
翻滚吧,Spark (错误记录)
1) 本地运行报错:
Exception in thread "main" org.apache.spark.SparkException: A master URL must be set in your configuration
解决方案:
第一种, 在代码里设置:
val conf= new SparkConf(). setAppName("SimpleApp"). setMaster("local")
第二种,在IDE里设置为本地单线程运行(-Dspark.master=local)

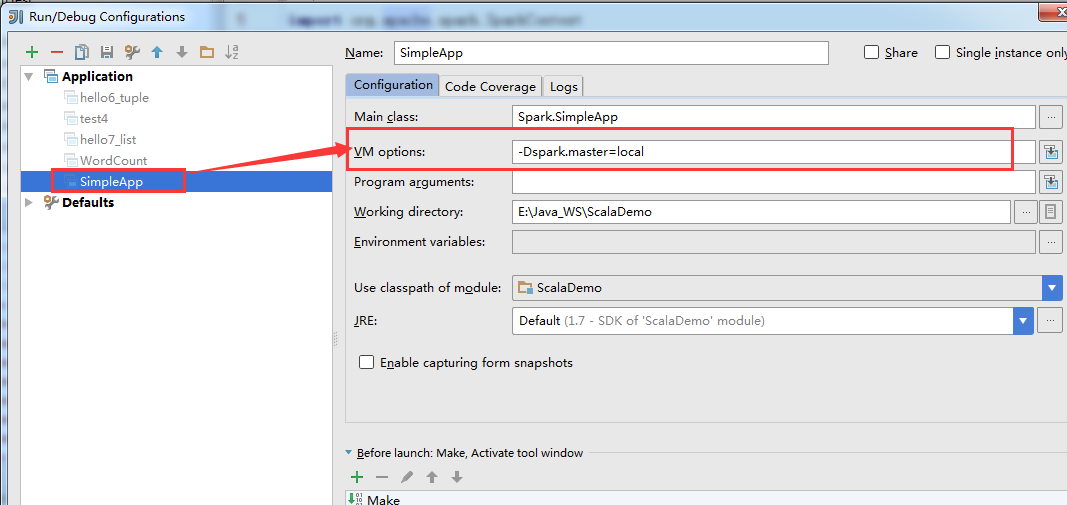
2) 调用函数出错:
Exception in thread "main" java.lang.ExceptionInInitializerError
at main.scala.test$.main(test.scala:13)
at main.scala.test.main(test.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)
Caused by: org.apache.spark.SparkException: Only one SparkContext may be running in this JVM (see SPARK-2243). To ignore this error, set spark.driver.allowMultipleContexts = true. The currently running SparkContext was created at:
org.apache.spark.SparkContext.<init>(SparkContext.scala:80)
原因:main函数和另一个独立的函数我都定义了SparkContext
解决:把main函数里面的SparkContext定义去掉。直接用函数里面的sc 即可。
3)自定义class名 与 Spark内置的类名 重复报错。
Warning:(1, 64)
imported `NaiveBayes' is permanently hidden by definition of object NaiveBayes
import org.apache.spark.mllib.classification.{NaiveBayesModel, NaiveBayes}
^
每天进步一点点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号