小技巧整理(一)
小技巧(一)
2020-03-18
liunx不常见但实用的命令
# 统计行数 字数 字符数
wc 123.txt
# 找到并删除30天以前的符合格式的文件
find /home/midou/logs// -mtime +30 -name "*.log.gz" -exec rm -rf {} \;
# 比较文件不同
diff testA.txt testB.txt
2020-03-19
快速创建相似表语句
CREATE TABLE order_record like order_today;
事务模式 2PC(两阶段提交),3PC(三阶段提交),TCC(补偿事务)的问题
2PC可能带来的三大问题
- 第二阶段提交过程若网络抖动或不稳定导致一方参与者没有收到commit消息,可能导致数据不一致
- 网络超时问题带来的网络同步阻塞问题,参与者占用的资源得不到释放
- 事务管理器单点问题,一旦协调者故障,它所造成的阻塞问题,哪怕有重新选举出协调者也不能解决前一个的遗留问题
3PC可能带来的问题
- 两阶段和三阶段的本质区别我理解就是加入了询问参与者事务是否可以提交阶段,一旦因为网络抖动不能执行这一步,超时后协调者会向所有参与者发送abort中断命令。加入第二阶段的意义在于,确保提交前状态一致
- 第三阶段同样若没有收到参与者成功响应,也会发送abort中断事务,若协调者故障,参与者一直没收到commit信号,则会自动提交事务
- 简单来讲就是 => 是否可以提交请求->事务是否可以正常执行->统一提交事务
- 3PC还存在问题,不能确保在协调者故障后,自动提交的一致性,可能协调者调用参与者A是通知abort中断事务,但参与者B由于网络问题,没有接收到,自动提交,导致不一致问题
TCC的问题
- 事务补偿机制,是通过业务层代码实现,侵入性太强,每个操作都需要try confirm cancel三个接口操作
- 开发难度大,较难维护,要确保数据一致性,confirm和cancel还要保证幂等性
mybatis需要注意问题
- mybatis Integer类型不能判!='',否则0值传不进来
2020-03-23
记一次k8s节点一直重启问题排查
查找
- 经初步排查,发现由于内存溢出导致节点重启
查节点
- top 发现dockered占用了3个G
- pidof dockered 查id
- lsof -p id | wc -l 查看打开文件数,上万肯定多了
- sudo lsof -p 4364|grep 137f8a0eb714 | wc -l 查看容器节点文件打开数
- 一般每个容器打开节点数为5个上下,若因为单个容器的原因导致文件打开节点数过多,可以专门针对该容器处理,最简单的就是重启它
- 而我发现我的问题是docker.sock 有非常多,似乎是容器本身打开了很多节点,没查出具体原因,但解决方法很简单,比较彻底的就是重启ECS,或许重启docker也行
2020-03-24
JVM参数优化
- 用以分析优化JVM参数和刚开始配置该参数
Java线程Dump分析
- 用以分析dump数据
Java内存Dump分析
- 用以分析JVM内存
导出hprof
jmap -dump:format=b,file=/home/admin/logs/heap.hprof 6214
导出dump
jstack -l 6111 > xxx.dump
2020-03-25
idea技巧
ctrl+alt+shift+N可以直接查spring上的mapping,比如/user/getPhone- 点idea中
database的表,再ctrl+Q可以快速查看表创建语句,索引创建语句,和开头10条数据 shift+alt+c查询最近作出的改变
数据库优化技巧(不常见)
- 使用
left join的时候,左边表尽量小,更节省开销,有条件的尽量放到左边处理 - exist & in的合理利用
select * from A where deptId in (select deptId from B);
select * from A where exists (select 1 from B where A.deptId = B.deptId);
mysql优化原则,就是小表驱动大表,小的数据集驱动大的数据集,从而让性能更优。
因此,我们要选择最外层循环小的,也就是,如果B的数据量小于A,适合使用in,如果B的数据量大于A,即适合选择exist。
- LIMIT n, m的效率是十分低的,一般可以通过在WHERE条件中指定范围来优化 WHERE id > ? limit 10
2020-03-26
mysql知识点补充
- explain的key_len表示使用到的索引长度,可以用来对比哪个索引没有用到
show profile进行sql调优
show VARIABLES like 'profiling'判断是否开启调优set profiling=on开启show profiles- 使用
show profile cpu,block io for query Query_ID;进行针对sql诊断
①converting HEAP to MyISAM:查询结果太大,内存不够,数据往磁盘上搬了。
②Creating tmp table:创建临时表。先拷贝数据到临时表,用完后再删除临时表。
③Copying to tmp table on disk:把内存中临时表复制到磁盘上,危险!!!
④locked。
如果在show profile诊断结果中出现了以上4条结果中的任何一条,则sql语句需要优化。
全局查询日志开启(生产环境别开)
show VARIABLES like '%general%%'查看是否开启set global general_log=1;开启set global log_output='TABLE';可通过sql查询查询过的sql
表锁判断与解决
show open tables where in_use>0;则in_use大于0则表示有锁unlock tables;解锁表show status like 'table%';,其中Table_locks_waited出现表级锁定争用而发生等待的次数(不能立即获取锁的次数,每等待一次锁该值加1),此值高则说明存在较严重的表级锁争用情况
行锁判断与解决
show status like 'innodb_row_lock%';
Innodb_row_lock_current_waits 0
Innodb_row_lock_time 39122
Innodb_row_lock_time_avg 4890
Innodb_row_lock_time_max 23008
Innodb_row_lock_waits 8
①Innodb_row_lock_current_waits:当前正在等待锁定的数量。
②Innodb_row_lock_time:从系统启动到现在锁定的时长。
③Innodb_row_lock_time_avg:每次等待锁所花平均时间。
④Innodb_row_lock_time_max:从系统启动到现在锁等待最长的一次所花的时间。
⑤Innodb_row_lock_waits:系统启动后到现在总共等待锁的次数。
2020-03-31
Spring循环依赖问题
- 分为构造函数依赖,属性依赖,构造函数依赖不能解决只会报异常
- 属性依赖Spring采用提前暴露对象的方式
- Spring的单例对象初始化主要分为三部:
- 实例化对象,会调用构造方法;createBeanInstance
- 属性填充,包括依赖的对象填充;populateBean
- 调用xml中init初始化方法;InitializeBean
- Spring解决循环依赖使用的是三级缓存,分别指
- singletonFactories 单例工厂cache
- earlySingletonObjects 提早曝光的单例对象cache
- singletonObjects 单例对象cache
2020-04-02
Kafka为什么这么快
- 消息批量压缩发送,减少网络IO损耗
- 通过Memory Mapped Files(mmap)内存映射文件提高IO速度,数据尾部写入速度最优
- 基于sendfile,减少内核到用户空间的拷贝过程,提升读取速度
tomcat限流
- tomcat有server.tomcat.accept-count这个参数,如果设置的比较小,超出的请求不会被处理,也可以减少tomcat线程的占用。比改代码风险小的多
arthas
安装启动
wget https://alibaba.github.io/arthas/arthas-boot.jar
java -jar arthas-boot.jar --target-ip 0.0.0.0
热修改代码
- jad --source-only com.example.demo.arthas.user.UserController > /tmp/UserController.java 保存反编译文件
- sc -d *UserController | grep classLoaderHash 找到类加载编号
- mc -c 1be6f5c3 /tmp/UserController.java -d /tmp 编译
- redefine /tmp/com/example/demo/arthas/user/UserController.class 重新加载
jad --source-only com.onegene.biology.biologywork.util.ReportUtil > /tmp/ReportUtil.java
sc -d *ReportUtil | grep classLoaderHash
mc -c 66b1b2c /tmp/ReportUtil.java -d /tmp
redefine /tmp/com/onegene/biology/biologywork/util/ReportUtil.class
2020-04-10
Mapper
tk-mybatis除了Mapper接口其实还提供了更多便捷接口
2020-04-15
通用日期格式化jackson配置
@Bean
@Primary
@ConditionalOnMissingBean(ObjectMapper.class)
public ObjectMapper jacksonObjectMapper(Jackson2ObjectMapperBuilder builder) {
ObjectMapper objectMapper = builder.createXmlMapper(false).build();
// 通过该方法对mapper对象进行设置,所有序列化的对象都将按改规则进行系列化
// Include.Include.ALWAYS 默认
// Include.NON_DEFAULT 属性为默认值不序列化
// Include.NON_EMPTY 属性为 空("") 或者为 NULL 都不序列化,则返回的json是没有这个字段的。这样对移动端会更省流量
// Include.NON_NULL 属性为NULL 不序列化
objectMapper.setSerializationInclusion(JsonInclude.Include.ALWAYS);
objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
// 允许出现特殊字符和转义符
objectMapper.configure(JsonParser.Feature.ALLOW_UNQUOTED_CONTROL_CHARS, true);
// 允许出现单引号
objectMapper.configure(JsonParser.Feature.ALLOW_SINGLE_QUOTES, true);
objectMapper.setDateFormat(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));
return objectMapper;
}
2020-04-17
@EnableAutoConfiguration配合META-INF/spring-factories
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
org.springframework.boot.autoconfigure.admin.SpringApplicationAdminJmxAutoConfiguration,\
org.springframework.boot.autoconfigure.aop.AopAutoConfiguration,\
org.springframework.boot.autoconfigure.amqp.RabbitAutoConfiguration
2020-04-18
- 比较两个内容是否有变化,只需要比较两者的md5值
2020-04-23
@Vaildator在Controller层对象的属性若是对象,属性需要加上@Vaild注解,属性对象内的参数注解才会起作用
2020-04-24
- idea可以条件断电
2020-04-25
CaseFormat来自guava的驼峰转换工具
CaseFormat.UPPER_CAMEL.to(CaseFormat.LOWER_CAMEL, modelNameUpperCamel))
2020-04-27
- 误删数据库恢复办法,前提是数据库有备份或开启binlog日志
2020-05-09
raft协议
- 所有节点都会以follower状态开始,如果没有收到leader的来信,那么他们都可以成为候选人
- 选举超时,指follower成为candidate之前所等待的时间,等待超时后,follower成为candidate开始新的选举任期
- 最先选举超时的节点,会先投自己一票,并向别的所有节点请求投票,如果其它节点在term任期内还没有投票则会投给它
- 一旦候选人candidate获得大多数投票,便成为leader,leader持续向follower发送心跳
- 一旦leader挂了,在选举超时后,有节点会成为candidate开始新一轮投票选举
- 当有两个节点同时发起候选人投票请求,且票数一致,会在这两个candidate中重设选举超时时间,先到时间的会再发起请求投票,确定leader
- 当发生网络分区,可能会产生两个领导者,客户端请求两个领导者产生不同的数据,但肯定分区数据复制不能达到半数节点,只有达到半数节点的分区能完成日志提交,当网络恢复时,将会以更高的term为准,未提交的数据将会回滚
ZAB协议
特性
- 保障已经在Leader服务器上提交的事务最终被所有的服务器提交
- 确保丢弃那些只在leader上被提出而没有被提交的事务
Zab协议原理
- 发现:zk集群必须选举出一个leader进程,同时leader会维护一个follower可用客户端列表
- 同步:leader负责将本身的数据和follower完成同步,做到多副本存储
- 广播:leader接收客户端新的事务Proposal请求,并广播给所有的follower
协议过程
包括了崩溃恢复和消息广播
2020-05-11
数据库乱码
- 数据库的乱码,可能只需要在mysql的url后加
&characterEncoding=UTF-8
界面化接口定义工具Hasor
2020-05-12
分布式锁的优化思路:购买商品,当有10000个请求同时并发过来,可以尝试用分段锁+合并库存的方式,比如将10000个库存拆分成10个1000个库存,相当于10个锁,可分配到不同机器上,当库存不够时,再锁别的库存合并
2020-05-14
Mybatis
- 一级缓存 session级别
- 二级缓存 namespace 即mapper级别的
2020-05-15
TODO用法
- TODO添加,设计代码目录
Redis sortedset 实现延迟队列
- score放时间戳,用zrangebyscore拉一定时间的数据,时间延迟读取
2020-05-18
- synchronize 编译后通过monitorenter 和 monitorexit指令实现互斥同步
2020-05-27
synchronized和ReentrantLock的区别
首先synchronized和ReentrantLock都是可重入锁
区别:
- synchronized是JVM层面实现,reentrantLock是JDK代码层面实现
- synchronized非公平锁,ReentrantLock可实现公平锁
- ReentrantLock可中断锁
- ReentrantLock可指定唤醒线程 Condition
2020-05-28
ThreadLocal
- ThreadLocal方法后 最好手动调用remove()方法,否则value不会被垃圾回收,其key为弱引用,value为强引用,可能导致key为null而value一直存在的情况
ThreadPoolExecutor 饱和策略
- ThreadPoolExecutor.AbortPolicy:抛出 RejectedExecutionException来拒绝新任务的处理。
- ThreadPoolExecutor.CallerRunsPolicy:调用执行自己的线程运行任务。您不会任务请求。但是这种策略会降低对于新任务提交速度,影响程序的整体性能。另外,这个策略喜欢增加队列容量。如果您的应用程序可以承受此延迟并且你不能任务丢弃任何一个任务请求的话,你可以选择这个策略。
- ThreadPoolExecutor.DiscardPolicy: 不处理新任务,直接丢弃掉。
- ThreadPoolExecutor.DiscardOldestPolicy: 此策略将丢弃最早的未处理的任务请求。
AQS
AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
2020-06-02
@Transactional
在@Transactional注解中如果不配置rollbackFor属性,那么事物只会在遇到RuntimeException的时候才会回滚
HyperLogLog
- 用户基数统计,比如访问用户数uv,同一用户去重,存在一定误差
Redis的发布订阅问题
- 没有Ack机制,不保证数据的连续。如果没有一个消费者,那么消息会被直接丢弃。
- 不持久化消息,如果Redis宕机,所有消息都会直接丢弃
2020-06-04
Netty知识点
特点
Netty是一个基于NIO的网络通信框架,具有高并发,传输快,封装好的特点
option
ChannelOption.SO_BACKLOG,标识当服务器请求处理线程全满时,用于临时存放已完成三次握手的请求的队列的最大长度。如果未设置或所设置的值小于1,Java将使用默认值50。ChannelOption.SO_KEEPALIVE,是否启用心跳保活机制。在双方TCP套接字建立连接后(即都进入ESTABLISHED状态)并且在两个小时左右上层没有任何数据传输的情况下,这套机制才会被激活。ChannelOption.TCP_NODELAY,如果要求高实时性,有数据发送时就马上发送,就将该选项设置为true关闭Nagle算法;如果要减少发送次数减少网络交互,就设置为false等累积一定大小后再发送。默认为false。ChannelOption.SO_RCVBUF AND ChannelOption.SO_SNDBUF,定义接收或者传输的系统缓冲区buf的大小ChannelOption.ALLOCATOR
Netty4使用对象池,重用缓冲区
bootstrap.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
bootstrap.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
handler()和childHandler()
handler()和childHandler()的主要区别是,handler()是发生在初始化的时候,childHandler()是发生在客户端连接之后
队列
原则:都是先入先出
- add 添加成功返回true,失败抛异常
- poll 获取一个队列数据并删除,不存在返回null
- put 阻塞试的放入队列,队列满了则阻塞等待别的线程取走数据才能放入
- take 队列有数据则直接获取并删除一个,没数据阻塞等待其它线程放入数据
- offer 添加数据,队列满了不阻塞,直接返回false表示添加失败
- peek 获取队列数据且不删除,获取不到则返回null
2020-06-05
Mysql更新语句执行过程
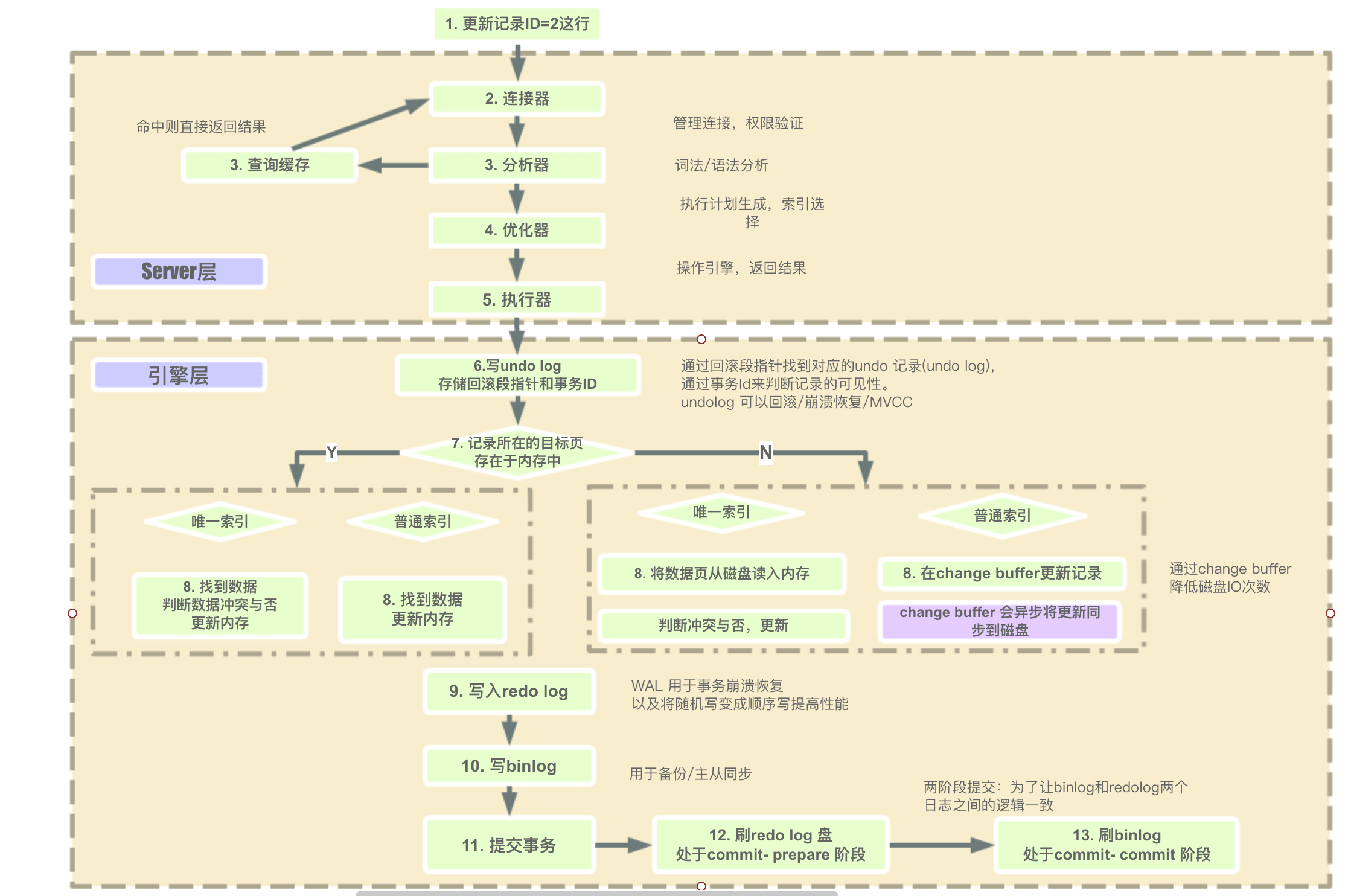
脏页是什么?
就是内存数据页与磁盘内存页的内容不一致时的内存页叫做脏页。内存页数据写入磁盘后,数据一致了,就是干净页了。
MVCC的实现原理是怎么样的?
mvcc主要适用于提交读,可重复读,可以解决幻读的问题。
innodb在解决幻读的问题主要是通MVVC 多版本并发版本控制来实现的
就是每一行数据中额外保存两个隐藏的列,创建时的版本号,删除时的版本号(可能为空),滚动指针(指向undo log中用于事务回滚的日志记录)
事务在对数据修改后,进行保存时,如果数据行的当前版本号与事务开始取得数据的版本号一致就保存成功,否则保存失败。
B树与B+树的区别是什么?
- B树每个节点会保存关键字,索引和数据。而B+树只有叶子节点保存数据,其他节点只保存关键字和索引,有更低的树高。所以相同的内存空间可以容纳更多的节点元素。
- B+树的所有数据都存在叶子节点上,所以查询会更加稳定,而且相邻的叶子节点都是连接在一起的,更加适合区间查找和搜索,
为什么不用红黑树?
红黑树等平衡树也可以用来实现索引,但是文件系统及数据库系统普遍采用 B+ Tree 作为索引结构,主要有以下两个原因:
(一)更少的查找次数
平衡树查找操作的时间复杂度和树高 h 相关,O(h)=O(logdN),其中 d 为每个节点的出度。
红黑树的出度为 2,而 B+ Tree 的出度一般都非常大,所以红黑树的树高 h 很明显比 B+ Tree 大非常多,查找的次数也就更多。
(二)利用磁盘预读特性
为了减少磁盘 I/O 操作,磁盘往往不是严格按需读取,而是每次都会预读。而B+数中存储的叶子节点在内存中是相邻的,这样可以读取会快一些。
hashMap键值对添加过程
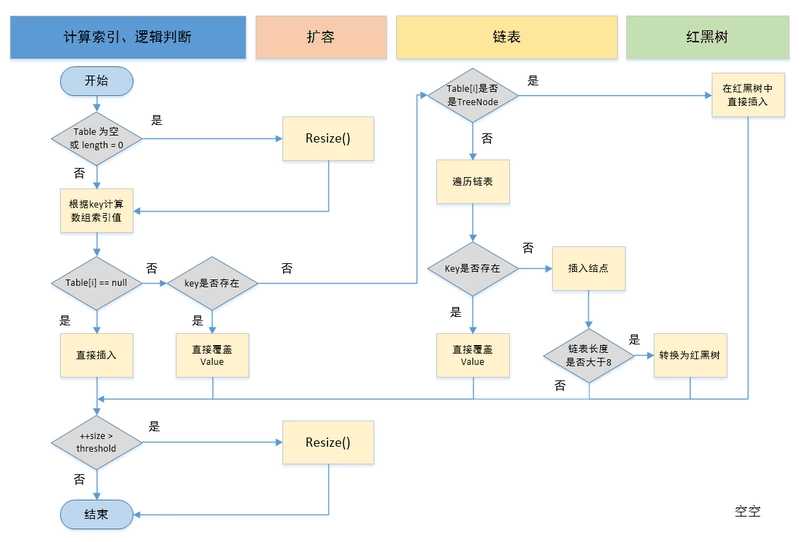
HashMap 非线程安全
HashMap是非线程安全的。(例如多个线程插入多个键值对,如果两个键值对的key哈希冲突,可能会使得两个线程在操作同一个链表中的节点,导致一个键值对的value被覆盖)
ConcurrentHash键值对添加过程
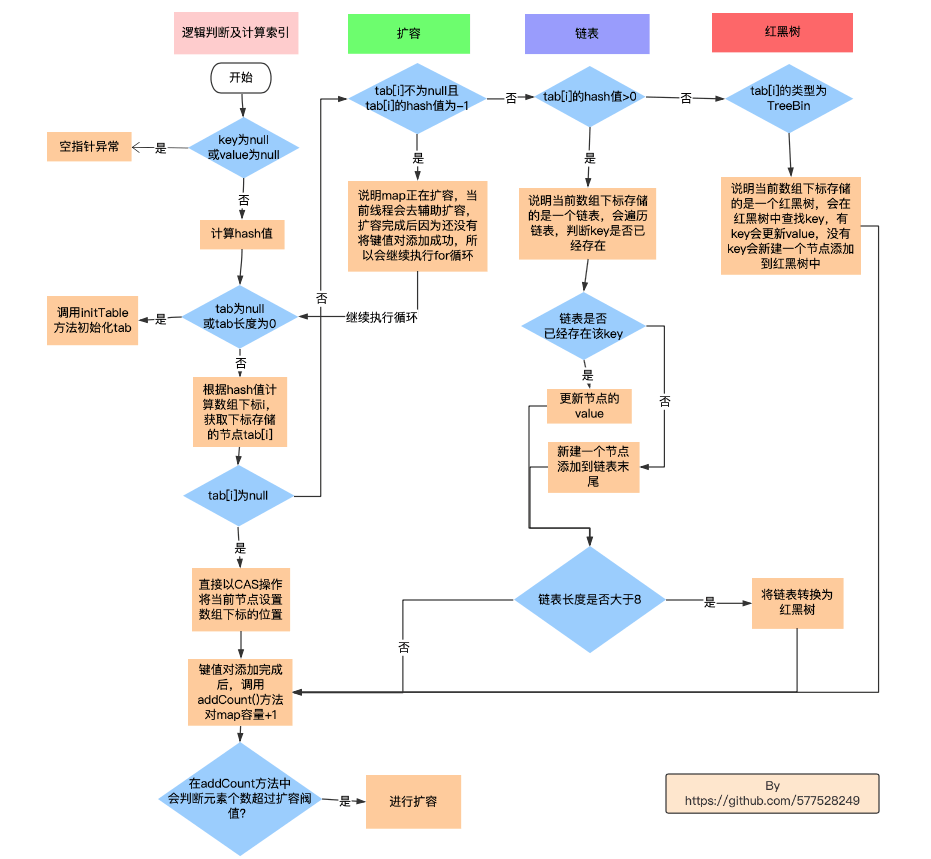
- 链表长度大于等于8,且数组长度大于64时,才会转换红黑树
ConcurrentHashMap 线程安全
ConcurrentHashMap是线程安全的,主要是通过CAS操作+synchronized来保证线程安全的。
2020-06-08
kafka怎么保证数据不丢失
- 每个topic至少设置2个partition
- 设置leader至少感知有一个follower活着
- 设置ack=all即每天数据都得到回应后才认为写成功
2020-06-09
Mysql知识点
!=特定值,查询结果不包含null
2020-06-15
spring aop事务调用方式,调用同一类中B方法
((ServiceA ) AopContext.currentProxy()).insert();
2020-06-22
Kubeasz
k8s快速安装
2020-06-28
IO多路复用理解
模式有 select,poll,epoll
- select的最大连接数默认1024存在限制;数据需要从用户态拷贝到内核态,开销也比较大;对socket扫描采用轮询的方法,效率较低
- poll和select的区别,取消了最大连接数的限制
2020-07-08
Filter和Interceptor区别
- 实现原理Filter使用函数回调,通过doFilter()方法实现;interceptor通过反射动态代理实现
- 使用范围Filter依赖Tomcat等容器,只能在web程序中使用;interceptor依赖Spring管理,不仅仅可以用在web程序
- 触发时机不同
2020-07-09
下载PDF文件,中文名乱码解决
response.setHeader(HttpHeaders.CONTENT_DISPOSITION, "attachment;fileName=" + new String((fileName + ".pdf").getBytes("UTF-8"), "iso-8859-1"));
显示SQL优化后语句
explain后加show warnings;一起执行
SQL快速造数据
DELIMITER ;;
CREATE PROCEDURE insertData()
BEGIN
declare i int;
set i = 1 ;
WHILE (i < 1000000) DO
INSERT INTO student(`name`,class,`page`,`status`)
VALUES(CONCAT('class_', i),
CONCAT('class_', i),
i, (SELECT FLOOR(RAND() * 2)));
set i = i + 1;
END WHILE;
commit;
END;;
CALL insertData();
simpread(简悦)
一款超好用的阅读插件,可以帮我们聚焦需要阅读的内容
GitHub地址:https://github.com/Kenshin/simpread
2020-07-14
一款Redis客户端,window和mac都有
Github地址:https://github.com/qishibo/AnotherRedisDesktopManager
如果,您希望更容易地发现我的新博客,不妨点击一下【关注我】。
我的写作热情也离不开您的肯定支持,感谢您的阅读,我是【老梁】!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号