[Flink]Flink1.6三种运行模式安装部署以及实现WordCount
前言
Flink三种运行方式:Local、Standalone、On Yarn。成功部署后分别用Scala和Java实现wordcount
环境
版本:Flink 1.6.2
集群环境:Hadoop2.6
开发工具: IntelliJ IDEA
一.Local模式
解压:tar -zxvf flink-1.6.2-bin-hadoop26-scala_2.11.tgz
cd flink-1.6.2
启动:./bin/start-cluster.sh
停止:./bin/stop-cluster.sh
可以通过master:8081监控集群状态
二.Standalone模式
集群安装
1:修改conf/flink-conf.yaml
jobmanager.rpc.address: hadoop100
2:修改conf/slaves
hadoop101
hadoop102
3:拷贝到其他节点
scp -rq /usr/local/flink-1.6.2 hadoop101:/usr/local
scp -rq /usr/local/flink-1.6.2 hadoop102:/usr/local
4:在hadoop100(master)节点启动
bin/start-cluster.sh
5:访问http://hadoop100:8081
三.Flink On Yarn模式
On Yarn实现逻辑
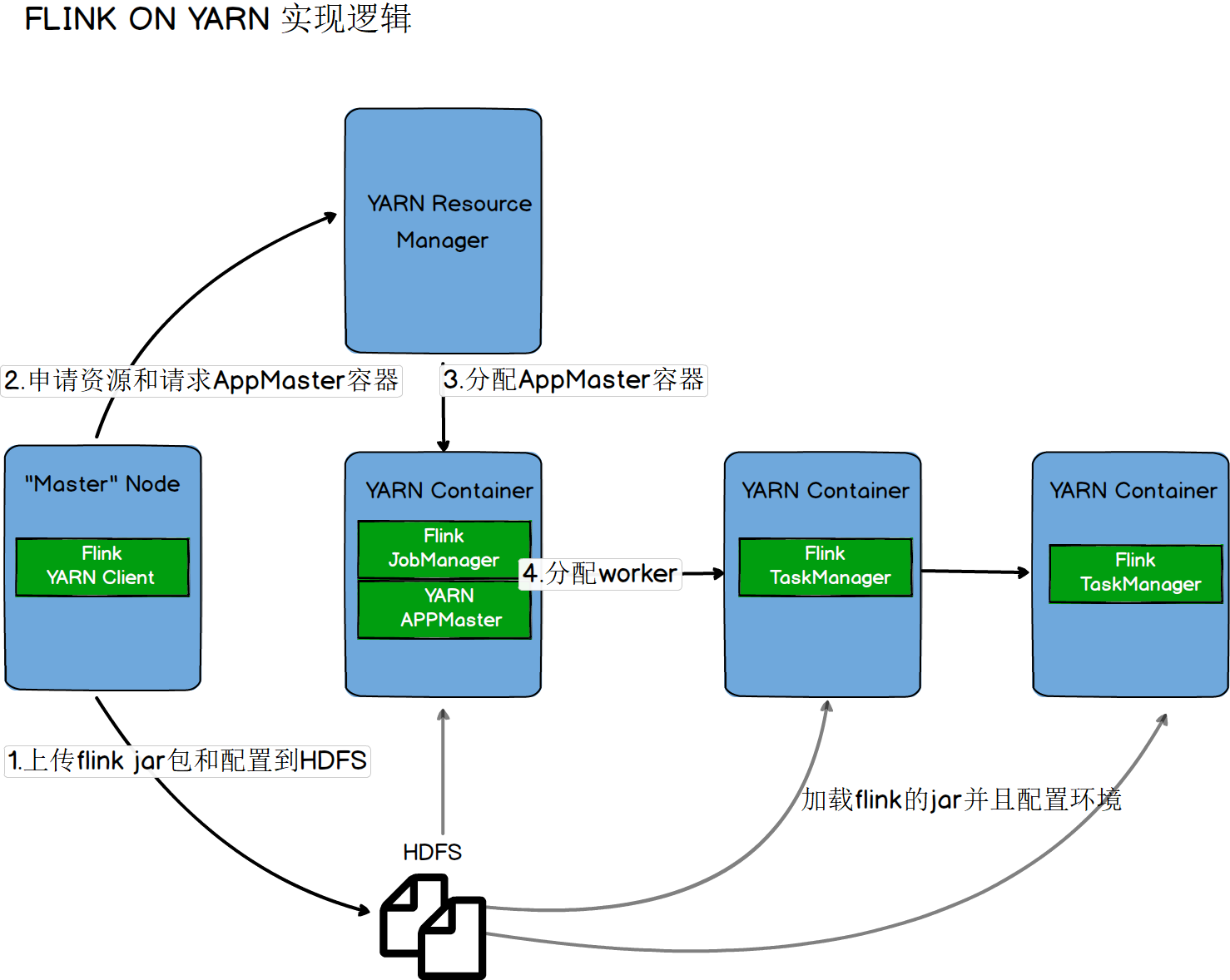 ##### 第一种【yarn-session.sh(开辟资源)+flink run(提交任务)】
启动一个一直运行的flink集群
./bin/yarn-session.sh -n 2 -jm 1024 -tm 1024 [-d]
附着到一个已存在的flink yarn session
./bin/yarn-session.sh -id application_1463870264508_0029
执行任务
./bin/flink run ./examples/batch/WordCount.jar -input hdfs://hadoop100:9000/LICENSE -output hdfs://hadoop100:9000/wordcount-result.txt
停止任务 【web界面或者命令行执行cancel命令】
##### 第二种【flink run -m yarn-cluster(开辟资源+提交任务)】
启动集群,执行任务
./bin/flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar
注意:client端必须要设置YARN_CONF_DIR或者HADOOP_CONF_DIR或者HADOOP_HOME环境变量,通过这个环境变量来读取YARN和HDFS的配置信息,否则启动会失败
##### 第一种【yarn-session.sh(开辟资源)+flink run(提交任务)】
启动一个一直运行的flink集群
./bin/yarn-session.sh -n 2 -jm 1024 -tm 1024 [-d]
附着到一个已存在的flink yarn session
./bin/yarn-session.sh -id application_1463870264508_0029
执行任务
./bin/flink run ./examples/batch/WordCount.jar -input hdfs://hadoop100:9000/LICENSE -output hdfs://hadoop100:9000/wordcount-result.txt
停止任务 【web界面或者命令行执行cancel命令】
##### 第二种【flink run -m yarn-cluster(开辟资源+提交任务)】
启动集群,执行任务
./bin/flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar
注意:client端必须要设置YARN_CONF_DIR或者HADOOP_CONF_DIR或者HADOOP_HOME环境变量,通过这个环境变量来读取YARN和HDFS的配置信息,否则启动会失败
四.WordCount
代码
Scala实现代码
package com.skyell
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
/**
* 滑动窗口计算
*
* 每隔1秒统计最近2秒数据,打印到控制台
*/
object SocketWindowWordCountScala {
def main(args: Array[String]): Unit = {
// 获取socket端口号
val port: Int = try{
ParameterTool.fromArgs(args).getInt("port")
}catch {
case e: Exception => {
System.err.println("No port set use default port 9002--scala")
}
9002
}
// 获取运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 连接socket获取数据
val text = env.socketTextStream("master", port, '\n')
//添加隐式转换,否则会报错
import org.apache.flink.api.scala._
// 解析数据(把数据打平),分组,窗口计算,并且聚合求sum
val windowCount = text.flatMap(line => line.split("\\s"))
.map(w => WordWithCount(w, 1))
.keyBy("word") // 针对相同word进行分组
.timeWindow(Time.seconds(2), Time.seconds(1))// 窗口时间函数
.sum("count")
windowCount.print().setParallelism(1) // 设置并行度为1
env.execute("Socket window count")
}
// case 定义的类可以直接调用,不用new
case class WordWithCount(word:String,count: Long)
}
Java实现代码
package com.skyell;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class BatchWordCountJava {
public static void main(String[] args) throws Exception{
String inputPath = "D:\\DATA\\file";
String outPath = "D:\\DATA\\result";
// 获取运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 读取本地文件中内容
DataSource<String> text = env.readTextFile(inputPath);
// groupBy(0):从0聚合 sum(1):以第二个字段加和计算
DataSet<Tuple2<String, Integer>> counts = text.flatMap(new Tokenizer()).groupBy(0).sum(1);
counts.writeAsCsv(outPath, "\n", " ").setParallelism(1);
env.execute("batch word count");
}
public static class Tokenizer implements FlatMapFunction<String, Tuple2<String,Integer>>{
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] tokens = value.toLowerCase().split("\\W+");
for (String token: tokens
) {
if(token.length()>0){
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
}
pom依赖配置
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.6.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.6.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.6.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.6.2</version>
<scope>provided</scope>
</dependency>
我是王马扎,AI软件出海创业者,wangmazha.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号