
大数据之Hue的搭建与相关配置
1. Hue是什么
HUE=Hadoop User Experience
Hue是一个开源的Apache Hadoop UI系统,由Cloudera Desktop演化而来,最后Cloudera公司将其贡献给Apache基金会的Hadoop社区,它是基于Python Web框架Django实现的。
通过使用Hue,可以在浏览器端的Web控制台上与Hadoop集群进行交互,来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job,执行Hive的SQL语句,浏览HBase数据库等等。
2. Hue能做什么
- 访问HDFS和文件浏览
- 通过web调试和开发hive以及数据结果展示
- 查询solr和结果展示,报表生成
- 通过web调试和开发impala交互式SQL Query
- spark调试和开发
- Pig开发和调试
- oozie任务的开发,监控,和工作流协调调度
- Hbase数据查询和修改,数据展示
- Hive的元数据(metastore)查询
- MapReduce任务进度查看,日志追踪
- 创建和提交MapReduce,Streaming,Java job任务
- Sqoop2的开发和调试
- Zookeeper的浏览和编辑
- 数据库(MySQL,PostGres,SQlite,Oracle)的查询和展示
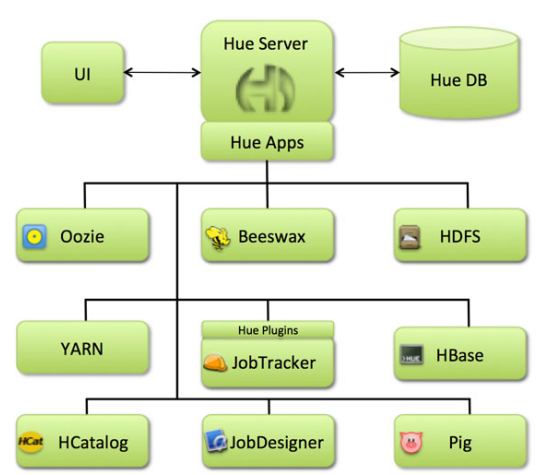
3. Hue的架构
Hue是一个友好的界面集成框架,可以集成各种大量的大数据体系软件框架,通过一个界面就可以做到查看以及执行所有的框架。
Hue提供的这些功能相比Hadoop生态各组件提供的界面更加友好,但是一些需要debug的场景可能还是要使用原生系统才能更加深入的找到错误的原因。
4. Hue的安装
4.1. 上传解压安装包
Hue的安装支持多种方式,包括rpm包的方式进行安装、tar.gz包的方式进行安装以及cloudera manager的方式来进行安装等,我们这里使用tar.gz包的方式来进行安装。
Hue的压缩包的下载地址:
http://archive.cloudera.com/cdh5/cdh/5/
我们这里使用的是CDH5.14.0这个对应的版本,具体下载地址为
http://archive.cloudera.com/cdh5/cdh/5/hue-3.9.0-cdh5.14.0.tar.gz
把下载好的安装包上传到我们的Linux服务器上并解压到我们的servers目录下
4.2. 编译初始化工作
4.2.1. 联网安装各种必须的依赖包
1 yum install -y asciidoc cyrus-sasl-devel cyrus-sasl-gssapi cyrus-sasl-plain gcc gcc-c++ krb5-devel libffi-devel libxml2-devel libxslt-devel make openldap-devel python-devel sqlite-devel gmp-devel
4.2.2. Hue 初始化配置
1 cd /export/servers/hue-3.9.0-cdh5.14.0/desktop/conf 2 vim hue.ini
1 #通用配置 2 [desktop] 3 secret_key=jFE93j;2[290-eiw.KEiwN2s3['d;/.q[eIW^y#e=+Iei*@Mn<qW5o 4 http_host=node-1 5 is_hue_4=true 6 time_zone=Asia/Shanghai 7 server_user=root 8 server_group=root 9 default_user=root 10 default_hdfs_superuser=root 11 #配置使用 mysql 作为 hue 的存储数据库,大概在 hue.ini 的 587 行左右 12 [[database]] 13 engine=mysql 14 host=node-1 15 port=3306 16 user=root 17 password=Hadoop 18 name=hue
4.2.3. 创建 mysql 中 Hue 使用的 DB
1 create database hue default character set utf8 default collate utf8_general_ci;
4.3.编译 Hue
1 cd /export/servers/hue-3.9.0-cdh5.14.0 2 make apps
1 cd /export/servers/hue-3.9.0-cdh5.14.0/ 2 build/env/bin/supervisor
第一次登陆hue的时候切记你配置文件配置的user是什么账户就创建什么账户,切莫创建其他否则你集成其他软件的时候将会面临一系列的集成不成功。
5.Hue 与软件的集成
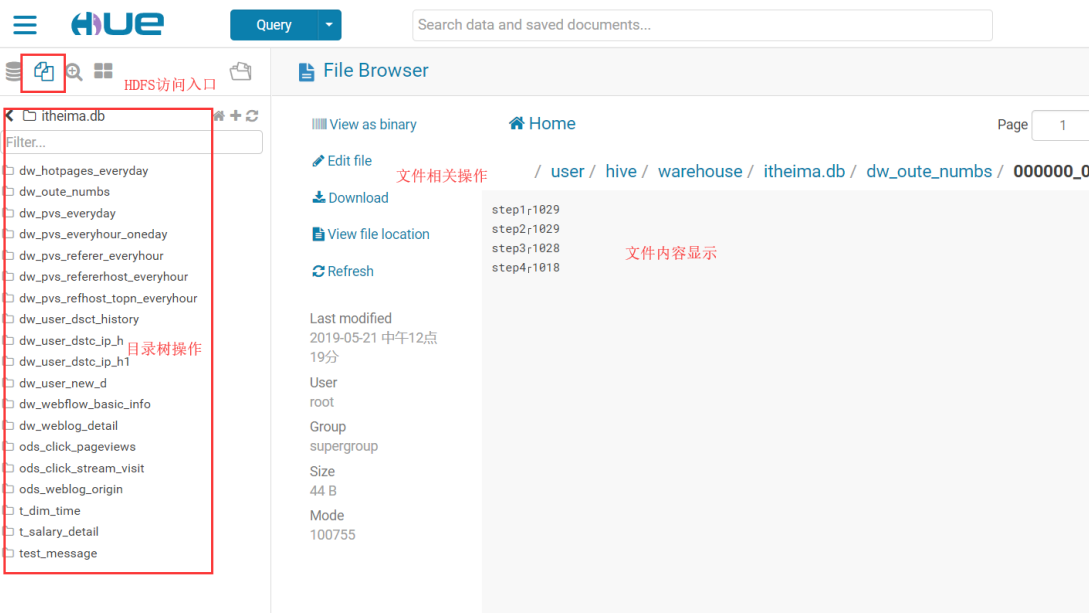
5.1. Hue 集成 HDFS
5.1.1 修改 core-site.xml 配置
1 <!—允许通过 httpfs 方式访问 hdfs 的主机名 --> 2 <property> 3 <name>hadoop.proxyuser.root.hosts</name> 4 <value>*</value> 5 </property> 6 <!—允许通过 httpfs 方式访问 hdfs 的用户组 --> 7 <property> 8 <name>hadoop.proxyuser.root.groups</name> 9 <value>*</value> 10 </property>
5.1.2 修改 hdfs-site.xml 配置
<property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property>
1 cd /export/servers/hue-3.9.0-cdh5.14.0/desktop/conf 2 vim hue.ini
1 [[hdfs_clusters]] 2 [[[default]]] 3 fs_defaultfs=hdfs://node-1:9000 4 webhdfs_url=http://node-1:50070 5 hadoop_hdfs_home= /export/servers/hadoop-2.7.5 6 hadoop_bin=/export/servers/hadoop-2.7.5/bin 7 hadoop_conf_dir=/export/servers/hadoop-2.7.5/etc/hadoop
5.1.4 重启 HDFS、Hue
1 start-dfs.sh 2 cd /export/servers/hue-3.9.0-cdh5.14.0/ 3 build/env/bin/supervisor
5.2.1.修改 hue.ini
1 [[yarn_clusters]] 2 [[[default]]] 3 resourcemanager_host=node-1 4 resourcemanager_port=8032 5 submit_to=True 6 resourcemanager_api_url=http://node-1:8088 7 history_server_api_url=http://node-1:19888
5.2.2.开启 yarn 日志聚集服务
1 <!--是否启用日志聚集功能。--> 2 <property> 3 <name>yarn.log-aggregation-enable</name> 4 <value>true</value> 5 </property> 6 <!--设置日志保留时间,单位是秒。--> 7 <property> 8 <name>yarn.log-aggregation.retain-seconds</name> 9 <value>106800</value> 10 </property>
5.2.3. 重启 Yarn、Hue
build/env/bin/supervisor
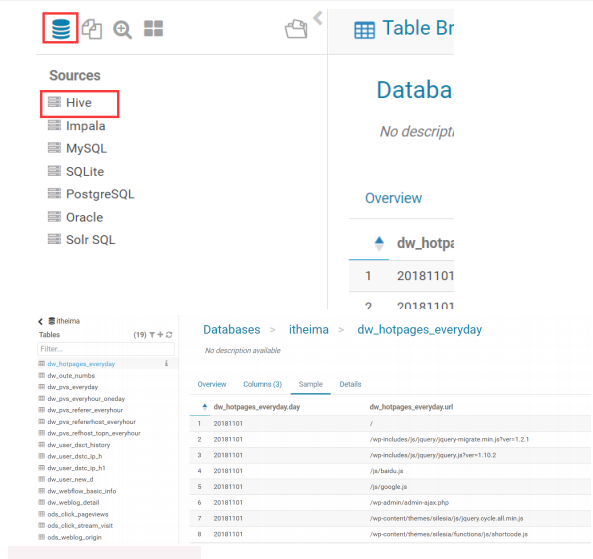
5.3. Hue 集成 Hive
如果需要配置 hue 与 hive 的集成,我们需要启动 hive 的 metastore 服务以及 hiveserver2 服务(impala 需要 hive 的 metastore 服务,hue 需要 hvie 的hiveserver2 服务)。
5.3.1.修改 Hue.ini
1 [beeswax] 2 hive_server_host=node-1 3 hive_server_port=10000 4 hive_conf_dir=/export/servers/hive/conf 5 server_conn_timeout=120 6 auth_username=root 7 auth_password=123456 8 [metastore] 9 #允许使用 hive 创建数据库表等操作 10 enable_new_create_table=true
5.3.2.启动 Hive 服务、重启 hue
去 node-3 机器上启动 hive 的 metastore 以及 hiveserver2 服务
cd /export/servers/hive nohup bin/hive --service metastore & nohup bin/hive --service hiveserver2 &
1 cd /export/servers/hue-3.9.0-cdh5.14.0/ 2 build/env/bin/supervisor
5.4 Hue 集成 Mysql
5.4.1.修改 hue.ini
需要把 mysql 的注释给去掉。 大概位于 1546 行
1 [[[mysql]]] 2 nice_name="My SQL DB" 3 engine=mysql 4 host=node-1 5 port=3306 6 user=root 7 password=hadoop
5.4.2. 重启 hue
5.5. Hue 集成 Oozie
5.5.1.修改 hue 配置文件 hue.ini
[liboozie] # The URL where the Oozie service runs on. This is required in order for # users to submit jobs. Empty value disables the config check. oozie_url=http://node-1:11000/oozie # Requires FQDN in oozie_url if enabled ## security_enabled=false # Location on HDFS where the workflows/coordinator are deployed when submitted. remote_deployement_dir=/user/root/oozie_works [oozie] # Location on local FS where the examples are stored. # local_data_dir=/export/servers/oozie-4.1.0-cdh5.14.0/examples/apps # Location on local FS where the data for the examples is stored. # sample_data_dir=/export/servers/oozie-4.1.0-cdh5.14.0/examples/input-data # Location on HDFS where the oozie examples and workflows are stored. # Parameters are $TIME and $USER, e.g. /user/$USER/hue/workspaces/workflow-$TIME # remote_data_dir=/user/root/oozie_works/examples/apps # Maximum of Oozie workflows or coodinators to retrieve in one API call. oozie_jobs_count=100 # Use Cron format for defining the frequency of a Coordinator instead of the old frequency number/unit. enable_cron_scheduling=true # Flag to enable the saved Editor queries to be dragged and dropped into a workflow. enable_document_action=true # Flag to enable Oozie backend filtering instead of doing it at the page level in Javascript. Requires Oozie 4.3+. enable_oozie_backend_filtering=true # Flag to enable the Impala action. enable_impala_action=true [filebrowser] # Location on local filesystem where the uploaded archives are temporary stored. archive_upload_tempdir=/tmp # Show Download Button for HDFS file browser. show_download_button=true # Show Upload Button for HDFS file browser. show_upload_button=true # Flag to enable the extraction of a uploaded archive in HDFS. enable_extract_uploaded_archive=true
#启动 hue 进程 cd /export/servers/hue-3.9.0-cdh5.14.0 build/env/bin/supervisor #启动 oozie 进程 cd /export/servers/oozie-4.1.0-cdh5.14.0 bin/oozied.sh start
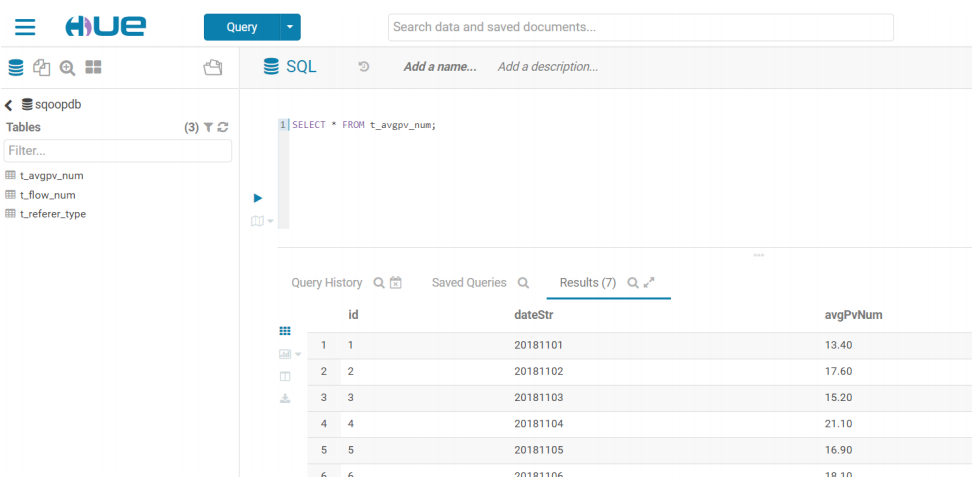
页面访问 hue
http://node-1:8888/
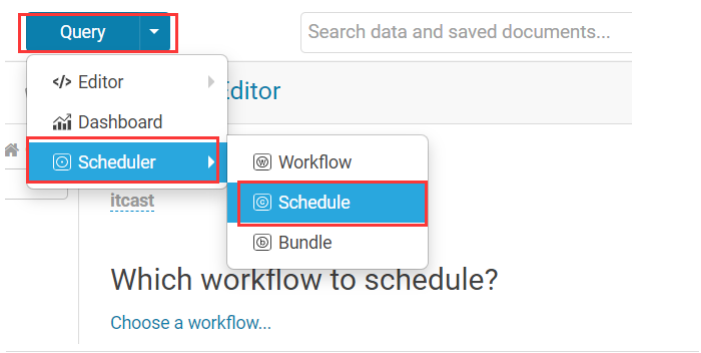
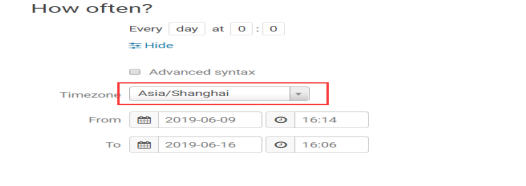
hue 提供了页面鼠标拖拽的方式配置 oozie 调度
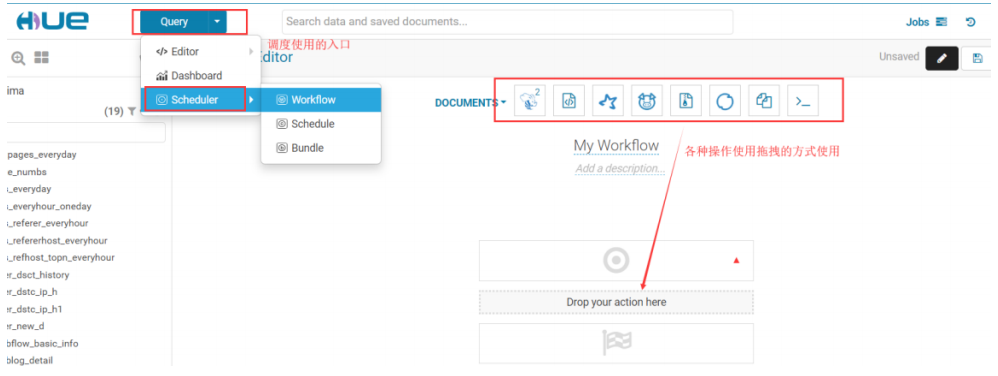
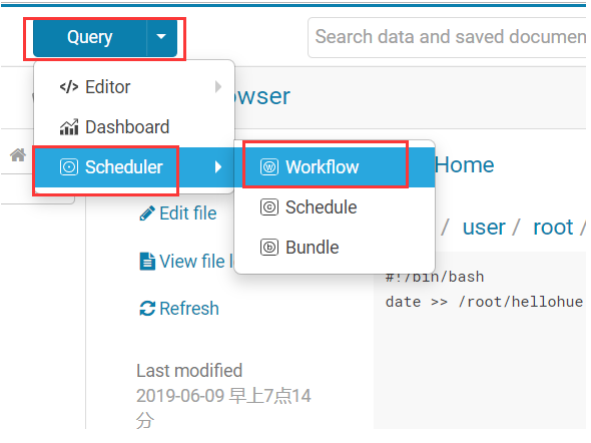
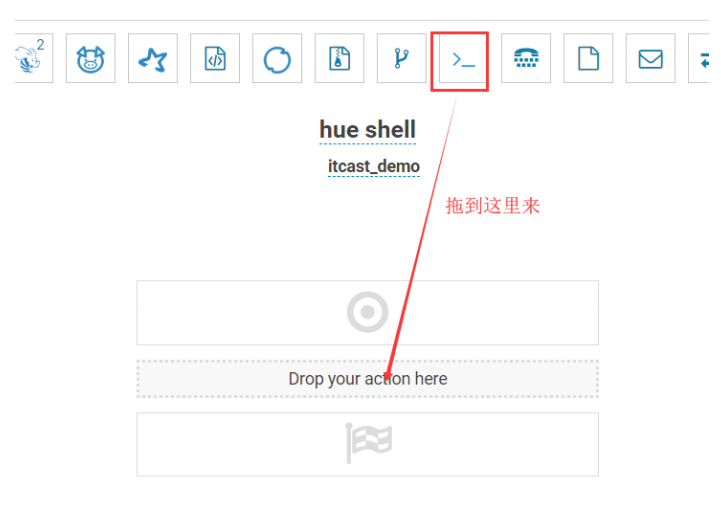
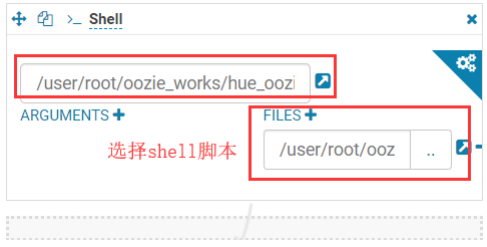
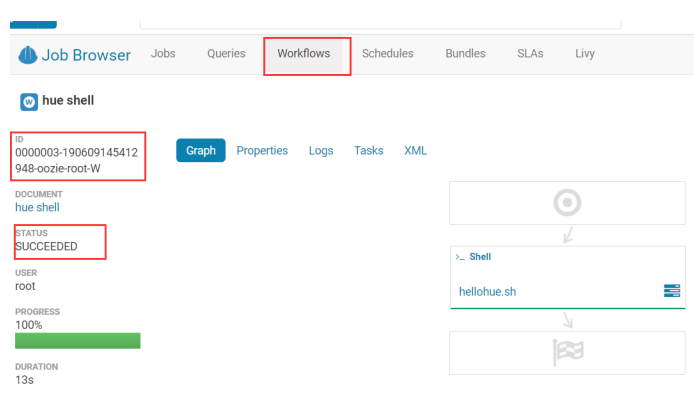
5.5.4.利用 hue 调度 shell 脚本
在 HDFS 上创建一个 shell 脚本程序文件。


打开工作流调度页面。
5.5.5.利用 hue 调度 hive 脚本
在 HDFS 上创建一个 hive sql 脚本程序文件。

打开 workflow 页面,拖拽 hive2 图标到指定位置。
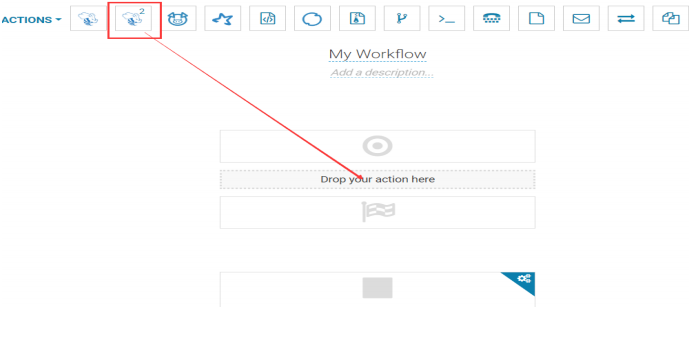

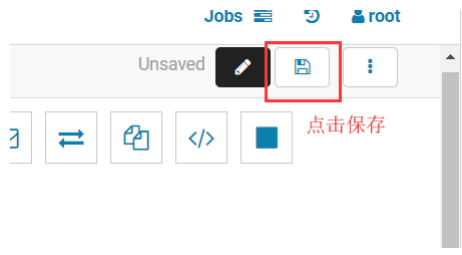
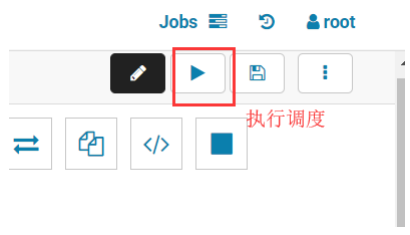
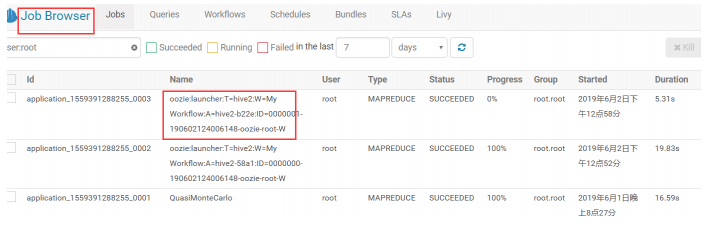
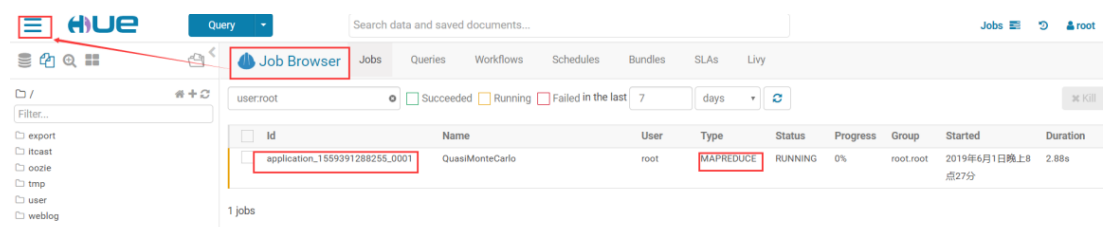
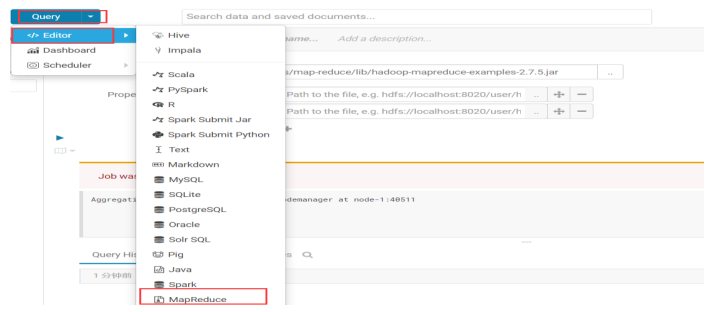
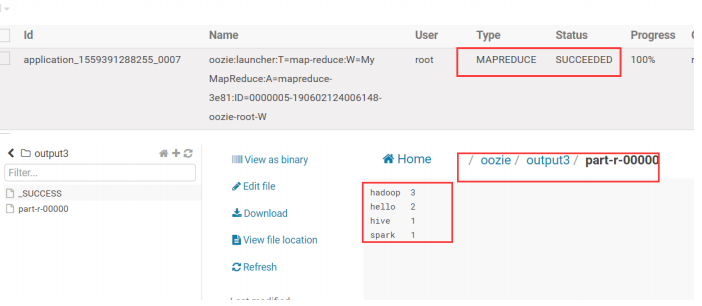
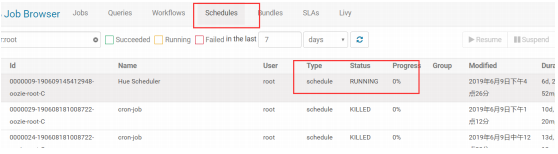
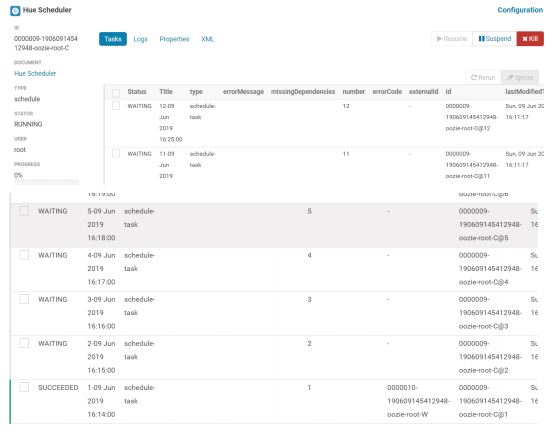
5.5.6.利用 hue 调度 MapReduce 程序
利用 hue 提交 MapReduce 程序




5.6. Hue 集成 Hbase
5.6.1.修改 hbase 配置1 <property> 2 <name>hbase.thrift.support.proxyuser</name> 3 <value>true</value> 4 </property> 5 <property> 6 <name>hbase.regionserver.thrift.http</name> 7 <value>true</value> 8 </property>
1 <property> 2 <name>hadoop.proxyuser.hbase.hosts</name> 3 <value>*</value> 4 </property> 5 <property> 6 <name>hadoop.proxyuser.hbase.groups</name> 7 <value>*</value> 8 </property>
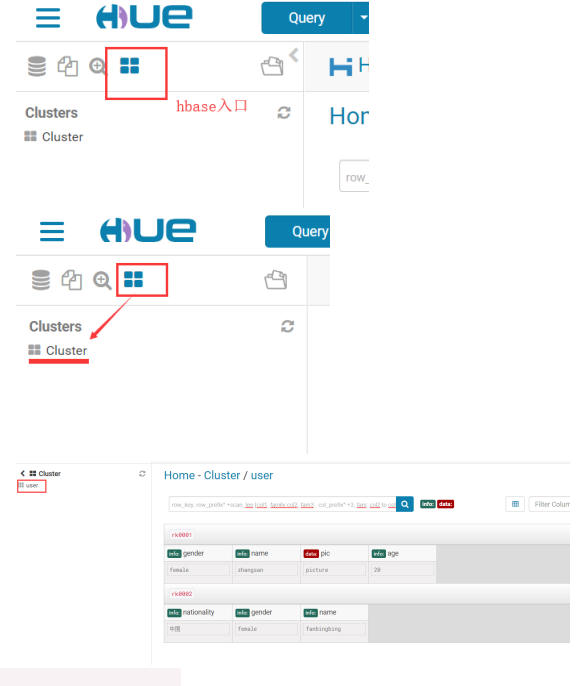
5.6.3.修改 Hue 配置
1 [hbase] 2 # Comma-separated list of HBase Thrift servers for clusters in the format of 3 '(name|host:port)'. 4 # Use full hostname with security. 5 # If using Kerberos we assume GSSAPI SASL, not PLAIN. 6 hbase_clusters=(Cluster|node-1:9090) 7 # HBase configuration directory, where hbase-site.xml is located. 8 hbase_conf_dir=/export/servers/hbase-1.2.1/conf 9 # Hard limit of rows or columns per row fetched before truncating. 10 ## truncate_limit = 500 11 # 'buffered' is the default of the HBase Thrift Server and supports security. 12 # 'framed' can be used to chunk up responses, 13 # which is useful when used in conjunction with the nonblocking server in Thrift. 14 thrift_transport=buffered
5.6.4.启动 hbase(包括 thrift 服务)、hue
1 #需要启动 hdfs 和 hbase,然后再启动 thrift。 2 start-dfs.sh 3 start-hbase.sh 4 hbase-daemon.sh start thrift 5 #重新启动 hue。 6 cd /export/servers/hue-3.9.0-cdh5.14.0/ 7 build/env/bin/supervisor
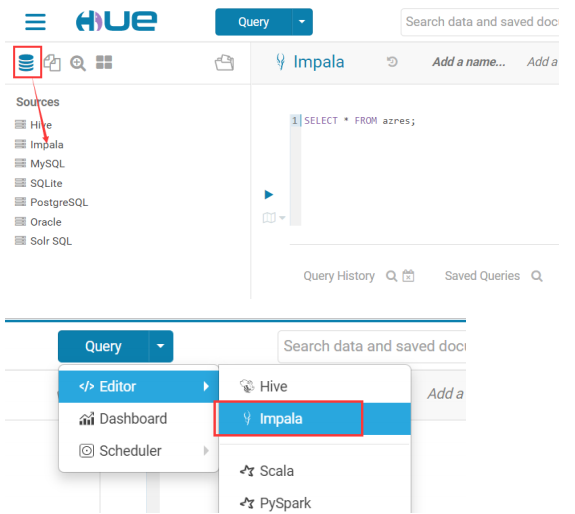
5.7.1.修改 Hue.ini
1 [impala] 2 server_host=node-3 3 server_port=21050 4 impala_conf_dir=/etc/impala/conf
5.7.2. 重启 Hue
到此我学过的软件基本上都集成到Hue上了,当然Hue的强大远不止如此,往后我学了新的软件会继续往上面集成的。
