封装自己的dapper lambda扩展-设计篇
前言
昨天开源了业务业余时间自己封装的dapper lambda扩展,同时写了篇博文《编写自己的dapper lambda扩展-使用篇》简单的介绍了下其使用,今天将分享下它的设计思路
链式编程
其实就是将多个方法通过点(.)将它们串接起来,让代码更加简洁, 可读性更强。
new SqlConnection("").QuerySet<User>() .Where(a => a.Name == "aasdasd") .OrderBy(a => a.CreateTime)
.Top(10) .Select(a => a.Name).ToList();
其原理是类的调用方法的返回值类型为类本身或其基类,选择返回基类的原因是为了做降级约束,例如我希望使用了Top之后接着Select和ToList,无法再用where或orderBy。
UML图

原型代码
CommandSet


public class CommandSet<T> : IInsert<T>, ICommand<T> { #region 方法 public int Insert(T entity) { throw new NotImplementedException(); } public int Update(T entity) { throw new NotImplementedException(); } public int Update(Expression<Func<T, T>> updateExpression) { throw new NotImplementedException(); } public int Delete() { throw new NotImplementedException(); } public IInsert<T> IfNotExists(Expression<Func<T, bool>> predicate) { throw new NotImplementedException(); } public ICommand<T> Where(Expression<Func<T, bool>> predicate) { throw new NotImplementedException(); } #endregion } public interface ICommand<T> { int Update(T entity); int Update(Expression<Func<T, T>> updateExpression); int Delete(); } public interface IInsert<T> { int Insert(T entity); } public static class Database { public static QuerySet<T> QuerySet<T>(this SqlConnection sqlConnection) { return new QuerySet<T>(); } public static CommandSet<T> CommandSet<T>(this SqlConnection sqlConnection) { return new CommandSet<T>(); } }
QuerySet
public class QuerySet<T> : IAggregation<T> { #region 方法 public T Get() { throw new NotImplementedException(); } public List<T> ToList() { throw new NotImplementedException(); } public PageList<T> PageList(int pageIndex, int pageSize) { throw new NotImplementedException(); } public List<T> UpdateSelect(Expression<Func<T, T>> @where) { throw new NotImplementedException(); } public IQuery<TResult> Select<TResult>(Expression<Func<T, TResult>> selector) { throw new NotImplementedException(); } public IOption<T> Top(int num) { throw new NotImplementedException(); } public IOrder<T> OrderBy<TProperty>(Expression<Func<T, TProperty>> field) { throw new NotImplementedException(); } public IOrder<T> OrderByDescing<TProperty>(Expression<Func<T, TProperty>> field) { throw new NotImplementedException(); } public int Count() { throw new NotImplementedException(); } public bool Exists() { throw new NotImplementedException(); } public QuerySet<T> Where(Expression<Func<T, bool>> predicate) { throw new NotImplementedException(); } #endregion } public interface IAggregation<T> : IOrder<T> { int Count(); bool Exists(); } public interface IOrder<T> : IOption<T> { IOrder<T> OrderBy<TProperty>(Expression<Func<T, TProperty>> field); IOrder<T> OrderByDescing<TProperty>(Expression<Func<T, TProperty>> field); } public interface IOption<T> : IQuery<T>, IUpdateSelect<T> { IQuery<TResult> Select<TResult>(Expression<Func<T, TResult>> selector); IOption<T> Top(int num); } public interface IUpdateSelect<T> { List<T> UpdateSelect(Expression<Func<T, T>> where); } public interface IQuery<T> { T Get(); List<T> ToList(); PageList<T> PageList(int pageIndex, int pageSize); }
以上为基本的设计模型,具体实现如有问题可以查看我的源码。
表达式树的解析
具体实现的时候会涉及到很多的表达式树的解析,例如where条件、部分字段update,而我实现的时候一共两步:先修树,再翻译。然而无论哪步都得对表达式树进行遍历。
表达式树
百度的定义:也称为“表达式目录树”,以数据形式表示语言级代码,它是一种抽象语法树或者说是一种数据结构。
我对它的理解是,它本质是一个二叉树,节点拥有自己的属性像nodetype。
而它的遍历方式为前序遍历
前序遍历
百度的定义:历首先访问根结点然后遍历左子树,最后遍历右子树。在遍历左、右子树时,仍然先访问根结点,然后遍历左子树,最后遍历右子树,以下图为例
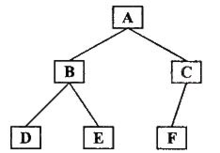
其遍历结果为:ABDECF
以一个实际例子:
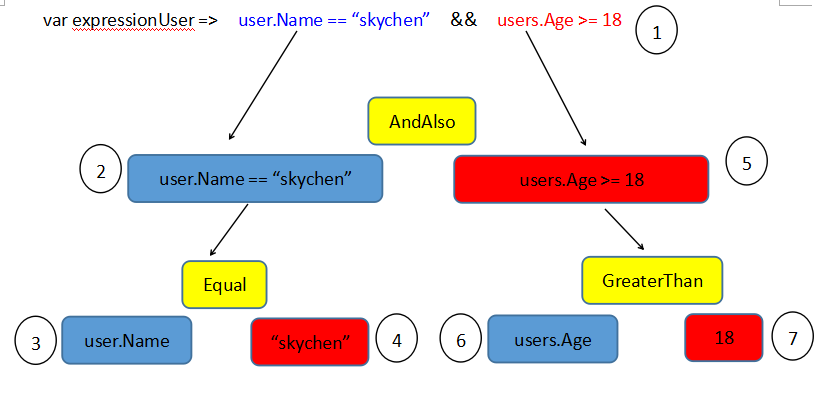
从上图可以看出,我们会先遍历到根节点的NodeType AndAlso翻译为 and ,然后到节点2,NodeType的Equal翻译为 = ,再到3节点翻译为 Name,再到4节点翻译为'skychen',那么将3、4节点拼接起来就为Name = 'skychen',如果类推6、7为Age >= 18,最后拼接这个语句为 Name = 'skychen' and Age >= 18。
修树
修树的目的,为了我们更好的翻译,例如DateTime.Now表达式树里的NodeType为MemberAccess,我希望转换成NodeType为Constant类型,以'2018-06-27 16:18:00'这个值作为翻译。
结束
以上为设计和实现的要点,具体的实现问题可以查看源码,如果有建议和疑问可以在下方留言,如果对您起到作用,希望您点一下推荐作为对我的支持。
再次双手奉上源码:https://github.com/SkyChenSky/Sikiro.DapperLambdaExtension.MsSql
作 者:
陈珙
出 处:http://www.cnblogs.com/skychen1218/
关于作者:专注于微软平台的项目开发。如有问题或建议,请多多赐教!
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角推荐一下。您的鼓励是作者坚持原创和持续写作的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号