Linux文件事件监控之Fanotify [一]【转】
转自:https://zhuanlan.zhihu.com/p/186027813
从监听到监控
Linux的文件事件监听的原理并不复杂,简单说就是当一个应用层的进程操作一个目录或文件时,会触发system call,此时内核的notification子系统可以守在那里,把该进程对文件的操作上报给应用层的监听进程(称为listerner)。
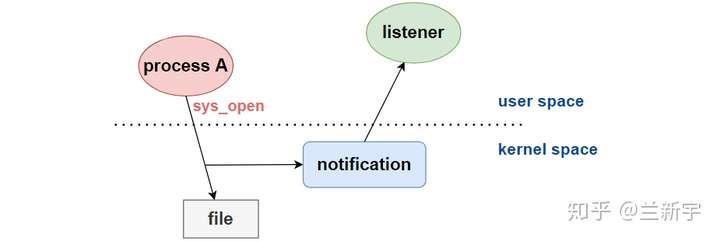
在这个领域,自2001年的2.4版本就引入的dnotify可以说是先驱,然而,它的缺陷实在太多了。正如其名字传达的,只能监控directory,并且它采用的是signal机制来向listener发送通知,因而可以携带的信息很有限。
所以,dnotify基本已经成了「先烈」,一个更优秀的名为"inotify"的监听机制于2005年在2.6.13内核中亮相,它除了可以监控目录,还可以监听普通文件产生的事件。此外,inotify摈弃了signal机制,改为通过event queue的形式向listener上传事件的相关信息。
看起来,inotify已经算是比较完备了,但是它在应用上还是存在诸多限制。其中一个最明显的问题是它只能"notify",作为listener,只是知道有这个文件事件发生了,最多记录一下,但并不能改变什么(比如被杀毒软件判定为病毒文件,就需要阻止这个操作)。
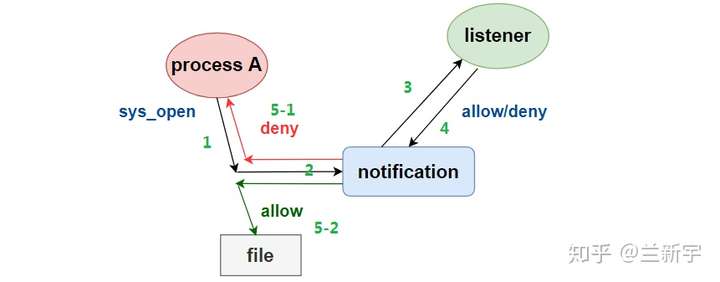
到了2.6.36内核,fanotify的出现解决了这个痛点,允许listener介入并改变文件事件的行为,才算实现了从“监听”到“监控”的跨越,同时也扩展了其应用的范围。
两个API
fanotify的调用接口是比较简洁的,主要有2个API,但其可携带的参数还是为它的使用增加了很多的灵活性。作为listerner,首先需要通过fanotify_init()函数来设定监控的模式:
#include <fcntl.h>
#include <sys/fanotify.h>
int fanotify_init(unsigned int flags, unsigned int event_f_flags);
如果"flags"为"FAN_CLASS_CONTENT",意思是当一个文件的content准备好后,listerner就要介入了,然后给出阻止/放行的决定。为"FAN_CLASS_NOTIF"就是listerner只需要被notify就可以了,类似于「已阅」,但不给出任何的修改意见。
虽然fanotify在内核中并不是作为一个module存在的,也没有对应的设备文件,但从抽象的角度,你完全可以把它视作一个特殊的文件,而"fanotify_init"就是去"open"这个文件,因此这里的"event_f_flags" 其实和VFS中open()系统调用的"flags" 参数差不多(比如" O_RDONLY"),这也是为什么需要包含"fcntl.h"头文件的原因。
同open()一样,该函数返回的也是代表fanotify这个特殊文件的file descriptor,获得了fd后,就可以利用fanotify_mark()来展开具体的配置了:
int fanotify_mark(int fanotify_fd, unsigned int flags,
uint64_t mask, int dirfd, const char *pathname);
文件事件的监控大致包括两个维度:对哪些文件产生的事件感兴趣,以及对这些文件的哪些事件感兴趣。"flags" 就是用来增加/删除感兴趣的文件列表(通过"FAN_MARK_ADD"/"FAN_MARK_REMOVE"等),而"mask" 就是用来设置感兴趣的事件列表,比如"FAN_OPEN"就是当文件被打开时,产生一个事件给listener。
至于"dirfd" 和"pathname",则是用来给出文件路径的,比如"AT_FDCWD"就表示从当前路径(Current Working Directory)开始解析。
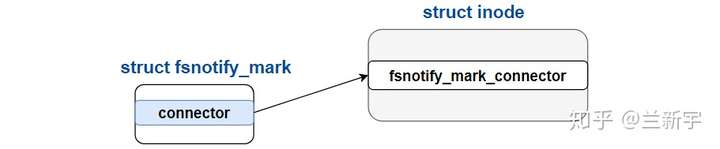
一个mark针对一个文件,那它是怎么和内核中表示文件的数据结构关联起来的呢?文件的唯一标识是inode,mark通过一个"fsnotify_mark_connector"类型的指针,指向了inode结构体中对应的元素(至于这里为什么是叫"fsnotify"而不是"fanotify",将在本文后半部分给出答案):
熟悉epoll的同学可能已经发现,fanotify_init()其实和epoll_create()挺像的,都是用来监听文件,而本身的instance也作为一个文件,有对应的file descriptor供应用程序操作。fanotify_mark()则可类比于epoll_ctl(),都是用来增删和修改事件列表的。
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
不过,fanotify并没有epoll_wait()这样的轮询机制,不能直接让listerner收到事件,所以在具体的使用上,fanotify和poll/epoll是层级的关系:
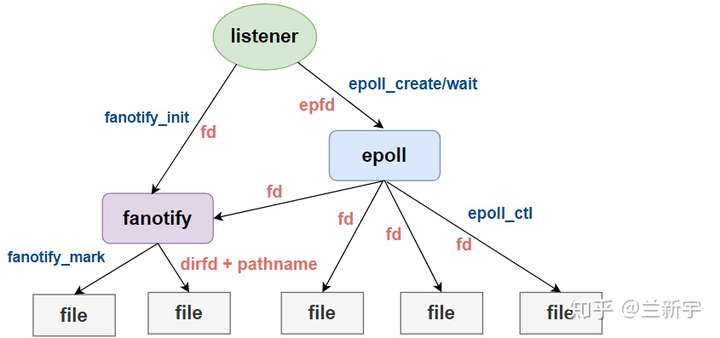
那为什么不直接只用epoll呢?这还得从fanotify的原理说起。先来看下对于一个被监控文件进行open操作时,fanotify是怎么发挥作用的:
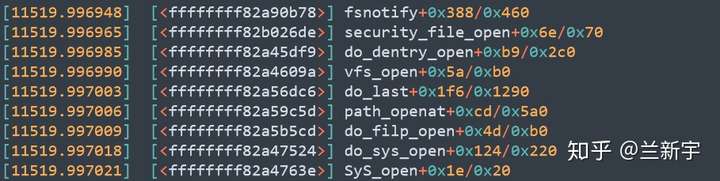
在do_dentry_open()之前,都是VFS的标准调用路径,而到了security_file_open()这里,已经准备好hook,在此潜伏已久的各路人马就开始出手了:
int security_file_open(struct file *file)
{
int ret = call_int_hook(file_open, 0, file);
if (ret)
return ret;
return fsnotify_perm(file, MAY_OPEN);
}
这些人马主要来自LSM(Linux Security Module),比如著名的SELinux(参考这篇文章):
call_int_hook -->
hlist_for_each_entry(P, &security_hook_heads.FUNC, list) {
RC = P->hook.FUNC(__VA_ARGS__);
if (RC != 0)
break;
}
统一入口
走到fsnotify_perm()这里,终于轮到前面已经露过一回脸的fsnotify了。从dnotify到inoitfy,再到fanotify,缺陷和限制逐渐减少,但这不是一个迭代的关系,它们仨的代码目前都存在于"/fs/notify"目录。
同时,由于机制的相似性,它们存在很多共通之处,将这些共通之处提取出来,就成了fsnotify。fsnotify作为后端,负责接收文件事件,它被作为前端、和listener直接交互的dnotify, inotify和fanotify所共享。
每一个前端instance被抽象为一个"group"(在代码中由"fsnotify_group"结构体表示),每个group都有自己的notification queue(以下简称"nq"),用于向listener传递事件。
从效率的角度,fsnotify不会把收到的事件依次放到每个group的"nq"上,而是只维护一个event queue,根据各个group配置的mask,在其对应的"nq"里存放指针,指向event queue中感兴趣的事件。
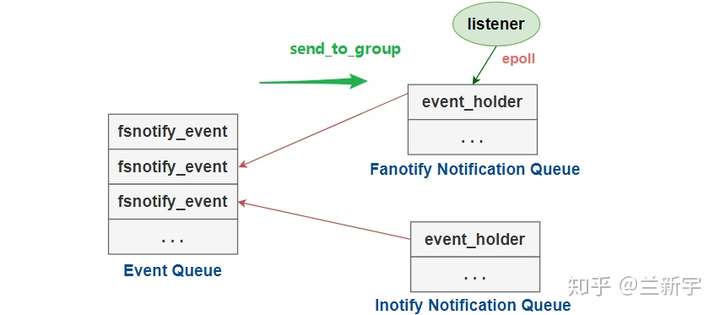
那fsnotify具体是如何将事件送到fanotify这个group,fanotify又是怎样和应用层的listener打交道的呢,请看下文分解。
参考:
原创文章,转载请注明出处。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类
2020-08-05 ARM Coresight -- 与内核并列的调试系统架构【转】
2016-08-05 Linux内核调试方法总结【转】
2015-08-05 linux 高级字符设备驱动 ioctl操作介绍 例程分析实现【转】
2015-08-05 Linux驱动总结3- unlocked_ioctl和堵塞(waitqueue)读写函数的实现 【转】
2015-08-05 初识CPU卡、SAM卡/CPU卡简介、SAM卡简介 【转】
2015-08-05 android中跨进程通讯的4种方式
2015-08-05 MISC混杂设备 struct miscdevice /misc_register()/misc_deregister()【转】