性较差,功能实现也很少。
有关静态网页的架构思想
在高并发,高访问量的场景下做架构优化,涉及的关键环节就是把动态网页转成静态网页,而不直接请求数据库和动态服务器,并且可以把静态内容推送到前端缓存(或CDN)中提供服务,这样就可以提升用户体验,节约服务器和维护成本。
1.3.5 动态网页资源
动态网页资源介绍
所谓的动态网页是与静态网页相对而言的,也就是说,动态网页的URL后缀不是.htm,.html,.shtml,.xml,.js,.css等静态网页的常见后缀扩展名形式,而是以.asp,.aspx,.php,.js,.do,.cgi等形式作为后缀的,并且一般在动态网页网址中会有标志性的符号--“?,&”,此外,在大多数情况下后端都需要有数据库支持等。
动态网页资源特点
1)网页扩展名后缀常见为:.asp,.aspx,.php,.jsp,.do,cgi等
2)网页一般以数据库技术为基础,大大降低了网站维护的工作量
3)采用动态网页技术的网站可以实现更多的功能,如用户注册,用户登录,在线调查,投票,用户管理,订单管理,发博文等等
4)动态网页并不是独立存在于服务器上的网页文件,当用户请求服务器上的动态程序时,服务器解析这些程序并可能读取数据库返回一个完整的网页内容。
5)动态网页中的“?”在搜索引擎的收录方面存在一定问题,搜索引擎一般不会从一个网站的数据库中访问全部网页,或者出于技术等方面的考虑,搜索蜘蛛一般不会去抓去网址中“?”后面的内容,因此在企业通过搜索引擎进行推广时,需要针对采用动态网页的网站做一定的技术处理(伪静态技术),以便适应搜索因穷的抓取要求。
6)程序在服务器端解析,这相当于顾客点餐,饭店厨师做饭做菜,耗时长,效率低。由于程序在服务端解析,因此,会消耗大量的CPU和内存,I/O等资源,并且多数还要读取数据库等服务,因此,其访问效率远不如静态网页,在服务端解析动态程序的服务常见的有PHP引擎,Java容器(tomcat,resin,jboss,weblogic)
有关动态网页的架构思想
- 一般来说,静态网页的性能效率是动态网页的10~30倍。且动态网站效率很差,并发能力也很低,在高并发场景中,应尽可能转换成静态网页提供服务。动态转静态几乎是所有高并发网站必备的架构方案思路,也是高级架构师的职责所在。
- 此外,动态转静态也要根据业务需求设计,例如,对于更新频繁的网站如果设计不好就可能会产生数据不一致的情况,即用户看到的数据不是网站最新的内容,而是静态的内容。
1.3.6 生产Web架构优化实战方案
由于静态网页程序在客户端解析,大大降低了服务器端的访问压力,因此解析效率更高,在实际高并发网站架构中,可以考虑把用户请求的数据解析后存成静态文件放于磁盘中或放于内存中,来降低动态服务器的压力,节约企业成本,提升用户体验。
(1)门户新闻业务
新闻网站的特点是一旦发布完成,几乎不会再改动网页内容。因此,对于新闻业务内容的静态化相对比较简单。
程序===>生成静态页面
- [x] 第一步:程序要支持发布动态内容转成静态功能
- [x] 第二步:运营编辑人员发布新闻网页后,后台程序立刻将动态网页生成静态文件。
- [x] 第三步:运维人员通过发布或事件触发把运营编辑生成的静态网页发布到事先搭建好的公司缓存集群服务器上,或者把静态内容同步到购买的全国所有CDN服务器节点上,然后,再提供给用户访问浏览。
(2)视频网站业务
- 视频网站和新闻网站类似,特点都是一旦发布完成,几乎不会再改动网页内容。因此,实现视频业务网站高效访问也很简单。
- 以优酷视频网为例,用户在上传视频时,需要经历转码-->审核的过程(大概1小时),然后一些热点视频也可能会被提前推送同步到CDN的核心节点或全国所有CDN服务器节点,用户访问时才会更快。
(3)Blog/BBS/SNS/微博社区业务/电商(如淘宝,京东)
这几类业务的动态转静态是比较困难的,因为,用户发布完成内容,可能会随时更新并查看,这种情况一般会通过异步方式,例如消息中间件技术加上NoSQL集群技术实现转换,当然也会改进产品细节,例如:在访问的环节设置延时,异步加载等手段。
1.4 网站流量度量术语
1.4.1 IP(internet Protocol)
IP(独立IP)即Internet Protocol,这里指独立IP数,独立IP数是指不同IP地址的计算机访问网站时被计算的总次数。独立IP数是衡量网站流量的一个重要指标。一般一天内(00:00 - 24:00)相同IP地址的客户端访问网站页面只被计算为一次,记录独立IP的时间可为一天或一个月,目前通用的标准为“一天”。
-
[x] 假设有部分同学同时在某处的局域网中打开了www.baidu.com,请问对于百度来说网站是几个独立IP?答:是一个独立IP。这是因为,国内几乎所有的公司都是采用局域网共享上网的,即通过路由器NAT地址转换上网,每个计算机在局域网内的私有IP是不同的,但是在外网上,就必须都要由路由器把每个私网地址转换成了路由器接口的固定公网IP(多IP映射暂不考虑),所以说,对于网站来说一天内多个相同公司的IP的客户端访问计算为一个独立IP
-
[x] 再假设一个客户端用户通过ADSL等直接拨号上网,但是上网的时候偶尔掉线,一共重新拨号了3次(相近时间重新拨号IP相同的几率是极少的),然后每次都继续打开百度的网页地址,请问此时,网站独立IP数是多少?还是一个独立IP
由此可见,通过独立iP数度量网站访问量,和实际的访问情况不是很匹配。国内的企业,学校大多数使用的NAT上网的,一个独立IP背后可能有数十上百个客户端访问。独立IP数虽然不是很准,但却是IT技术人员比较关心的一个衡量网站的指标。
1.4.2 PV(Page View)
- PV(访问量)即Page View,中文翻译为页面浏览,即页面浏览器或点击量,不管客户端是不是相同,也不管IP是不是相同,用户每次访问一个网站页面都会被计算一个PV。
- PV的具体度量方法就是从客户浏览器发出一个对Web服务器的请求(Request),Web服务器接到这个请求后,将该请求对应的一个网页(Page)发送给浏览器,就产生一个PV。这里有一个问题,就是只要这个请求发送给了浏览器,无论这个页面是否完全打开(或下载完成),那么都是会被计数为1个PV(服务器日志),一般为了防止用户快速刷PV,很多网站把PV的统计程序放在页面的最下面。
- 用PV衡量网站时,PV数反映的是浏览某网站的页面数量,每刷新一次页面也算一次。因此,可以说PV数与来访用户的数量成正比,但PV数并不是真正的页面来访者数量,而是网站被访问的页面数量,因为一个来访者可能产生多个PV。
问:如果一个用户要访问赶集网或58同城租房,你觉得用户可能会产生多少PV?
答:平均可能会有十几到几十个PV,一个来访者访问网站的PV数的多少是和网站提供的业务直接相关的。
例如:这些分类网站,用户浏览网站可能是为了找房子,找工作,因此一个用户访问的页面会很多,因此PV就会很多。
PV(Page View)是网站被访问的页面数量的一个指标,但不能直接知道有多少人访问了这个网站。
一个来访者访问网站,可能产生若干PV数,但是独立IP数就只有1个,因此,如果对比一个网站的独立IP数和PV数,不难看出,PV数一定会大于等于独立IP数的,视网站的业务而定,例如,对于分类门户,可能会达到10:1,甚至更多。
1.4.3 UV(Unique Visitor)
- UV(独立访客)即Unique Visitor,同一台客户端(PC或移动端)访问网站被计算为一个访客。一天(00:00-24:00)内相同的客户端访问同一个网站只计算一次UV。UV一般是以客户端Cookie等技术作为统计依据的,实际统计会有误差。
- 考虑到一台客户端电脑可能会有多人使用的情况,因此,UV(独立访客)实际上并不一定是独立的自然人访问。
1.http请求报文:浏览器版本,OS
2.http响应报文:cookie(id)
1.4.4 企业网站对IP,PV,UV的度量
- [x] 先来看对IP的度量:
- 分析所有Web服务器的访问日志信息,对IP地址段去重后计数,这是IT人员的基本计算手段
- 在网站的每一个(所有)页面结尾,嵌入JS等统计程序代码,待用户加载网页后,IP即传给统计IP的服务器,这种方法一般被第三方统计公司或企业内部开发日志分析程序时使用
- 用第三方大家比较信任的统计工具例如:谷歌的统计(GA)。
IP的统计方法简单,易用,因此,成为了多数网站衡量网站流量的重要指标之一。
- [x] 对PV的度量如下:
- 分析Web服务的访问日志(需要排除js,css及各种图片的日志信息),只计算HTML,PHP等页面数量。
- 在网站的每一个页面结尾,嵌入JS等统计程序代码,待用户加载网页后,访问数量即传给统计PV的服务器,这种方法一般被第三方统计公司或在企业内部开发日志分析程序时使用。
- 用第三方大家比较信任的统计工具例如:谷歌的统计(GA)
PV的统计方法也很简单,易用,因此,也是多数网站衡量网站流量的重要指标之一。
特别提示:
IP和PV概念,统计方法也是Linux运维人员要掌握的重点。
- [x] 对于UV的度量如下:
- 通过客户端HTTP请求报文分析
一个客户端会多次请求网站服务器,每次HTTP请求都会携带客户端自身的大量信息,比如:IP地址,请求发出时间,浏览器版本,操作系统版本等等。网站服务器对这些请求进行分析,如果这些请求满足一些共同特征,比如来自同一个IP地址,且浏览器版本和操作系统版本相同,请求时间又相近等,那么就可以认为这些是来自于同一个客户端,那么多个页面访问也只算一个UV。共同特征的定义是由服务器方决定的。通常,用IP地址+其他特征共同来定义的情况较多。但此种度量方法无法解决以下问题,例如:多个人的电脑软硬件经常雷同,并且是一个公司或者学校的人;多个人共用一个电脑的情况。 - 通过cookie鉴别
当客户端第一次访问某个网站服务器的时候,网站服务器会给这个客户端的电脑发出一个cookie,通常放在这个客户端电脑的C盘当中。在这个cookie中会分配一个独一无二的编号,这其中会记录一些访问服务器的信息,如访问时间,访问了哪些页面,等等。当你下次再访问这个服务器的时候,服务器就可以直接从你的电脑中找到上一次放进去的Cookie文件,并且对其进行一些更新,但那个独一无二的编号是不会变的。如果在一定时间内,服务器发现2个来访者对应的是一个编号,那么自然可以认为它来源于同一个来访者了,于是就计算1个UV。 - 使用Cookie的方法要比分析客户端HTTP请求头部信息分析更精确些。但也存在一些问题,比如:有的客户端为保证更高级别的安全,关闭了Cookie的功能;或者是有些客户端设置了在退出页面时自动删除Cookie,亦或你经常自己去手动删除Cookie,那么这个方法就不那么精确了。
- 因此,以上两个方法都只能得到近似的UV,而不是绝对精确。
- UV的度量相对IP和PV来说,不但麻烦,而且要开发比较复杂的程序系统才能得到期望的结果,因此,在Linux运维领域大家提及的较少,一般企业市场及运营人员可能会关注网站的UV。
- 通过客户端HTTP请求报文分析
1.4.5 IP,PV,UV的区别
- 针对该主题,通过一个访问示例来讲解吧
- 假设某城市的一个网吧里,有10个人都进入了www.baidu.com网站,每个人平均访问了5个页面,但是这个网吧对外出口是一个公网IP(注意:也可以配置多个IP出口,此处不计特殊情况),所以,对于baidu网站来说,只会计算一个独立IP访问,但是因为网吧里有10人在访问www.baidu.com网站,并且平均都访问了5次,因此,对于baidu网站来说,PV数就是10*5=50个PV,而因为有10个人访问,就是10个不同的客户端访问,因此,UV为10。
- 那么,在访问示例中:网站独立IP数为1个,PV数为50个,UV(独立访客)为10个。
- 通过上述结果,我们不难得出一个结论,一个网站的独立IP数量要比网站实际访问的PV数量小的多。通常情况下(国内互联网环境),网站的UV数也会大于独立IP数。
- PV数高说明访问的页面数多,但是不一定就代表来访者多:但PV数一定与来访者的数量成正比,不过,PV并不直接决定页面的真实来访者数量。比如在访问某网站时,一个人也可通过不断的刷新页面,制造出非常高的PV数。PV数多,用户访问网站页面的总数量多,通常服务器的压力会大一些。
1.4.6 并发连接
网站并发连接
在面试过程中Linux运维人员经常会被问到:你的公司网站最大并发是多少?
那么到底什么事并发?怎么理解并发呢?
A种理解:网站服务器每秒能够接收的最大用户请求数
B种理解:网站服务器每秒能够响应的最大用户请求数。
C种理解:网站服务器在单位时间内能够处理的最大连接数。
虽然A,B的理解占IT人员中的大多数,但是,C理解更为准确一些。
举个单位时间段的例子说明
我们去餐馆吃饭,餐馆里一共有10张桌子,每张桌最多坐4个人同时吃饭,那么一般人的理解,这个餐馆能够接收的并发吃饭人数为10*4,即40个并发,这里就没有考虑时间问题,1秒并发可以是40个,10分钟内并发也是40个。因为这里还有一个因素,就是每个人吃饭时长的问题,如果平均每个人10分钟吃完,那么可以说10分钟内,这个餐馆的并发为40个,而不是每秒钟并发40个,因为,第一秒可以是40个人同时进来,但是第二秒就无人可进了(满员了),如果说10分钟并发是40个,下一个10分钟还能是40个,第三个10分钟还可以是40个。即网站服务器在单位时间内能够处理的最大连接数。
再举个同一个时刻示例:
高速公路每个方向都有2条车道,那么,同一时刻并发的车辆为两辆,并且并发可以永远为2,如果按秒计算,每秒的并发可能就可以有十几辆,这个例子和餐馆不同,因为高速路处理并发不需要处理时间,但是对于Web服务器来讲,需要花费时间处理请求,这个请求可能是1秒或数秒,因此说,并发不应该只是用户访问的请求数,而是服务器同时处理的并发数,并且单位时间不一定是1秒,可能是一个连接的处理周期内的连接数。
对于网站服务器来说,所谓的并发就是单位时间内,服务器能够同时处理的最大连接数,因为有的请求1秒结束,有的请求可能10秒才结束(业务程序及配置不同),因此,网站并发不是客户端每秒的并发请求数,而是服务器在一段时间内(1秒或者数秒内)可以处理的最大连接数,这个连接既包含正在建立的连接,也包含已经建立的连接。
例如:某网站的并发是5000
意味着:单位时间内(理解为1秒或数秒内),正在处理的连接数,正在建立的连接数。加起来一共是5000个。
- [x] Concurrent User表示网站并发用户总数。
- [x] Request Per Second [RPS]表示每秒请求数(吞吐量)
- [x] Simultaneous Browser connections [SBC]表示并发浏览连接数。
- [x] Thinking Time 表示平均用户思考时间
1.4.7 工作场景:统计并发数的基本方法
1)统计当下时刻的linux的网络连接数并发,netstat -an|grep -i “est”|wc -l
2)nginx web 层 active status
其他服务并发连接
(1)QPS(Query Per Second)每秒查询率
每秒查询率QPS是用于衡量一个特定的查询服务器在规定时间内所处理流量多少的标准。运维工作中,DNS系统以及数据库等服务的查询性能经常用每秒查询率来衡量。
(2)IOPS(Input/Output Operations Per Second)
IOPS即每秒进行读写(I/O)操作的次数,多用于数据库等场合,衡量随机访问的性能。存储端的IOPS性能和主机端的I/O是不同的,IOPS是指存储每秒可接受多少次主机发出的访问,主机的一次I/O需要多次访问存储才可以完成。例如,主机写入一个最小的数据块,也要经过“发送写入请求,写入数据,收到写入确认”等三个步骤,也就是3个存储访问。
如何测试磁盘的存储性能?
1.连续的读写向磁盘中写入大的文件
dd if=/dev/zero of=/tmp/test01.bin bs=1K count=10000
1.4.8 常见企业网站排名及PV/IP访问量
| 网站 | 独立IP万/日 | PV数万/日 | 网站并发级别 |
|---|---|---|---|
| www.51cto.com | 582000 | 1338600 | 10000 |
| www.ganji.com | 17340000 | 13872000 | 10000-30000 |
| www.58.com | 1398000 | 22927200 | 10000-30000 |
| www.weibo.com | 30180000 | 166593600 | 几十万 |
| www.taobao.com | 46620000 | 489510000 | 几十万-百万 |
| www.jd.com | 6108000 | 98949600 | 数万 |
| www.suning.com | 930000 | 7254000 | 10000-30000 |
提示:以上数据于大约2015年7月从第三方http://alexa.chinaz.com/alexa_more.aspx 网站查找所得,仅供读者参考,不同的统计程序差别也很大,有一定误差,实际最高日访问量要比此表大,因为网站访问量也节假日等有关,另外统计的误差和chinaz.com的统计方法有关,后面的最大并发以及机器数量级别为作者根据访问量及业务类型估算而来,不代表网站的实际情况,仅对初学者是一个参考。
1.4.9 有关网站度量Linux企业运维常见面试题
常见面试题如下:
- 请问你们的网站并发是多少?
- 你们公司网站访问量是多少?怎么计算?
一定要理解IP,PV,并发量这3个点的知识,在回答时才能有的放失,这三个点的多少决定面试时说多大的架构,对于没有经验的新手不能在说有几万的PV时,还说数十台的集群架构,这样就乌龙了。
- 运维部分日志分析
- 开发在页面嵌入JS程序统计收集,分析
- 运营市场通过第三方公司提供的工具程序统计,例如:GA统计
1.5 www服务软件介绍
1.5.1 www软件全球使用排名参考
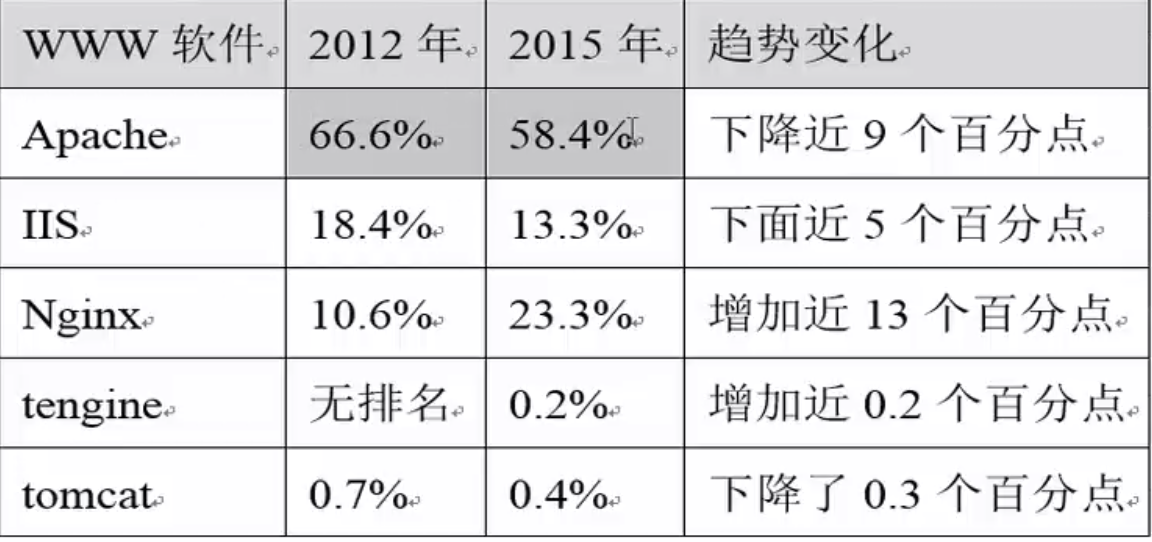
从上述趋势变化不难发现,Apache虽然份额最大,但是有逐年下降趋势,而这个Nginx后起之秀上升趋势显著,另外,Nginx的分支Tengine也从看不见身影到逐渐占有一定份额了。
1.5.2 当前互联网主流Web服务说明
常用来提供静态Web服务的软件:
- Apache:这是中小型Web服务的主流,Web服务器中的老大哥。
- Nginx:大型网站Web服务主流,曾经Web服务器中的初生牛犊,现已长大。Nginx的分支tengine(http://tengine.taobao.org/)目前也在飞速发展。
- Lighttpd:这是一个不温不火的优秀的Web软件,社区不活跃,静态解析效率很高。在Nginx流行前,它是大并发静态业务的首选,国内百度贴吧,豆瓣等众多网站都有lighttpd奋斗的身影。
常用来提供动态服务的软件
- PHP(fastcgi):大中小型网站都会使用,动态网页语言PHP程序的解析容器。它可配合Apache解析动态程序,不过,这里的PHP不是Fastcgi守护进程模式,而是mod_php5.so(module).也可配合Nginx解析动态程序,此时的PHP常用Fastcgi守护进程模式提供服务。
- tomcat:中小企业动态Web服务主流,互联网Java容器主流(如jsp,do)
- resin:大型动态Web服务主流,互联网Java容器主流(如jsp,do)
- IIS(internet information services):微软Windows下的Web服务软件(asp,.aspx)
1.5.3 www 静态程序服务软件apache
- Apache软件有几个重要的版本系列,分别为:Apache1.3,Apache2.0,Apache2.2,Apache2.4等,其中,APache1.3和Apache2.0系列已经成为过去时,官方的网站也看不见其踪影了,目前主流的Apache为2.2系列,正在向Apache2.4系列过渡阶段。如果没有特别要求,建议读者当下使用Apache2.2系列。
官方地址:http://www.apache.org/
1.5.4 www静态服务软件Nginx
Nginx的版本只有一个系列,但是版本更新很快,仅仅半年就有数个版本,这也看出来社区的活跃程序。具体内容参见文档地址:http://www.nginx.org/以及http://www.nginx.org/en/docs/
1.5.5 www 动态服务软件Resin
Resin官方号称是世界上最快的Web服务,是大型动态Web服务主流,为互联网Java程序的解析容器,百度,人人都曾用过Resin
目前企业用的较多的是3.1系列,正在向4.0过度
1.5.6 www动态服务软件tomcat
tomcat一直是中小企业动态Web服务的主流,常用作解析Java的程序的容器,其版本发展变化如下表。
| Servlet/JSP Spec | Apache Tomcat version | Actual release revision | Mininum Java Version |
|---|---|---|---|
| 3.0/2.2 | 7.0.x | 7.0.26 | 1.6 |
| 2.5/2.1 | 6.0.x | 6.0.35 | 1.5 |
| 2.4/2.0 | 5.5.x | 5.5.35 | 1.4 |
| 2.3/1.2 | 4.1.x(archived) | 4.1.40(archived) | 1.3 |
| 2.2/1.1 | 3.3.x(archived) | 3.3.2(archived) | 1.1 |
目前企业使用的主流版本有6系列和7系列,官方也已经推出了更新的8.0系列
tomcat官方地址:
http://tomcat.apache.org/whicheversion.html
http://tomcat.apache.org/
1.5.7 www动态服务软件PHP
- PHP软件是大中小型网站程序前台页面开发的首选,存世开源软件众多,也是中小企业网站开发的首选,它是动态网页语言PHP程序的解析容器。PHP的版本系列有PHP5.2,PHP5.3,PHP5.4,PHP5.5,PHP5.6,其中最经典的版本为PHP5.2系列,企业应用的主流版本可以说是百花争艳。
- 值得注意的是PHP提供解析的方式,在配合Apache解析动态程序时,用的是mod_php5.so(module)模块的方式:在配合nginx解析动态程序时,常用Fastcgi守护进程模式提供服务。
1.6 本章重点回顾
- 用户访问网站基本流程
- DNS系统解析原理
- HTTP协议通信原理,包括HTTP协议,请求报文,响应报文,状态码等相关知识
- 动态,静态概念特点以及伪静态技术;
- 动态转静态Web优化方案
- IP,PV,UV的概念和区别
- 并发的概念理解
- 了解常用www服务软件特点,如Apache,Nginx,PHP(Fastcgi),tomcat,Resin等
1.7 本章知识相关面试考试题
1)请描述DNS系统的解析原理?
2)请描述HTTP协议的工作原理?
3)请问你的公司的网站访问量是多少?
4)请说出http状态吗200,301,403,404,500,502,504代表的意义?
附录1:记录一次linux线上服务器被黑时间
(1),原因:
本来在家正常休息,突然远程托管的机房的线上服务器蹦了远程不了,服务启动不了,然后让上海机房重启了一次,还是直接挂了,一直到我远程上才行。
(2)现象
远程服务器发现出现这类信息
Hi, please view: http://pastie.org/pastes/10800563/text?key=hzzm4hk4ihwx1jfxzfizzq for further information in regards to your files!
Hi, please view: http://pastie.org/pastes/10800563/text?key=hzzm4hk4ihwx1jfxzfizzq for further information in regards to your files!
Hi, please view: http://pastie.org/pastes/10800563/text?key=hzzm4hk4ihwx1jfxzfizzq for further information in regards to your files!
Hi, please view: http://pastie.org/pastes/10800563/text?key=hzzm4hk4ihwx1jfxzfizzq for further information in regards to your files!
Hi, please view: http://pastie.org/pastes/10800563/text?key=hzzm4hk4ihwx1jfxzfizzq for further information in regards to your files!
Hi, please view: http://pastie.org/pastes/10800563/text?key=hzzm4hk4ihwx1jfxzfizzq for further information in regards to your files!登录信息
然后FQ去了国外网站查看
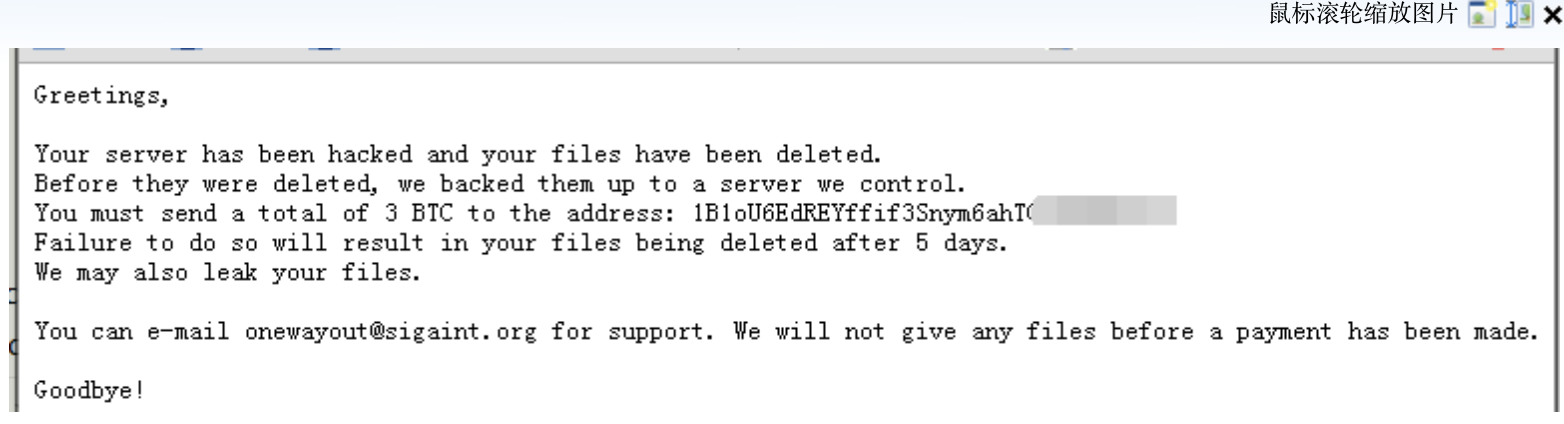
Greetings,
Your server has been hacked and your files have been deleted.
Before they were deleted, we backed them up to a server we control.
You must send a total of 3 BTC to the address: 1B1oU6EdREYffif3**********
Failure to do so will result in your files being deleted after 5 days.
We may also leak your files.
You can e-mail onewayout@sigaint.org for support. We will not give any files before a payment has been made.
Goodbye!
发现被黑!!!
(3).开始排查:
首先检查日志,以前做过安全运维,所以写过类似于检查命令和工具,开始一一排查。
#查看是否为管理员增加或者修改
find / -type f -perm 4000
#显示文件中查看是否存在系统以外的文件
rpm -Vf /bin/ls
rpm -Vf /usr/sbin/sshd
rpm -Vf /sbin/ifconfig
rpm -Vf /usr/sbin/lsof
#检查系统是否有elf文件被替换
#在web目录下运行
grep -r "getRuntime" ./
#查看是否有木马
find . -type f -name "*.jsp" | xargs grep -i "getRuntime"
#运行的时候被连接或者被任何程序调用
find . -type f -name "*.jsp" | xargs grep -i "getHostAddress"
#返回ip地址字符串
find . -type f -name "*.jsp" | xargs grep -i "wscript.shell"
#创建WshShell对象可以运行程序、操作注册表、创建快捷方式、访问系统文件夹、管理环境变量
find . -type f -name "*.jsp" | xargs grep -i "gethostbyname"
#gethostbyname()返回对应于给定主机名的包含主机名字和地址信息的hostent结构指针
find . -type f -name "*.jsp" | xargs grep -i "bash"
#调用系统命令提权
find . -type f -name "*.jsp" | xargs grep -i "jspspy"
#Jsp木马默认名字
find . -type f -name "*.jsp" | xargs grep -i "getParameter"
fgrep - R "admin_index.jsp" 20120702.log > log.txt
#检查是否有非授权访问管理日志
#要进中间件所在日志目录运行命令
fgrep - R "and1=1"*.log>log.txt
fgrep - R "select "*.log>log.txt
fgrep - R "union "*.log>log.txt
fgrep - R "../../"*.log >log.txt
fgrep - R "Runtime"*.log >log.txt
fgrep - R "passwd"*.log >log.txt
#查看是否出现对应的记录
fgrep - R "uname -a"*.log>log.txt
fgrep - R "id"*.log>log.txt
fgrep - R "ifconifg"*.log>log.txt
fgrep - R "ls -l"*.log>log.txt
#查看是否有shell攻击
#以root权限执行
cat /var/log/secure
#查看是否存在非授权的管理信息
tail -n 10 /var/log/secure
last cat /var/log/wtmp
cat /var/log/sulog
#查看是否有非授权的su命令
cat /var/log/cron
#查看计划任务是否正常
tail -n 100 ~./bash_history | more
查看临时目录是否存在攻击者入侵时留下的残余文件
ls -la /tmp
ls -la /var/tmp
#如果存在.c .py .sh为后缀的文件或者2进制elf文件。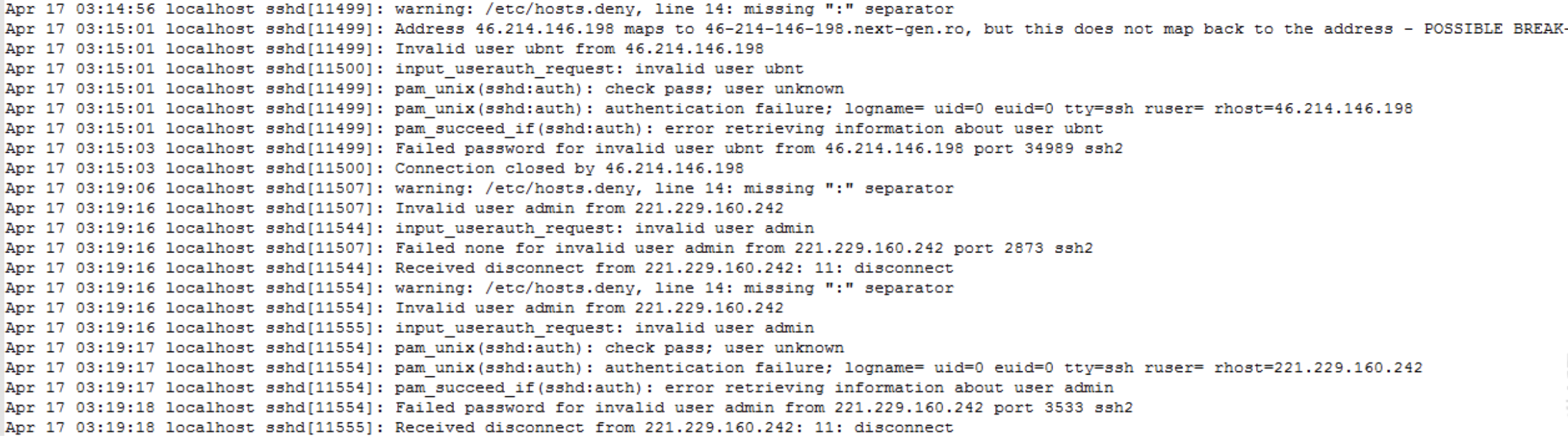

Apr 17 03:14:56 localhost sshd[11499]: warning: /etc/hosts.deny, line 14: missing ":" separator
Apr 17 03:15:01 localhost sshd[11499]: Address 46.214.146.198 maps to 46-214-146-198.next-gen.ro, but this does not map back to the address - POSSIBLE BREAK-IN ATTEMPT!
Apr 17 03:15:01 localhost sshd[11499]: Invalid user ubnt from 46.214.146.198
Apr 17 03:15:01 localhost sshd[11500]: input_userauth_request: invalid user ubnt
Apr 17 03:15:01 localhost sshd[11499]: pam_unix(sshd:auth): check pass; user unknown
Apr 17 03:15:01 localhost sshd[11499]: pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=46.214.146.198
Apr 17 03:15:01 localhost sshd[11499]: pam_succeed_if(sshd:auth): error retrieving information about user ubnt
Apr 17 03:15:03 localhost sshd[11499]: Failed password for invalid user ubnt from 46.214.146.198 port 34989 ssh2
Apr 17 03:15:03 localhost sshd[11500]: Connection closed by 46.214.146.198
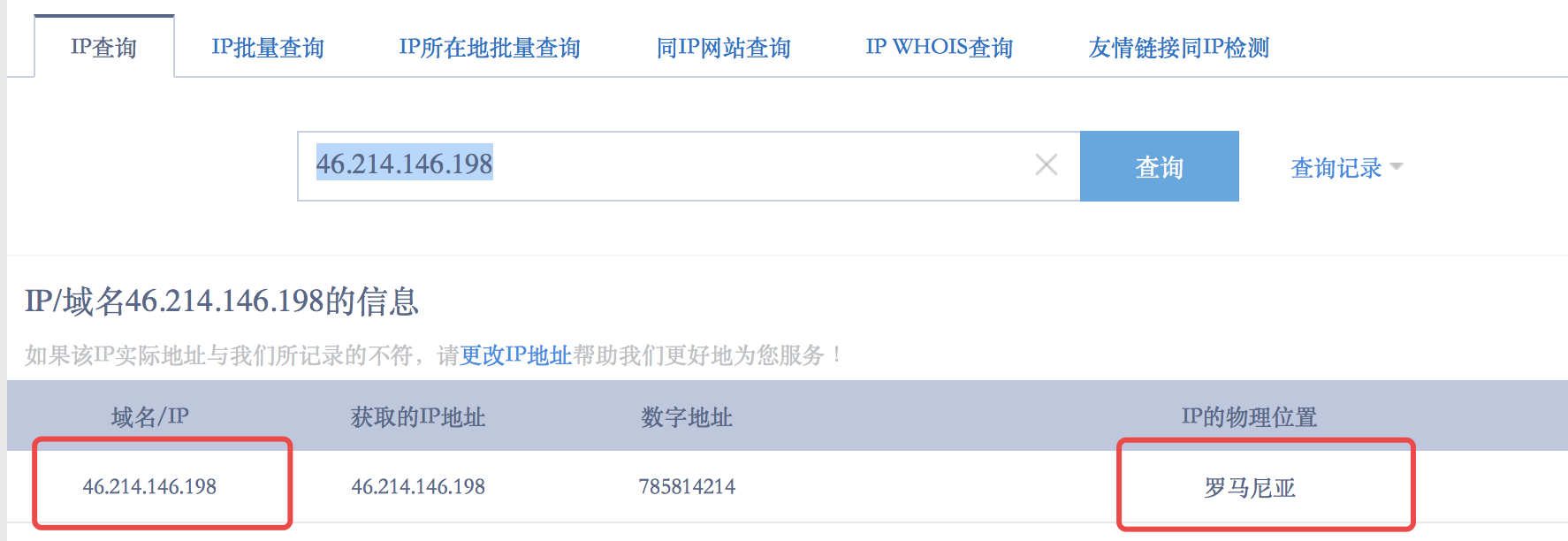
应该就是他了,查看历史记录
日志发现Invalid user ubnt from 46.214.146.198
历史记录和相关访问日志已经删除,痕迹清除
发现没有异常
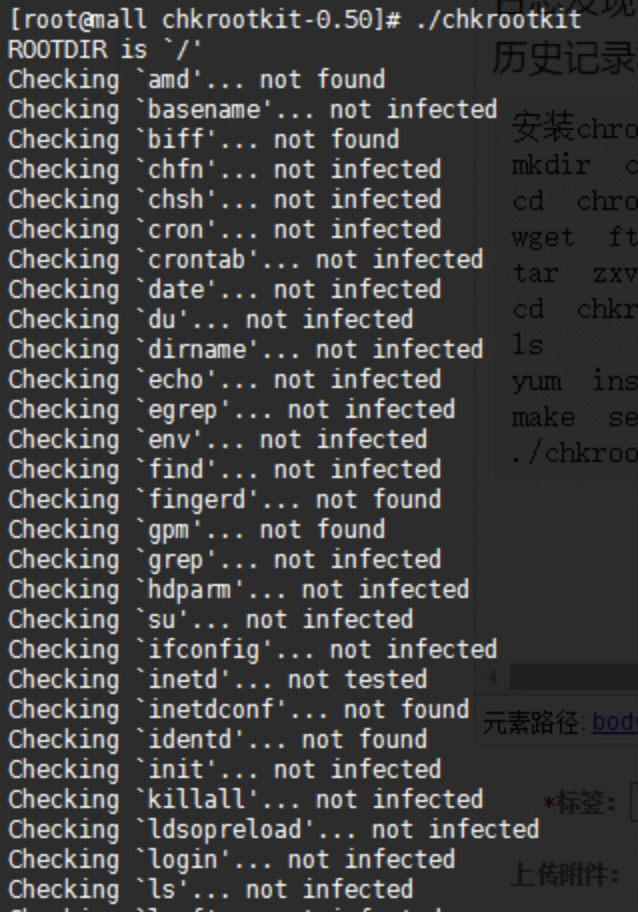
打开vi /etc/motd 发现
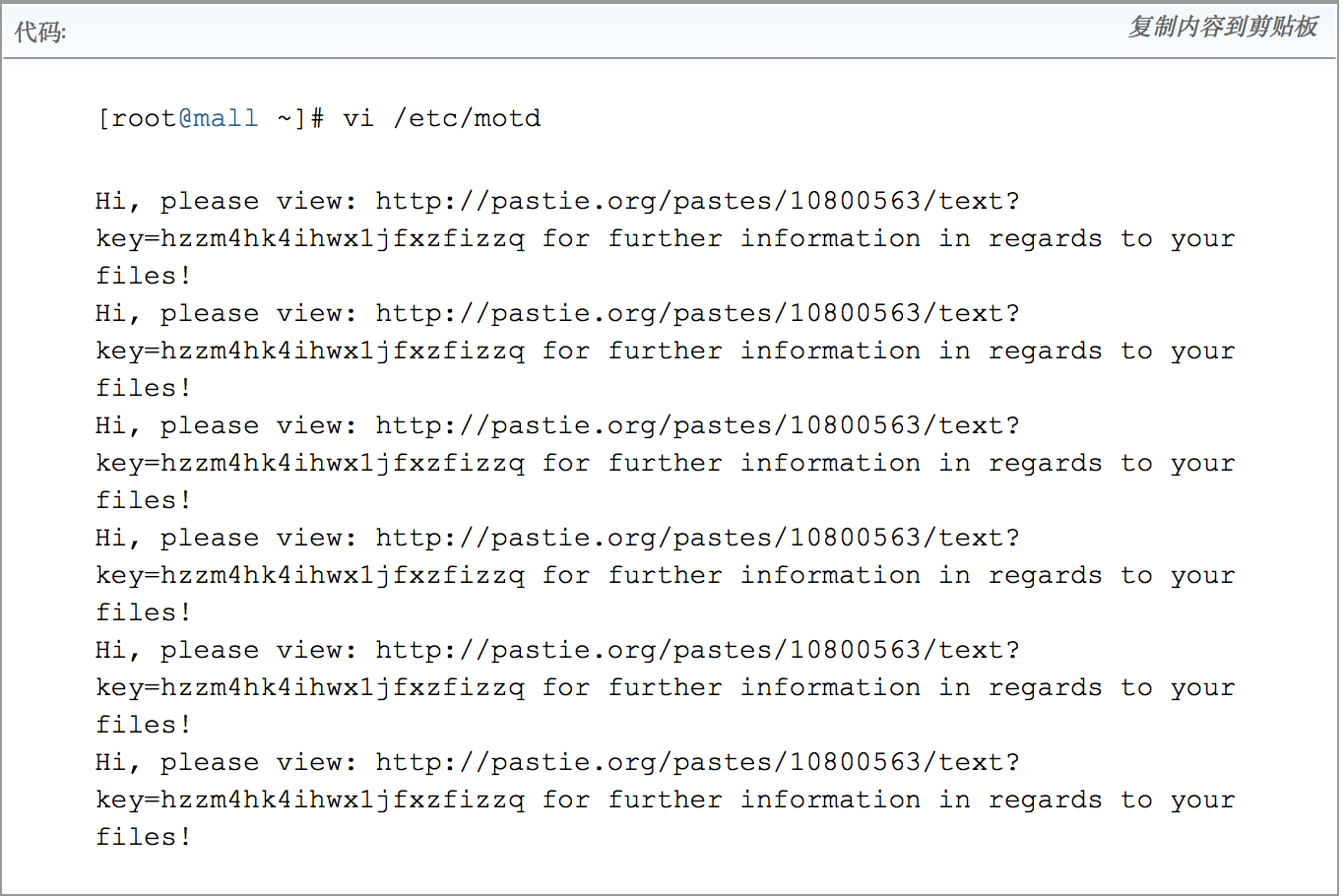
查找不出后门也找不到相关命令,感觉思路受损,晕头转向。
最后查找下单天的web访问日志和相关ip访问
发现一条命令让我好奇,GET /cgi-bin/center.cgi?id=20
HTTP/1.1 ,并且有点异常
感觉很像目前流行的bash shell漏洞,测试一下,果然存在漏洞
env x='() { :;}; echo vulnerable' bash -c "echo this is a test"
[root@mall ~]# env x='() { :;}; echo vulnerable' bash -c "echo this is a test"
vulnerable
this is a test(4) 修复升级命令
yum -y install yum-downloadonly
yum -y install bash-4.1.2-33.el6_7.1x86_64.rpm(5)完成后做了如下措施
- 修改了系统账户密码
- 修改了sshd端口为2220
- 修改了nginx用户nologin
- 发现系统服务器存在bash严重漏洞 破壳漏洞(Shellshock)并修复。
- 更新完成后后面没有发现入侵或者服务器自动挂机现象
(6)漏洞被利用过程
我发送GET请求-->目标服务器cgi路径
目标服务器解析这个get请求,碰到UserAgent后面的参数,Bash解释器就执行了后面的命令
(7)Shellshock介绍
Shellshock,又称Bashdoor,是在Unix中广泛使用的Bash shell中的一个安全漏洞,首次于2014年9月24日公开。许多互联网守护进程,如网页服务器,使用bash来处理某些命令,从而允许攻击者在易受攻击的Bash版本上执行任意代码。这可使攻击者在未授权的情况下访问计算机系统。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号