Linux IO过程和数据结构
通过相关系统调用(如open/read/write)发起IO请求,属于IO请求的源头。
X86 系统结构中,所有系统调用都从用户空间中汇聚到 0x80 中断点,同时保存具体的系统调用号。当read系统调用调用发生时,库函数在保存read系统调用号以及参数后,陷入0x80 中断。0x80 中断处理程序将根据系统调用号对不同的系统调用分别处理(调用不同的内核函数处理)。也就是说,陷入 0x80 中断,这时IO库函数工作结束。Read 系统调用在用户空间中的处理也就完成了,后面交给内核处理。
系统调用在内核中分层处理

对于read系统调用在内核的处理,如上图所述,经过了VFS、具体文件系统,如ext2、页高速缓冲存层、块设备层、设备驱动层、和设备层。
-
VFS。其中,VFS主要是用来屏蔽下层具体文件系统操作的差异,对上提供一个统一接口,正是因为有了这个层次,所以可以把设备抽象成文件。具体文件系统(ext4、xfs等),则定义了自己的块大小、操作集合等。
-
page cache。引入cache层的目的,是为了提高IO效率。它缓存了磁盘上的部分数据,当请求到达时,如果在cache中存在该数据且是最新的,则直接将其传递给用户程序,免除了对底层磁盘的操作。当从块设备读取时,会预读。
-
块设备层。主要工作是,接收上层发出的磁盘请求,会对这些IO请求作合并、排序、调度等,并最终发出IO请求(BIO)。它提供了一套具体设备的抽象接口,用来访问多种不同的存储设备的模块接口。在该层次上实现了多种电梯调度算法,对bio请求合并和排序,回调驱动层提供的请求处理函数,以处理具体的IO请求。如cfq、deadline等。
-
SCSI驱动层。驱动层的驱动程序对应具体的物理设备,它从上层取出IO请求,并根据该IO请求中指定的信息,通过向具体块设备的设备控制器发送命令的方式,来操纵设备传输数据。
-
设备层都是具体的物理设备。
buffer IO、mmap、direct io
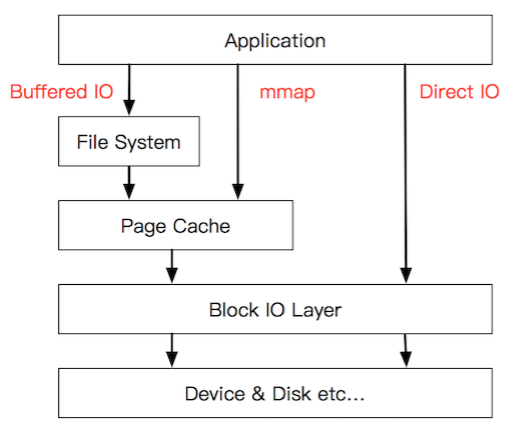
- Buffered IO是调用read/write时的IO形式,read时,经过vfs,达到page cache,如果在page cache中存在要读取的数据,则直接从page cache内存复制到用户内存空间,不需要再交给下层处理。write如果作用在page cache,几乎不会发生真实io,而是交给os异步处理回写。
- mmap 把文件映射到用户空间里的虚拟内存,省去了Buffered IO中从page cache复制到用户空间的过程,文件中的位置在虚拟内存中有了对应的地址,可以像操作内存一样操作这个文件,相当于已经把整个文件放入内存,但在真正使用到这些数据前却不会消耗物理内存,也不会有读写磁盘的操作。读写到来时,以page fault的形式由操作系统完成io。在支持DAX的文件系统中,比如NVM(PMEM/AEP/BPS),需要使用mmap,存在构建页表和page fault的开销。
mmmap减少了一次内存复制,但也有不方便的地方:
MMAP 使用时必须实现指定好内存映射的大小,对于文件不确定大小的情形实在是太不友好了。
MMAP 使用的是虚拟内存,和 PageCache 一样是由操作系统来控制刷盘的,虽然可以通过 force() 来手动控制,但这个时间把握不好,在小内存场景下会很令人头疼。
MMAP 的回收问题,当 MappedByteBuffer 不再需要时,可以手动释放占用的虚拟内存,处理非常麻烦。
- Direct IO 绕过了 PageCache,在随机读的场景下,page cache无法预取优化,反而带来开销。一些数据库系统想自己管理缓存,可以使用Direct IO.
内核中数据结构
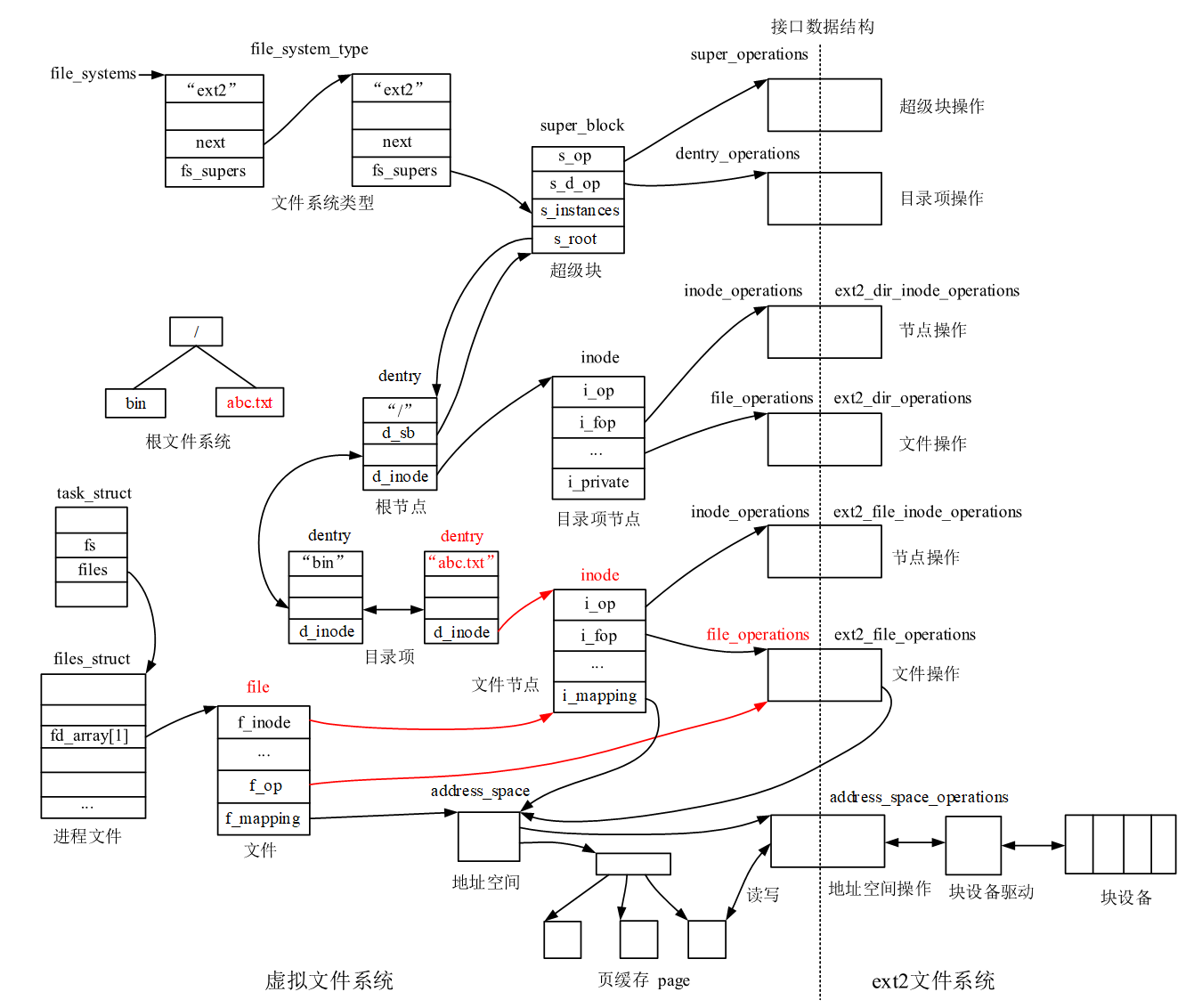
ref
https://lwn.net/Articles/736534/
https://www.modb.pro/db/128893
https://zhuanlan.zhihu.com/p/39721251
https://developer.aliyun.com/article/374897
https://bbs.huaweicloud.com/forum/thread-37695-1-1.html
https://spongecaptain.cool/SimpleClearFileIO/1. page cache.html
https://spongecaptain.cool/SimpleClearFileIO/
https://www.cnkirito.moe/file-io-best-practise/
