theirs《A 2019 Guide to Speech Synthesis with Deep Learning》
from:https://zhuanlan.zhihu.com/p/91968492
《A 2019 Guide to Speech Synthesis with Deep Learning》
人类语音的人工产生被称为语音合成。这种基于机器学习的技术适用于文本到语音,音乐生成,语音生成,启用语音的设备,导航系统以及视障人士的可访问性。
在本文中,我们将研究为深度学习而编写和开发的研究和模型架构。
但是在我们进入之前,我们需要简要概述几种特定的传统语音合成策略:拼接式(concatenative)和参数式(parametric)。
在拼接式方法中,来自大型数据库的语音用于生成新的可听语音。在需要不同风格的语音的情况下,将使用新的音频语音数据库。这限制了这种方法的可扩展性。
参数式方法使用录制的人的语音和具有可修改以更改语音的一组参数的功能。
这两种方法代表了进行语音合成的旧方法。现在,让我们看一下使用深度学习进行操作的新方法。这是我们将涵盖的研究,以研究流行的和当前的语音合成方法:
- WaveNet:A Generative Model for Raw Audio
- Tacotron:Towards End-toEnd Speech Synthesis
- DeepVoice 1:Real-time Neural Text-to-Speech
- DeepVoice 2:Multi-Speaker Neural Text-to-Speech
- DeepVoice 3:Scaling Text-to-speech With Convolutional Sequence Learning
- Parallel WaveNet:Fast High-Fidelity Speech Synthesis
- Neural Voice Cloning with a Few Samples
- VoiceLoop:Voice Fitting and Synthesis via A Phonological Loop
- Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
本文的作者来自Google。他们提出了一种用于生成原始音频波形的神经网络。他们的模型是完全概率的和自回归的,并且可以为英语和普通话生成最新的文本到语音结果。
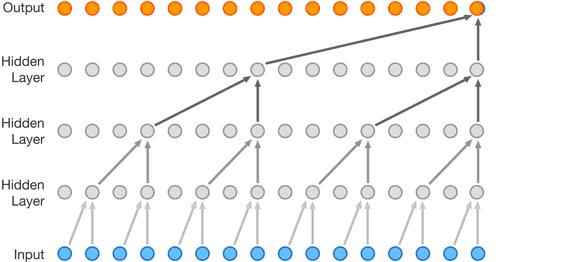
WaveNet是一种基于音频生成模型PixelCNN。它能够产生与人类声音非常相似的音频。
在架构中使用因果卷积,可确保模型不违反数据建模的顺序。在此模型中,每个预测的语音样本都反馈到网络,以帮助预测下一个语音样本。由于因果卷积没有递归关系,因此它们比RNN的训练速度更快。
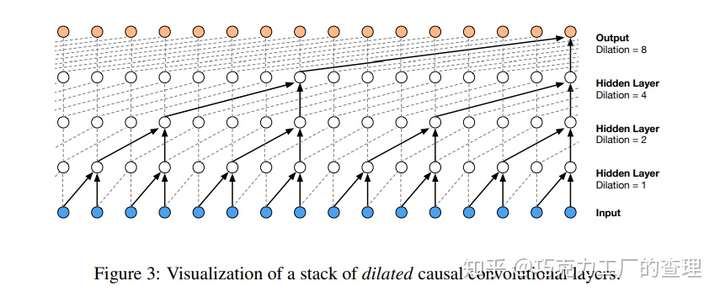
使用因果卷积的主要挑战之一是,它们需要多层才能增加接收场。为了解决这一挑战,作者使用了膨胀卷积。扩散卷积使网络具有较大的接收场,但具有几层。使用softmax分布对各个音频样本的条件分布进行建模。
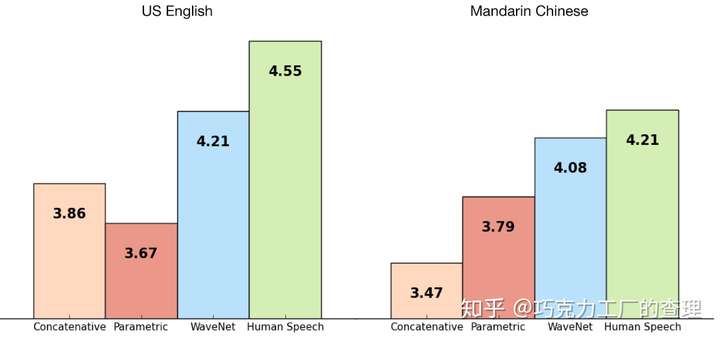
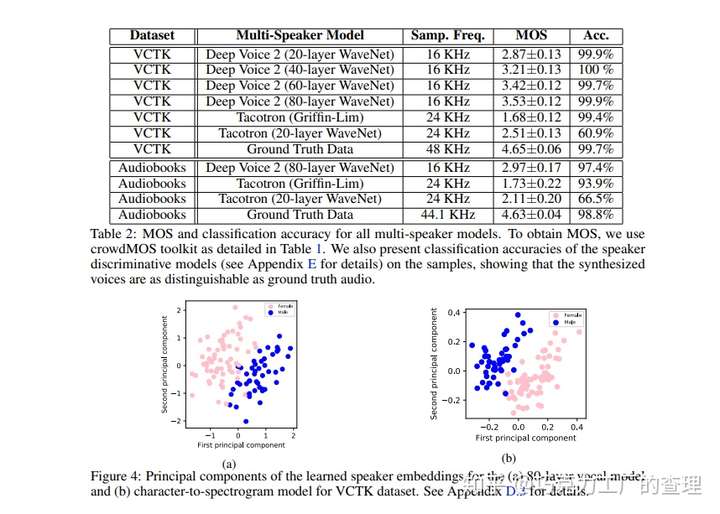
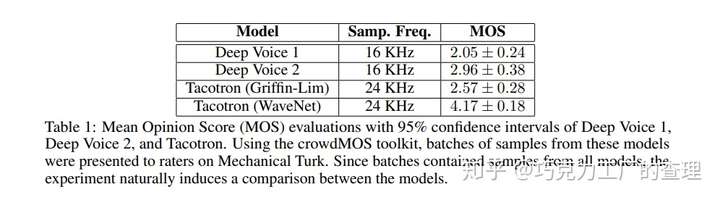
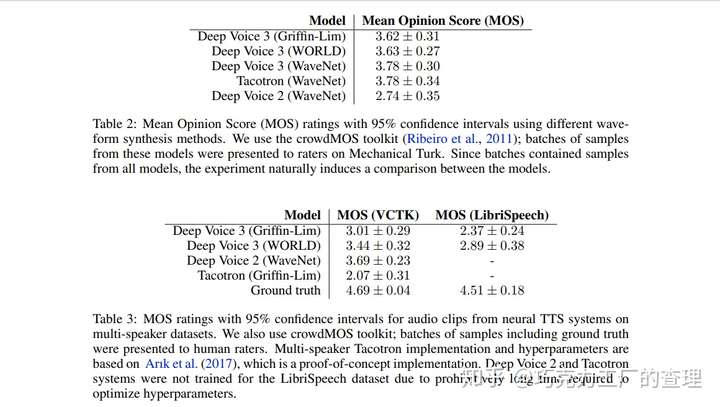
该模型在multispeaker语音生成,文本到语音和音乐音频建模方面进行了评估。MOS(平均意见分数)用于此评估。它可以测量语音质量。基本上,这是一个人对语音质量的看法。它是介于1到5之间的数字,其中5个是最好的质量。
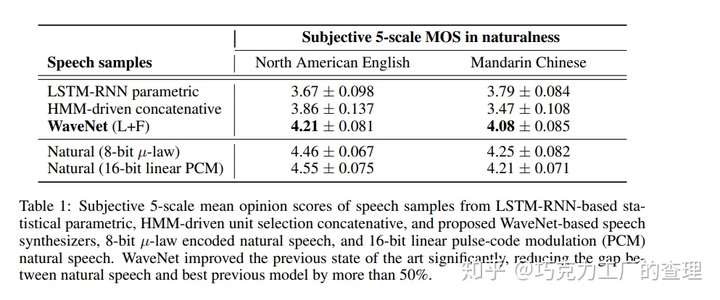
下图显示了WaveNet的质量,等级为1-5。
Tacotron:Towards End-toEnd Speech Synthesis
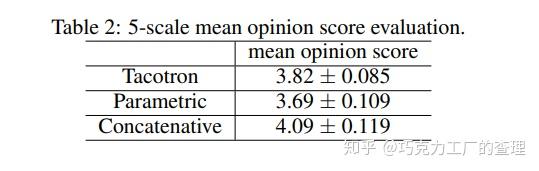
本文的作者来自Google。Tacotron是一种端到端生成文本到语音模型,可以直接从文本和音频对中合成语音。Tacotron在美式英语上的平均意见得分为3.82。Tacotron在帧级生成语音,因此比样本级自回归方法快。
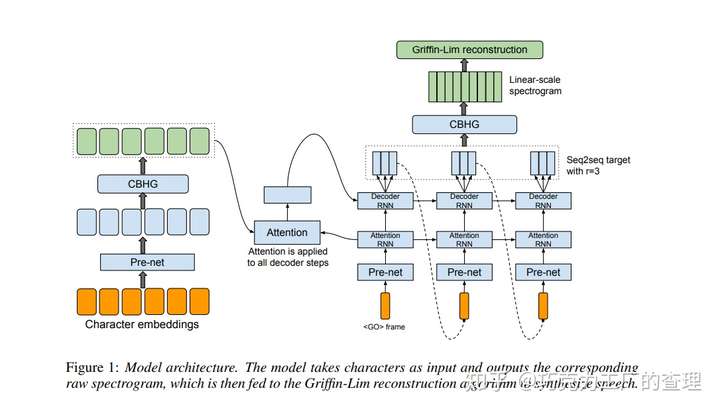
该模型在音频和文本对上进行了训练,这使其非常适用于新数据集。Tacotron具有一个seq2seq模型,该模型包括一个编码器encoder,一个基于注意力的解码器decoder和一个post-processing网络。如下面的架构图所示,该模型将characters作为输入并输出原始频谱图。然后将该频谱图转换为波形。
WaveNet:A Generative Model for Raw Audio
本文的作者来自Google。他们提出了一种用于生成原始音频波形的神经网络。他们的模型是完全概率的和自回归的,并且可以为英语和普通话生成最新的文本到语音结果。
该模型在multispeaker语音生成,文本到语音和音乐音频建模方面进行了评估。MOS(平均意见分数)用于此评估。它可以测量语音质量。基本上,这是一个人对语音质量的看法。它是介于1到5之间的数字,其中5个是最好的质量。
下图显示了WaveNet的质量,等级为1-5。
Tacotron:Towards End-toEnd Speech Synthesis
本文的作者来自Google。Tacotron是一种端到端生成文本到语音模型,可以直接从文本和音频对中合成语音。Tacotron在美式英语上的平均意见得分为3.82。Tacotron在帧级生成语音,因此比样本级自回归方法快。
该模型在音频和文本对上进行了训练,这使其非常适用于新数据集。Tacotron具有一个seq2seq模型,该模型包括一个编码器encoder,一个基于注意力的解码器decoder和一个post-processing网络。如下面的架构图所示,该模型将characters作为输入并输出原始频谱图。然后将该频谱图转换为波形。
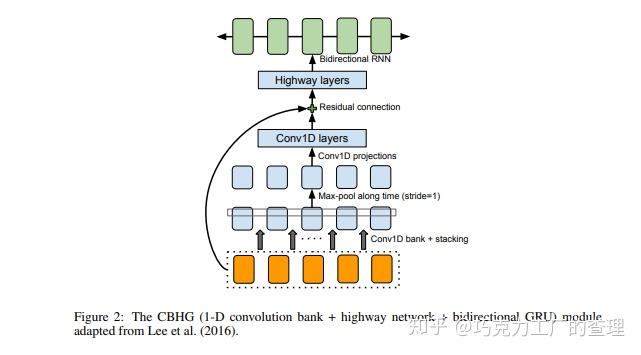
下图显示了CBHG模块的外观。它由一维卷积滤波器,highway networks和双向GRU(门控循环单元)组成。
character序列被馈送到编码器encoder,编码器提取文本的顺序表示。每个字符都表示为one-hot向量,并嵌入到连续向量中。然后添加非线性变换,然后添加一个dropout层以减少过度拟合。从本质上讲,这减少了单词的错误发音。
使用的解码是tanh函数 content-based 的注意力解码器decoder。然后使用Griffin-Lim算法生成波形。该模型使用的超参数如下所示。

下图显示了Tacotron与其他替代产品相比的性能。
DeepVoice 1:Real-time Neural Text-to-Speech
本文的作者来自百度的硅谷人工智能实验室。深度语音是使用深度神经网络开发的文本到语音系统。
它有五个主要组成部分:
- 使用 connectionist temporal classification(CTC)损失的深度神经网络定位音素phoneme 边界的分割模型。
- grapheme-to-phoneme转换模型(grapheme-to-phoneme是使用规则生成单词发音的过程)。
- 音素phoneme持续时间预测模型。
- 基频预测模型。
- 使用WaveNet变体的音频合成模型,该模型使用较少的参数。
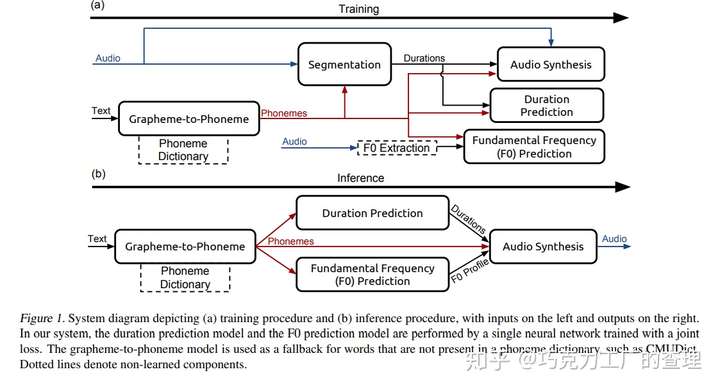
grapheme-to-phoneme 模型将英语字符转换为音素phonemes。分段模型标识每个音素在音频文件中的开始和结束位置。音素持续时间模型预测音素序列中每个音素的持续时间。
基频模型可预测音素是否发声。音频合成模型通过组合grapheme-to-phoneme模型,音素持续时间和基本频率预测模型的输出来合成音频。
与其他模型相比,此模型效果如下。

DeepVoice 2:Multi-Speaker Neural Text-to-Speech
本文代表了百度硅谷人工智能实验室对“DeepVoice”的第二次迭代。他们介绍了一种使用低维可训练说话者嵌入来增强 neural text-to-speech的方法,以从单个模型产生各种声音。
该模型基于与DeepVoice 1类似的pipeline。但是,它代表了音频质量的显着改善。该模型能够从每个speaker 不到半小时的数据中学习数百种独特的声音。
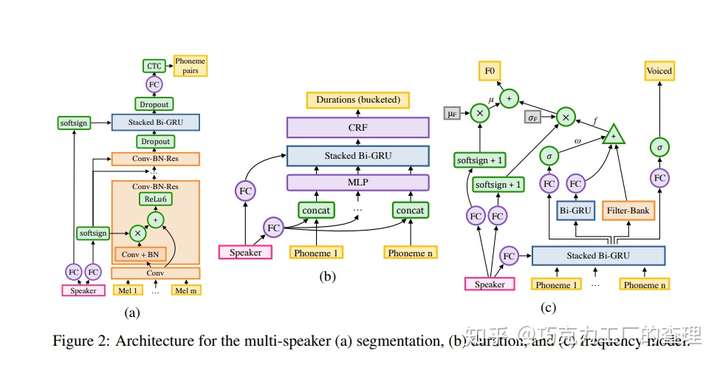
作者还介绍了基于WaveNet的spectrogram-to-audio neural vocoder 声码器,然后将其与Tacotron一起使用,代替Griffin-Lim音频生成器。本文的主要重点是处理多个speaker,每个speaker的数据更少。总体架构类似于Deep Voice1。Deep Voice 2的训练过程如下图所示。

DeepVoice 2和DeepVoice 1之间的主要区别在于音素持续时间和频率模型的分离。DeepVoice 1具有一个用于共同预测音素持续时间和频率分布的模型。在DeepVoice 2中,先预测音素持续时间,然后将其用作频率模型的输入。
DeepVoice 2中的分段模型是一种卷积循环架构,其中应用了connectionist temporal classification(CTC)损失来对音素对进行分类。DeepVoice 2的主要修改是在卷积层中添加了batch normalization和residual connections。其声音模型基于WaveNet架构。
通过用每个speakers单个低维级别的speaker嵌入矢量扩展每个模型,可以完成来自多个speakers的语音合成。speakers之间的Weight分配是通过将与speaker相关的参数存储在非常低维的向量中来实现的。
循环神经网络(RNN)的初始状态是使用speaker embeddings产生的。使用均匀分布来随机初始化speaker embeddings,并使用反向传播共同对其进行训练。speaker embeddings被合并到模型的多个部分中,以确保考虑每个speaker的独特语音签名。
现在让我们看看该模型与其他模型相比的性能如何。
Deep Voice 3:Scaling Text-to-speech With Convolutional Sequence Learning
在Deep Voice的第三次迭代中,作者介绍了一种基于全卷积注意力机制fully-convolutional attention-based 的neural text-to-speech(TTS)系统。
作者提出了一种fully-convolutional 完全卷积的字符到频谱图character-to-spectrogram体系结构,该体系结构可以实现完全并行的计算。该体系结构是一种基于注意力的sequence-to-sequence模型。该模型在LibriSpeech ASR数据集上进行了训练。
所提出的体系结构能够将诸如字符characters,音素phonemes和重音stresses的文本特征转换成不同的声码器vocoder参数。其中一些包括梅尔波段频谱图,线性标度对数幅度频谱图,基频,频谱包络和非周期性参数。这些vocoder声码器参数然后用作音频波形合成模型的输入。
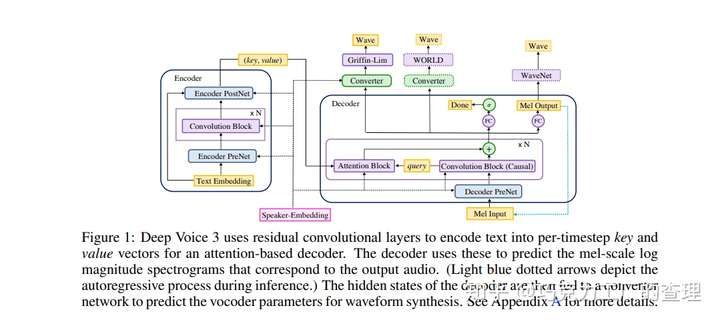
该体系结构由以下内容组成:
- 编码器—一种全卷积编码器,可将文本特征转换为内部学习的表示形式。
- 解码器-一种全卷积因果解码器,以自回归方式对学习的表示进行解码。
- 转换器—一种全卷积的post-processing 网络,可预测最终的声码器参数。
对于文本预处理,使用作者的大写文本输入字符,删除标点符号,在每个发音处以句号或问号结尾,并用表示暂停时间的特殊字符替换空格。
下图是此模型与其他替代模型的性能比较。
Parallel WaveNet: Fast High-Fidelity Speech Synthesis
本文的作者来自Google。他们介绍了一种称为“ 概率密度蒸馏(Probability Density Distillation)”的方法,该方法从训练有素的WaveNet训练并行前馈网络。该方法是通过结合逆自回归流(IAF)和WaveNet 的最佳功能而构建的。这些功能代表了WaveNet的有效训练和IAF网络的有效采样。
为了进行培训,作者使用预训练的WaveNet作为“teacher”,parallel WaveNet“student”从中学习。这里的目标是让student在从teacher那里学到的分布下匹配自己样本的概率。
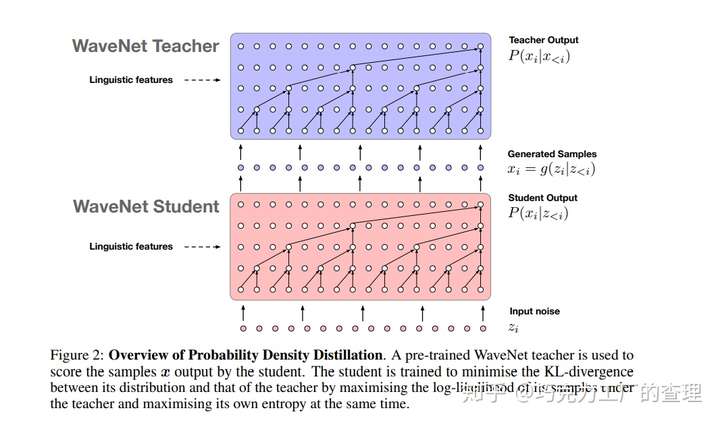
作者还提出了其他损失函数,以指导student生成高质量的音频流:
- Power loss—与人类语音一样,确保使用语音不同频段的功率。
- Perceptual loss-对于这种损失,作者尝试了feature reconstruction loss(分类器中特征图之间的欧式距离)和style loss( Gram matrices之间的欧式距离)进行实验。他们发现style loss会产生更好的结果。
- Contrastive loss会惩罚具有高可能性的波形,而与conditioning vector无关。
下图显示了此模型的性能。
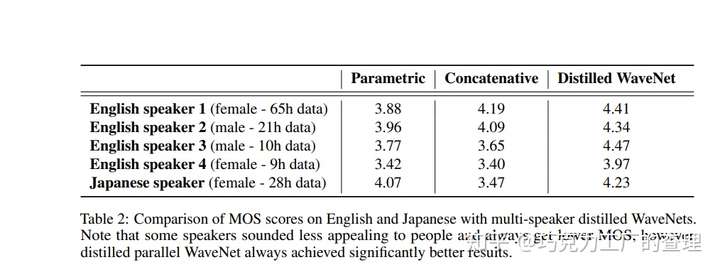
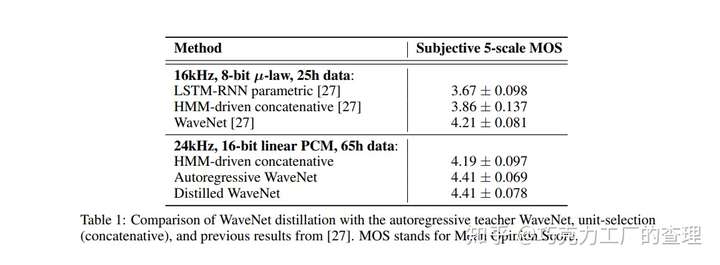
Neural Voice Cloning with a Few Samples
本文的作者来自百度研究。他们引入了一种neural语音克隆系统,该系统可以从一些音频样本中学习合成人的声音。
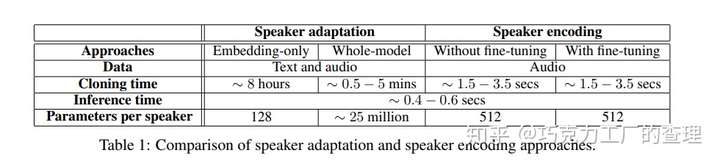
所使用的两种方法是speaker adaptation和speaker encoding。Speaker adaptation通过fine-tuning 多说话者 multi-speaker 生成模型来工作,而speaker encoding则通过训练单独的模型直接推断出适用于多说话者multi-speaker生成模型的新说话者嵌入speaker embedding 来工作。
本文使用DeepVoice 3作为multi-speaker模型的基准。对于语音克隆,作者可以从说话者中提取说话者特征并生成音频(只要给定说话者的文本可用)。
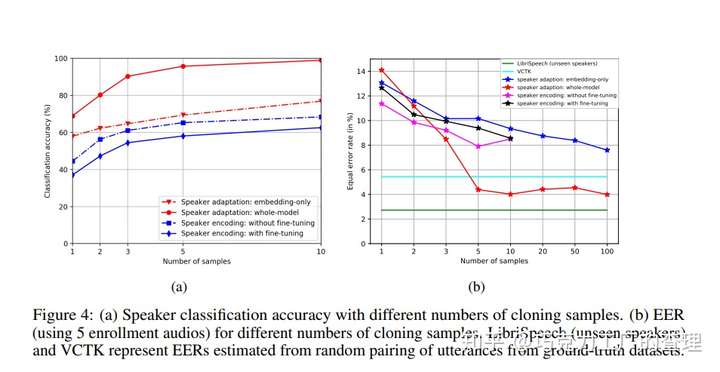
用于生成的音频的性能指标是语音自然度和说话者相似度。他们提出了一种speaker encoding方法,该方法可以直接从看不见的说话人的音频样本中估算出说话人的嵌入embeddings程度。
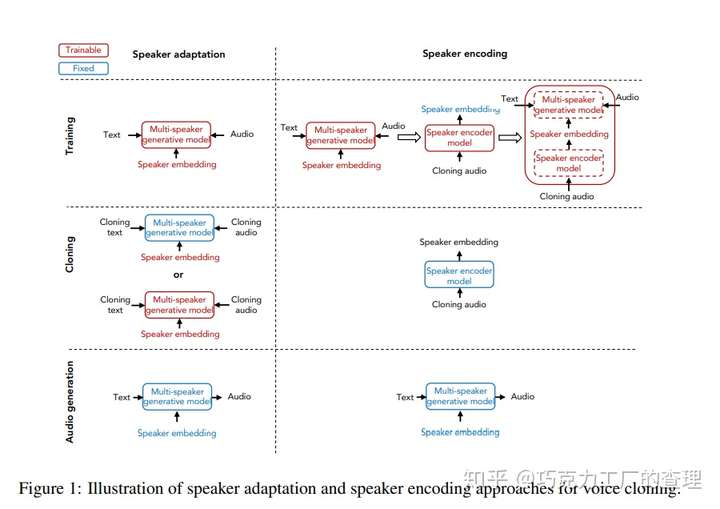
下面是语音克隆的执行方式。
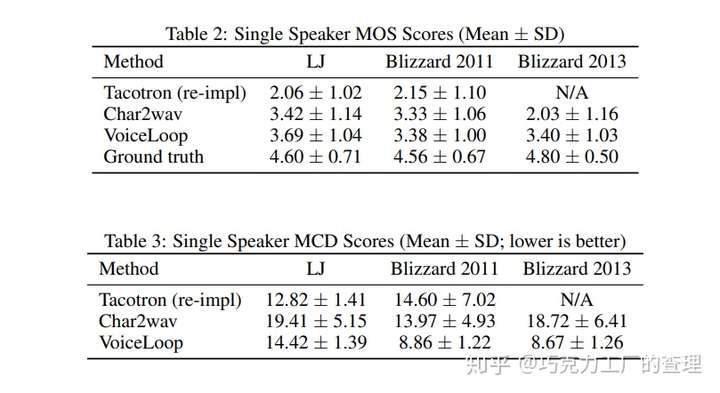
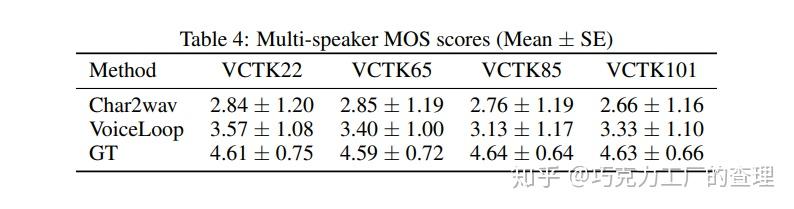
VoiceLoop:Voice Fitting and Synthesis via A Phonological Loop
本文的作者来自Facebook AI Research。他们引入了一种neural text-to-speech (TTS)技术,该技术可以从wild采样的语音中将文本转换为语音。
VoiceLoop受工作记忆模型(称为语音循环 phonological loop)的启发,该模型可在短时间内保存语言信息。它由一个不断被替换的phonological store以及一个在phonological store中保持较长期representations的rehearsal process组成。
VoiceLoop通过实现一个 shifting buffer as a matrix来构造phonological store。句子表示为音素列表。然后从每个音素中解码出一个short向量。当前上下文向量是通过对音素的编码进行加权并在每个时间点对其求和来生成的。
使VoiceLoop与众不同的一些属性包括:使用内存缓冲区代替传统的RNN,在所有进程之间共享内存以及对所有计算使用shallow,完全连接的网络。
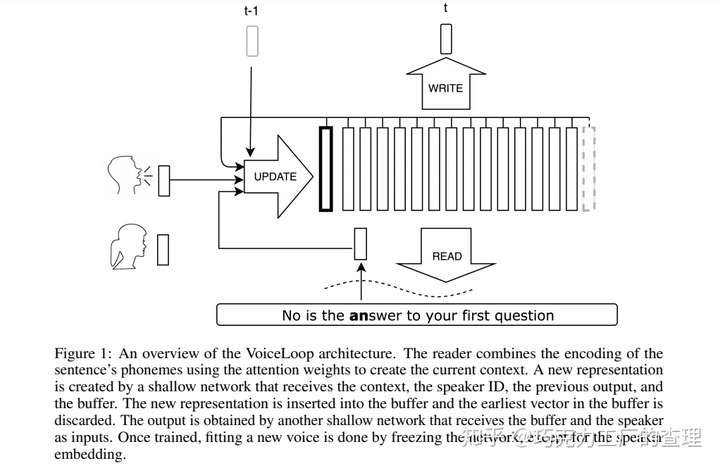
下面是模型与其他替代方案相比的表现。
Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
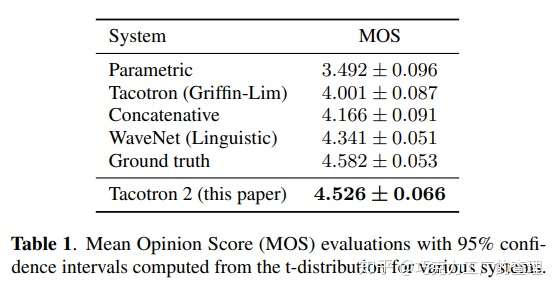
本文的作者来自Google和加州大学伯克利分校。他们介绍了Tacotron 2,这是一种用于从文本进行语音合成的神经网络体系结构。
它由一个递归sequence-to-sequence特征预测网络组成,该网络将字符嵌入character embeddings映射到梅尔尺度谱图mel-scale spectrograms。然后是经过修改的WaveNet模型。该模型用作合成来自声谱图的时域波的声码器vocoder。该模型的平均意见得分(MOS)为4.53。
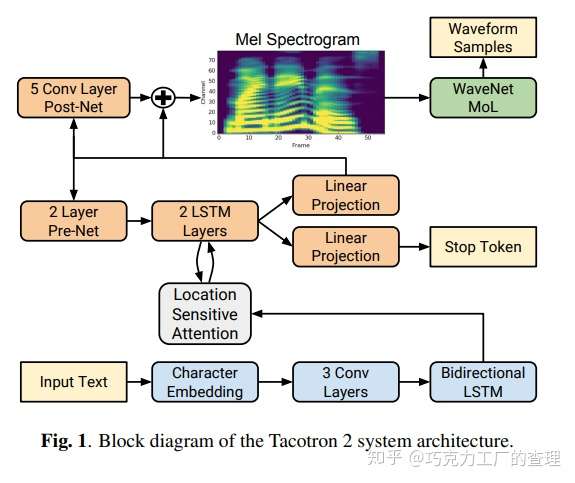
该模型是通过结合Tacotron和WaveNet的最佳功能而构建的。以下是该模型与替代模型相比的性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号