多处理器计算机中的NUMA架构
非统一内存访问(NUMA)描述了当代多处理系统中使用的共享内存架构。
NUMA是一个由多个节点组成的计算系统: 每个CPU被分配自己的本地内存,并且可以从系统中的其他CPU访问远程内存。
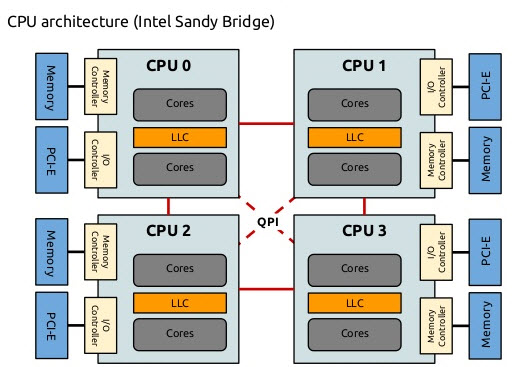
如此设计主要是为了解决UMA架构中, 基于总线的计算机系统的一个瓶颈——有限的带宽会导致可伸缩性问题。系统中添加的cpu越多,每个节点可用的分得的带宽就越少。此外,添加的cpu越多,单个cpu的内存带宽就越小,总线增长,访存时延也会增大。
支持NUMA技术的计算机允许所有cpu直接访问整个内存——cpu将其视为一个单一的线性地址空间。这可以更有效地使用64位寻址方案,从而更快地移动数据、更少地复制数据、更容易地进行编程。
总之,NUMA架构解决了可伸缩性问题,这是它的主要优点之一。在NUMA中,内存分配总是优先在本地节点上进行,一个节点的cpu将拥有更高的带宽或更低的延迟来访问同一节点上的内存。缺点是将数据从一个节点到另一个节点的成本较高。只要这种情况不经常发生,NUMA系统将优于具有更传统架构的系统。
为了避免缓存丢失和保证多缓存的一致性,需要花费大量的研究时间来寻找合适的CPU缓存数量、缓存结构和相应的算法。
内存写引发cpu缓存更新,需要内存和多个cache的一致性,来保证每次读到最新的数据,协议有两种:
snoopy总线嗅探
Directory每个主存集中式管理全局状态表
NUMA系统中一般使用Directory,因为对NUMA的拓展性更好,AEP也是使用Directory。测试结果显示,跨numa 对aep写的性能下降到不跨的20%。主要原因是发生随机写,更新本地aep上的缓存状态表,性能拉胯。
BPS机器可以配置使用snoopy,跨numa性能大大改善。不需要写本地缓存表,而是其他node主动嗅探总线,就可以知道对哪些数据做了修改。
ref:
https://www.cnblogs.com/cdaniu/p/15598997.html
https://mp.weixin.qq.com/s/l3S7FivUX-ynnWe7tLS-ww
https://wingsxdu.com/posts/note/cpu-cache-and-memory-barriers/
https://people.eecs.berkeley.edu/~pattrsn/252F96/Lecture18.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号