0-1损失(二分类)、交叉熵损失(分类)、Softmax Loss(多分类)、合页损失(SVM)、均方差(线性回归)、Modified Huber Loss(分类)、指数损失(Adaboost)1 0-1 Loss
一般来说,二分类机器学习模型包含两个部分:线性输出一般是s = wx;非线性输出比如是Sigmoid函数
&lt;img src="https://pic3.zhimg.com/v2-d3cabe9056577f5c49991613acb9f2e2_b.png" data-caption="" data-size="normal" data-rawwidth="149" data-rawheight="39" class="content_image" width="149"/&gt; ,经过 Sigmoid 函数,g(s) 值被限定在 [0,1] 之间,若 s ≥ 0,g(s) ≥ 0.5,则预测为正类;若 s < 0,g(s) < 0.5,则预测为负类。
表示正负类有两种方式: {+1, -1} 或 {1, 0} 。使用 y={+1, -1}时,若 ys ≥ 0,则预测正确,若 ys < 0,则预测错误。ys 的符号反映了预测的准确性和预测的置信程度。预测类别与真实类别的四种情况:
s ≥ 0, y = +1: 预测正确
s ≥ 0, y = -1: 预测错误
s < 0, y = +1: 预测错误
s < 0, y = -1: 预测正确
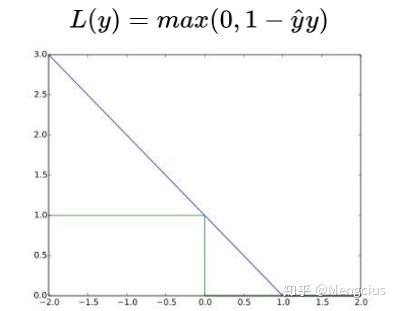
0-1 Loss 是最简单的一种损失函数。对于二分类问题,如果预测类别 y^与真实类别 y 不同,则 L=1;如果 y_^= y ,则 L=0。
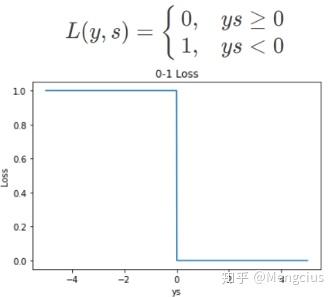
L 表示损失函数,横坐标为ys,下图为loss曲线:
&lt;img src="https://pic2.zhimg.com/v2-f86487ac17c4fdd802116fe074599fa9_b.jpg" data-caption="" data-size="normal" data-rawwidth="335" data-rawheight="298" class="content_image" width="335"/&gt;
优点:非常直观容易理解
缺点:实际应用中原始Loss 很少使用。
Loss 对每个错分类点都施以相同的惩罚(损失为 1),同等看待,这样对犯错比较大的点(ys 远小于 0)无法进行较大的惩罚,这不符合常理。
不连续、非凸、不可导,难以使用梯度优化算法。
2 交叉熵损失 (Cross Entropy Loss)
用于Logistic 回归与Softmax 分类,要与Sigmoid(二分类)或Softmax(多分类)联合使用。逻辑回归就是分类问题
从Shannon信息论角度推导交叉熵:
信息量:I(x)=−log( p(x) ),一个事件发生的概率越大,则它的信息量就越小。
熵:对于一个随机变量X而言,它的所有可能取值的信息量的期望E[I(x)]就称为熵。
&lt;img src="https://pic2.zhimg.com/v2-c3c7295e9c8d9f1927dc450cda55f14d_b.png" data-caption="" data-size="normal" data-rawwidth="435" data-rawheight="49" class="origin_image zh-lightbox-thumb" width="435" data-original="https://pic2.zhimg.com/v2-c3c7295e9c8d9f1927dc450cda55f14d_r.jpg"/&gt;
期望:离散型随机变量的一切可能的取值xi与对应的概率p(xi)乘积之和称为期望E(x) 。它是简单算术平均的一种推广,类似加权平均。
&lt;img src="https://pic3.zhimg.com/v2-b85a359a75aa89704aadca94ddf704fe_b.png" data-caption="" data-size="normal" data-rawwidth="141" data-rawheight="65" class="content_image" width="141"/&gt;
相对熵 (relative entropy):又称为KL散度、KL距离,是两个随机分布间距离的度量,D(p||q)。它可以度量当真实分布为p时,假设分布q的无效性。
机器学习的目的就是希望计算得到的概率分布q尽可能地逼近真实概率分布p,从而使得相对熵接近最小值0。
&lt;img src="https://pic3.zhimg.com/v2-641a3c0e32936b2d7d9263f0bf6ae88e_b.jpg" data-caption="" data-size="normal" data-rawwidth="462" data-rawheight="156" class="origin_image zh-lightbox-thumb" width="462" data-original="https://pic3.zhimg.com/v2-641a3c0e32936b2d7d9263f0bf6ae88e_r.jpg"/&gt;
交叉熵:相对熵公式的后半部分就是交叉熵,也反映了分布p q的相似程度,值越小越相似。
由于真实的概率分布是固定的,相对熵公式的前半部分就成了一个常数,那么相对熵达到最小值的时候,也意味着交叉熵达到了最小值。对q的优化就等效于求交叉熵的最小值。
&lt;img src="https://pic3.zhimg.com/v2-1536bb9556e851f962ef3b0a9aed45ce_b.png" data-caption="" data-size="normal" data-rawwidth="486" data-rawheight="50" class="origin_image zh-lightbox-thumb" width="486" data-original="https://pic3.zhimg.com/v2-1536bb9556e851f962ef3b0a9aed45ce_r.jpg"/&gt;
二分类的逻辑回归交叉熵损失函数:二分类时y^用Sigmoid,输出标签为{0,1}时如下式,当y=1但y^不为1时误差随着y^变小而变大:
而多分类时y^用Softmax,L=-yi*log(yi^),i是真实类别
&lt;img src="https://pic2.zhimg.com/v2-bc87a1178ba1dfddb723b6a8e65c448d_b.png" data-caption="" data-size="normal" data-rawwidth="683" data-rawheight="84" class="origin_image zh-lightbox-thumb" width="683" data-original="https://pic2.zhimg.com/v2-bc87a1178ba1dfddb723b6a8e65c448d_r.jpg"/&gt;
从极大似然性的角度推导:对交叉熵求最小值,也等效于求最大似然估计。输出标签为{0,1}时预测类别的概率P可以写成,引入-log使概率 P(y|x) 越大-log P(y|x) 越小:
当真实样本标签 y = 1 时忽略第二项; y = 0 时忽略第一项。
&lt;img src="https://pic1.zhimg.com/v2-d536ff827ed4d3a2cf8ad326b3d13e30_b.jpg" data-caption="" data-size="normal" data-rawwidth="745" data-rawheight="132" class="origin_image zh-lightbox-thumb" width="745" data-original="https://pic1.zhimg.com/v2-d536ff827ed4d3a2cf8ad326b3d13e30_r.jpg"/&gt;
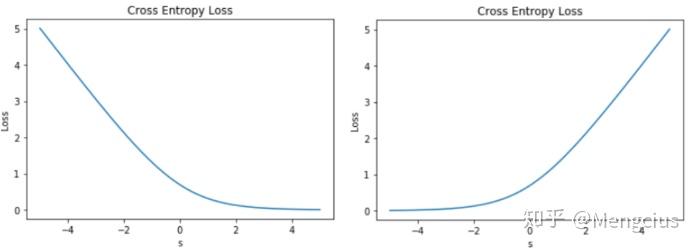
Loss曲线,当输出标签y用{1,0}表示时:
当y=1时 L=-log(y^),将sigmoid的y^=1/(1+e^-s)代入,得到Loss曲线,线性输出s 越大于零,L 越小,左图,横坐标是s
当y=0时 L=-log(1-y^),s 越小于零,L 越小,右图
&lt;img src="https://pic2.zhimg.com/v2-fb8cc26f6e2bdaa0ef17a9a6cd206c6d_b.jpg" data-caption="" data-size="normal" data-rawwidth="696" data-rawheight="250" class="origin_image zh-lightbox-thumb" width="696" data-original="https://pic2.zhimg.com/v2-fb8cc26f6e2bdaa0ef17a9a6cd206c6d_r.jpg"/&gt;
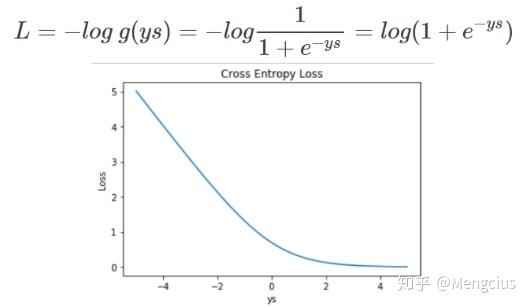
当输出标签y用{-1,+1}表示时:交叉熵loss是一样的,只是表示方式不同,用ys替换上面的s。把ys整合作为横坐标,容易作图且具有实际的物理意义。
&lt;img src="https://pic3.zhimg.com/v2-e39693c7c2bb0b29ff124eaba4bae072_b.jpg" data-caption="" data-size="normal" data-rawwidth="529" data-rawheight="308" class="origin_image zh-lightbox-thumb" width="529" data-original="https://pic3.zhimg.com/v2-e39693c7c2bb0b29ff124eaba4bae072_r.jpg"/&gt;
优点:是使用最广泛的损失函数之一
在整个实数域内,Loss 近似线性变化,尤其是当 ys << 0 的时候,Loss 更近似线性。错误越大惩罚越大
交叉熵 Loss 连续可导,便于求导计算
模型受异常点的干扰就较小
参考1 交叉熵损失函数公式推导 3 Softmax Loss
概念区分
Softmax回归:逻辑回归的一般形式,将logistic激活函数推广到了C个类别,C=2的Softmax回归就是逻辑回归。
Softmax分类器:是多类别的分类器。没有隐藏层的神经网络任何两个分类之间的决策边界都是线性的,但可以用多个不同的线性函数来分成多类(多个神经单元)。网络越深就可以学到更复杂的非线性决策边界。
Softmax层:在神经网络的最后一层输出层,有几个类别就设几个单元,算出各单元线性预测值z后,用Softmax激活函数算出各概率。
图像分类的主干网络AlexNet/VGG/ResNet/MobileNet等预测模型的最后一层都是"Softmax",训练和验证模型的最后一层都是"Accuracy"+"SoftmaxWithLoss"。因为图像分类只需要对深度特征进行分离即可。
Softmax函数(激活函数):将z映射为概率的公式如下,它同时需要一个向量z_i,因为要结合所有输出归一化成概率,输出也是向量。它通常用在输出层上。
Sigmoid和ReLu激活函数都是只处理一个实数z,输出也是一个实数。二分类时的输出层用Sigmoid函数,隐藏层用ReLu函数。
Softmax-Loss(Softmax损失函数):带有Softmax输出层的神经网络的损失函数,Softmax分类器的损失函数,Softmax激活函数的计算结果作为Softmax分类器损失函数的输入。
Hardmax:将z中最大元素置1,其他位置都是0。而Softmax从z到概率的映射更温和,是具体概率值。
Softmax激活函数,求多类别概率
在逻辑回归中的作用是将线性预测值转化为类别概率,Softmax函数定义如下:
经典的深度神经网络顶层其实本来也就是一个逻辑回归分类器
&lt;img src="https://pic2.zhimg.com/v2-82fbb0bd8050fc3835ada85d6f7654a5_b.jpg" data-caption="" data-size="normal" data-rawwidth="387" data-rawheight="70" class="content_image" width="387"/&gt;
设zi=wx+b是第i个类别的线性预测结果,带入Softmax其实就是先对每一个zi取指数变成非负(避免相加时正负值相抵),然后除以所有项之和来进行归一化变成0~1间的各类别概率。现在每个oi=σi(z)就可以解释成数据 x 属于多个类别 i 的概率(m个类别,一个数据x有很多个特征x0,x1,x2...),或称似然 (Likelihood)。
注意:逻辑回归中zi经过sigmoid激活函数,转换成了0~1间的概率值,计算数据x属于这个正确类y=1的概率。
Softmax分类器用的损失函数(交叉熵损失), Multinomial Logistic Loss
逻辑回归的目标函数(代价函数,损失函数)是根据最大似然原则来建立的,假设数据x所对应的类别为y,o_y就是由Softmax函数算来的x属于正确类别y的概率。最大似然就是要最大化o_y,通常使用 negative log-likelihood 而不是 likelihood,也就是说最小化 -log(o_y) 的值,这两者结果在数学上等价。所以最小化代价函数就是最小化:
&lt;img src="https://pic3.zhimg.com/v2-2a8f61aa484aebf325d899d515a7bf46_b.png" data-caption="" data-size="normal" data-rawwidth="199" data-rawheight="34" class="content_image" width="199"/&gt;
在Softmax分类中一般用的损失函数是:(吴恩达解释)
正确样本y2=1,其他样本都是0就舍弃了(公式是交叉熵损失函数)
最小化损失函数,就是最大似然,就是最大化-log(o_y),就是最大化o_y。(o_y就是y2^)
&lt;img src="https://pic2.zhimg.com/v2-7e1207ba82186d3d821f68eead1c73c5_b.png" data-caption="" data-size="normal" data-rawwidth="484" data-rawheight="39" class="origin_image zh-lightbox-thumb" width="484" data-original="https://pic2.zhimg.com/v2-7e1207ba82186d3d821f68eead1c73c5_r.jpg"/&gt;
整个训练集的损失 J,是所有损失的和的平均值,前面的是单个训练样本的损失。这个的损失函数展开就是各网络层各单元的参数w b的代数式,求梯度时也是对它们求梯度。梯度下降时要求出损失函数对所有层所有单元中权重的梯度,同时更新所有的权重。
&lt;img src="https://pic4.zhimg.com/v2-447ba3fb52dbd45488374654e6f751d3_b.jpg" data-caption="" data-size="normal" data-rawwidth="342" data-rawheight="70" class="content_image" width="342"/&gt; Softmax-Loss
Softmax-Loss就是将Softmax激活函数代入了上面的损失函数L,且参与的是实际类别的Softmax激活值s_yi和所有类别Softmax激活值的和s_j。下图是cs231n中的表示(R是正则项,惩罚W来减轻复杂度):
&lt;img src="https://pic1.zhimg.com/v2-8fa9b5e2784f8f84873b96dd3de061ec_b.png" data-caption="" data-size="normal" data-rawwidth="1179" data-rawheight="74" class="origin_image zh-lightbox-thumb" width="1179" data-original="https://pic1.zhimg.com/v2-8fa9b5e2784f8f84873b96dd3de061ec_r.jpg"/&gt; &lt;img src="https://pic2.zhimg.com/v2-591bed8343d50a3dadeac6c893cbd6e1_b.jpg" data-caption="" data-size="normal" data-rawwidth="638" data-rawheight="201" class="origin_image zh-lightbox-thumb" width="638" data-original="https://pic2.zhimg.com/v2-591bed8343d50a3dadeac6c893cbd6e1_r.jpg"/&gt;
Softmax-Loss实际上是由softmax函数和交叉熵损失函数(Cross Entropy Loss)组合而成。
Softmax激活函数和Multinomial Logistic Loss是可以合并成一个Softmax-loss层,也可以是分开的,分开后更灵活一点,但有数值稳定性的问题,计算量也变大。
Loss曲线:当 s << 0 时,Softmax 近似线性;当 s>>0 时,Softmax 趋向于零。
&lt;img src="https://pic1.zhimg.com/v2-a697c99612eee8b46beeb736362d2128_b.jpg" data-caption="" data-size="normal" data-rawwidth="512" data-rawheight="371" class="origin_image zh-lightbox-thumb" width="512" data-original="https://pic1.zhimg.com/v2-a697c99612eee8b46beeb736362d2128_r.jpg"/&gt; weighted softmax loss(加权softmax)
假如我们是一个分类问题,只有两类,但是两类的样本数目差距非常之大。比如边缘检测问题,边缘像素的重要性是比非边缘像素大的,此时可以针对性的对样本进行加权。
&lt;img src="https://pic2.zhimg.com/v2-0b7267c51538092570e25d7353e4b8d9_b.png" data-caption="" data-size="normal" data-rawwidth="375" data-rawheight="53" class="content_image" width="375"/&gt;
wc就是这个权重,c=0代表边缘像素,c=1代表非边缘像素,则我们可以令w0=1,w1=0.001,即加大边缘像素的权重。当然也可以自适应权重。
Softmax与Softmax-Loss AI之路 4 合页损失 (Hinge Loss)
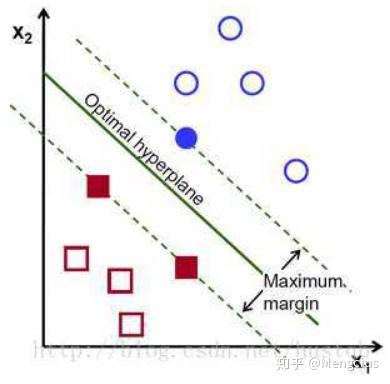
Hinge Loss 一般多用于支持向量机SVM(大间距分类器)中,体现了 SVM 距离最大化的思想。
优点:当 Loss>0时是线性函数,便于梯度下降算法求导。
&lt;img src="https://pic2.zhimg.com/v2-d0b6175a4a2c37e84e5e162d0c17621d_b.jpg" data-caption="" data-size="normal" data-rawwidth="390" data-rawheight="384" class="content_image" width="390"/&gt; Hinge loss用于二分类
以SVM的线性输出模型为例y^=s=wx,L 为下列公式,loss曲线以ys=y*y^为横轴
若y*y^<1,则损失为 1-y*y^ 大于零,分类错误
输出标签y=-1时,-1<y^<0,y=1时,0<y^<1,此范围loss都不等于0
若y*y^>=1,则损失为 0,分类正确
输出标签y=-1时,y^<=-1,y=1时,y^>=1,此范围loss都等于0
&lt;img src="https://pic2.zhimg.com/v2-71cb2f0a164419bfe7fafc1a7186637d_b.jpg" data-caption="" data-size="normal" data-rawwidth="397" data-rawheight="311" class="content_image" width="397"/&gt; Hinge loss用于最大间距
代表正负样本得分的间距:
y'>y+m时,loss=0,即正样本的预测值大于负样本的预测值加间距
y是正样本的得分,y' 是负样本的得分,m是两者间距。
&lt;img src="https://pic3.zhimg.com/v2-ee3873b0992220d06f7feb91a4a5da12_b.png" data-caption="" data-size="normal" data-rawwidth="333" data-rawheight="38" class="content_image" width="333"/&gt;
希望正样本分数越高越好,负样本分数越低越好,但二者得分之差最多到m就足够了,差距增大并不会有任何奖励。
cs231n中的表示:
&lt;img src="https://pic4.zhimg.com/v2-1901863501a8894b476f3c0546ec5de3_b.jpg" data-caption="" data-size="normal" data-rawwidth="857" data-rawheight="530" class="origin_image zh-lightbox-thumb" width="857" data-original="https://pic4.zhimg.com/v2-1901863501a8894b476f3c0546ec5de3_r.jpg"/&gt; 5 均方差 (MSE, mean squared error)
用于线性回归问题,属于最小二乘法(OLS)
最小二乘的基本原则是:最优拟合直线应该是使各点到回归直线的距离和最小的直线,即平方和最小。
用均方差(MSE)作为一项衡量指标:
&lt;img src="https://pic4.zhimg.com/v2-644dd53e5fbbc68957dc69b18d6af0bf_b.jpg" data-caption="" data-size="normal" data-rawwidth="236" data-rawheight="61" class="content_image" width="236"/&gt;
线性回归为什么不能用交叉熵?交叉熵公式对于线性回归问题,任意取一个值比如 -1.5,就没法计算 log(-1.5),所以一般不用交叉熵来优化回归问题。
分类问题为什么不能用MSE?分类问题需要用 one hot 的形式计算各 label 的概率,然后用 argmax 来决定分类,计算概率的时候通常用 softmax。用 MSE 计算 loss 的问题在于,通过 Softmax 输出的曲线是波动的,有很多局部的极值点,非凸优化问题。而 cross entropy 计算 loss,则依旧是一个凸优化问题,可用梯度下降求解。
方差、MSE等公式 为什么分类问题用 cross entropy,而回归问题用 MSE 6 Modified Huber Loss
scikit-learn 中的 SGDClassifier 就使用了它。
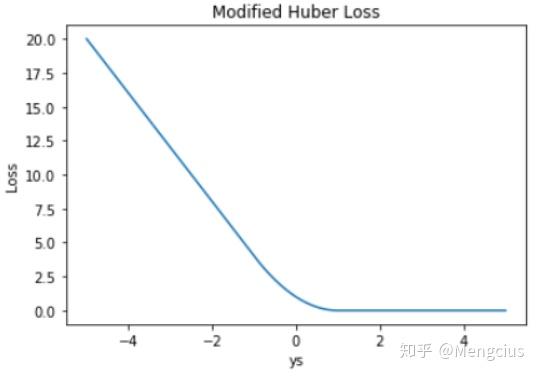
Huber Loss 也能应用于分类问题中,称为 Modified Huber Loss:
&lt;img src="https://pic3.zhimg.com/v2-db3788cd07d5c906252f05c6930273b6_b.png" data-caption="" data-size="normal" data-rawwidth="887" data-rawheight="137" class="origin_image zh-lightbox-thumb" width="887" data-original="https://pic3.zhimg.com/v2-db3788cd07d5c906252f05c6930273b6_r.jpg"/&gt;
Loss曲线:Modified Huber Loss 结合了 MSE、Hinge Loss 和 交叉熵 Loss 的优点。
&lt;img src="https://pic4.zhimg.com/v2-fdbc1de98fdeb5bd7270ee99d2143587_b.jpg" data-caption="" data-size="normal" data-rawwidth="537" data-rawheight="376" class="origin_image zh-lightbox-thumb" width="537" data-original="https://pic4.zhimg.com/v2-fdbc1de98fdeb5bd7270ee99d2143587_r.jpg"/&gt;
优点:一方面能在 ys > 1 时产生稀疏解提高训练效率;另一方面对于 ys < −1 样本的惩罚以线性增加,这意味着受异常点的干扰较少。
7 指数损失 (Exponential Loss)
&lt;img src="https://pic4.zhimg.com/v2-cca9a270b27e64bac3a967906f74ff4b_b.jpg" data-caption="" data-size="normal" data-rawwidth="229" data-rawheight="53" class="content_image" width="229"/&gt;
Exponential Loss 与交叉熵 Loss 类似,但它是指数下降的,梯度更大。
缺点:受异常点的干扰较大
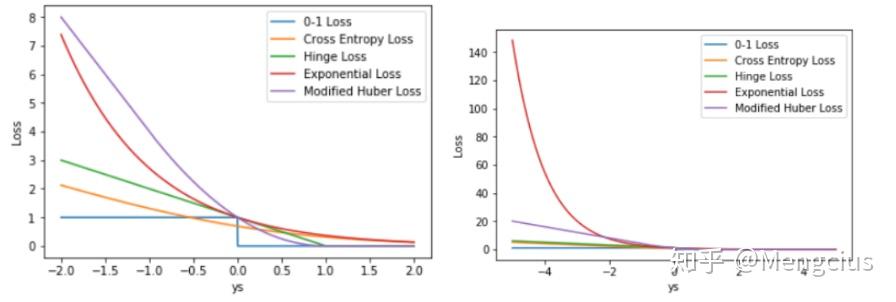
比较各loss对异常点的容忍性
绘制5种Loss,左图 ys 的取值范围是 [-2,+2],右图范围[-5,+5]:
&lt;img src="https://pic3.zhimg.com/v2-0ebd75bb43eb88d9ac40e53e326fe12a_b.jpg" data-caption="" data-size="normal" data-rawwidth="896" data-rawheight="302" class="origin_image zh-lightbox-thumb" width="896" data-original="https://pic3.zhimg.com/v2-0ebd75bb43eb88d9ac40e53e326fe12a_r.jpg"/&gt;
Exponential Loss 远远大于其它 Loss。从训练的角度来看,如果样本中存在离群点,Exponential Loss 会给离群点赋予更高的惩罚权重,但却可能是以牺牲其他正常数据点的预测效果为代价,降低模型的整体性能
相比 Exponential Loss,其它四个 Loss,包括 Softmax Loss,都对离群点有较好的“容忍性”,受异常点的干扰较小,模型较为健壮。
机器学习分类损失函数 机器学习中的损失函数
转载请注明:https://zhuanlan.zhihu.com/FaceRec 我的知乎 中查看其他系列专栏《CNN模型合集 》《人脸识别合集 》《目标检测合集 》《CS231n深度视觉笔记 》《OpenCV图像处理教程 》

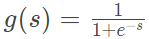
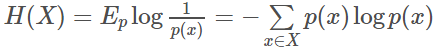
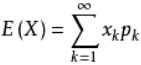
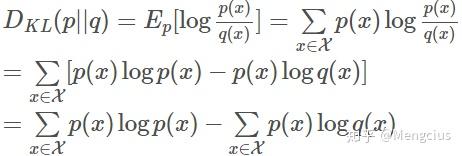
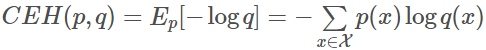
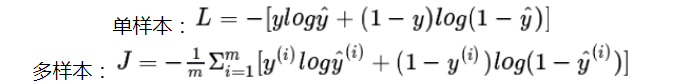
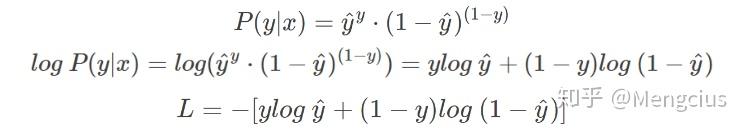
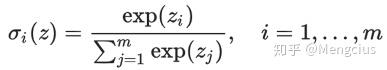
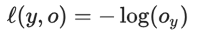
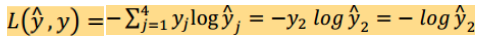
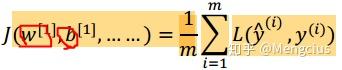



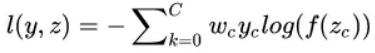
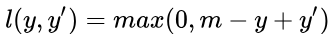

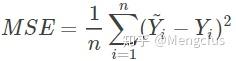
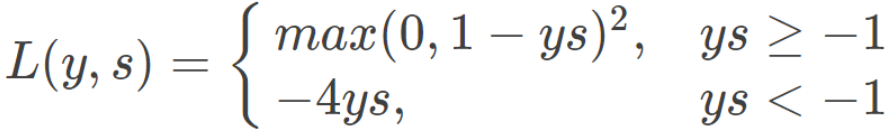
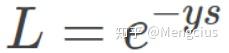

 浙公网安备 33010602011771号
浙公网安备 33010602011771号