
Spark 2.x 中 Sort-Based Shuffle 产生的内幕
本课主题
- Sorted-Based Shuffle 的诞生和介绍
- Shuffle 中六大令人费解的问题
- Sorted-Based Shuffle 的排序和源码鉴赏
- Shuffle 在运行时的内存管理
引言
在历史的发展中,为什么 Spark 最终还是选择放弃了 HashShuffle 而使用了 Sorted-Based Shuffle,而且作为后起之秀的 Tungsten-based Shuffle 它到底在什么样的背景下产生的。Tungsten-Sort Shuffle 已经并入了 Sorted-Based Shuffle,Spark 的引擎会自动识别程序需要原生的 Sorted-Based Shuffle 还是用 Tungsten-Sort Shuffle,那识别的依据是什么,其实 Spark 会检查相对的应用程序有没有 Aggregrate 的操作。文章的后续部份会介绍 Tungsten-Sort Shuffle 是如何管理内存和CPU。其实 Sorted-Based Shuffle 也有缺点,其缺点反而是它排序的特性,它强制要求数据在 Mapper 端必须要先进行排序 (注意,这里没有说对计算结果进行排序),所以导致它排序的速度有点慢。而 Tungsten-Sort Shuffle 对它的排序算法进行了改进,优化了排序的速度。希望这篇文章能为读者带出以下的启发:
- 了解为什么 Spark 最终选择了 Sorted-Based Shuffle 而放弃了Hash-Based Shuffle
- 了解什么是 Spark Sorted-Based Shuffle
- 了解 Spark Shuffle 中六大令人费解的问题
- 了解 Sorted-Based Shuffle 具体是如何排序
Spark Sorted-Based Shuffle 的诞生
为什么 Spark 用 Sorted-Based Shuffle 而放弃了 Hash-Based Shuffle?在 Spark 里为什么最终是 Sorted-Based Shuffle 成为了核心,有基本了解过 Spark 的学习者都会知道,Spark会根据宽依赖把它一系列的算子划分成不同的 Stage,Stage 的内部会进行 Pipeline,Stage 与 Stage 之间进行 Shuffle,Shuffle 的过程包含三部份。
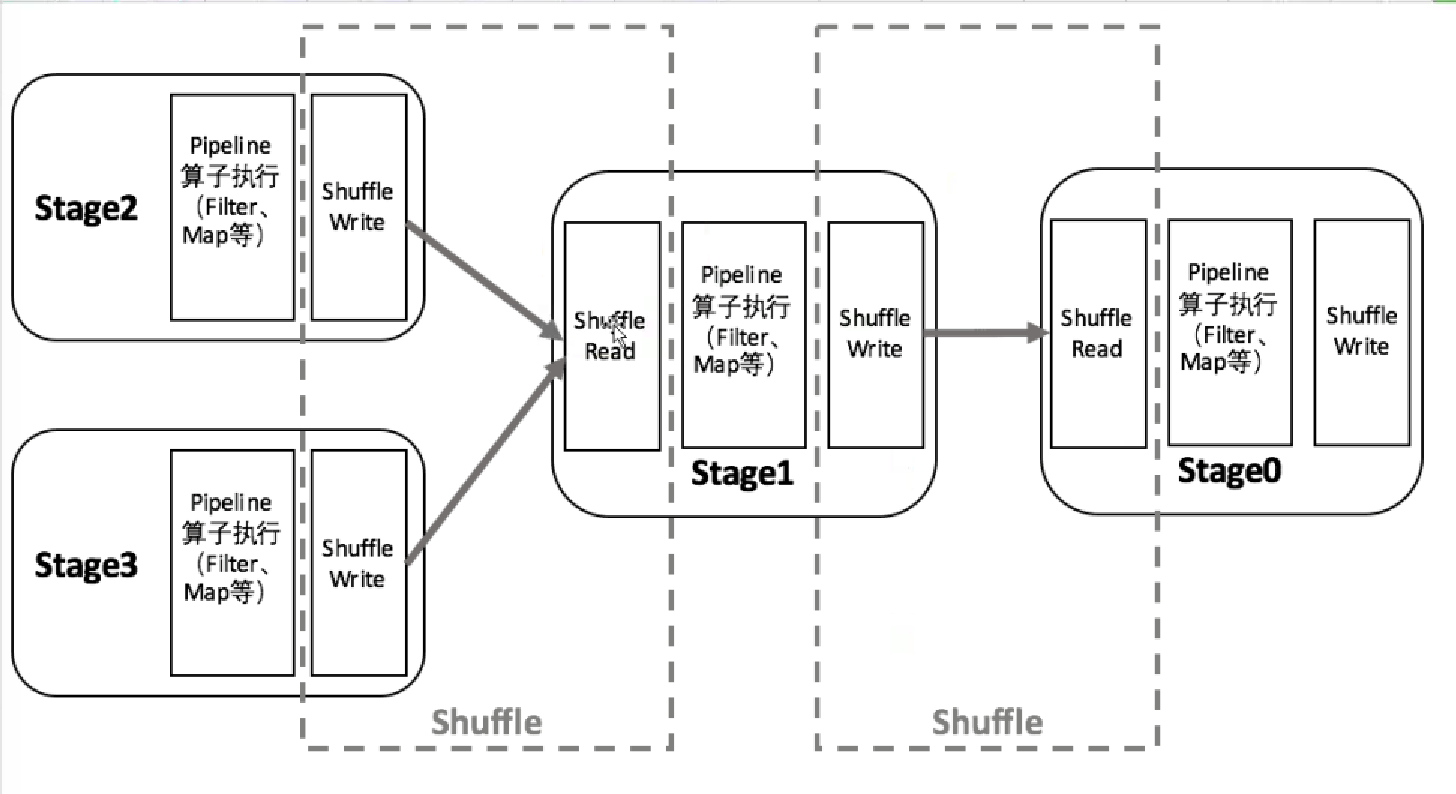
第一部份是 Shuffle 的 Write;第二部份是网络的传输;第三部份就是 Shuffle 的 Read,这三大部份设置了内存操作、磁盘IO、网络IO以及 JVM 的管理。而这些东西影响了 Spark 应用程序在 95%以上效率的唯一原因,假设你程序代码的质素本身是非常好的情况下,你性能的95%都消耗在 Shuffle 阶段的本地写磁盘文件,网络传输数据以及抓取数据这样的生命周期中。
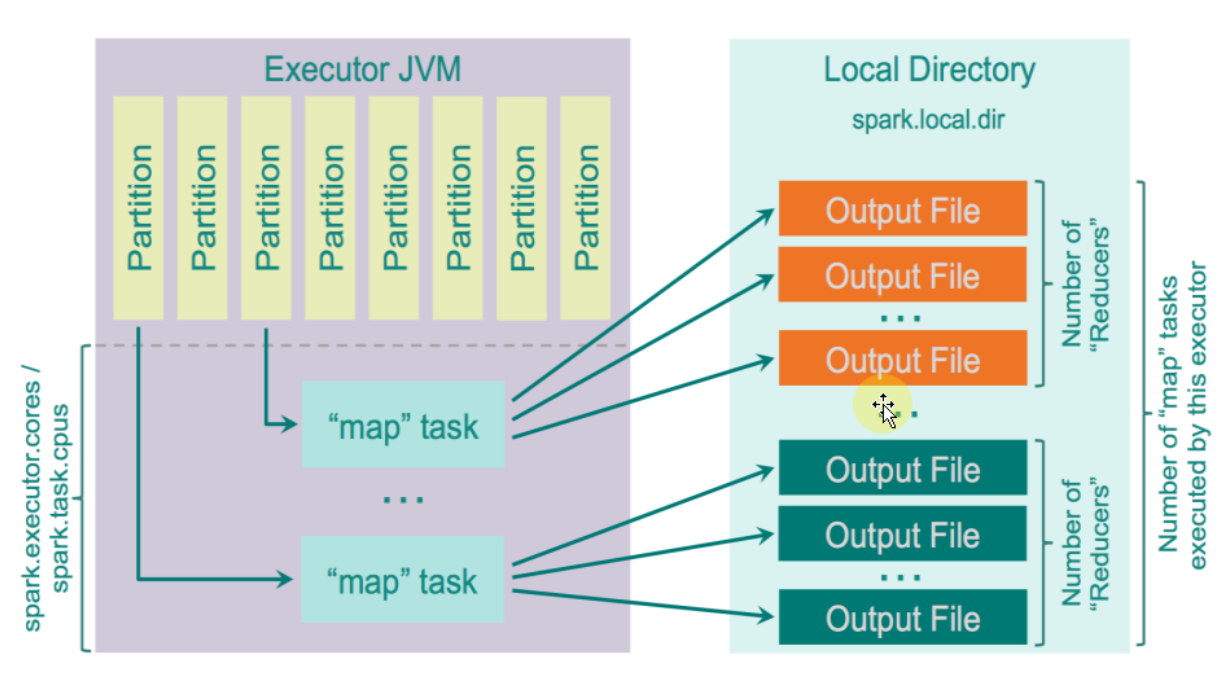
在 Shuffle 写数据的时候,内存中有一个缓存区叫 Buffer,你可以想像成一个Map,同时在本地磁盘有相对应的本地文件。如果本地磁盘有文件你在内存中肯定也需要有相对应的管理句柄。也就是说,单是从 ShuffleWrite 内存占用的角度讲,已经有一部份内存空间是用在存储 Buffer 数据的,另一部份的内存空间是用来管理文件句柄的,回顾 HashShuffle 所产生小文件的个数是 Mapper 分片数量 x Reducer 分片数量 (MxR)。比如Mapper端有1千个数据分片,Reducer端也有1千过数据分片,在 HashShuffle 的机制下,它在本地内存空间中会产生 1000 * 1000 = 1,000,000 个小文件,可想而知的结果会是什么,这么多的 IO,这么多的内存消耗、这么容易产生 OOM、以及这么沉重的 CG 负担。再说,如果Reducer端去读取 Mapper端的数据时,Mapper 端有这么多的小文件,要打开很多网络通道去读数据,打开 1,000,000 端口不是一件很轻松的事。这会导致一个非常经典的错误:Reducer 端也就是下一个 Stage 通过 Driver 去抓取上一个 Stage 属于它自己的数据的时候,说文件找不到。其实这个时候不是真的是磁盘上文件找不到,而是程序不响应,因为它在进行垃圾回收 (GC) 操作。
因为 Spark 想完成一体化多样化的数据处理中心或者叫一统大数据领域的一个美梦,肯定不甘心于自己只是一个只能处理中小规模的数据计算平台,所以Spark最根本要优化和逼切要解决的问题是:减少 Mapper 端 ShuffleWriter 所产生的文件数量,这样便可以能让 Spark 从几百台集群的规模中瞬间变成可以支持几千台甚至几万台集群的规模。(一个Task背后可能是一个Core去运行、也可能是多个Core去运行,但默认情况下是用一个Core去运行一个Task)。
减少Mapper端的小文件所带来的好处是:
- Mapper端的内存占用变少了;
- Spark可以处理不竟竟是小规模的数据,处理大规模的数据也不会很容易达到性能瓶颈;
- Reducer端抓取数据的次数也变少了;
- 网络通道的句柄也变少;
- 极大了减少 Reducer 的内存不竟竟是因为数据级别的消耗,而且是框架时要运行的必须消耗。
Spark Sorted-Based Shuffle介绍
Sorted-Based Shuffle 的出现,最显著的优势就是把 Spark 从只能处理中小规模的数据平台,变成可以处理无限大规模的数据平台。可能你会问规模真是这么重要吗?当然有,集群规模意为著它处理数据的规模,也意为著它的运算能力。
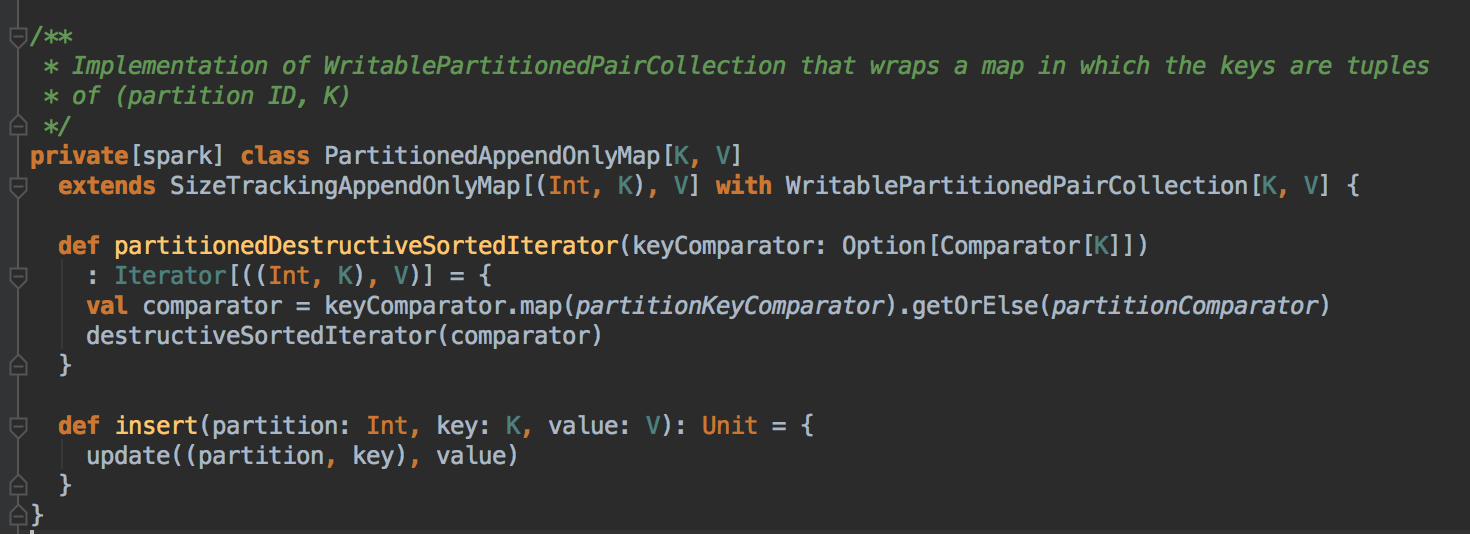
Sorted-Based Shuffle 不会为每个Reducer 中的Task 生产一个单独的文件,相反Sorted-Based Shuffle 会把Mapper 中每个ShuffleMapTask 所有的输出数据Data 只写到一个文件中,因为每个ShuffleMapTask 中的数据会被分类,所以Sort-based Shuffle 使用了index 文件存储具体ShuffleMapTask 输出数据在同一个Data 文件中是如何分类的信息。所以说基于 Sort-based Shuffle 会在 Mapper 中的每一个 ShuffleMapTask 中产生两个文件 (并发度的个数 x 2)!!!
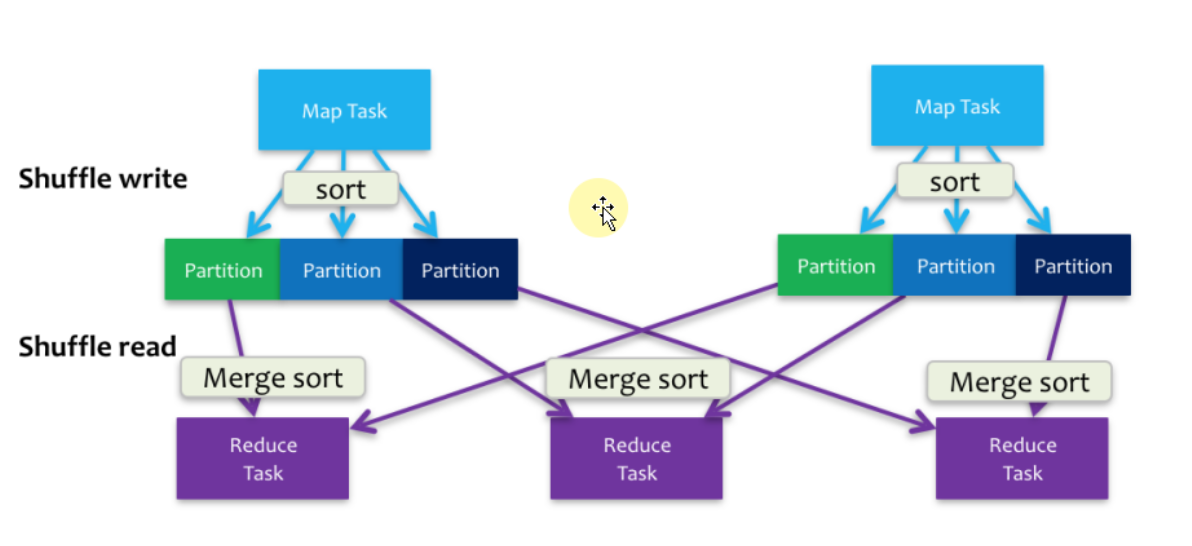
它会产生一个 Data 文件和一个 Index 文件,其中 Data 文件是存储当前 Task 的 Shuffle 输出的, 而 Index 文件则存储了 Data 文件中的数据通过 Partitioner 的分类信息,此时下一个阶段的 Stage 中的 Task 就是根据这个 Index 文件获取自己所需要抓取的上一个 Stage 中 ShuffleMapTask 所产生的数据;
假设现在 Mapper 端有 1000 个数据分片,Reducer 端也有 1000 个数据分片,它的并发度是100,使用 Sorted-Based Shuffle 会产生多少个 Mapper端的小文件,答案是 100 x 2 = 200 个。它的 MapTask 会独自运行,每个 MapTask 在运行的时候写2个文件,运行成功后就不需要这个 MapTask 的文件句柄,无论是文件本身的句柄还是索引的句柄都不需要,所以如果它的并发度是 100 个 Core,每次运行 100 个任务的话,它最终只会占用 200 个文件句柄,这跟 HashShuffle 的机制不一样,HashShuffle 最差的情况是 Hashed 句柄存储在内存中的。
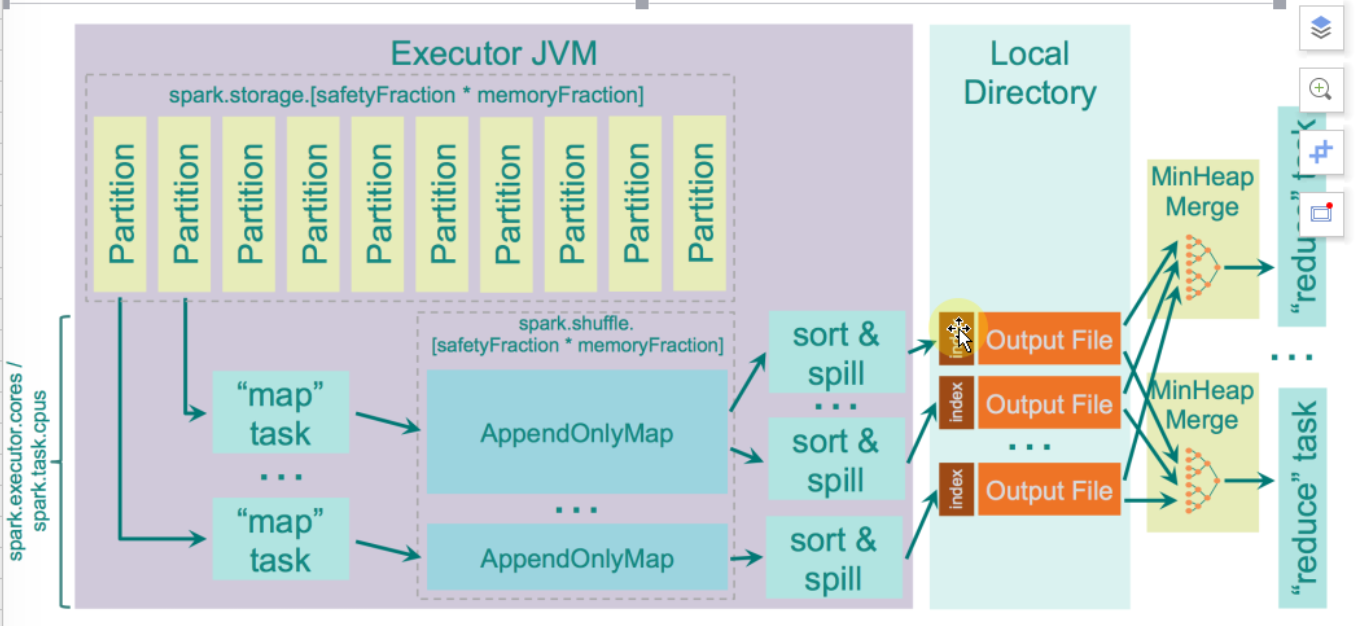
Sorted-Based Shuffle 主要是在Mapper阶段,这个跟Reducer端没有任何关系,在Mapper阶段它要进行排序,你可以认为是二次排序,它的原理是有2个Key进行排序,第一个是 PartitionId进行排序,第二个是就是本身数据的Key进行排序。看下图,它会把 PartitionId 分成3个,分别是索引为 0、1、2,这个在Mapper端进行排序的过程其实是让Reducer去抓取数据的时候变得更高效,比如说第一个Reducer,它会到Mappr端的索引为 0 的数据分片中抓取数据。
具体而言,Reducer 首先找 Driver 去获取父 Stage 中每个 ShuffleMapTask 输出的位置信息,跟据位置信息获取 Index 文件,解析 Index 文件,从解析的 Index 文件中获取 Data 文件中属于自己的那部份内容。
一个Mapper任务除了有一个数据文件以外,它也会有一个索引文件,Map Task 把数据写到文件磁盘是顺序根据自身的Key写进去的,也同时按照 Partition写进去的,因为它是顺序写数据,记录每个 Partition 的大小。
Sort-Based Shuffle 的弱点:
- 如果 Mapper 中 Task 的数量过大,依旧会产生很多小文件,此时在 Shuffle 传数据的过程中到 Reducer 端,Reducer 会需要同时大量的记录来进行反序例化,导致大量内存消耗和GC 的巨大负担,造成系统缓慢甚至崩溃!
- 强制了在 Mapper 端必顺要排序,这里的前提是本身数据根本不需要排序的话;
- 如果需要在分片内也进行排序的话,此时需要进行 Mapper 端和 Reducer 端的两次排序!
- 它要基于记录本身进行排序,这就是 Sort-Based Shuffle 最致命的性能消耗;
Shuffle 中六大令人费解的问题
- 第一大问题:什么时候进行 Shuffle 的 fetch 操作?Shuffle 是在一边进行 Mapper 端 map 操作的同时,一边进行 Reducer 端的 shuffle 和 reduce 操作吗?
错误的观点是:Spark 是一边 Mapper 一边 Shuffle 的,而 Hadoop MapReduce 是先完成 Mapper 然后才进行 Reducer 的 Shuffle。正确的观点是 Spark 一定是先完成 Mapper 端所有的 Tasks,才会进行 Reducer 端的 Shuffle 过程。这是因为 Spark Job 是按照 Stage 线性执行的,前面的 Stage 必须执行完毕,才能够执行后面 Reducer 端的 Shuffle 过程。
- 更准确来说 Spark Shuffle 的过程是边拉取数据边进行 Aggregrate 操作的,其实与 Hadoop MapReduce 相比其优势确实是在速度上,但是也会导致一些算法不好实现,例如求平均值等,为什么呢?因为边拉取数据边进行 Aggregrate 这个过程中,后面的Stage依赖于前面的Stage,Spark 是以 Stage 为单位进行计算的,如果里面的任务没有计算完,后面你怎么计算呢。但如果你是求和的话,它就会计算的特别快;
- Hadoop MapReduce 是把数据拉过来之后,然后进行计算,如果用 MapReduce 求平均值的话,它的算法就会很好实现。
- 第二大问题:Shuffle fetch 过来的数据到底放在了那里?
Spark 这种很灵活地使用并行度以及倾向于优先使用内存的计算模型,如果不正常地使用这些特徵的话会很容易导致 Spark 的应用程序出现 OOM 的情况,Spark 在不同的版本 fetch 过来的数据放在哪里是有不同的答案。抓过来的数据首先会放在 Reducer 端的内存缓存区中,Spark曾经有版本要求只能放在内存缓存中,其数据结构类似于 HashMap (AppendOnlyMap),显然这个设计特别消耗内存和极易出现OOM,同时这也极大的限制了 Spark 集群的规模,现在的实现都是内存 + 磁盘的方式 (数据结构类使用了 ExternalAppendOnlyMap),当然也可以通过调以下参数来设置只能使用内存。
1spark.shuffle.spill=false如果设置了这个运行模式,在生产环境下建义对内存的数据作2份备份,因为在默认情况下内存数据只有1份,它不像HDFS那样,天然有3份备份。使用 ExternalAppendOnlyMap 的方式时,如果内存占用率达到一定的临界值后会首先尝试在内存中扩大 ExternalAppendOnlyMap (内部有实现算法),如果不能扩容的话才会 spill 到磁盘。
-
第三大问题:Shuffle 的数据在 Mapper 端如何存储,在 Reducer 端如何知道数据具体在那里的?在Spark的实现上每一个Stage (里面是 ShuffleMapTask) 中的 Task 在 Stage 的最后一个 RDD 上一定会注册给 Driver 上的 MapOutputTrackerMaster,Mapper 通过和 MapOutputTrackerMaster 来汇报 ShuffleMapTask 具体输出数据的位置 (具体的输出文件及内容是和 Reducer 有关的),Reducer 是向 Driver 中的 MapOutputTrackerMaster 请求数据的元数据信息,然后和 Mapper 所在的 Executor 进行通信。
- 第四大问题:竟竟从 HashShuffle 的角度来讲,我们在 Shuffle 的时候到底可以产生多少 Mapper 端的中间文件?
这里有一个很重要的调优参数 (可以在 TaskSchedulerImpl.scala 中找到此参数),该参数决定了 Spark 在运行时每个 Task 所需要的 Core 的个数,默认情况是1个,现在假设 spark.task.cpus=T。![]()
- 问题一、例如说有M个Mapper、R个Reducer 和 C个Core,那么 HashShuffle 可以产生多少个 Mapper 的中间文件?
- HashShuffle 会产生 C x R 的小文件。
- Consolidated HashShuffle 有可能产生 C x R 个小文件。因为设置了 spark.task.cpus 的参数,那么真实的答案是 (C / T) x R 个小文件。
- 问题二、例如在生产环境下有 E 个 Executors (例如100个),每个 Executor上有 C 个Cores (例如10个),同时也有 R 个Reducer,那么 HashShuffle 可以产生多少个 Mapper 的中间文件?
- HashShuffle 会产生实际 Task 的个数 x R 个的小文件。
- Consolidated HashShuffle 会产生 (E x (C / T)) x R 个的小文件。
- 问题一、例如说有M个Mapper、R个Reducer 和 C个Core,那么 HashShuffle 可以产生多少个 Mapper 的中间文件?
- 第五大问题:Spark中Sorted-Based Shuffle 数据结果默认是排序的吗?Sorted-Based Shuffle 采用了什么的排序算法?这个排序算法的好处是什么?
Spark Sorted-Based Shuffle 在 Mapper 端是排序的,包括 partition 的排序和每个 partition 内部元素的排序!但在 Reducer 端是没有进行排序,所以 Job 的结果默认不是排序的。Sorted-Based Shuffle 采用了 Tim-Sort 排序算法,好处是可以极为高效的使用 Mapper 端的排序成果全局排序。 - 第六大问题:Spark Tungsten-Sorted Shuffle 在 Mapper 中会对内部元素进行排序吗?Tungsten-Sorted Shuffle不适用于什么情况?说出具体的原因。
Tungsten-Sorted Shuffle 在 Mapper 中不会对内部元素进行排序 (它只会对Partition进行排序),原因是它自己管理的二进制序列化后的数据,问题来啦:数据是进入 Buffer 时或者是进入磁盘的时才进行排序呢?答案是数据的排序是发生在 Buffer 要满了 spill 到磁盘时才进行排序的。所以 Tungsten-Sorted Shuffle 它对内部不会进行排序
Tungsten-Sorted Shuffle 什么时候会退化成为 Sorted-Based Shuffle?它是在程序有 Aggregrate 操作的时候;或者是 Mapper 端输出的 partition 大于 16777216;或者是一条 Record 大于128M的时候,原因也是因为它自己管理的二进制序列化后的数据以及数组指针管理范围。
Sorted-Based Shuffle 的排序算法
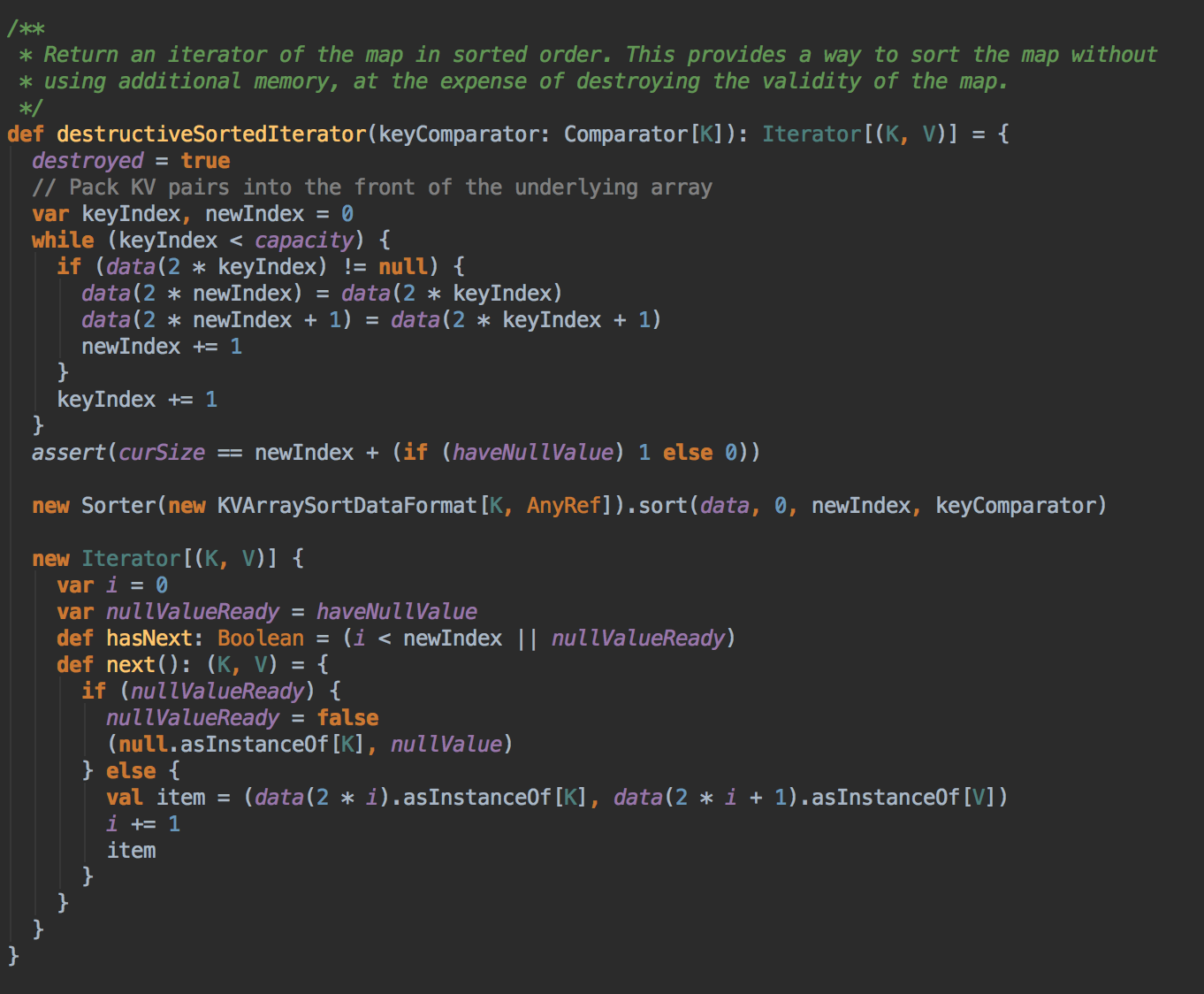
人们会对 Sorted-Based Shuffle 有一种误解,就是它产出的结果是有序的,这一节会讲解 Sorted-Based Shuffle 是如何工作的并配合源码看看它具体的实现,Sorted-Based Shuffle 的核心是借助于 ExternalSorter 把每个 ShuffleMapTask 的输出排序到一个文件中 (FileSegmentGroup),为了区分下一个阶段 Reducer Task 不同的内容,它还需要有一个索引文件 (Index) 来告诉下游 Stage 的并行任务,那一部份是属于你的。
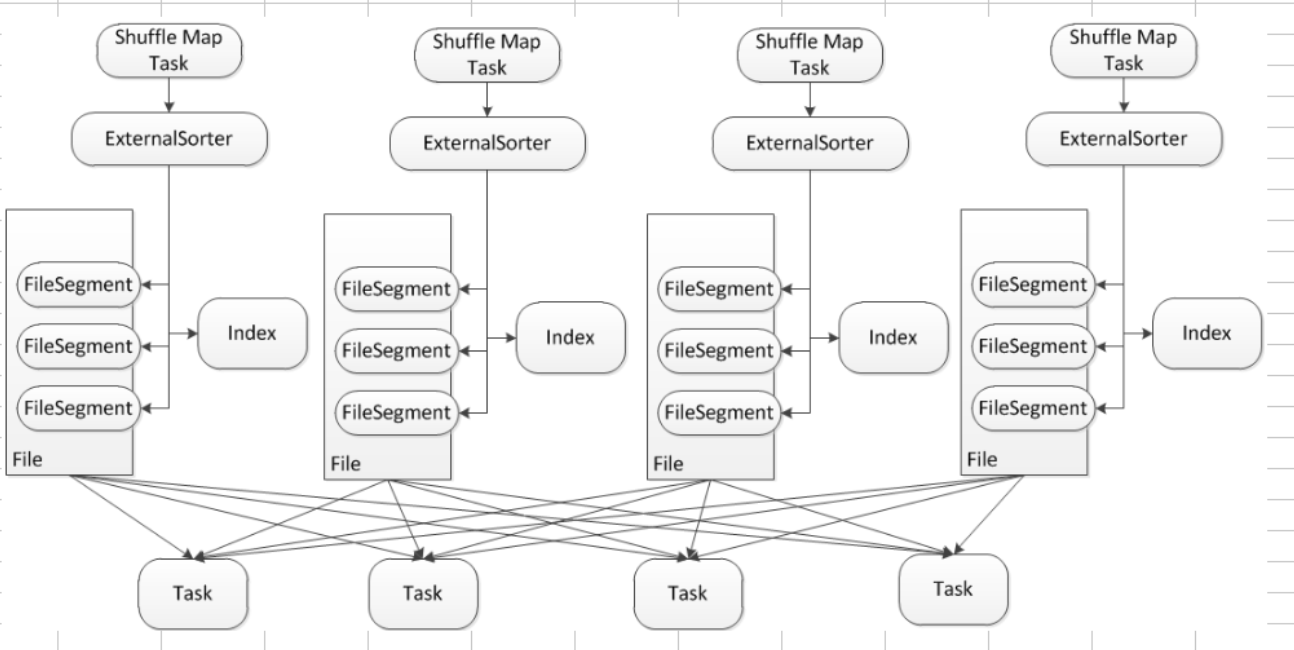
上图在 Reducer 端有4个Reducer Task,它会产生一组 File Group 和 一个索引文件,File Group 里的 FileSegement 会进行排序,下游的 Task 可以很容易跟据索引 (index) 定位到这个 Fie 中的那一部份 FileSegement 是属于下游的,它相当于一个指针,下游的 Task 要向 Driver 去碓定文件在那里,然后到了这个 File 文件所在的地方,实际上会跟 BlockManager 进行沟通,BlockManager 首先会读一个 Index 文件,根据它的命名则进行解析,比如说下一个阶段的第一个 Task,一般就是抓取第一个 Segment,这是一个指针定位的过程。
再次强调 Sort-Based Shuffle 最大的意义是减少临时文件的输出数量,且只会产生两个文件:一个是包含不同内容划分成不同 FileSegment 构成的单一文件 File,另外一个是索引文件 Index。上图在 Sort-Based Shuffle 的介绍中看见了一个 Sort and Spill 的过程 (它是 Spill 到磁盘的时候再进行排序的),现在我们从源码的角度去看看到底它这个排序实际上是在干什么的。
Sort-Based Shuffle 排序源码
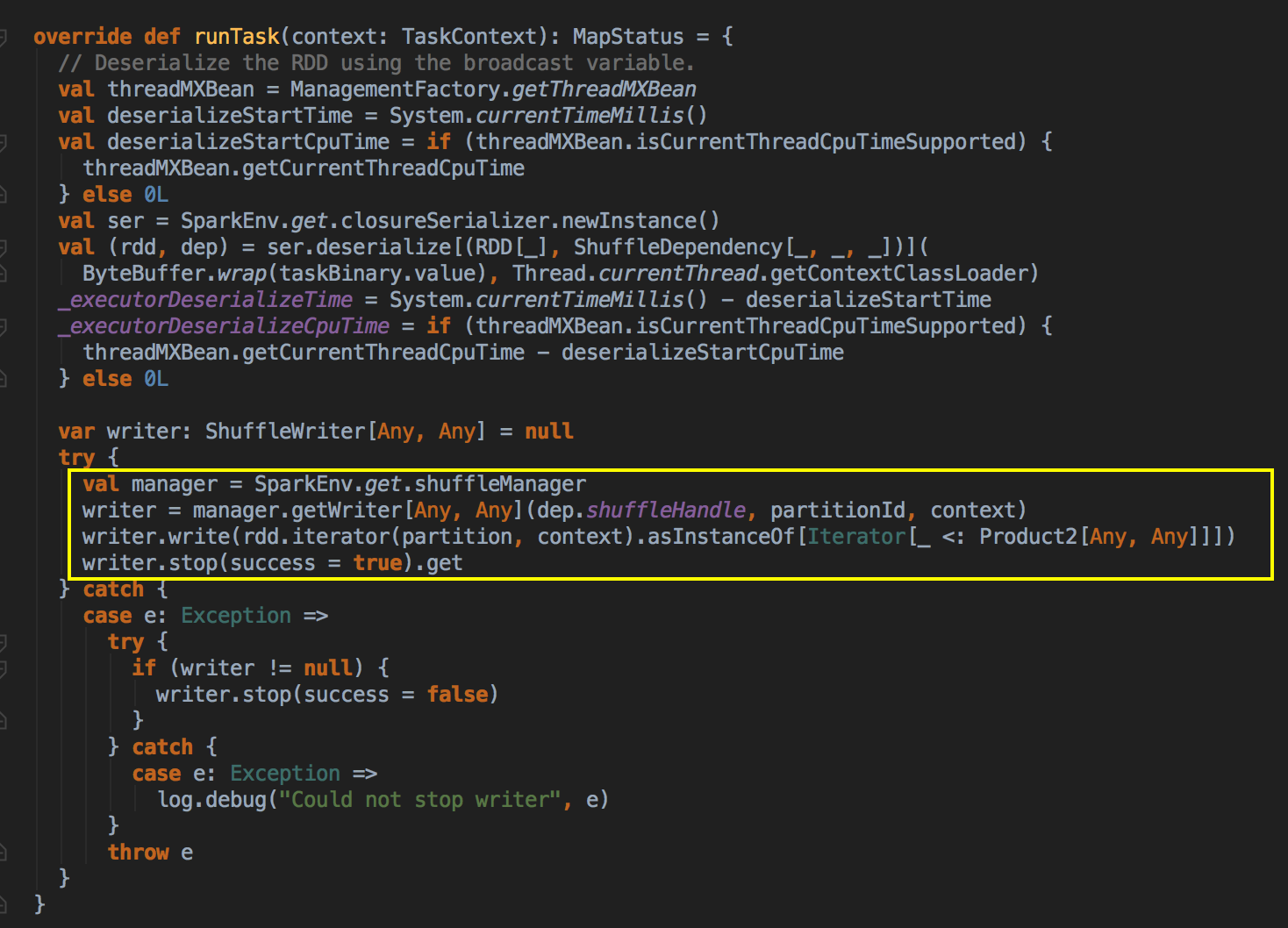
- 首先从 ShuffleMapTask 的 runTask方法中找出当前的 ShuffleManager,然后找出 writer 的方法,然后把 shuffleHandle、partitionId 以及內容作为参数传进来,并调用它的 getWriter 方法。
[下图是一个 ShuffleMapTask.scala 中 writer 方法]![]()
- 找出 ShuffleManager,在Spark2.X版本中只有 SortShuffleManager,已经没有了 Hash-Based Shuffle Manager 了
[下图是一个 SparkEnv.scala 中 shuffleManager 成员]![]()
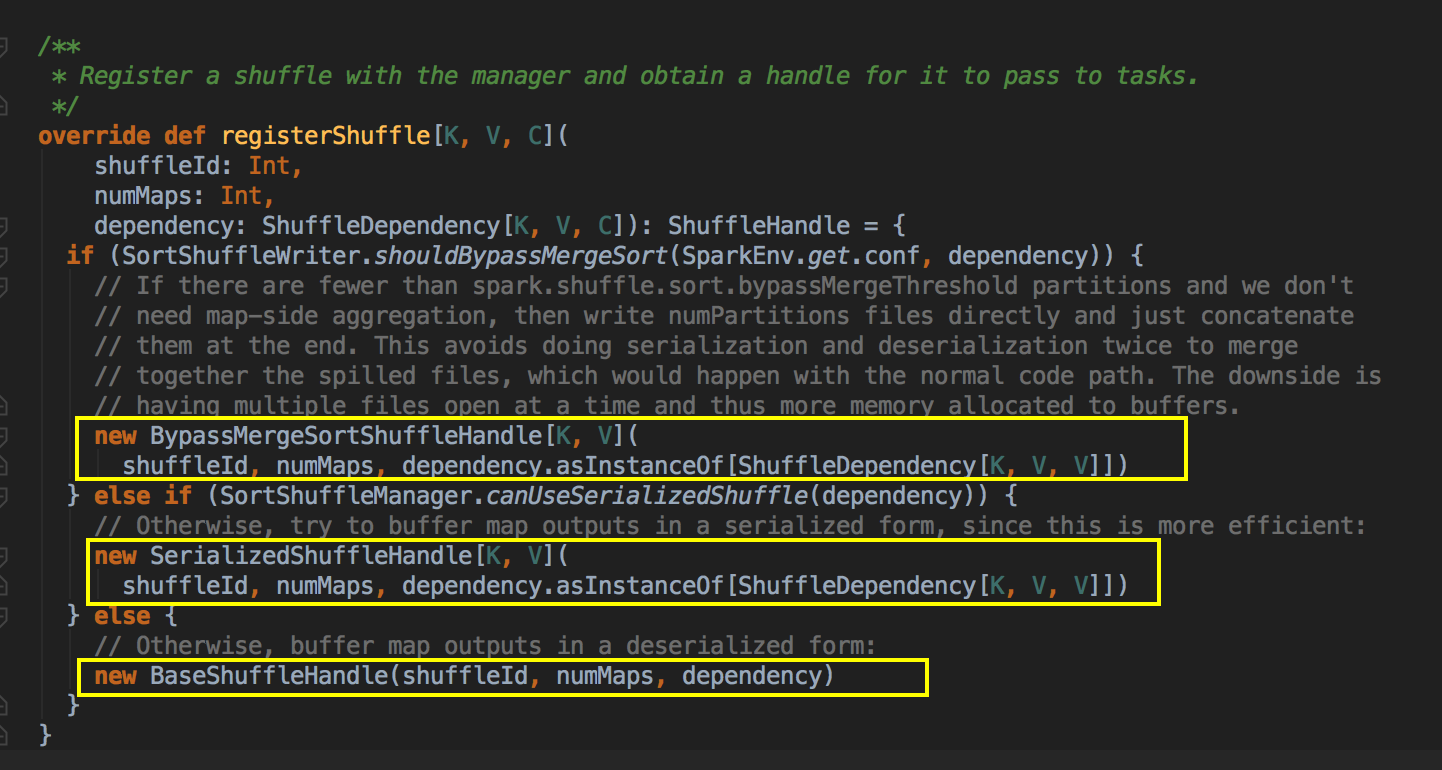
- 定义 ShuffleManager 的 Handler 方式,通过调用 registerShuffle 方法来定义要用那种排序策略。
[下图是一个 Dependency.scala 中 shuffleHandle 成员]![]()
[下图是一个 SortShuffleManager.scala 中 registerShuffle 方法]![]()
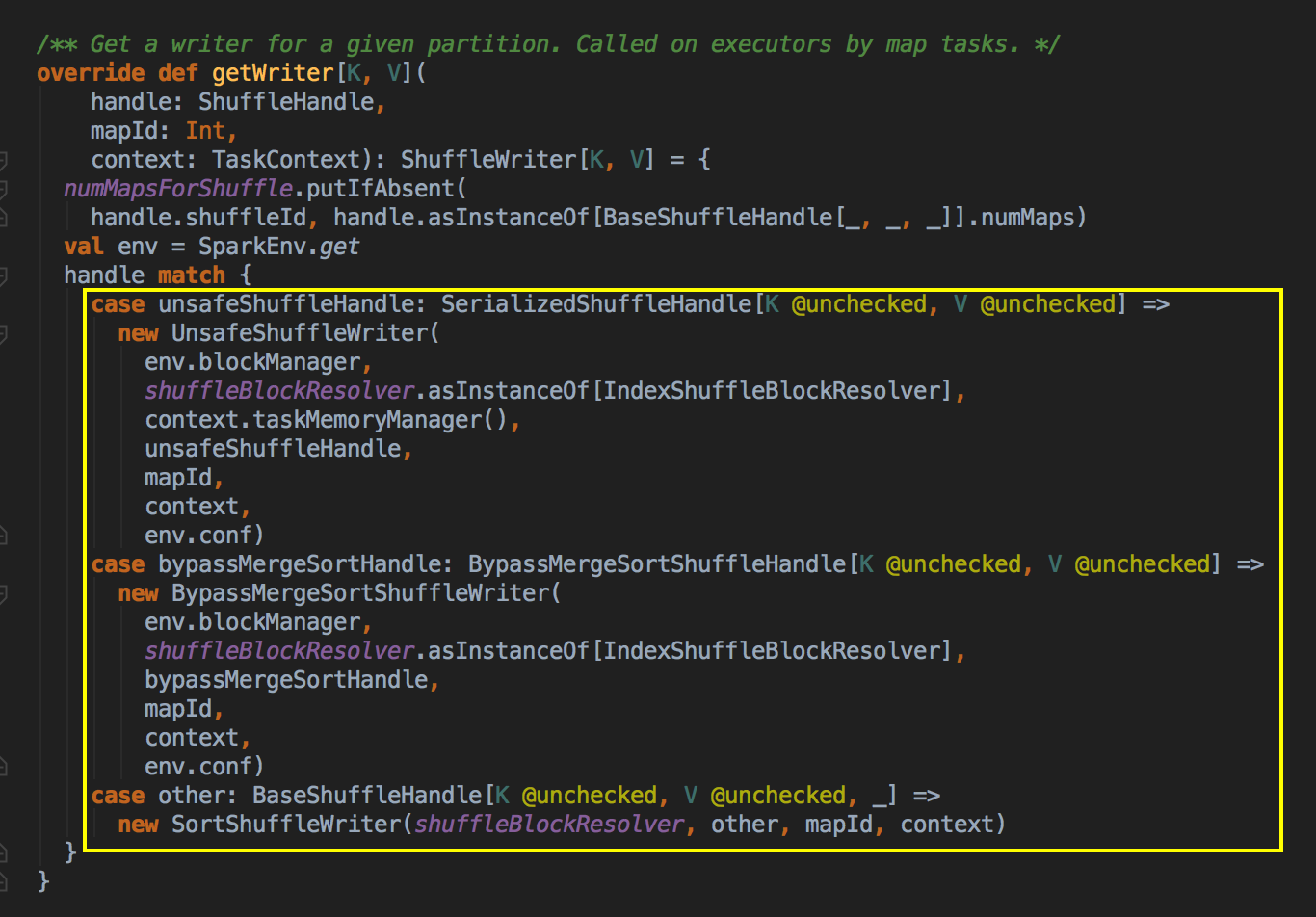
- 在这里看到有三种 ShuffleWriter 的实现方式,第一种是 UnsafeShuffleWriter,第二种是 BypassMergeSortShuffleWriter; 第三种是 SortShuffleWriter。现在我们深入看看 SortShuffleWriter 的具体实现方式。
[下图是一个 SortShuffleManager.scala 中 getWriter 方法]![]()
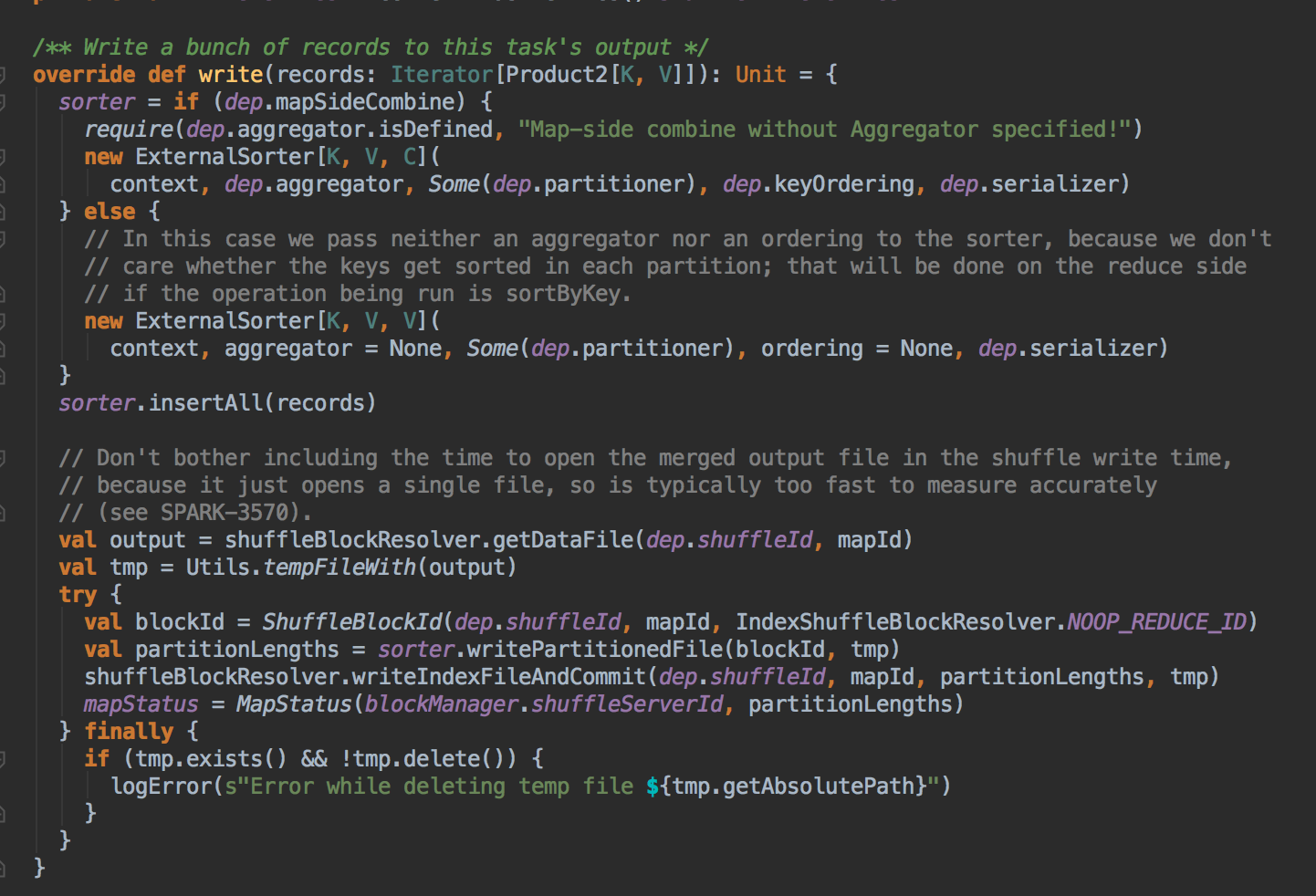
- 然后创建了 SortShuffleWriter 的实例对象,在这里你看见它创建了一个 ExternalSorter 的实例,write 方法会首先判断一下会不会进行 combine 操作,其实就是本地需不需要有 aggregrator 的问题,创建了 sorter 之后,它会先对我们的 sorted 进行 insertAll 的操作,它会根据 ShuffleId 和 StageId 去获得 output,然后它通过 sorter 中的 writePartitionedFie 方法来获得 partitionLengths。最后是一个 mapStatus,它是我们运制程序最后返回的一个数据结构,它会告诉你数据在那里。
[下图是一个 SortShuffleManager.scala 中 write 方法]![]()
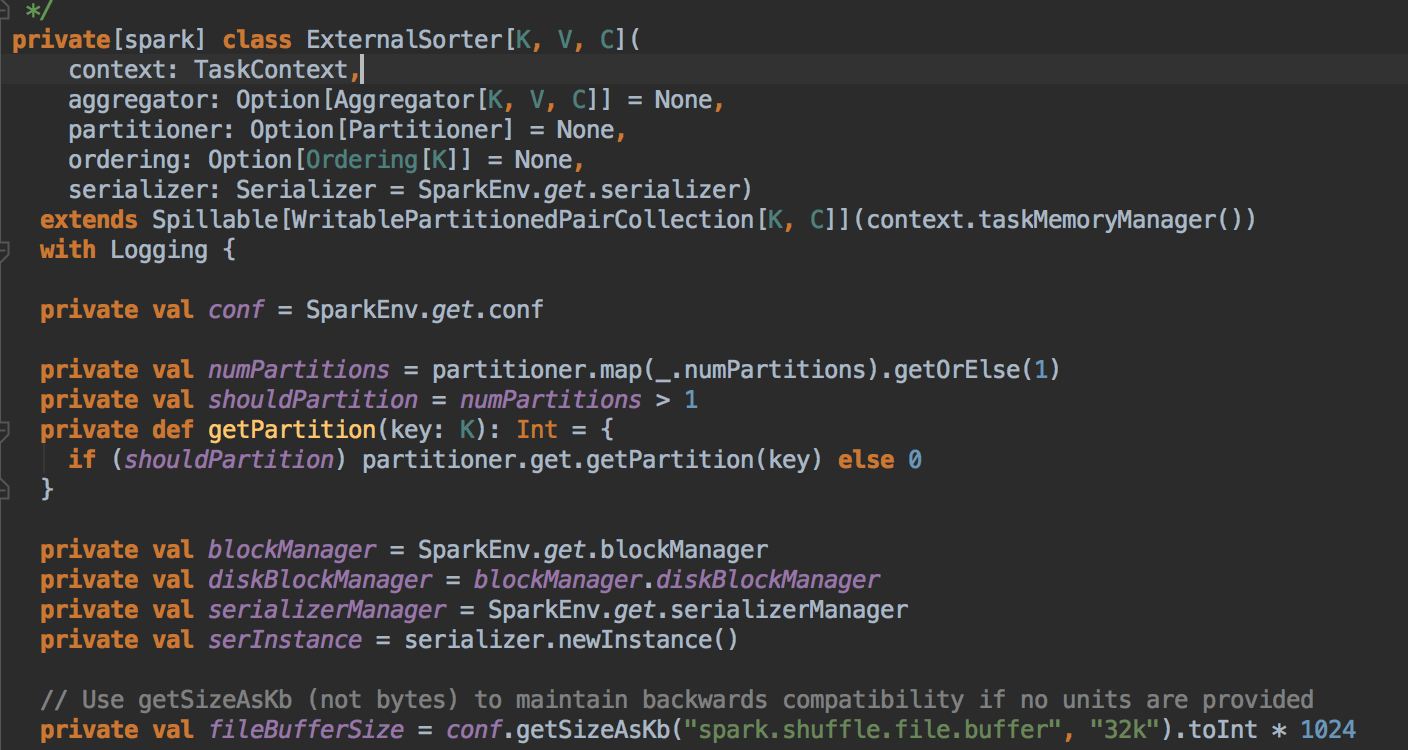
- 这种基于Sort的Shuffle实现机制中引入了外部排序器(ExternalSorter),ExternalSorter继承了 spillable,因为内存攸用在达到一定值时,会spill到磁盘中,这样的设计可以减少内存的开销。在 External Sorter 中会定义 fileBufferSize 的大小,默应是 32k x 1024 的大小。
[下图是一个 ExternalSorter.scala 中 fileBufferSize 大小]![]()
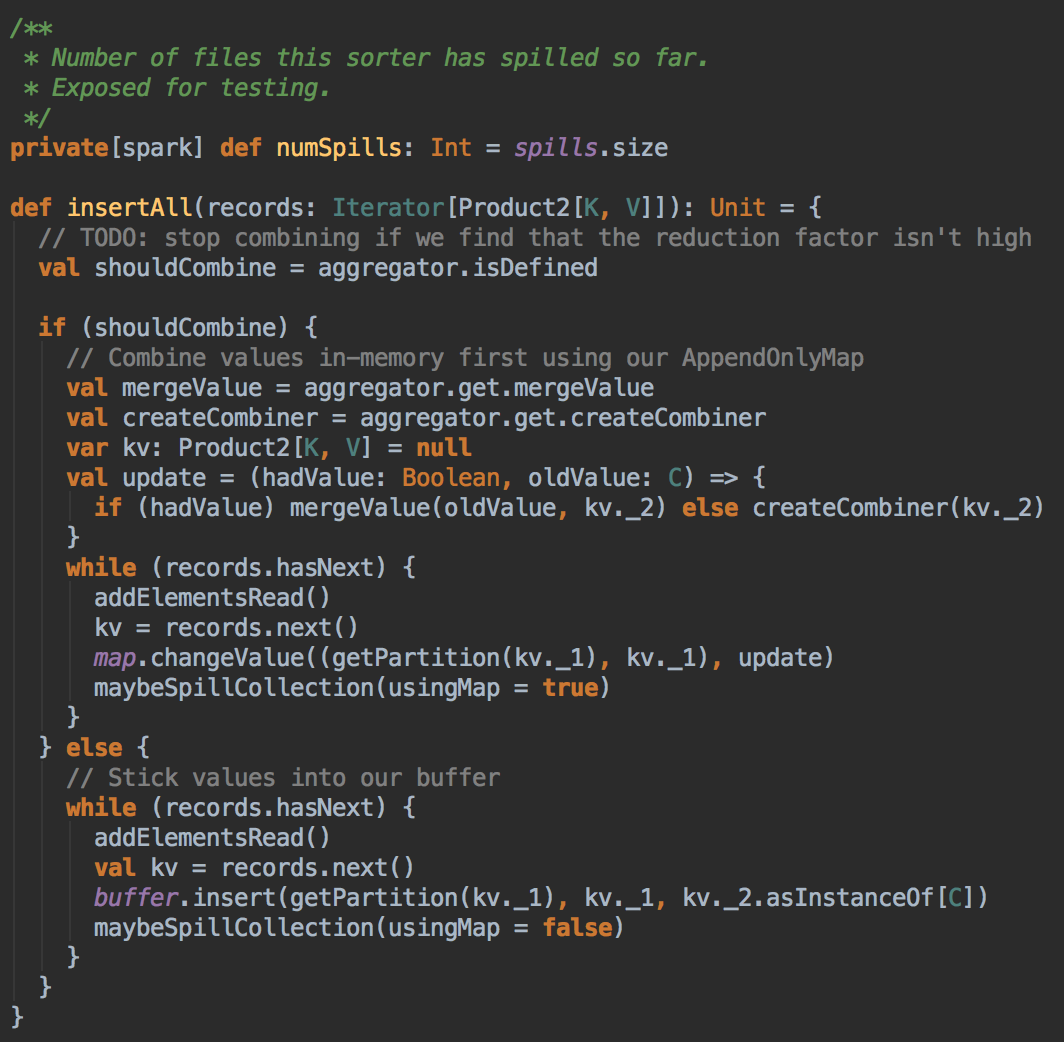
- 通过查看外部排序器(ExternalSorter)的insertAll方法,然后 sorter 调用了 insertAll( ) 的方法。
[下图是一个 ExternalSorter.scala 中 insertAll 方法]![]()
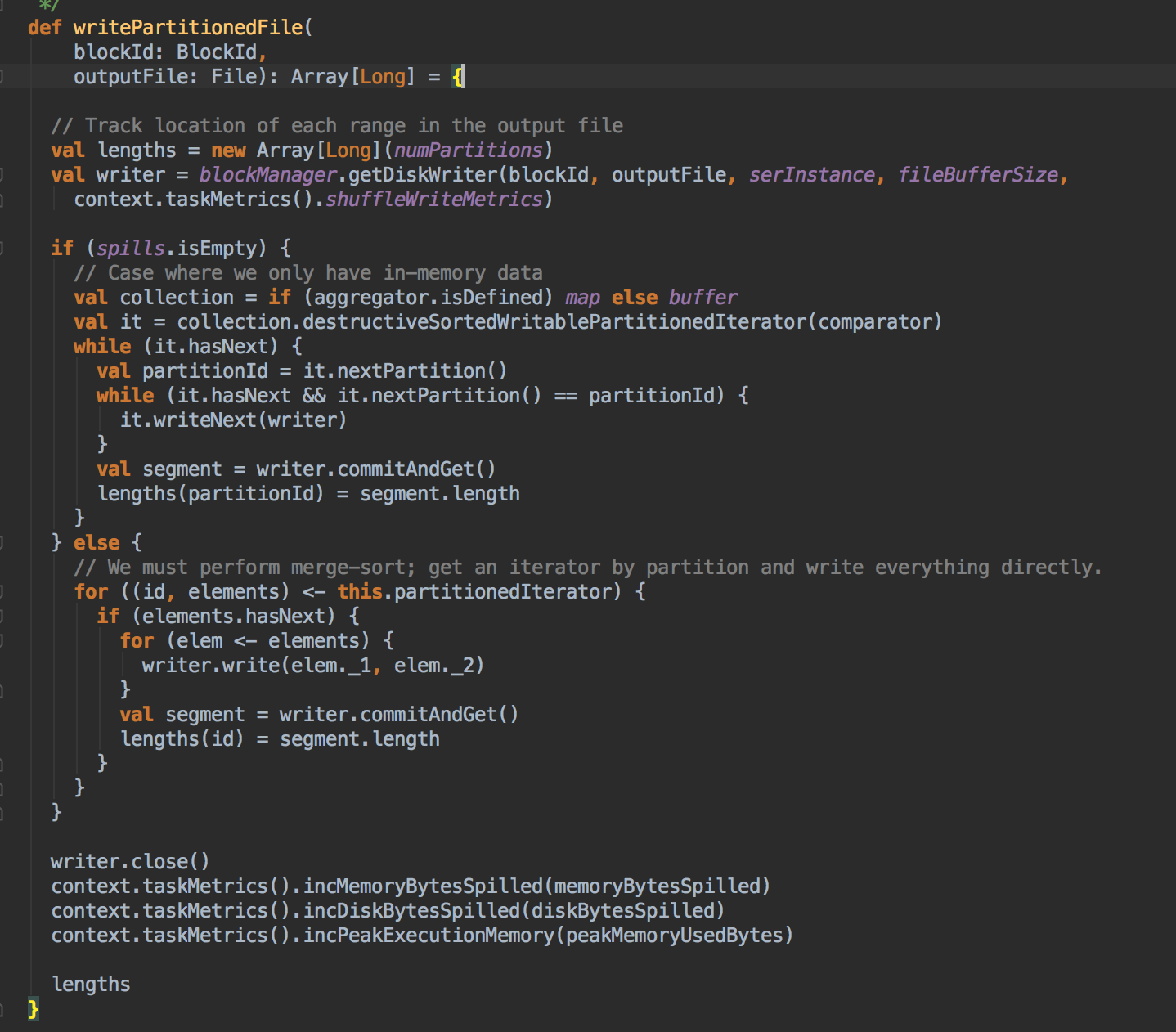
- 对于外部排序器(External Sorter),除了 insertAll 方法外,它的 writePartitionedFile 方法也非常重要,其中BlockId是数据块的逻辑位置,File 参数则是对应逻辑位置的物理存储位置,这两个参数值获取方法和使用 BypassMergeSOrtShuffleHandle及其对应的 ShuffleWriter 是一样的。
![]()
- xxxxx
![]()
- xxx
![]()
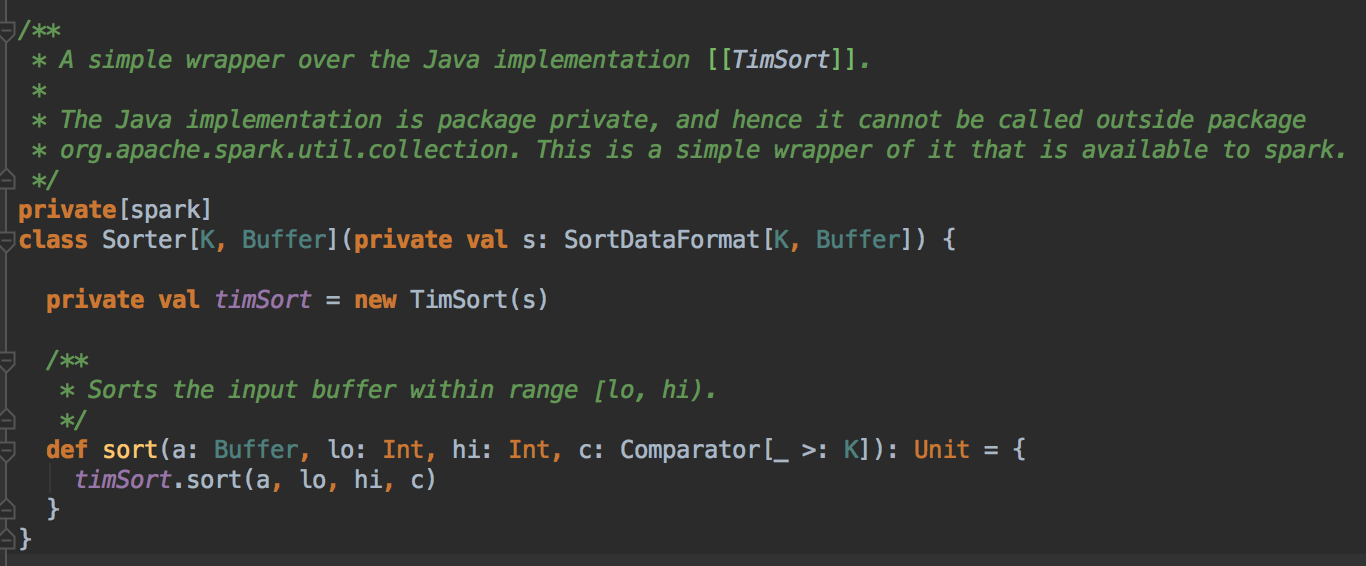
- 创建了一个 Sorter 的实例
![]()
- 代码追迹到这里可以看见它使用了什么排序的方法
![]()

总结
Sorted-Based Shuffle 的诞生和出现意味著 Spark 从只能处理〝中小规模数据的数据处理平台"从新定位为能够处理〝大规模数据的数据处理平台",更进一步巩故它在数据处理领域的龙头地位。它最大的优化就是:减少了因为 HashShuffle 机制不论是原生 HashShuffle、还是 Consolidated Shuffle 在 Mapper 端所产生的海量小文件 (这是应用程序运行时的一个中间过程),中间文件数量从 M x R 个数 变成 2M 的小文件。数据量愈大,这个所优化带来的效果便愈来愈强烈,这是优化的第一步。
虽然 Sort-Based Shuffle 已经大大提升了序程运行时的效率,但如果 Mapper 端并行度的数据分片过多的话,也会导致大量内存消耗和GC的巨大负担,造成系统缓慢甚至崩溃。基于这观点 Spark 再一次突破自己,推出了 Tungsten-Based Shuffle,提升了在Mapper端进行排序的速度,充分利用了的 CPU 等资源。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号