lvs+keepalived 高可用及负载均衡
一、环境准备
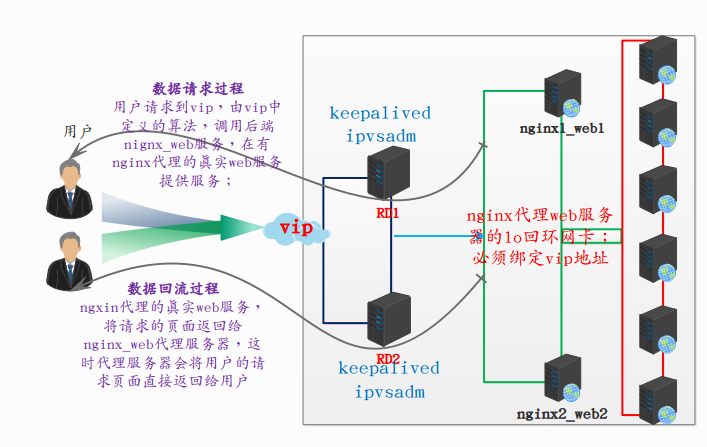
VIP:10.18.43.30
dr1:10.18.43.10
dr2:10.18.43.20
web1:10.18.43.13
web2:10.18.43.14
结构图
(一)、预处理
(1)、关闭所有机器selinux,
vim /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
-------------------------------------------------------------
setenforce 0 #退出保存,执行setenforce 0 当前生效
(2)、关闭所有机器firewalld
systemctl stop firewalld.service
(3)、添加网卡
在DR1与DR2机器添加个添加一张网卡,(也可以不用添加使用本机网卡,主机有两块网卡,其中一块可以用来检测心跳,MASTER和BACKUP如果无法接收到彼此的组播通知,但是两个节点实际上都处于工作状态,这时两个节点均为MASTER强行绑定虚拟IP,从而导致脑裂。)
(二)、部署处理
部署要使用的相关软件;
可以在nginx 上做七层负载均衡,将四层负载均衡的请求在次分发给后端真实提供web服务的集群,根聚七层负载均衡的算法,调用一台真实wen服务器,来给用户提供服务;(这里没有做七层)
(1)、后端部署
nginx编译安装,(在web1和web2执行相同的操作,此处省略web2操作步骤)
groupadd nginx #创建nginx组
useradd -r -g nginx -s /bin/nologin nginx #创建nginx用户并取消shell
wget http://nginx.org/download/nginx-1.14.0.tar.gz #下载nginx软件包
tar xf nginx-1.14.0.tar.gz -C /tpm/ #解压nginx源码包
cd /tmp/nginx-1.14.0/
./configure \
--prefix=/usr/local/nginx \
--without-select_module \
--without-poll_module \
--with-debug \
--with-http_ssl_module \
--with-http_realip_module \
--with-http_addition_module \
--with-http_sub_module \
--with-http_dav_module \
--with-http_flv_module \
--with-http_xslt_module \
--with-http_gzip_static_module \
--with-http_random_index_module \
--with-http_secure_link_module \
--with-http_degradation_module \
--with-http_stub_status_module \
--with-cc=`which gcc`
make -j 2 && make install
(2)、启动nginx服务
cd /usr/local/nginx/
sbin/nginx
[root@web1-1 nginx]# lsof -i:80
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nginx 1134 root 6u IPv4 27680 0t0 TCP *:http (LISTEN)
nginx 1135 nginx 6u IPv4 27680 0t0 TCP *:http (LISTEN)
(3)、设置lo回环地址
(在web1和web2,执行相同的操作)
[root@web1-1 ~]# echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
[root@web1-1 ~]# echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
[root@web1-1 ~]# ip a a dev lo 10.18.43.30/32
[root@web1-1 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet 10.18.43.30/32 scope global lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 52:54:00:ed:d6:71 brd ff:ff:ff:ff:ff:ff
inet 10.18.43.13/24 brd 10.18.43.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:feed:d671/64 scope link
valid_lft forever preferred_lft forever
测试后端web服务是否正常,(web1,web2执行相同操作)
[root@web1-1 ~]# curl 10.18.43.13
web1
(4)、高可用
下载ipvsadm,keepalived,
yum -y install ipvsadm keepalived
(5)、keepalived部署详解
[root@DR-1-1 ]# vim /etc/keepalived/keepalived.conf
global_defs {
router_id lvs #全局配置
}
vrrp_instance lvs_keepalived { #库名称
state BACKUP #角色:MASTER BACKUP
interface eth0 #网卡:这里我们拿eth0做为心跳测试,检测另一台BACKUP存活状态
virtual_router_id 51 #小组段:默认是51
priority 100 # 服务的优先权最高255
nopreempt # BACKUP 不抢IP
advert_int 1
authentication {
auth_type PASS
auth_pass 1111 #小组密码
}
virtual_ipaddress {
10.18.43.30/32 dev eth1 # 虚拟ip
}
}
virtual_server 10.18.43.30 80 {
delay_loop 6 #延时环 6秒
lb_algo rr #轮询规则rr
lb_kind DR #使用的工作模式
persistence_timeout 50 #连接超时 时间
protocol TCP #使用的协议
real_server 10.18.43.13 80 {
weight 1 #权重
TCP_CHECK {
connect_port 80 #监听端口
connect_timeout 3 #连接超时3秒
nb_get_retry 3 #重试连接3次
delay_before_retry 3 #连接超时3重试连接3次
}
}
real_server 10.18.43.14 80 {
weight 1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
将这份配置发给dr2,只需要修改优先级;
[root@DR-2-2 ]# vim /etc/keepalived/keepalived.conf
global_defs {
router_id lvs #全局配置,全局必须一致
}
vrrp_instance lvs_keepalived { #库名称
state BACKUP #角色:MASTER BACKUP
interface eth0 #网卡:这里我们拿eth0做为心跳测试,检测另一台BACKUP存活状态
virtual_router_id 51 #小组段:默认是51
priority 150 #注意这里的优先级
nopreempt # BACKUP 不抢IP
advert_int 1
authentication {
auth_type PASS
auth_pass 1111 #小组密码
}
virtual_ipaddress {
10.18.43.30/32 dev eth1 # 虚拟ip
}
}
virtual_server 10.18.43.30 80 {
delay_loop 6 #延时环 6秒
lb_algo rr #轮询规则rr
lb_kind DR #使用的工作模式
persistence_timeout 50 #连接超时 时间
protocol TCP #使用的协议
real_server 10.18.43.13 80 {
weight 1 #权重
TCP_CHECK {
connect_port 80 #监听端口
connect_timeout 3 #连接超时3秒
nb_get_retry 3 #重试连接3次
delay_before_retry 3 #连接超时3重试连接3次
}
}
real_server 10.18.43.14 80 {
weight 1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
(6)、启动keepalived
(在DR1和DR2执行相同操作)
[root@DR-1-1 ~]# systemctl start keepalived.service
[root@DR-2-2 ~]# systemctl start keepalived.service
(7)、查看结果
DR1与RD2先启动那个机器,虚拟VIP就会在那个主机的第二张网卡上,(第一张网卡是用来做心跳测试的,)
[root@DR-1-1 keepalived]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:c9:8e:89 brd ff:ff:ff:ff:ff:ff
inet 10.18.43.10/24 brd 10.18.43.255 scope global dynamic eth0
valid_lft 41215sec preferred_lft 41215sec
inet6 fe80::70de:1853:c4c6:aa/64 scope link
valid_lft forever preferred_lft forever
4: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:51:4b:4f brd ff:ff:ff:ff:ff:ff
inet 10.18.43.12/24 brd 10.18.43.255 scope global dynamic eth1
valid_lft 43069sec preferred_lft 43069sec
inet 10.18.43.30/32 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::e958:18e:3504:b3f/64 scope link
valid_lft forever preferred_lft forever
二、概念补充
(1)、脑裂
一般来说,脑裂的发生,有一下几种原因;
1、高可用服务器对之间心跳线链路发生故障,导致无法正常通信;
2、因心跳线坏了,(包括断了,老化等一些物理上的原因)
3、因网卡及相关驱动坏了,IP配置及冲突问题(网卡直连)
4、因心跳线间链接的设备故障(网卡及交换机)
5、因仲裁的机器出问题(采用仲裁的方案)
6、高可用服务器上开启了iptables防火强阻挡了心跳消息传输
7、高可用服务器上心跳网卡地址等信息配置不正确,导致心跳失败;
8、其他服务配置不当等原因,如心跳方式不同,心跳广播冲突,软件Bug等。
提示:keepalived配置里同一VRRP实例如果virtual_router_id两端参数配置不一致也后悔导致脑裂问题发生;
(2)、常见解决方案
在实际生产环境中,我们可以从以下几个方面来防止脑裂问题的发生;
1、同时使用串行电缆和以太网电缆链接,同时使用两跳心跳线路,这样一条线路坏了,另一条还是好的,依然能传送心跳消息
2、当检测到脑裂时,强行关闭一个心跳节点,
3、做好对脑裂的监控报警,在问题发生时人为第一时间介入仲裁,降低损失。
(3)、keepalived配置
在这里主要解释一下我的配置没有写入MASTER,在有nopreempt参数的情况下,是可以不要MASTER,为了确保vip在一台机器上的稳定性,我们需要在配置文件中添加nopreempt参数,而且取消MASTER角色;
如果MASTER角色存在,那么MASTER角色宕机之后,他的vip会漂移到BACKUP角色主机上,这时如果是以为网络抖动的原因造成的,当MASTER服务链接正常时,MASTER角色就会将原有的vip抢回来,反复来回几次之后,keepalived就会宕机,造成不可设想的后果;
如果取消MASTER角色,添加nopreempt参数,vip会按照服务启动的先回顺序和优先级来决定他在那台机器上,有一台keepalived宕机,vip就会漂移到另一台BACKUP机器上,当另一台keepalived正常只会,他不会去抢vip,这样就不会造成vip来回在keepalived机器上飘来飘去;

您的资助是我最大的动力!
金额随意,欢迎来赏!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号