


大数据之高可用Hadoop集群环境搭建
首先我们要明确一点,高可用的Hadoop环境之所以被称之为高可用,就是因为它所具备的容灾性更强,对分布式计算的能力更出众,来达到一种高可用的状态,那么就必然会有多个NameNode,ResourceManager的出现。那么我们的高可用的Hadoop环境资源分配如下图:
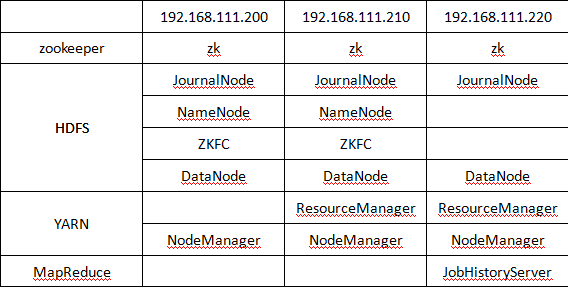
搭建集群
第一步:我们依然是把我们下载的安装包上传并解压。这里就不在详解了,之前写的文章反复写到了。
第二步:配置文件的修改,高可用与普通学习版差别就是在各个配置文件的内容中。
修改core-site.xml
1 <configuration> 2 <!-- 指定NameNode的HA高可用的zk地址 --> 3 <property> 4 <name>ha.zookeeper.quorum</name> 5 <value>node01:2181,node02:2181,node03:2181</value> 6 </property> 7 <!-- 指定HDFS访问的域名地址 --> 8 <property> 9 <name>fs.defaultFS</name> 10 <value>hdfs://ns</value> 11 </property> 12 <!-- 临时文件存储目录 --> 13 <property> 14 <name>hadoop.tmp.dir</name> 15 <value>/export/servers/hadoop-2.7.5/data/tmp</value> 16 </property> 17 <!-- 开启hdfs垃圾箱机制,指定垃圾箱中的文件七天之后就彻底删掉 18 单位为分钟 19 --> 20 <property> 21 <name>fs.trash.interval</name> 22 <value>10080</value> 23 </property> 24 </configuration>
修改hdfs-site.xml
1 <configuration> 2 <!-- 指定命名空间 --> 3 <property> 4 <name>dfs.nameservices</name> 5 <value>ns</value> 6 </property> 7 <!-- 指定该命名空间下的两个机器作为我们的NameNode --> 8 <property> 9 <name>dfs.ha.namenodes.ns</name> 10 <value>nn1,nn2</value> 11 </property> 12 13 <!-- 配置第一台服务器的namenode通信地址 --> 14 <property> 15 <name>dfs.namenode.rpc-address.ns.nn1</name> 16 <value>node01:8020</value> 17 </property> 18 <!-- 配置第二台服务器的namenode通信地址 --> 19 <property> 20 <name>dfs.namenode.rpc-address.ns.nn2</name> 21 <value>node02:8020</value> 22 </property> 23 <!-- 所有从节点之间相互通信端口地址 --> 24 <property> 25 <name>dfs.namenode.servicerpc-address.ns.nn1</name> 26 <value>node01:8022</value> 27 </property> 28 <!-- 所有从节点之间相互通信端口地址 --> 29 <property> 30 <name>dfs.namenode.servicerpc-address.ns.nn2</name> 31 <value>node02:8022</value> 32 </property> 33 34 <!-- 第一台服务器namenode的web访问地址 --> 35 <property> 36 <name>dfs.namenode.http-address.ns.nn1</name> 37 <value>node01:50070</value> 38 </property> 39 <!-- 第二台服务器namenode的web访问地址 --> 40 <property> 41 <name>dfs.namenode.http-address.ns.nn2</name> 42 <value>node02:50070</value> 43 </property> 44 45 <!-- journalNode的访问地址,注意这个地址一定要配置 --> 46 <property> 47 <name>dfs.namenode.shared.edits.dir</name> 48 <value>qjournal://node01:8485;node02:8485;node03:8485/ns1</value> 49 </property> 50 <!-- 指定故障自动恢复使用的哪个java类 --> 51 <property> 52 <name>dfs.client.failover.proxy.provider.ns</name> 53 <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> 54 </property> 55 56 <!-- 故障转移使用的哪种通信机制 --> 57 <property> 58 <name>dfs.ha.fencing.methods</name> 59 <value>sshfence</value> 60 </property> 61 62 <!-- 指定通信使用的公钥 --> 63 <property> 64 <name>dfs.ha.fencing.ssh.private-key-files</name> 65 <value>/root/.ssh/id_rsa</value> 66 </property> 67 <!-- journalNode数据存放地址 --> 68 <property> 69 <name>dfs.journalnode.edits.dir</name> 70 <value>/export/servers/hadoop-2.7.5/data/dfs/jn</value> 71 </property> 72 <!-- 启用自动故障恢复功能 --> 73 <property> 74 <name>dfs.ha.automatic-failover.enabled</name> 75 <value>true</value> 76 </property> 77 <!-- namenode产生的文件存放路径 --> 78 <property> 79 <name>dfs.namenode.name.dir</name> 80 <value>file:///export/servers/hadoop-2.7.5/data/dfs/nn/name</value> 81 </property> 82 <!-- edits产生的文件存放路径 --> 83 <property> 84 <name>dfs.namenode.edits.dir</name> 85 <value>file:///export/servers/hadoop-2.7.5/data/dfs/nn/edits</value> 86 </property> 87 <!-- dataNode文件存放路径 --> 88 <property> 89 <name>dfs.datanode.data.dir</name> 90 <value>file:///export/servers/hadoop-2.7.5/data/dfs/dn</value> 91 </property> 92 <!-- 关闭hdfs的文件权限 --> 93 <property> 94 <name>dfs.permissions</name> 95 <value>false</value> 96 </property> 97 <!-- 指定block文件块的大小 默认128M--> 98 <property> 99 <name>dfs.blocksize</name> 100 <value>134217728</value> 101 </property> 102 </configuration>
修改yarn-site.xml,注意三台机器都不一样,注释中有些,要细心。
1 <configuration> 2 <!-- Site specific YARN configuration properties --> 3 <!-- 是否启用日志聚合.应用程序完成后,日志汇总收集每个容器的日志,这些日志移动到文件系统,例如HDFS. --> 4 <!-- 用户可以通过配置"yarn.nodemanager.remote-app-log-dir"、"yarn.nodemanager.remote-app-log-dir-suffix"来确定日志移动到的位置 --> 5 <!-- 用户可以通过应用程序时间服务器访问日志 --> 6 7 <!-- 启用日志聚合功能,应用程序完成后,收集各个节点的日志到一起便于查看 --> 8 <property> 9 <name>yarn.log-aggregation-enable</name> 10 <value>true</value> 11 </property> 12 13 14 <!--开启resource manager HA,默认为false--> 15 <property> 16 <name>yarn.resourcemanager.ha.enabled</name> 17 <value>true</value> 18 </property> 19 <!-- 集群的Id,使用该值确保RM不会做为其它集群的active --> 20 <property> 21 <name>yarn.resourcemanager.cluster-id</name> 22 <value>mycluster</value> 23 </property> 24 <!--配置resource manager 命名--> 25 <property> 26 <name>yarn.resourcemanager.ha.rm-ids</name> 27 <value>rm1,rm2</value> 28 </property> 29 <!-- 配置第一台机器的resourceManager --> 30 <property> 31 <name>yarn.resourcemanager.hostname.rm1</name> 32 <value>node03</value> 33 </property> 34 <!-- 配置第二台机器的resourceManager --> 35 <property> 36 <name>yarn.resourcemanager.hostname.rm2</name> 37 <value>node02</value> 38 </property> 39 40 <!-- 配置第一台机器的resourceManager通信地址 --> 41 <property> 42 <name>yarn.resourcemanager.address.rm1</name> 43 <value>node03:8032</value> 44 </property> 45 <property> 46 <name>yarn.resourcemanager.scheduler.address.rm1</name> 47 <value>node03:8030</value> 48 </property> 49 <property> 50 <name>yarn.resourcemanager.resource-tracker.address.rm1</name> 51 <value>node03:8031</value> 52 </property> 53 <property> 54 <name>yarn.resourcemanager.admin.address.rm1</name> 55 <value>node03:8033</value> 56 </property> 57 <property> 58 <name>yarn.resourcemanager.webapp.address.rm1</name> 59 <value>node03:8088</value> 60 </property> 61 62 <!-- 配置第二台机器的resourceManager通信地址 --> 63 <property> 64 <name>yarn.resourcemanager.address.rm2</name> 65 <value>node02:8032</value> 66 </property> 67 <property> 68 <name>yarn.resourcemanager.scheduler.address.rm2</name> 69 <value>node02:8030</value> 70 </property> 71 <property> 72 <name>yarn.resourcemanager.resource-tracker.address.rm2</name> 73 <value>node02:8031</value> 74 </property> 75 <property> 76 <name>yarn.resourcemanager.admin.address.rm2</name> 77 <value>node02:8033</value> 78 </property> 79 <property> 80 <name>yarn.resourcemanager.webapp.address.rm2</name> 81 <value>node02:8088</value> 82 </property> 83 <!--开启resourcemanager自动恢复功能--> 84 <property> 85 <name>yarn.resourcemanager.recovery.enabled</name> 86 <value>true</value> 87 </property> 88 <!--在node3上配置rm1,在node2上配置rm2,在node1上不配置。根据你要搭建的集群框架来。注意:一般都喜欢把配置好的文件远程复制到其它机器上,
但这个在YARN的另一个机器上一定要修改--> 89 <property> 90 <name>yarn.resourcemanager.ha.id</name> 91 <value>rm1</value> 92 <description>If we want to launch more than one RM in single node, we need this configuration</description> 93 </property> 94 95 <!--用于持久存储的类。尝试开启--> 96 <property> 97 <name>yarn.resourcemanager.store.class</name> 98 <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> 99 </property> 100 <property> 101 <name>yarn.resourcemanager.zk-address</name> 102 <value>node02:2181,node03:2181,node01:2181</value> 103 <description>For multiple zk services, separate them with comma</description> 104 </property> 105 <!--开启resourcemanager故障自动切换,指定机器--> 106 <property> 107 <name>yarn.resourcemanager.ha.automatic-failover.enabled</name> 108 <value>true</value> 109 <description>Enable automatic failover; By default, it is enabled only when HA is enabled.</description> 110 </property> 111 <property> 112 <name>yarn.client.failover-proxy-provider</name> 113 <value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value> 114 </property> 115 <!-- 允许分配给一个任务最大的CPU核数,默认是8 --> 116 <property> 117 <name>yarn.nodemanager.resource.cpu-vcores</name> 118 <value>4</value> 119 </property> 120 <!-- 每个节点可用内存,单位MB --> 121 <property> 122 <name>yarn.nodemanager.resource.memory-mb</name> 123 <value>1024</value> 124 </property> 125 <!-- 单个任务可申请最少内存,默认1024MB --> 126 <property> 127 <name>yarn.scheduler.minimum-allocation-mb</name> 128 <value>1024</value> 129 </property> 130 <!-- 单个任务可申请最大内存,默认8192MB,根据你虚拟机的内存来,我虚拟机是4G,那么最多给它3G,不然其他软件运行容易出问题 --> 131 <property> 132 <name>yarn.scheduler.maximum-allocation-mb</name> 133 <value>3072</value> 134 </property> 135 <!--多长时间聚合删除一次日志 此处--> 136 <property> 137 <name>yarn.log-aggregation.retain-seconds</name> 138 <value>2592000</value><!--30 day--> 139 </property> 140 <!--时间在几秒钟内保留用户日志。只适用于如果日志聚合是禁用的--> 141 <property> 142 <name>yarn.nodemanager.log.retain-seconds</name> 143 <value>604800</value><!--7 day--> 144 </property> 145 <!--指定文件压缩类型用于压缩汇总日志--> 146 <property> 147 <name>yarn.nodemanager.log-aggregation.compression-type</name> 148 <value>gz</value> 149 </property> 150 <!-- nodemanager本地文件存储目录--> 151 <property> 152 <name>yarn.nodemanager.local-dirs</name> 153 <value>/export/servers/hadoop-2.7.5/yarn/local</value> 154 </property> 155 <!-- resourceManager 保存最大的任务完成个数 --> 156 <property> 157 <name>yarn.resourcemanager.max-completed-applications</name> 158 <value>1000</value> 159 </property> 160 <!-- 逗号隔开的服务列表,列表名称应该只包含a-zA-Z0-9_,不能以数字开始--> 161 <property> 162 <name>yarn.nodemanager.aux-services</name> 163 <value>mapreduce_shuffle</value> 164 </property> 165 166 <!--rm失联后重新链接的时间--> 167 <property> 168 <name>yarn.resourcemanager.connect.retry-interval.ms</name> 169 <value>2000</value> 170 </property> 171 </configuration>
修改mapred-site.xml
1 <configuration> 2 <!--指定运行mapreduce的环境是yarn --> 3 <property> 4 <name>mapreduce.framework.name</name> 5 <value>yarn</value> 6 </property> 7 <!-- MapReduce JobHistory Server IPC host:port --> 8 <property> 9 <name>mapreduce.jobhistory.address</name> 10 <value>node03:10020</value> 11 </property> 12 <!-- MapReduce JobHistory Server Web UI host:port --> 13 <property> 14 <name>mapreduce.jobhistory.webapp.address</name> 15 <value>node03:19888</value> 16 </property> 17 <!-- The directory where MapReduce stores control files.默认 ${hadoop.tmp.dir}/mapred/system --> 18 <property> 19 <name>mapreduce.jobtracker.system.dir</name> 20 <value>/export/servers/hadoop-2.7.5/data/system/jobtracker</value> 21 </property> 22 <!-- The amount of memory to request from the scheduler for each map task. 默认 1024--> 23 <property> 24 <name>mapreduce.map.memory.mb</name> 25 <value>1024</value> 26 </property> 27 <!-- <property> 28 <name>mapreduce.map.java.opts</name> 29 <value>-Xmx1024m</value> 30 </property> --> 31 <!-- The amount of memory to request from the scheduler for each reduce task. 默认 1024--> 32 <property> 33 <name>mapreduce.reduce.memory.mb</name> 34 <value>1024</value> 35 </property> 36 <!-- <property> 37 <name>mapreduce.reduce.java.opts</name> 38 <value>-Xmx2048m</value> 39 </property> --> 40 <!-- 用于存储文件的缓存内存的总数量,以兆字节为单位。默认情况下,分配给每个合并流1MB,给个合并流应该寻求最小化。默认值100--> 41 <property> 42 <name>mapreduce.task.io.sort.mb</name> 43 <value>100</value> 44 </property> 45 46 <!-- <property> 47 <name>mapreduce.jobtracker.handler.count</name> 48 <value>25</value> 49 </property>--> 50 <!-- 整理文件时用于合并的流的数量。这决定了打开的文件句柄的数量。默认值10--> 51 <property> 52 <name>mapreduce.task.io.sort.factor</name> 53 <value>10</value> 54 </property> 55 <!-- 默认的并行传输量由reduce在copy(shuffle)阶段。默认值5--> 56 <property> 57 <name>mapreduce.reduce.shuffle.parallelcopies</name> 58 <value>25</value> 59 </property> 60 <property> 61 <name>yarn.app.mapreduce.am.command-opts</name> 62 <value>-Xmx1024m</value> 63 </property> 64 <!-- MR AppMaster所需的内存总量。默认值1536--> 65 <property> 66 <name>yarn.app.mapreduce.am.resource.mb</name> 67 <value>1536</value> 68 </property> 69 <!-- MapReduce存储中间数据文件的本地目录。目录不存在则被忽略。默认值${hadoop.tmp.dir}/mapred/local--> 70 <property> 71 <name>mapreduce.cluster.local.dir</name> 72 <value>/export/servers/hadoop-2.7.5/data/system/local</value> 73 </property> 74 </configuration>
修改slaves
1 node01 2 node02 3 node03
修改hadoop-env.sh
1 export JAVA_HOME=/export/servers/jdk1.8.0_141
第一台机器环境已经配好,然后scp 拷贝到其他两台机器,切记一定要记得去修改yarn-site.xml 三台机器都不一样。
启动集群的过程,记住一步一步来,不要跳过,否则各种错的你心态爆炸
启动集群
启动HDFS过程
1 cd /export/servers/hadoop-2.7.5 2 bin/hdfs zkfc -formatZK 3 sbin/hadoop-daemons.sh start journalnode 4 #这一步只在第一次搭建完启动的时候执行,其他时候切记不可执行,否则数据全部格式化 5 bin /hdfs namenode -format 6 bin/hdfs namenode -initializeSharedEdits -force 7 sbin/start-dfs.sh
node02上面执行
cd /export/servers/hadoop-2.7.5 #让第二台NameNode为Standby状态 bin/hdfs namenode -bootstrapStandby #后台启动NameNode sbin/hadoop-daemon.sh start namenode
启动yarn过程
node03执行
1 cd /export/servers/hadoop-2.7.5 2 sbin/start-yarn.sh
node02执行
cd /export/servers/hadoop-2.7.5 sbin/start-yarn.sh
查看ResourceManager状态
node03执行
cd /export/servers/hadoop-2.7.5 bin/yarn rmadmin -getServiceState rm1
查询结果为Active就说明成功了
node02执行
1 cd /export/servers/hadoop-2.7.5 2 bin/yarn rmadmin -getServiceState rm2
查询结果为Active就说明成功了
启动jobHistory服务
1 cd /export/servers/hadoop-2.7.5 2 sbin/mr-jobhistory-daemon.sh start historyserver
检查集群启动情况
三台机器分别输入命令jps
第一台机器进程中应该具备NameNode、DataNode、JournalNode、NodeManager、DFSZKFailoverController这些进程,否则就可能是哪里启动失败了,看少了哪个进程。NameNode HDFS 主节点进程、DataNode HDFS 从节点进程、JournalNode HDFS共享数据进程、NodeManager yarn 从节点进程、DFSZKFailoverController Zookeeper资源调度进程。
第二台机器进程中应该具备NameNode、DataNode、JournalNode、ResourceManager、NodeManager、DFSZKFailoverController这些进程,否则就可能是哪里启动失败了,看少了哪个进程。NameNode HDFS 主节点进程、DataNode HDFS 从节点进程、JournalNode HDFS共享数据进程、ResourceManager yarn 主节点进程、NodeManager yarn 从节点进程、DFSZKFailoverController Zookeeper资源调度进程。
第三台机器进程中应该具备DataNode、JournalNode、ResourceManager、NodeManager、DFSZKFailoverController、JobHistoryServer这些进程,否则就可能是哪里启动失败了,看少了哪个进程。NameNode HDFS 主节点进程、DataNode HDFS 从节点进程、JournalNode HDFS共享数据进程、ResourceManager yarn 主节点进程、NodeManager yarn 从节点进程、DFSZKFailoverController Zookeeper资源调度进程、JobHistoryServer任务执行历史进程。
这些进程缺一不可,缺少了任何一个Hadoop集群都说明集群搭建出了问题。确认无误之后,就在Windows主机上访问以下网站,进行进一步的确认。
node01机器查看hdfs状态
http://node01:50070/dfshealth.html#tab-overview
node02机器查看hdfs状态
http://node02:50070/dfshealth.html#tab-overview
yarn集群访问查看
http://node03:8088/cluster
历史任务浏览界面
页面访问:
http://192.168.111.220:19888/jobhistory
如果上面的地址都能正常打开,说明这次你的高可用Hadoop集群就搭建成功了。

