Python序列 数据类型 创建方式 Tuple元组 Str字符串 List列表 dict字典 Set集合 range,zip,map,enumerate
Python 序列分类 数据类型
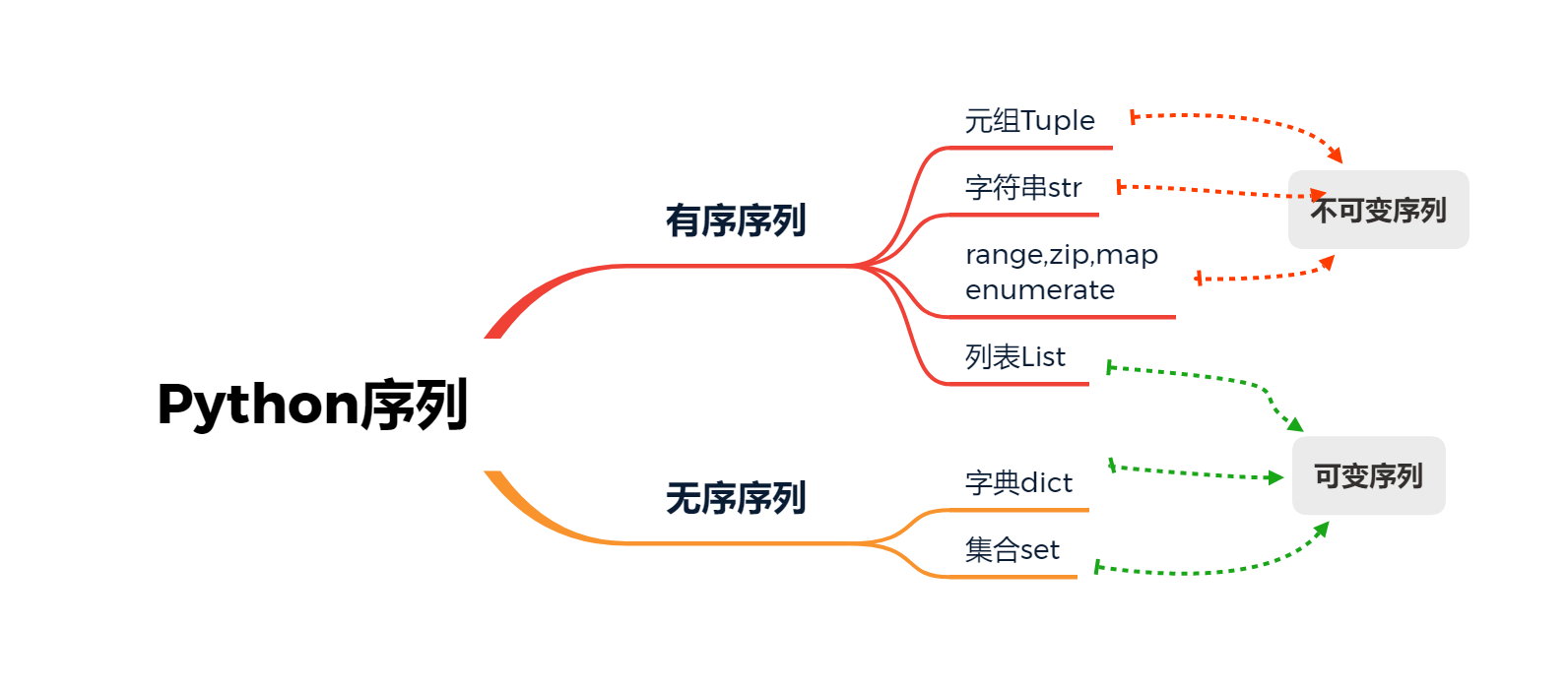
详细介绍
Python 主要数据类型: 元组Tuple, 字符串Str,列表List,字典Dict,集合Set
对比
| 元组Tuple | 字符串Str | 列表List | 字典Dict | 集合Set | |
|---|---|---|---|---|---|
| 形式 | (1, 2, 3) | “abc” | [1, 2, 3] | {key : value} | {1, 2, 3} |
| 可变 | 不可变 | 不可变 | 可变 | 可变 | 可变 |
| 有序 | 有序 | 有序 | 有序 | 无序 | 无序 |
| 转换函数 | tuple() | str() | list() | dict() | set() |
各大类型创建方式
Tuple元组
Tuple是不可变的序列,通常用于存储异构数据的集合(例如由内置的 enumerate() 生成的 2 元组)。 元组还用于需要不可变的同构数据序列的情况(例如允许存储在集合或字典实例中)。3
可以通过多种方式构造元组:
-
使用一对括号表示空元组:
() -
对单例元组使用尾随逗号:
a,或(a,) -
分隔 带逗号的项目:
a, b, c或(a, b, c) -
使用
tuple()内置:tuple()或tuple(iterable)
-
构造函数构建一个元组,其项目相同且顺序相同 作为可迭代的项目。
iterable可以是一个序列、一个支持迭代的容器或一个迭代器对象。 如果iterable已经是一个元组,则原样返回。 例如,tuple('abc')返回('a', 'b', 'c')和tuple( [1, 2, 3] )返回(1, 2, 3)。 如果没有给出参数,构造函数会创建一个新的空元组,()。 -
请注意,实际上是逗号构成了元组,而不是括号。 括号是可选的,除了在空元组的情况下,或者当需要它们以避免句法歧义时。 例如,f(a, b, c) 是一个带有三个参数的函数调用,而 f((a, b, c)) 是一个带有 3 元组作为唯一参数的函数调用。
-
元组实现了所有常见的序列操作。
-
定义
tuple = (1, 2, 3) -
转换
tuple([iterable])
>>> tuple('abc')
('a', 'b', 'c')
>>> type((1, 2, 3))
<class 'tuple'>
Str字符串
文本序列类型-Python中的str文本数据是用str对象或字符串处理的。字符串是Unicode代码点的不可变序列。字符串文字的书写方式多种多样:
- 单引号:
'allows embedded "double" quotes' - 双引号:
"allows embedded 'single' quotes" - 三重引号:
'''Three single quotes''', """Three double quotes"""
-
三重引号字符串可以跨多行-所有关联的空格都将包含在字符串文本中。
-
作为单个表达式的一部分并且它们之间只有空格的字符串文字将隐式转换为单个字符串文字。也就是说,(“spam”“eggs”)=“spam eggs”。
定义str = "fyz is nb plus pro Max"
转换str(obj)
>>> str(b'Zoot!')
"b'Zoot!'"
range,zip,map,enumerate
map(function, iterable, …)
map(function, iterable, …)
map(function, iterable, ...)返回一个迭代器,该迭代器将函数应用于可迭代的每个项目,产生结果。 如果传递了额外的可迭代参数,则函数必须采用那么多参数并并行应用于所有可迭代项中的项目。 对于多个可迭代对象,当最短的可迭代对象耗尽时,迭代器将停止。function:函数,iterable:可迭代对象
>>>list(map(lambda x, y : x + y, [1, 2, 3], [10, 20, 30, 40, 50]))
[11, 22, 33]
Ranges
range表示一个不可变的数字序列,通常用于在 for 循环中循环特定次数。
-
range(stop) -
range(start, stop[, step]) -
start 开始参数的值(如果没有提供参数,则为 0)
-
stop 停止参数的值
-
step 步骤参数的值(如果没有提供参数,则为 1)
>>> list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> list(range(1, 11))
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> list(range(0, 30, 5))
[0, 5, 10, 15, 20, 25]
>>> list(range(0, 10, 3))
[0, 3, 6, 9]
>>> list(range(0, -10, -1))
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
>>> list(range(0))
[]
>>> list(range(1, 0))
[]
zip
-
zip(*iterables) 制作一个迭代器,聚合来自每个迭代器的元素。 -
返回元组的迭代器,其中第 i 个元组包含来自每个参数序列或可迭代对象的第 i 个元素。 当最短的输入迭代用完时,迭代器停止。 使用单个可迭代参数,它返回一个 1 元组的迭代器。 没有参数,它返回一个空的迭代器。
-
当您不关心较长iterables中的尾随、不匹配值时,只应将
zip()用于长度不等的输入。原文:zip() should only be used with unequal length inputs when you don’t care about trailing, unmatched values from the longer iterables. -
zip()和*运算符可用于解压缩列表:
>>> x = [1, 2, 3]
>>> y = [4, 5, 6]
>>> zipped = zip(x, y)
>>> list(zipped)
[(1, 4), (2, 5), (3, 6)]
>>> x2, y2 = zip(*zip(x, y))
>>> x == list(x2) and y == list(y2)
True
enumerate
enumerate(iterable, start=0)- 返回一个枚举对象。
iterable必须是一个序列、一个迭代器或其他一些支持迭代的对象。enumerate()返回的迭代器的 next() 方法返回一个元组,其中包含一个计数(从 start 开始,默认为 0)和通过迭代迭代获得的值。
>>>names = ["fyz", "yjk", "xhr", "zc"]
>>>for i, name in enumerate(names):
print(i, name)
0 fyz
1 yjk
2 xhr
3 zc
List列表
list是可变序列,通常用于存储同类项的集合(其中精确的相似度因应用程序而异)。
可以通过多种方式构造列表:
-
使用一对方括号表示空列表:
[] -
使用方括号,用逗号分隔项目:
[a],[a, b, c ] -
使用列表推导式:
[x for x in iterable] -
使用类型构造函数:
list()或list(iterable)
- 构造函数构建一个列表,其项目与可迭代的项目相同且顺序相同。
iterable可以是一个序列、一个支持迭代的容器或一个迭代器对象。 - 如果
iterable已经是一个列表,则创建并返回一个副本,类似于iterable[:]。 例如,list('abc')返回['a', 'b', 'c']并且list( (1, 2, 3) )返回[1, 2, 3]。 如果没有给出参数,构造函数会创建一个新的空列表[]
>>> list([1, 2, 3])
[1, 2, 3]
>>> names = ["fyz", "yjk", "xhr", "zc"]
>>> list([i.upper() for i in names])
['FYZ', 'YJK', 'XHR', 'ZC']
dict字典
-
映射类型Mapping Types — dict 映射对象将可散列值映射到任意对象。 映射是可变对象。 目前只有一种标准映射类型,即字典。
-
字典的键几乎是任意值。 不可散列的值,即包含列表、字典或其他可变类型(按值而不是按对象标识进行比较)的值不能用作键。 用于键的数字类型遵循数字比较的正常规则:如果两个数字比较相等(例如 1 和 1.0),那么它们可以互换使用以索引相同的字典条目。 (但是请注意,由于计算机将浮点数存储为近似值,因此将它们用作字典键通常是不明智的。)
-
可以通过将逗号分隔的
key:value对列表放在大括号内来创建字典,例如:{' jack': 4098, 'sjoerd': 4127}或{4098:'jack', 4127: 'sjoerd'},或通过dict构造函数。 -
返回一个从可选位置参数和一组可能为空的关键字参数初始化的新字典。
可以通过多种方式创建字典:
-
使用逗号分隔的键:大括号内的值对列表:
{'jack': 4098, 'sjoerd': 4127}或{4098: 'jack', 4127: 'sjoerd'} -
使用字典推导式:
{},{x: x ** 2 for x in range(10)} -
使用类型构造函数:
dict(),dict([('foo', 100), ('bar', 200)]),dict(foo=100, bar=200)
>>> {x: x ** 2 for x in range(10)}
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
>>> dict([('foo', 100), ('bar', 200)])
{'foo': 100, 'bar': 200}
- 字典的合并
>>> a = {"fyz":"dalao", "yjk":"wuqing"}
>>> b = {"xhr":"niubi", "zc":"laji"}
>>> {**a, **b}
{'fyz': 'dalao', 'yjk': 'wuqing', 'xhr': 'niubi', 'zc': 'laji'}
-
如果没有给出位置参数,则创建一个空字典。 如果给出了一个位置参数并且它是一个映射对象,则使用与映射对象相同的键值对创建一个字典。 否则,位置参数必须是可迭代对象。 可迭代对象中的每个项目本身必须是一个恰好有两个对象的可迭代对象。 每个项目的第一个对象成为新字典中的键,第二个对象成为相应的值。 如果某个键出现多次,则该键的最后一个值将成为新字典中的相应值。
-
如果给出了关键字参数,则关键字参数及其值将添加到从位置参数创建的字典中。 如果要添加的键已经存在,则来自关键字参数的值将替换来自位置参数的值。
下面的例子都返回一个等于{"one": 1, "two": 2, "three": 3}的字典:
>>> a = dict(one=1, two=2, three=3)
>>> b = {'one': 1, 'two': 2, 'three': 3}
>>> c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
>>> d = dict([('two', 2), ('one', 1), ('three', 3)])
>>> e = dict({'three': 3, 'one': 1, 'two': 2})
>>> f = dict({'one': 1, 'three': 3}, two=2)
>>> a == b == c == d == e == f
True
Set集合
-
Set Types-Set,frozenset
-
Set对象是不同的可哈希对象的无序集合。常见的用途包括成员测试、从序列中删除重复项以及计算数学运算,如交集、并集、差分和对称差分
-
与其他集合一样,
set支持x in set、len(set)和For x in set。集合是无序集合,不记录元素位置或插入顺序。因此,集合不支持索引、切片或其他类似序列的行为。 -
当前有两种内置的
set类型,set和frozenset。集合类型是可变的-可以使用add()和remove()等方法更改内容。因为它是可变的,所以它没有哈希值,不能用作字典键或另一个集合的元素。frozenset类型是不可变的和可散列的-它的内容在创建之后不能被更改;因此,它可以用作字典键或另一个集合的元素。 -
除了set构造函数之外,还可以通过在大括号中放置逗号分隔的元素列表(例如:
{'jack','sjoerd})来创建非空集(不是frozensets)。 -
返回一个新的set或frozenset对象,其元素取自iterable。集合的元素必须是可哈希的。要表示集合的集合,内部集合必须是frozenset对象。如果未指定iterable,则返回一个新的空集。
集合可以通过多种方式创建:
-
使用逗号分隔的大括号内元素列表:
{'jack', 'sjoerd'} -
使用集合理解:
{c for c in 'abracadabra' if c not in 'abc'} -
使用类型构造函数:
set(),set('foobar'),set(['a','b','foo'])
>>> {c for c in 'abracadabra' if c not in 'abc'}
{'d', 'r'}
>>> set('foobar')
{'b', 'r', 'f', 'o', 'a'}
>>> set(['a','b','foo'])
{'b', 'foo', 'a'}
使用类型构造函数:set(),set('foobar'),set(['a','b','foo'])
>>> {c for c in 'abracadabra' if c not in 'abc'}
{'d', 'r'}
>>> set('foobar')
{'b', 'r', 'f', 'o', 'a'}
>>> set(['a','b','foo'])
{'b', 'foo', 'a'}

