Linux内核【链表】整理笔记(2) 【转】
转自:http://blog.chinaunix.net/uid-23069658-id-4725279.html
关于链表我们更多时候是对其进行遍历的需求,上一篇博文里我们主要认识了一下和链表操作比较常用的几个内核API接口,其入参全都是清一色的struct list_head{}类型。至于链表的遍历,内核也有一组基本的接口(其实都是宏定义的)供开发者调用。
首先是list_for_each(pos, head),参数pos是需要开发者在外部提供的一个临时struct list_head{}类型的指针对象,类似于for循环的i、j、k之类的游标,head是我们要遍历的链表头。常见用法:
点击(此处)折叠或打开
- LIST_HEAD(student_list);
- struct list_head *stu;
- list_for_each(stu, &student_list){
- //在这个作用域里,指针stu依次指向student_list里的每一个struct list_head{}成员节点
- }
当然stu指向的是struct list_head{}类型的对象,我们一般是需要指向struct student{}的才对,此时list_entry(ptr, type, member)就出场了,它完全是container_of(ptr, type, member)的一个别名而已。container_of()就是根据type类型结构体中的member成员的指针ptr,反身找到该member所在结构体对象的type首地址。废话不多说,上图:
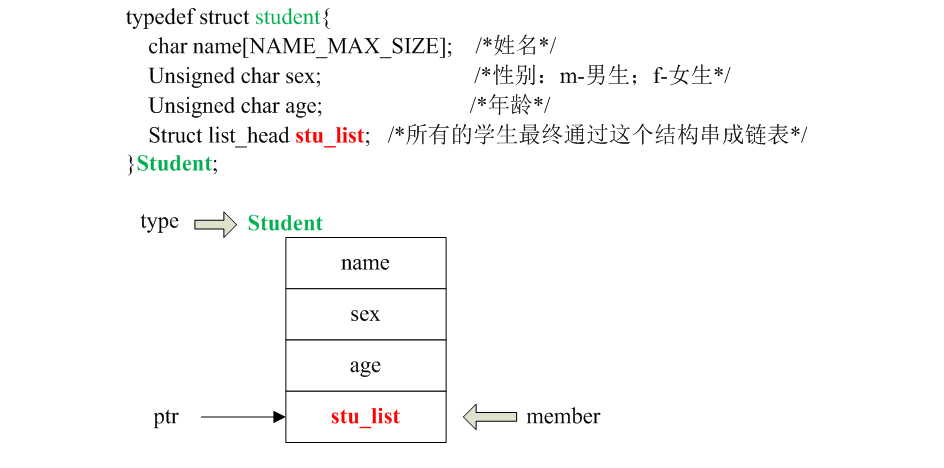
此时的用法就变成下面这样子:

注意结合上图,领会一下list_entry(ptr,type,member)三个参数之间的关系。这样如果每次要遍历链表时既要定义临时的struct list_head{}指针变量,又要定义目标结构体对象指针变量,总感觉些许不爽。好在Linux感知到了你的J点,于是乎:
点击(此处)折叠或打开
- list_for_each_entry(pos, head, member)
横空出世。参数pos和member意义没有变,而head则指向我们要遍历的链表首地址,这样一来开发者不用再自己定义struct list_head{}类型临时指针变量,只要需要自己定义一个的目标数据结构的临时指针变量就可以了:
点击(此处)折叠或打开
- LIST_HEAD(student_list);
- struct student *st;
- list_for_each_entry(st, &student_list, stu_list){
- //Todo here … …
- }
此时指针变量st,就相当于for循环的游标变量i了。
当然,内核能感知的远不止于此,还有一个名为list_for_each_entry_reverse(pos, head, member)的宏,用于对双向链表的逆向遍历,参数的意义和list_for_each_entry()完全一样,区别在它是对链表从尾部到首部进行依次遍历。该接口主要是为了提高链表的访问速度,考虑两种情况:
第一,如果你明确知道你要访问的节点会出现在链表靠后的位置;
第二,如果你需要用双向链表实现一个类似于“栈”的数据结构;
针对以上两种需求,相比于list_for_each_entry(),list_for_each_entry_reverse()的速度和效率明显优于前者。为了追求极致,内核开发者们就是这么任性,没办法。
上述两个接口在遍历链表时已经完全可以胜任,但还无法满足删除的需求,原因是…算了,都懒的说了,把那两个宏展开,在纸上画一下,如果要删除节点,会发生什么“神奇”的事情就一目了然了。那如果遍历链表过程中要删除节点,该怎么办?咱接着唠:
点击(此处)折叠或打开
- list_for_each_entry_safe(pos, n, head, member)
如果你还没看过list.h文件,那么单从list_for_each_entry_safe(pos,n,head,member)的四个入参命名上,应该可以读懂它们的意思和用法了吧!如果你已经在纸上画过了,那么新增的n很明显应该是pos指针所指元素的下一个节点的地址,注意,pos和n都是目标结构体的类型,而非struct list_head{}类型,本例中它们都是struct student{}类型的指针,童鞋们可不要犯迷糊了。现在用法就更简单了:
点击(此处)折叠或打开
- LIST_HEAD(student_list);
- struct student *st,*next;
- list_for_each_entry_safe (st, next,&student_list, stu_list){
- //在这里可以对st所指向的节点做包括删除在内的任意操作
- //但千万别操作next,它是由list_for_each_entry_safe()进行维护的
- }
不用多想,肯定也存在一个名为list_for_each_entry_safe_reverse(pos, n, head, member)的宏。简单小节一下:
1)、list_for_each_entry()和list_for_each_entry_reverse(),如果只需要对链表进行遍历,这两个接口效率要高一些;
2)、list_for_each_entry_safe()和list_for_each_entry_safe_reverse(),如果遍历过程中有可能要对链表进行删除操作,用这两个;
实际项目中,大家可以根据具体场景而考虑使用哪种方式。另外,关于链表遍历,内核还有其他一些列list_for_*相关的宏可供调用,这里就不一一阐述了,list.h源码里面无论是注释还是实现都相当明确。

说了老半天,还是操练几把感受感受,模拟训练之“内核级精简版学生管理系统”:
头文件student.h长相如下:
点击(此处)折叠或打开
- /*student.h*/
- #ifndef __STUDENT_H_
- #define __STUDENT_H_
- #include <linux/list.h>
- #define MAX_STRING_LEN 32
- typedef struct student
- {
- char m_name[MAX_STRING_LEN];
- char m_sex;
- int m_age;
- struct list_head m_list; /*把我们的学生对象组织成双向链表,就靠该节点了*/
- }Student;
- #endif
源文件student.c长相也不丑陋:
点击(此处)折叠或打开
- #include <linux/module.h>
- #include <linux/kernel.h>
- #include <linux/init.h>
- #include "student.h"
- MODULE_LICENSE("Dual BSD/GPL");
- MODULE_AUTHOR("Koorey Wung");
- static int dbg_flg = 0;
- LIST_HEAD(g_student_list);
- static int add_stu(char* name,char sex,int age)
- {
- Student *stu,*cur_stu;
- list_for_each_entry(cur_stu,&g_student_list,m_list){ //仅遍历是否有同名学生,所以用该接口
- if(0 == strcmp(cur_stu->m_name,name))
- {
- printk("Error:the name confict!\n");
- return -1;
- }
- }
- stu = kmalloc(sizeof(Student), GFP_KERNEL);
- if(!stu)
- {
- printk("kmalloc mem error!\n");
- return -1;
- }
- memset(stu,0,sizeof(Student));
- strncpy(stu->m_name,name,strlen(name));
- stu->m_sex = sex;
- stu->m_age = age;
- INIT_LIST_HEAD(&stu->m_list);
- if(dbg_flg)
- printk("(Add)name:[%s],\tsex:[%c],\tage:[%d]\n",stu->m_name,stu->m_sex,stu->m_age);
- list_add_tail(&stu->m_list,&g_student_list); //将新学生插入到链表尾部,很简单吧
- return 0;
- }
- EXPORT_SYMBOL(add_stu); //导出该函数,后面我们要在其他模块里调用,为了便于测试,下面其他借个接口类似
- static int del_stu(char *name)
- {
- Student *cur,*next;
- int ret = -1;
- list_for_each_entry_safe(cur,next,&g_student_list,m_list){ //因为要删除链表的节点,所以必须有带有“safe”的宏接口
- if(0 == strcmp(name,cur->m_name))
- {
- list_del(&cur->m_list);
- printk("(Del)name:[%s],\tsex:[%c],\tage:[%d]\n",cur->m_name,\
- cur->m_sex,cur->m_age);
- kfree(cur);
- cur = NULL;
- ret = 0;
- break;
- }
- }
- return ret;
- }
- EXPORT_SYMBOL(del_stu);
- static void dump_students(void)
- {
- Student *stu;
- int i = 1;
- printk("===================Student List================\n");
- list_for_each_entry(stu,&g_student_list,m_list){ //同样,也仅遍历链表而已
- printk("(%d)name:[%s],\tsex:[%c],\tage:[%d]\n",i++,stu->m_name,\
- stu->m_sex,stu->m_age);
- }
- printk("===============================================\n");
- }
- EXPORT_SYMBOL(dump_students);
- static void init_system(void)
- {
- /*初始化时,向链表g_student_list里添加6个节点*/
- add_stu("Tom",'m',18);
- add_stu("Jerry",'f',17);
- add_stu("Alex",'m',18);
- add_stu("Conory",'f',18);
- add_stu("Frank",'m',17);
- add_stu("Marry",'f',17);
- }
- /*因为没有数据库,所以当我们的模块退出时,需要释放内存*/
- static void clean_up(void)
- {
- Student *stu,*next;
- list_for_each_entry_safe(stu,next,&g_student_list,m_list){
- list_del(&stu->m_list);
- printk("Destroy [%s]\n",stu->m_name);
- kfree(stu);
- }
- }
- /*模块初始化接口*/
- static int student_mgt_init(void)
- {
- printk("Student Managment System,Initializing...\n");
- init_system();
- dbg_flg = 1; //从此以后,再调用add_stu()时,都会有有内核打印信息,详见实例训练
- dump_students();
- return 0;
- }
- static void student_mgt_exit(void)
- {
- clean_up();
- printk("System Terminated!\n");
- }
- module_init(student_mgt_init);
- module_exit(student_mgt_exit);
Makefile:
点击(此处)折叠或打开
- obj-m += student.o tools.o
- CURRENT_PATH:=$(shell pwd)
- LINUX_KERNEL:=$(shell uname -r)
- LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
- all:
- make -I. -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
- clean:
- make -I. -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) clean
其中tools.c是一个辅助模块,用于实现从用户空间直接调用调用内核空间EXPORT_SYMBOL出来的任意一个API接口,比如add_stu()、del_stu()或者dump_students()等等。OK,万事俱备,只欠东风,一条make命令下去,然后好戏正式开始:

总的来说,Linux内核链表的使用还算比较简单基础,是内核学习的入门必修课。当然实际项目中,对链表进行插入或者删除时如果有同步或者互斥需求,则需要采用诸如互斥锁之类的内核保护手段,防止对链表操作时出现竞争冒险现象。

