kubernetes相关概念
kubernetes基础概念
Node
Node是Pod真正运行的主机,可以物理机,也可以是虚拟机。为了管理Pod,每个Node节点上至少要运行container runtime(比如docker或者rkt)、kubelet和kube-proxy服务。
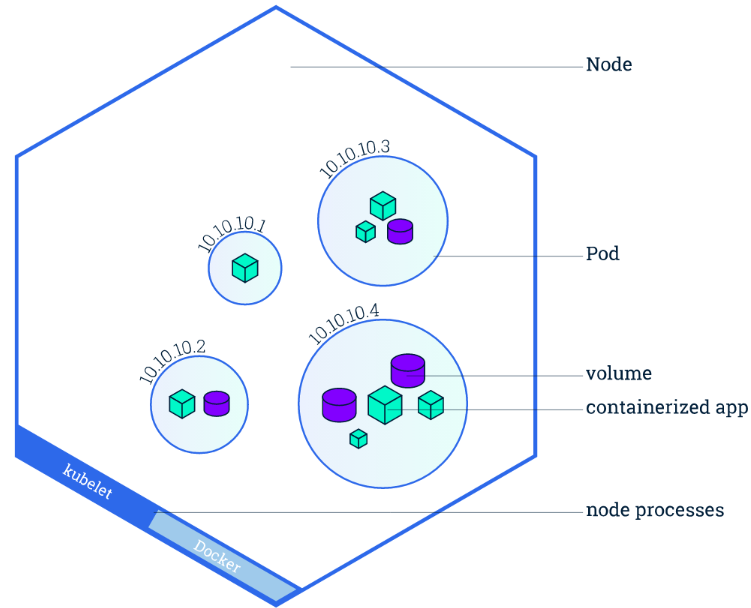
不像其他的资源(如Pod和Namespace),Node本质上不是Kubernetes来创建的,Kubernetes只是管理Node上的资源。虽然可以通过Manifest创建一个Node对象(如下json所示),但Kubernetes也只是去检查是否真的是有这么一个Node,如果检查失败,也不会往上调度Pod。
这个检查是由Node Controller来完成的。Node Controller负责
- 维护Node状态
- 与Cloud Provider同步Node
- 给Node分配容器CIDR
- 删除带有NoExecute taint的Node上的Pods
默认情况下,kubelet在启动时会向master注册自己,并创建Node资源。
Node的状态
每个Node都包括以下状态信息
- 地址:包括hostname、外网IP和内网IP
- 条件(Condition):包括OutOfDisk、Ready、MemoryPressure和DiskPressure
- 容量(Capacity):Node上的可用资源,包括CPU、内存和Pod总数
- 基本信息(Info):包括内核版本、容器引擎版本、OS类型等
Pod
Pod 是一组紧密关联的容器集合,它们共享 IPC、Network 和 UTS namespace,是 Kubernetes 调度的基本单位。Pod 的设计理念是支持多个容器在一个 Pod 中共享网络和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务。
Pod 的特征
- 包含多个共享 IPC、Network 和 UTC namespace 的容器,可直接通过 localhost 通信
- 所有 Pod 内容器都可以访问共享的 Volume,可以访问共享数据
- 无容错性:直接创建的 Pod 一旦被调度后就跟 Node 绑定,即使 Node 挂掉也不会被重新调度(而是被自动删除),因此推荐使用 Deployment、Daemonset 等控制器来容错
- 优雅终止:Pod 删除的时候先给其内的进程发送 SIGTERM,等待一段时间(grace period)后才强制停止依然还在运行的进程
- 特权容器(通过 SecurityContext 配置)具有改变系统配置的权限(在网络插件中大量应用)
label
标签其实就一对 key/value ,被关联到对象上,比如Pod,标签的使用我们倾向于能够标示对象的特殊特点,并且对用户而言是有意义的(就是一眼就看出了这个Pod是尼玛数据库),但是标签对内核系统是没有直接意义的。标签可以用来划分特定组的对象(比如,所有ssd设备),标签可以在创建一个对象的时候直接给与,也可以在后期随时修改,每一个对象可以拥有多个标签,但是,key值必须是唯一的。
合法的label值必须是63个或者更短的字符。要么是空,要么首位字符必须为字母数字字符,中间必须是横线,下划线,点或者数字字母。
与name和UID不同,label不提供唯一性。通常,我们会看到很多对象有着一样的label。
通过label选择器,客户端/用户能方便辨识出一组对象。label选择器是kubernetes中核心的组织原语。
API目前支持两种选择器:基于相等的和基于集合的。一个label选择器一可以由多个必须条件组成,由逗号分隔。在多个必须条件指定的情况下,所有的条件都必须满足,因而逗号起着AND逻辑运算符的作用。
一个空的label选择器(即有0个必须条件的选择器)会选择集合中的每一个对象。
一个null型label选择器(仅对于可选的选择器字段才可能)不会返回任何对象。
Namespace
Namespace是对一组资源和对象的抽象集合,比如可以用来将系统内部的对象划分为不同的项目组或用户组。常见的pods, services, replication controllers和deployments等都是属于某一个namespace的(默认是default),而node, persistentVolumes等则不属于任何namespace。
Namespace常用来隔离不同的用户,比如Kubernetes自带的服务一般运行在kube-system namespace中。
kubectl可以通过–namespace或者-n选项指定namespace。如果不指定,默认为default。查看操作下,也可以通过设置–all-namespace=true来查看所有namespace下的资源。
查看namespace
$ kubectl get namespaces NAME STATUS AGE default Active 11d kube-system Active 11d
注意:namespace包含两种状态”Active”和”Terminating”。在namespace删除过程中,namespace状态被设置成”Terminating”。
创建namespace
(1) 命令行直接创建 $ kubectl create namespace new-namespace (2) 通过文件创建 $ cat my-namespace.yaml apiVersion: v1 kind: Namespace metadata: name: new-namespace $ kubectl create -f ./my-namespace.yaml
删除namespace
$ kubectl delete namespaces new-namespace
注意:
- 删除一个namespace会自动删除所有属于该namespace的资源。
- default和kube-system命名空间不可删除。
kubernetes资源控制
HPA
Horizontal Pod Autoscaling (HPA) 可以根据 CPU 使用率或应用自定义 metrics 自动扩展 Pod 数量(支持 replication controller、deployment 和 replica set )。
- 控制管理器每隔 30s(可以通过
--horizontal-pod-autoscaler-sync-period修改)查询 metrics 的资源使用情况 - 支持三种 metrics 类型
- 预定义 metrics(比如 Pod 的 CPU)以利用率的方式计算
- 自定义的 Pod metrics,以原始值(raw value)的方式计算
- 自定义的 object metrics
- 支持两种 metrics 查询方式:Heapster 和自定义的 REST API
- 支持多 metrics
Replication Controller(RC)
Replication Controller 保证了在所有时间内,都有特定数量的Pod副本正在运行,如果太多了,Replication Controller就杀死几个,如果太少了,Replication Controller会新建几个,和直接创建的pod不同的是,Replication Controller会替换掉那些删除的或者被终止的pod,不管删除的原因是什么(维护阿,更新啊,Replication Controller都不关心)。基于这个理由,我们建议即使是只创建一个pod,我们也要使用Replication Controller。Replication Controller 就像一个进程管理器,监管着不同node上的多个pod,而不是单单监控一个node上的pod,Replication Controller 会委派本地容器来启动一些节点上服务(Kubelet ,Docker)。
replication controller的任务永远都只会是单一的。它自身不会进行是否可读和是否可用的检测,相比与自动进行缩放和放大,replication controller更倾向与使用外部的自动平衡工具,这些外部工具要作的仅仅是修改replicas的值来实现Pod数量的变化,我们不会增加replication controller的调度策率,也不会让replication controller来验证受控的Pod是否符合特定的模版,因为这些都会阻碍自动调整和其它的自动的进程。类似的,完成时限,需求依赖,配置扩展,等等都属于其它的部分。
Taints和tolerations
Taints和tolerations用于保证Pod不被调度到不合适的Node上,Taint应用于Node上,而toleration则应用于Pod上(Toleration是可选的)。
比如,可以使用taint命令给node1添加taints:
kubectl taint nodes node1 key1=value1:NoSchedule
kubectl taint nodes node1 key1=value2:NoExecute
Taints和tolerations的具体使用方法请参考调度器章节。
Node维护模式
标志Node不可调度但不影响其上正在运行的Pod,这种维护Node时是非常有用的
kubectl cordon $NODENAM
ReplicaSet(RS)
什么是ReplicaSet?
ReplicaSet是下一代复本控制器。ReplicaSet和 Replication Controller之间的唯一区别是现在的选择器支持。Replication Controller只支持基于等式的selector(env=dev或environment!=qa),但ReplicaSet还支持新的,基于集合的selector(version in (v1.0, v2.0)或env notin (dev, qa))。在试用时官方推荐ReplicaSet。
大多数kubectl支持Replication Controller的命令也支持ReplicaSets。rolling-update命令有一个例外 。如果您想要滚动更新功能,请考虑使用Deployments。此外, rolling-update命令是必须的,而Deployments是声明式的,因此我们建议通过rollout命令使用Deployments。
虽然ReplicaSets可以独立使用,但是今天它主要被 Deployments 作为协调pod创建,删除和更新的机制。当您使用Deployments时,您不必担心管理他们创建的ReplicaSets。Deployments拥有并管理其ReplicaSets。
何时使用ReplicaSet?
ReplicaSet可确保指定数量的pod“replicas”在任何设定的时间运行。然而,Deployments是一个更高层次的概念,它管理ReplicaSets,并提供对pod的声明性更新以及许多其他的功能。因此,我们建议您使用Deployments而不是直接使用ReplicaSets,除非您需要自定义更新编排或根本不需要更新。
这实际上意味着您可能永远不需要操作ReplicaSet对象:直接使用Deployments并在规范部分定义应用程序。
Services
Kubernetes Pod是平凡的,它门会被创建,也会死掉(生老病死),并且他们是不可复活的。 ReplicationControllers动态的创建和销毁Pods(比如规模扩大或者缩小,或者执行动态更新)。每个pod都由自己的ip,这些IP也随着时间的变化也不能持续依赖。这样就引发了一个问题:如果一些Pods(让我们叫它作后台,后端)提供了一些功能供其它的Pod使用(让我们叫作前台),在kubernete集群中是如何实现让这些前台能够持续的追踪到这些后台的?
答案是:Service
Kubernete Service 是一个定义了一组Pod的策略的抽象,我们也有时候叫做宏观服务。这些被服务标记的Pod都是(一般)通过label Selector决定的(下面我们会讲到我们为什么需要一个没有label selector的服务)
举个例子,我们假设后台是一个图形处理的后台,并且由3个副本。这些副本是可以相互替代的,并且前台并需要关心使用的哪一个后台Pod,当这个承载前台请求的pod发生变化时,前台并不需要直到这些变化,或者追踪后台的这些副本,服务是这些去耦.
对于Kubernete原生的应用,Kubernete提供了一个简单的Endpoints API,这个Endpoints api的作用就是当一个服务中的pod发生变化时,Endpoints API随之变化,对于哪些不是原生的程序,Kubernetes提供了一个基于虚拟IP的网桥的服务,这个服务会将请求转发到对应的后台pod。
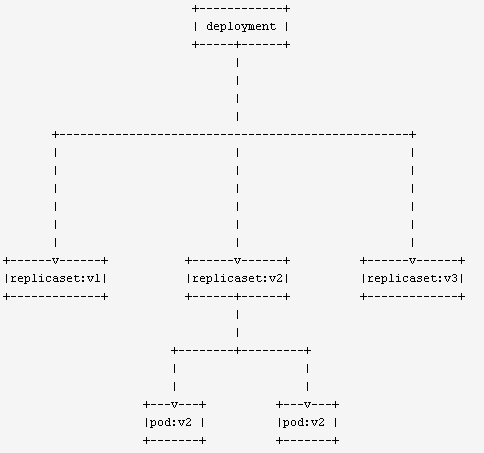
Deployment
Deployment负责控制Pod的生命周期、保证服务有一定数量的Pod在运行。Deployment定义了Pod内容,包括Pod数量、更新方式、使用的镜像,资源限制等等。
● deployment调度replicaset,pod由replicaset调度
● deployment管理多个replicaset版本,可用于回滚
● replicaset控制pod的行为,包括新增pod、删除pod
StatefullSet
使用Deployment创建的Pod是无状态的,当挂在Volume之后,如果该Pod挂了,Replication Controller会再run一个来保证可用性,但是由于是无状态的,Pod挂了的时候与之前的Volume的关系就已经断开了,新起来的Pod无法找到之前的Pod。但是对于用户而言,他们对底层的Pod挂了没有感知,但是当Pod挂了之后就无法再使用之前挂载的磁盘了。
解决方案?
使用K8s v1.5版本推出的StatefulSet可以保留Pod的状态。
StatefulSet本质上是Deployment的一种变体,在v1.9版本中已成为GA版本,它为了解决有状态服务的问题,它所管理的Pod拥有固定的Pod名称、启停顺序;在StatefulSet中,Pod名字称为网络标识(hostname),还必须要用到共享存储。
在Deployment中,与之对应的服务是service,而在StatefulSet中与之对应的headless service,headless service,即无头服务,与service的区别就是它没有Cluster IP,解析它的名称时将返回该Headless Service对应的全部Pod的Endpoint列表。
以redis cluster为例,由于各redis container 的角色不一定相同(有master、slave之分),所以每个redis container被重建之后必须保持原有的hostname,必须挂载原有的volume,这样才能保证每个shard内是正常的。而且每个redis shard 所管理的slot不同,存储的数据不同,所以要求每个redis shard 所连接的存储不同,保证数据不会被覆盖或混乱。(注:在Deployment中 Pod template里定义的存储卷,所有副本集共用一个存储卷,数据是相同的,因为Pod创建时基于同一模板生成)
为了保证container所挂载的volume不会出错,k8s引入了volumeClaimTemplate。
所以具有以下特性的应用使用statefullSet:
1)、稳定且唯一的网络标识符;
2)、稳定且持久的存储;
3)、有序、平滑地部署和扩展;
4)、有序、平滑的终止和删除;
5)、有序的滚动更新;
对于一个完整的StatefulSet应用由三个部分组成: headless service、StatefulSet controller、volumeClaimTemplate。
DaemonSet
DaemonSet 可以保证集群中所有的或者部分的节点都能够运行同一份 Pod 副本,每当有新的节点被加入到集群时,Pod 就会在目标的节点上启动,如果节点被从集群中剔除,节点上的 Pod 也会被垃圾收集器清除;
DaemonSet 的作用就像是计算机中的守护进程,它能够运行集群存储、日志收集和监控等『守护进程』,这些服务一般是集群中必备的基础服务。
Deployment 部署的副本 Pod 会分布在各个 Node 上,每个 Node 都可能运行好几个副本。
DaemonSet 的不同之处在于:每个 Node 上最多只能运行一个副本。
DaemonSet 的典型应用场景有:
-
在集群的每个节点上运行存储 Daemon,比如 glusterd 或 ceph。
-
在每个节点上运行日志收集 Daemon,比如 flunentd 或 logstash。
-
在每个节点上运行监控 Daemon,比如 Prometheus Node Exporter 或 collectd。
CrontJob
CronJob即定时任务,就类似于Linux系统的crontab,在指定的时间周期运行指定的任务。在Kubernetes 1.5,使用CronJob需要开启batch/v2alpha1 API,即–runtime-config=batch/v2alpha1。
CronJob Spec
- .spec.schedule指定任务运行周期,格式同Cron
- .spec.jobTemplate指定需要运行的任务,格式同Job
- .spec.startingDeadlineSeconds指定任务开始的截止期限
- .spec.concurrencyPolicy指定任务的并发策略,支持Allow、Forbid和Replace三个选项
apiVersion: batch/v2alpha1
kind: CronJob
metadata:
name: cronjob-demo
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- name: hello
image: busybox
args:
- "bin/sh"
- "-c"
- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
Job
Kubernetes 中的 Job 可以创建并且保证一定数量 Pod 的成功停止,当 Job 持有的一个 Pod 对象成功完成任务之后,Job 就会记录这一次 Pod 的成功运行;当一定数量的Pod 的任务执行结束之后,当前的 Job 就会将它自己的状态标记成结束。

apiVersion: batch/v1
kind: Job
metadata:
name: job-demo
spec:
template:
metadata:
name: job-demo
spec:
restartPolicy: Never
containers:
- name: counter
image: busybox
command:
- "bin/sh"
- "-c"
- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
Resource Quotas
资源配额(Resource Quotas)是用来限制用户资源用量的一种机制。
它的工作原理为
- 资源配额应用在Namespace上,并且每个Namespace最多只能有一个ResourceQuota对象
- 开启计算资源配额后,创建容器时必须配置计算资源请求或限制(也可以用LimitRange设置默认值)
- 用户超额后禁止创建新的资源
资源配额的启用
首先,在API Server启动时配置ResourceQuota adminssion control;然后在namespace中创建ResourceQuota对象即可。
资源配额的类型
- 计算资源,包括cpu和memory
- cpu, limits.cpu, requests.cpu
- memory, limits.memory, requests.memory
- 存储资源,包括存储资源的总量以及指定storage class的总量
- requests.storage:存储资源总量,如500Gi
- persistentvolumeclaims:pvc的个数
- .storageclass.storage.k8s.io/requests.storage
- .storageclass.storage.k8s.io/persistentvolumeclaims
- 对象数,即可创建的对象的个数
- pods, replicationcontrollers, configmaps, secrets
- resourcequotas, persistentvolumeclaims
- services, services.loadbalancers, services.nodeports
kubernetes网络管理
NetWork Policy
Network Policy提供了基于策略的网络控制,用于隔离应用并减少攻击面。它使用标签选择器模拟传统的分段网络,并通过策略控制它们之间的流量以及来自外部的流量。
在使用Network Policy之前,需要注意
- apiserver开启extensions/v1beta1/networkpolicies
- 网络插件要支持Network Policy,如Calico、Romana、Weave Net和trireme等
策略
1、Namespace隔离
默认情况下,所有Pod之间是全通的。每个Namespace可以配置独立的网络策略,来隔离Pod之间的流量。比如隔离namespace的所有Pod之间的流量(包括从外部到该namespace中所有Pod的流量以及namespace内部Pod相互之间的流量):
kubectl annotate ns <namespace> "net.beta.kubernetes.io/network-policy={\"ingress\": {\"isolation\": \"DefaultDeny\"}}"
注:目前,Network Policy仅支持Ingress流量控制。
2、Pod隔离
通过使用标签选择器(包括namespaceSelector和podSelector)来控制Pod之间的流量。比如下面的Network Policy
- 允许default namespace中带有role=frontend标签的Pod访问default namespace中带有role=db标签Pod的6379端口
- 允许带有project=myprojects标签的namespace中所有Pod访问default namespace中带有role=db标签Pod的6379端口
apiVersion: extensions/v1beta1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
ingress:
- from:
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: tcp
port: 6379
Ingress
什么是Ingress?
通常情况下,service和pod的IP仅可在集群内部访问。集群外部的请求需要通过负载均衡转发到service在Node上暴露的NodePort上,然后再由kube-proxy将其转发给相关的Pod。
而Ingress就是为进入集群的请求提供路由规则的集合。
Ingress 为 Kubernetes 集群中的服务提供了外部入口以及路由,而 Ingress Controller 监测 Ingress 和 Service 资源的变更并根据规则配置负载均衡、路由规则和 DNS 等并提供访问入口。
kubernetes配置管理
ConfigMap
为了把配置文件从image中解耦,增强应用的可移植性、可复用性,k8s提供了configmap和seret。
configmap
configmap就是一系列配置数据的集合。而这些数据将来可以注入到pod中的container中。注入方式有两种:
1)、把configmap做存存储卷,然后挂载;
2)、使用ENV的valueFrom方式去引用configmap中所保存的数据。
configmap中保存着k:v格式的数据。value长度没有限制。pod启动时可以到configmap中获取相关的配置项
Secret
Secret是用来保存小片敏感数据的k8s资源,例如密码,token,或者秘钥。这类数据当然也可以存放在Pod或者镜像中,但是放在Secret中是为了更方便的控制如何使用数据,并减少暴露的风险。
kubernetes存储控制
Volumes
容器中的磁盘的生命周期是短暂的,这就带来了一系列的问题,第一,当一个容器损坏之后,kubelet 会重启这个容器,但是文件会丢失-这个容器会是一个全新的状态,第二,当很多容器在同一Pod中运行的时候,很多时候需要数据文件的共享。Kubernete Volume解决了这个问题
Docker有一个Volumes的概念,虽然这个Volume有点宽松和管理性比较小。在Docker中,一个 Volume 是一个简单的所在主机的一个目录或者其它容器中的。生命周期是没有办法管理,直到最近才有 local-disk-backed 磁盘。Docker现在提供了磁盘驱动,但是功能非常有限(例如Docker1.7只能挂在一个磁盘每个容器,并且无法传递参数)
从另外一个方面讲,一个Kubernetes volume,拥有明确的生命周期,与所在的Pod的生命周期相同。因此,Kubernetes volume独立与任何容器,与Pod相关,所以数据在重启的过程中还会保留,当然,如果这个Pod被删除了,那么这些数据也会被删除。更重要的是,Kubernetes volume 支持多种类型,任何容器都可以使用多个Kubernetes volume。
它的核心,一个 volume 就是一个目录,可能包含一些数据,这些数据对pod中的所有容器都是可用的,这个目录怎么使用,什么类型,由什么组成都是由特殊的volume 类型决定的
想要使用一个volume,Pod必须指明Pod提供了那些磁盘,并且说明如何挂在到容器中。
Kubernete 支持如下类型的volume:
emptyDir hostPath gcePersistentDisk awsElasticBlockStore nfs iscsi glusterfs rbd gitRepo secret persistentVolumeClaim
PV/PVC
PersistentVolume (PV) 和 PersistentVolumeClaim (PVC) 提供了方便的持久化卷:PV 提供网络存储资源,而 PVC 请求存储资源。这样,设置持久化的工作流包括配置底层文件系统或者云数据卷、创建持久性数据卷、最后创建 PVC 来将 Pod 跟数据卷关联起来。PV 和 PVC 可以将 pod 和数据卷解耦,pod 不需要知道确切的文件系统或者支持它的持久化引擎。
Volume 生命周期
Volume 的生命周期包括 5 个阶段
- Provisioning,即 PV 的创建,可以直接创建 PV(静态方式),也可以使用 StorageClass 动态创建
- Binding,将 PV 分配给 PVC
- Using,Pod 通过 PVC 使用该 Volume,并可以通过准入控制 StorageObjectInUseProtection(1.9 及以前版本为 PVCProtection)阻止删除正在使用的 PVC
- Releasing,Pod 释放 Volume 并删除 PVC
- Reclaiming,回收 PV,可以保留 PV 以便下次使用,也可以直接从云存储中删除
- Deleting,删除 PV 并从云存储中删除后段存储
根据这 5 个阶段,Volume 的状态有以下 4 种
- Available:可用
- Bound:已经分配给 PVC
- Released:PVC 解绑但还未执行回收策略
- Failed:发生错误
kubernetes安全管理
Security Context
在运行一个容器时,有时候需要使用sysctl修改内核参数,比如net.、vm.、kernel等,sysctl需要容器拥有超级权限,容器启动时加上--privileged参数即可。那么,在kubernetes中是如何使用的呢
kubernetes中有个字段叫securityContext,即安全上下文,它用于定义Pod或Container的权限和访问控制设置。其设置包括:
- Discretionary Access Control: 根据用户ID(UID)和组ID(GID)来限制其访问资源(如:文件)的权限
- Security Enhanced Linux (SELinux): 给容器指定SELinux labels
- Running as privileged or unprivileged:以
privileged或unprivileged权限运行 - Linux Capabilities: 给某个特定的进程privileged权限,而不用给root用户所有的
privileged权限
Service Account
Service account是为了方便Pod里面的进程调用Kubernetes API或其他外部服务而设计的。它与User account不同
- User account是为人设计的,而service account则是为Pod中的进程调用Kubernetes API而设计;
- User account是跨namespace的,而service account则是仅局限它所在的namespace;
- 每个namespace都会自动创建一个default service account
- Token controller检测service account的创建,并为它们创建secret
- 开启ServiceAccount Admission Controller后
- 每个Pod在创建后都会自动设置spec.serviceAccount为default(除非指定了其他ServiceAccout)
- 验证Pod引用的service account已经存在,否则拒绝创建
- 如果Pod没有指定ImagePullSecrets,则把service account的ImagePullSecrets加到Pod中
- 每个container启动后都会挂载该service account的token和ca.crt到/var/run/secrets/kubernetes.io/serviceaccount/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号