Linux内存管理:slub分配器【转】
转自:https://zhuanlan.zhihu.com/p/166649492
概述:
我们知道内核中的物理内存由伙伴系统(buddy system)进行管理,它的分配粒度是以物理页帧(page)为单位的,但内核中有大量的数据结构只需要若干bytes的空间,倘若仍按页来分配,势必会造成大量的内存被浪费掉。slab分配器的出现就是为了解决内核中这些小块内存分配与管理的难题。这个概念首先在sun公司的SunOS5.4操作系统中得以实现。slab分配器是基于buddy页分配器,在它上面实现了一层面向对象的缓存管理机制(是不是感觉有点像malloc函数在glibc中实现的内存池)。
关于本文,slab分配器的主要内容大致可分为三部分,第一部分包括基本概念,第二部分是slab的使用与原理,第三部分如何调试slab。
slub机制:
虽然内核是用面对过程的C语言实现的,但是内核的在许多功能的设计上也运用了面对对象的思想,slab分配器就是其中之一,它把常用的数据结构都看成一个个对象。我们知道buddy分配器的分配单元是以页为单位的,然后将不同order的空闲物理页帧串成若干链表,分配时从对应链表里取出。而slab分配器则是以目标数据结构为单分配单元,且会将目标数据结构提前分配并串成链表,分配时从中取用。
古时候slab分配器就单指slab分配器,从2.6内核开始对slab分配器的实现添加了两个备选方案slub和slob,其实现在用slub比较多,包括笔者本人的板子和设备上的内核也都是slub。我认为slub就是在之前slab上优化后的一个产物,去除了许多臃肿的实现,逐渐会完全替代老的slab;而slob则是一个很轻量级的slab实现,代码量不大,官方说适合一些嵌入式设备。接下来我们详细介绍一下slub机制。
设计思想:
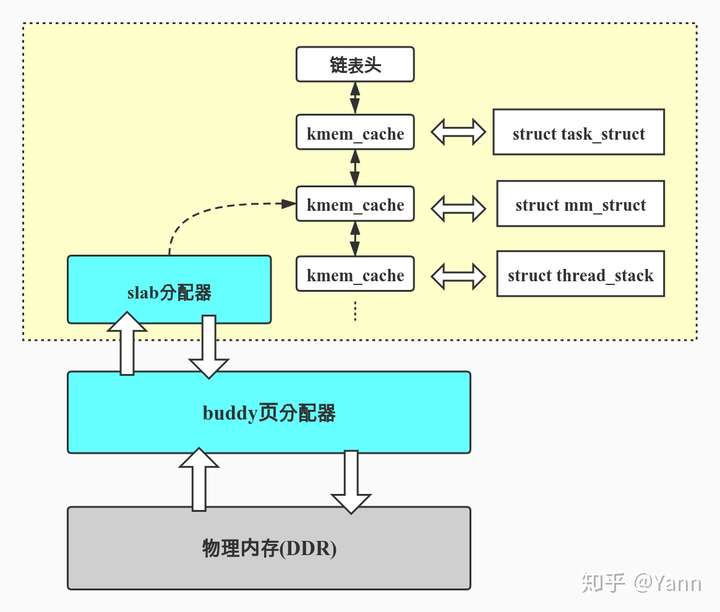
首先我们要知道是slab分配器是基于buddy分配器的,即slab需要从buddy分配器获取连续的物理页帧作为制造对象的原材料。简单来说,就是基于buddy分配器获得连续的pages,作为某数据结构对象的缓存,再将这段连续的pages从内部切割成一个个对齐的对象,使用时从中取用,这样一段连续的page我们称为一个slab。
slub分配器的使用:
/*分配一块给某个数据结构使用的缓存描述符
name:对象的名字 size:对象的实际大小 align:对齐要求,通常填0,创建是自动选择。 flags:可选标志位 ctor: 构造函数 */
struct kmem_cache *kmem_cache_create( const char *name, size_t size, size_t align, unsigned long flags, void (*ctor)(void*));
/*销毁kmem_cache_create分配的kmem_cache*/
int kmem_cache_destroy( struct kmem_cache *cachep);
/*从kmem_cache中分配一个object flags参数:GFP_KERNEL为常用的可睡眠的,GFP_ATOMIC从不睡眠 GFP_NOFS等等等*/
void* kmem_cache_alloc(struct kmem_cache* cachep, gfp_t flags);
/*释放object,把它返还给原先的slab*/
void kmem_cache_free(struct kmem_cache* cachep, void* objp);slab分配器使用起来很简单,通过上面的4个接口即可以为我们需要的object创建缓存并从中申请object。
1.先通过kmem_cache_create创建一个缓存管理描述符kmem_cache。
2.使用kmem_cache_alloc从缓存kmem_cache中申请object使用。
这里有个复杂且重要的结构体:struct kmem_cache,即缓存描述符。准确的来说它并不包含实际的缓存空间,而是包含了一些缓存的管理数据,和指向实际缓存空间的指针。
关键数据结构:kmem_cache
从上面的框图页我们可以看出kmem_cache在slab分配器中有着举足轻重的地位, slub设计思想和实现都藏在了struct kmem_cache中。内核中有着大量的数据结构都是通过slab分配器分配,它们申请并维护自己的kmem_cache,所有的kmem_cache又都被串在一个名为slab_caches的双向链表上。
kmem_cache数据结构中包含着许多的slab,其中一部存在于kmem_cache_node->partial中,每个node(若UMA架构则只有一个node)对应kmem_cache_node数组中的一项。另一部分slab位于per cpu的kmem_cache_cpu变量的partial成员中,kmem_cache_cpu为每个cpu提供一份本地的slab缓存(其实,这部分slab也是来源于kmem_cache_node中的slab)
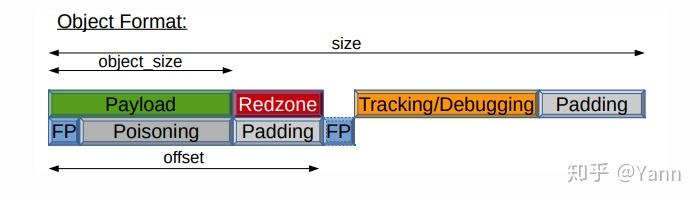
文章的开始我们也已经描述了slab就是1个或几个连续的page,然后在内部被切分成若干个对象(objects),同一块缓存中的slab大小相同,所以切分得到的对象数量也相同。slab中没有被使用的对象称为空闲对象(free object),同一slab中的所有空闲对象被串成了一个单项链表。如何串起来的呢?每个空闲对象的内部都会存有下一个空闲对象的地址,这样一来slab内的free objects就形成了一个单向链表,需要注意的是这个地址并未放在空闲对象的首地址处,而是首地址 + kmem_cache->offset的地方。
说了那么多,画了副图来表达kmem_cache数据结构之间关系,希望能帮助理解:
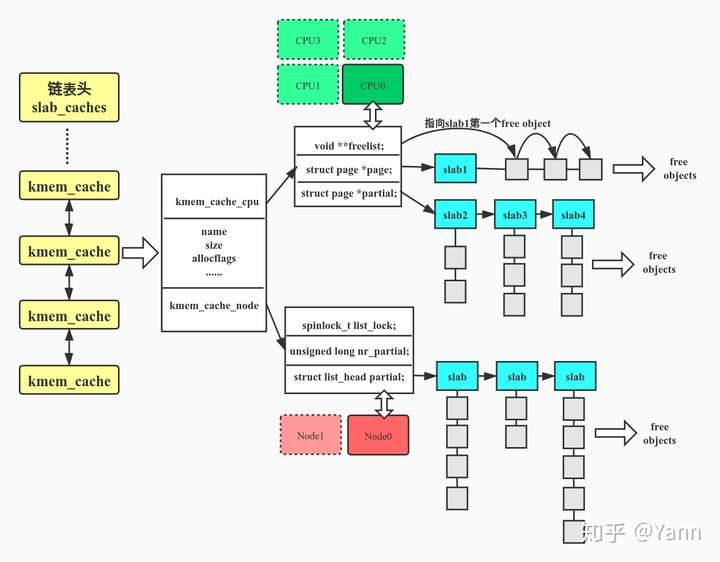
上图展示了各个数据结构之间的关系,接下来我们结合上图来看一下相关数据结构成员的含义:
struct kmem_cache {
/*per-cpu变量,用来实现每个CPU上的slab缓存。好处如下:
1.促使cpu_slab->freelist可以无锁访问,避免了竞争,提升分配速度
2.使得本地cpu缓存中分配出的objects被同一cpu访问,提升TLB对object的命中率(因为一个page中有多个object,他们共用同一个PTE)
*/
struct kmem_cache_cpu __percpu *cpu_slab;
/*下面这些是初始化kmem_cache时会设置的一些变量 */
/*分配时会用到的flags*/
slab_flags_t flags;
/*kmem_cache_shrink缩减partial slabs时,将被保有slab的最小值。由函数set_min_partial(s, ilog2(s->size)/2)设置。*/
unsigned long min_partial;
/*object的实际大小,包含元数据和对齐的空间*/
unsigned int size;
/*object中payload的大小,即目标数据结构的实际大小*/
unsigned int object_size;
/*每个free object中都存了next free object的地址,但是并未存在object的首地址,而是首地址加上offset的地方*/
unsigned int offset;
/*此结构体实际是个unsigned int,里面存了单个slab的占用的order数和一个slab中object的数量*/
struct kmem_cache_order_objects oo;
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
struct kmem_cache_order_objects min;
/*标准gfp掩码,用于从buddy分配页面时*/
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
/*object的构造函数,通常不使用*/
void (*ctor)(void *);
/*object中到metadata的偏移*/
unsigned int inuse;
/*对齐大小。澄清:slab中对齐方式通常有两种。1是按处理器字长对齐;2是按照cacheline大小对齐。*/
unsigned int align;
/*若flags中使用REDZONE时有意义*/
unsigned int red_left_pad; /* Left redzone padding size */
/*对象名称,例:mm_struct task_struct*/
const char *name;
/*kmem_cache的链表结构,通过此成员串在slab_caches链表上*/
struct list_head list;
/*下面两个成员用于表示对象内部的一块空间,使userspace可以访问其中的内容。具体可以看kmem_cache_create_usercopy的实现*/
unsigned int useroffset;
unsigned int usersize;
/*每个node对应一个数组项,kmem_cache_node中包含partial slab链表*/
struct kmem_cache_node *node[MAX_NUMNODES];
};
struct kmem_cache_cpu {
/*指向下面page指向的slab中的第一个free object*/
void **freelist;
/* Globally unique transaction id */
unsigned long tid;
/*指向当前正在使用的slab*/
struct page *page;
/*本地slab缓存池中的partial slab链表*/
struct page *partial;
};
struct kmem_cache_node {
/*kmem_cache_node数据结构的自选锁,可能涉及到多核访问*/
spinlock_t list_lock;
/*node中slab的数量*/
unsigned long nr_partial;
/*指向partial slab链表*/
struct list_head partial;
};slab的内部结构:
struct page中的slub成员:
顺便提一嘴,每个物理页都对应一个struct page结构体,结构体中有个联合体,其中定义了一些slab分配器要用到的成员。若该page用于slab,则下面成员将生效并被使用,代码如下。需要注意的是这里也有个freelist,它指向所属slab的第一个free object,不要和kmem_cache_cpu中的freelist混淆。
struct page {
......
struct { /* slab, slob and slub */
union {
struct list_head slab_list; /* uses lru */
struct { /* Partial pages */
struct page *next;
int pages; /* Nr of pages left */
int pobjects; /* Approximate count */
};
};
struct kmem_cache *slab_cache; /* not slob */
/* Double-word boundary */
void *freelist; /* 指向slab中第一个free object */
union {
void *s_mem; /* slab: first object */
unsigned long counters; /* SLUB */
struct { /* SLUB */
unsigned inuse:16; /*当前slab中已经分配的object数量*/
unsigned objects:15;
unsigned frozen:1;
};
};
......
}分配对象:
object的分配通过kmem_cache_alloc()接口,实际分配object的过程会存在以下几种情形:
- fast path:即可直接从本地cpu缓存中的freelist拿到可用object
kmem_cache_alloc
slab_alloc
slab_alloc_node
-->object = c->freelist //本地cpu缓存的freelist有可用的object
-->void *next_object=get_freepointer_safe(s, object); //获取next object的地址,用于后面更新freelist
-->this_cpu_cmpxchg_double //更新cpu_slab->freelist和cpu_slab->tid
-->prefetch_freepointer(s, next_object); //优化语句,将next object的地址放入cacheline,提高后面用到时的命中率
-->stat(s, ALLOC_FASTPATH); //设置状态为ALLOC_FASTPATH- slow path:本地cpu缓存中的freelist为NULL,但本地cpu缓存中的partial中有未满的slab
kmem_cache_alloc
slab_alloc
slab_alloc_node
__slab_alloc //分配过程关闭了本地中断
___slab_alloc
-->page = c->page为NULL的情况下 //即本地cpu缓存中当前在使用的slab的free object已经分完
-->goto new_slab; //跳转到new_slab,从本地缓存池的partial取一个slab赋给page,并跳转到redo
-->freelist = get_freelist(s, page) //获取page中的freelist(注意:此freelist为strcut page中的,并非本地cpu缓存的freelist)
-->c->freelist = get_freepointer(s, freelist) //将freelist重新赋给kmem_cache_cpu中的freelist - very slow path:本地cpu缓存中的freelist为NULL,且本地cpu缓存中的partial也无slab可用。
kmem_cache_alloc
slab_alloc
slab_alloc_node
__slab_alloc //分配过程关闭了本地中断
___slab_alloc
-->page = c->page为NULL的情况下 //即本地cpu缓存中当前在使用的slab的free object已经分完
-->goto new_slab; //跳转到new_slab,通过slub_percpu_partial(c)检查到本地cpu缓存池中partial无slab可用。
-->freelist = new_slab_objects(s, gfpflags, node, &c); //此函数中会出现两种情况:情况1.当前node对应的kmem_cache_node中有可用partial slab,并从
中获取slab分给本地cpu缓冲池。情况2.当前node对应的kmem_cache_node无可用的partial slab,
通过new_slab->allocate_slab->alloc_slab_page->alloc_pages从buddy分配器申请内存并创建新
的slab。两种情况最终都会返回一个可用的freelist
-->c->freelist = get_freepointer(s, freelist) //将freelist重新赋给kmem_cache_cpu中的freelist slab的回收:
object的回收和分配有些类似,也分为slow path和fast path。暂时没有写,后面有空的话补上。
slab调试:
- 通过/proc/slabinfo
root@intel-x86-64:~# cat /proc/slabinfo
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavai
l>
ecryptfs_key_record_cache 0 0 576 28 4 : tunables 0 0 0 : slabdata 0 0 0
ecryptfs_inode_cache 0 0 960 34 8 : tunables 0 0 0 : slabdata 0 0 0
ecryptfs_file_cache 0 0 16 256 1 : tunables 0 0 0 : slabdata 0 0 0
ecryptfs_auth_tok_list_item 0 0 832 39 8 : tunables 0 0 0 : slabdata 0 0 0
i915_dependency 0 0 128 32 1 : tunables 0 0 0 : slabdata 0 0 0
execute_cb 0 0 128 32 1 : tunables 0 0 0 : slabdata 0 0 0
i915_request 5 28 576 28 4 : tunables 0 0 0 : slabdata 1 1 0
intel_context 5 21 384 21 2 : tunables 0 0 0 : slabdata 1 1 0
nfsd4_delegations 0 0 248 33 2 : tunables 0 0 0 : slabdata 0 0 0
......- 通过slabtop工具
Active / Total Objects (% used) : 428417 / 433991 (98.7%)
Active / Total Slabs (% used) : 12139 / 12139 (100.0%)
Active / Total Caches (% used) : 86 / 156 (55.1%)
Active / Total Size (% used) : 117938.18K / 120241.55K (98.1%)
Minimum / Average / Maximum Object : 0.01K / 0.28K / 16.25K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
42944 42688 99% 0.06K 671 64 2684K anon_vma_chain
40320 38417 95% 0.19K 1920 21 7680K dentry
38752 38752 100% 0.12K 1211 32 4844K kernfs_node_cache
33138 31872 96% 0.19K 1578 21 6312K cred_jar
26880 26880 100% 0.03K 210 128 840K kmalloc-32
23976 23929 99% 0.59K 888 27 14208K inode_cache
22218 22218 100% 0.09K 483 46 1932K anon_vma
16576 16260 98% 0.25K 518 32 4144K filp
15360 15360 100% 0.01K 30 512 120K kmalloc-8
15104 15104 100% 0.02K 59 256 236K kmalloc-16
......- crash工具的kmem命令
crash中的kmem有着很多的用法,可通过help kmem详细了解,下面简单两个常用的命令。
- kmem -i:查看系统的内存使用情况。可以看到slab一共占用124.3MB
crash> kmem -i
PAGES TOTAL PERCENTAGE
TOTAL MEM 4046335 15.4 GB ----
FREE 3663809 14 GB 90% of TOTAL MEM
USED 382526 1.5 GB 9% of TOTAL MEM
SHARED 15487 60.5 MB 0% of TOTAL MEM
BUFFERS 0 0 0% of TOTAL MEM
CACHED 191471 747.9 MB 4% of TOTAL MEM
SLAB 31825 124.3 MB 0% of TOTAL MEM
TOTAL HUGE 0 0 ----
HUGE FREE 0 0 0% of TOTAL HUGE
TOTAL SWAP 0 0 ----
SWAP USED 0 0 0% of TOTAL SWAP
SWAP FREE 0 0 0% of TOTAL SWAP
COMMIT LIMIT 2023167 7.7 GB ----
COMMITTED 404292 1.5 GB 19% of TOTAL LIMIT2. kmem -S object_name:查看某个kmem_cache的slab使用情况
crash> kmem -S mm_struct
CACHE OBJSIZE ALLOCATED TOTAL SLABS SSIZE NAME
ffff9275fd00a840 1056 31 240 8 32k mm_struct
CPU 0 KMEM_CACHE_CPU:
ffff9275fec2eff0
CPU 0 SLAB:
SLAB MEMORY NODE TOTAL ALLOCATED FREE
ffffcdc190f25400 ffff9275fc950000 0 30 5 25
FREE / [ALLOCATED]
[ffff9275fc950000]
[ffff9275fc950440]
ffff9275fc950880 (cpu 0 cache)
[ffff9275fc950cc0]
ffff9275fc951100 (cpu 0 cache)
ffff9275fc951540 (cpu 0 cache)
ffff9275fc951980 (cpu 0 cache)
ffff9275fc951dc0 (cpu 0 cache)
ffff9275fc952200 (cpu 0 cache)
ffff9275fc952640 (cpu 0 cache)
[ffff9275fc952a80]
ffff9275fc952ec0 (cpu 0 cache)
ffff9275fc953300 (cpu 0 cache)
.........
参考:
《linux内核设计与实现》第三版
《深入理解linux内核架构》
The Linux Foundation官方网站
https://hammertux.github.io/slab-allocator
https://fliphtml5.com/traq/olio/basic
原创文章,转载和引用请注明出处。
作者:Yann Xu

