OpenCV探索之路(五):图片缩放和图像金字塔
对图像进行缩放的最简单方法当然是调用resize函数啦!
resize函数可以将源图像精确地转化为指定尺寸的目标图像。
要缩小图像,一般推荐使用CV_INETR_AREA来插值;若要放大图像,推荐使用CV_INTER_LINEAR。
现在说说调用方式
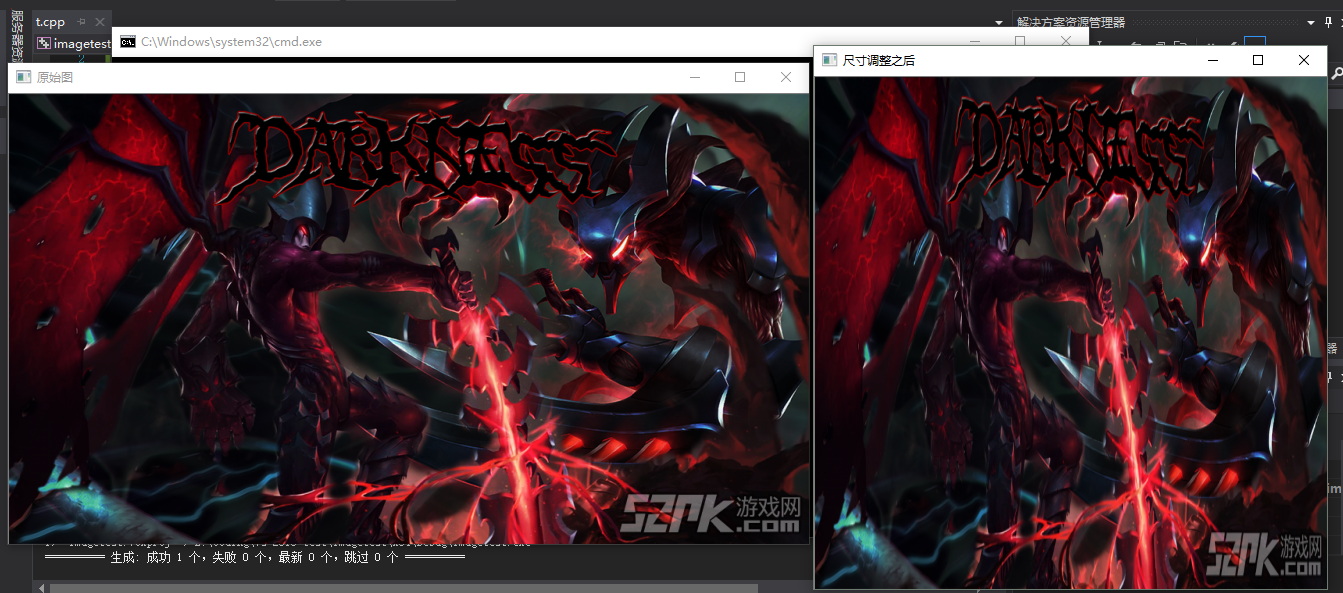
第一种,规定好你要图片的尺寸,就是你填入你要的图片的长和高。
#include<opencv2\opencv.hpp>
#include<opencv2\highgui\highgui.hpp>
using namespace std;
using namespace cv;
//图片的缩小与放大
int main()
{
Mat img = imread("lol5.jpg");
imshow("原始图", img);
Mat dst = Mat::zeros(512, 512, CV_8UC3); //我要转化为512*512大小的
resize(img, dst, dst.size());
imshow("尺寸调整之后", dst);
waitKey(0);
}
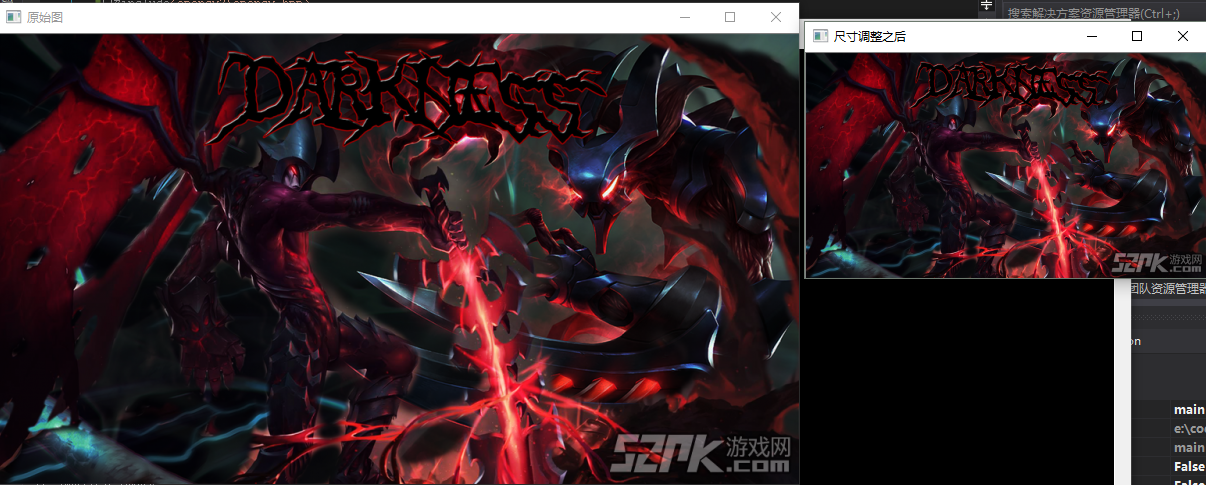
第二种,填入你要缩小或者放大的比率。
#include<opencv2\opencv.hpp>
#include<opencv2\highgui\highgui.hpp>
using namespace std;
using namespace cv;
//图片的缩小与放大
int main()
{
Mat img = imread("lol5.jpg");
imshow("原始图", img);
Mat dst;
resize(img, dst, Size(),0.5,0.5);//我长宽都变为原来的0.5倍
imshow("尺寸调整之后", dst);
waitKey(0);
}
接下来说说图像金字塔
说白了,图像金字塔就是用来进行图像缩放的,干的事情跟resize函数没两样,那我们还需要学它吗?我觉得有必要的额,因为在学习卷积神经网络中会遇到这个名词,所以都学一学吧,搞图形都绕不过他!
说说什么是图像金字塔。
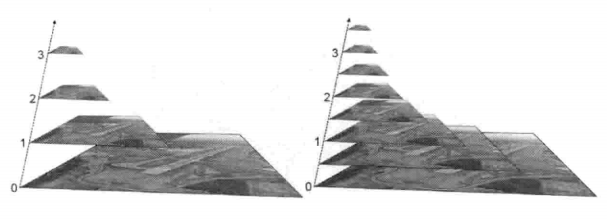
其实非常好理解,如上图所示,我们将一层层的图像比喻为金字塔,层级越高,则图像尺寸越小,分辨率越低。
两种类型的金字塔:
- 高斯金字塔:用于下采样,主要的图像金字塔;
- 拉普拉斯金字塔:用于重建图像,也就是预测残差(我的理解是,因为小图像放大,必须插入一些像素值,那这些像素值是什么才合适呢,那就得进行根据周围像素进行预测),对图像进行最大程度的还原。比如一幅小图像重建为一幅大图像,
图像金字塔有两个高频出现的名词:上采样和下采样。现在说说他们俩。
- 上采样:就是图片放大(所谓上嘛,就是变大),使用PryUp函数
- 下采样:就是图片缩小(所谓下嘛,就是变小),使用PryDown函数
下采样将步骤:
- 对图像进行高斯内核卷积
- 将所有偶数行和列去除
下采样就是图像压缩,会丢失图像信息。
上采样步骤:
- 将图像在每个方向放大为原来的两倍,新增的行和列用0填充;
- 使用先前同样的内核(乘以4)与放大后的图像卷积,获得新增像素的近似值。
上、下采样都存在一个严重的问题,那就是图像变模糊了,因为缩放的过程中发生了信息丢失的问题。要解决这个问题,就得看拉普拉斯金字塔了。
下面给出OpenCV中pryUp和pryDown的用法。
#include<opencv2\opencv.hpp>
#include<opencv2\highgui\highgui.hpp>
using namespace std;
using namespace cv;
//图像金字塔
int main()
{
Mat img = imread("lol8.jpg");
imshow("原始图", img);
Mat dst,dst2;
pyrUp(img, dst, Size(img.cols*2, img.rows*2)); //放大一倍
pyrDown(img, dst2, Size(img.cols * 0.5, img.rows * 0.5)); //缩小为原来的一半
imshow("尺寸放大之后", dst);
imshow("尺寸缩小之后", dst2);
waitKey(0);
}
显然,无论是放大还是缩小,图像都变得模糊了,这就是他的致命缺点。

个人认为,要做缩放就用resize函数吧,毕竟方便太多而且图像不会变模糊!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号