

流式计算基础
01_流式计算基础_第1天(Storm是什么、Storm核心组件、Storm编程模型)
课程介绍
课程名称:Storm是什么
课程目标:
通过该课程的学习能够了解离线计算与流式计算的区别、掌握Storm框架的基础知识、了解流式计算的一般架构图。
课程大纲:
1、 离线计算是什么?
2、 流式计算是什么?
3、 流式计算与离线计算的区别?
4、 Storm是什么?
5、 Storm与Hadoop的区别?
6、 Storm的应用场景及行业案例
7、 Storm的核心组件(重点掌握)
8、 Storm的编程模型(重点掌握)
9、 流式计算的一般架构图(重点掌握)
背景介绍
Storm背景介绍
课程内容
1、离线计算是什么?
离线计算:批量获取数据、批量传输数据、周期性批量计算数据、数据展示
代表技术:Sqoop批量导入数据、HDFS批量存储数据、MapReduce批量计算数据、Hive批量计算数据、***任务调度
1,hivesql
2、调度平台
3、Hadoop集群运维
4、数据清洗(脚本语言)
5、元数据管理
6、数据稽查
7、数据仓库模型架构
2、流式计算是什么
流式计算:数据实时产生、数据实时传输、数据实时计算、实时展示
代表技术:Flume实时获取数据、Kafka/metaq实时数据存储、Storm/JStorm实时数据计算、Redis实时结果缓存、持久化存储(mysql)。
一句话总结:将源源不断产生的数据实时收集并实时计算,尽可能快的得到计算结果
3、离线计算与实时计算的区别
最大的区别:实时收集、实时计算、实时展示
4、Storm是什么?
Flume实时采集,低延迟
Kafka消息队列,低延迟
Storm实时计算,低延迟
Redis实时存储,低延迟
Storm用来实时处理数据,特点:低延迟、高可用、分布式、可扩展、数据不丢失。提供简单容易理解的接口,便于开发。
海量数据?数据类型很多,产生数据的终端很多,处理数据能力增强
5、Storm与Hadoop的区别
l Storm用于实时计算,Hadoop用于离线计算。
l Storm处理的数据保存在内存中,源源不断;Hadoop处理的数据保存在文件系统中,一批一批。
l Storm的数据通过网络传输进来;Hadoop的数据保存在磁盘中。
l Storm与Hadoop的编程模型相似
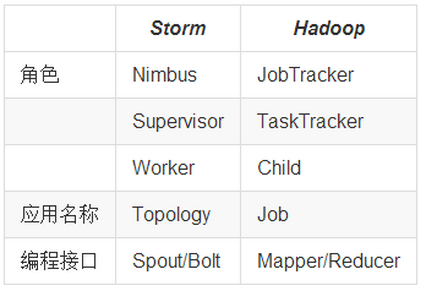
Job:任务名称
JobTracker:项目经理
TaskTracker:开发组长、产品经理
Child:负责开发的人员
Mapper/Reduce:开发人员中的两种角色,一种是服务器开发、一种是客户端开发
Topology:任务名称
Nimbus:项目经理
Supervisor:开组长、产品经理
Worker:开人员
Spout/Bolt:开人员中的两种角色,一种是服务器开发、一种是客户端开发
6、Storm应用场景及行业案例
Storm用来实时计算源源不断产生的数据,如同流水线生产。
6.1、运用场景
l 日志分析
从海量日志中分析出特定的数据,并将分析的结果存入外部存储器用来辅佐决策。
l 管道系统
将一个数据从一个系统传输到另外一个系统,比如将数据库同步到Hadoop
l 消息转化器
将接受到的消息按照某种格式进行转化,存储到另外一个系统如消息中间件
6.2、典型案列
l 一淘-实时分析系统:实时分析用户的属性,并反馈给搜索引擎
最初,用户属性分析是通过每天在云梯上定时运行的MR job来完成的。为了满足实时性的要求,希望能够实时分析用户的行为日志,将最新的用户属性反馈给搜索引擎,能够为用户展现最贴近其当前需求的结果。
l 携程-网站性能监控:实时分析系统监控携程网的网站性能
利用HTML5提供的performance标准获得可用的指标,并记录日志。Storm集群实时分析日志和入库。使用DRPC聚合成报表,通过历史数据对比等判断规则,触发预警事件。
l 阿里妈妈-用户画像:实时计算用户的兴趣数据
为了更加精准投放广告,阿里妈妈后台计算引擎需要维护每个用户的兴趣点(理想状态是,你对什么感兴趣,就向你投放哪类广告)。用户兴趣主要基于用户的历史行为、用户的实时查询、用户的实时点击、用户的地理信息而得,其中实时查询、实时点击等用户行为都是实时数据。考虑到系统的实时性,阿里妈妈使用Storm维护用户兴趣数据,并在此基础上进行受众定向的广告投放。
7、Storm核心组件(重要)
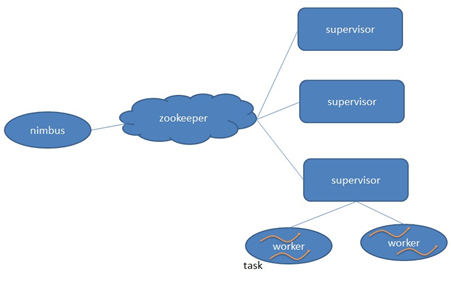
l Nimbus:负责资源分配和任务调度。
l Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。---通过配置文件设置当前supervisor上启动多少个worker。
l Worker:运行具体处理组件逻辑的进程。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
l Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。
8、Storm编程模型(重要)
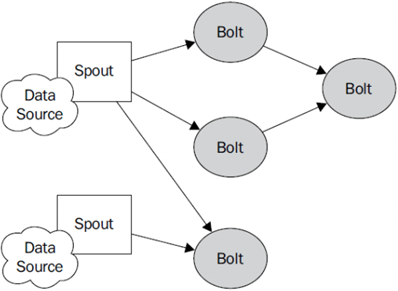
l Topology:Storm中运行的一个实时应用程序的名称。(拓扑)
l Spout:在一个topology中获取源数据流的组件。
通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。
l Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
l Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。
l Stream:表示数据的流向。
9、流式计算一般架构图(重要)

l 其中flume用来获取数据。
l Kafka用来临时保存数据。
l Strom用来计算数据。
l Redis是个内存数据库,用来保存数据。
02_流式计算基础_第1天(Storm集群部署、单词计数、Stream Grouping)
课程介绍
课程名称:Storm集群部署及单词技术
课程目标:
通过本课程能够掌握Strom集群搭建、Storm配置文件、Storm源码管理、Storm编程模型。
课程大纲:
1、 集群部署的基本流程
2、 集群部署的基础环境准备
3、 Storm集群部署
4、 Storm集群的常用操作命令
5、 Storm集群的进程及日志熟悉
6、 Storm源码下载及目录熟悉
7、 Storm 单词计数案列
课程内容
1、 集群部署的基本流程
集群部署的流程:下载安装包、解压安装包、修改配置文件、分发安装包、启动集群
注意:
所有的集群上都需要配置hosts
vi /etc/hosts
192.168.239.128 storm01 zk01 hadoop01
192.168.239.129 storm02 zk02 hadoop02
192.168.239.130 storm03 zk03 hadoop03
2、 集群部署的基础环境准备
安装前的准备工作(zk集群已经部署完毕)
l 关闭防火墙
chkconfig iptables off && setenforce 0
l 创建用户
groupadd realtime && useradd realtime && usermod -a -G realtime realtime
l 创建工作目录并赋权
mkdir /export
mkdir /export/servers
chmod 755 -R /export
l 切换到realtime用户下
su realtime
3、Storm集群部署
3.1、下载安装包
3.2、解压安装包
tar -zxvf apache-storm-0.9.5.tar.gz -C /export/servers/
cd /export/servers/
ln -s apache-storm-0.9.5 storm
3.3、修改配置文件
mv /export/servers/storm/conf/storm.yaml /export/servers/storm/conf/storm.yaml.bak
vi /export/servers/storm/conf/storm.yaml
输入以下内容:

3.4、分发安装包
scp -r /export/servers/apache-storm-0.9.5 storm02:/export/servers
然后分别在各机器上创建软连接
cd /export/servers/
ln -s apache-storm-0.9.5 storm
3.5、启动集群
l 在nimbus.host所属的机器上启动 nimbus服务
cd /export/servers/storm/bin/
nohup ./storm nimbus &
l 在nimbus.host所属的机器上启动ui服务
cd /export/servers/storm/bin/
nohup ./storm ui &
l 在其它个点击上启动supervisor服务
cd /export/servers/storm/bin/
nohup ./storm supervisor &
3.6、查看集群
访问nimbus.host:/8080,即可看到storm的ui界面。
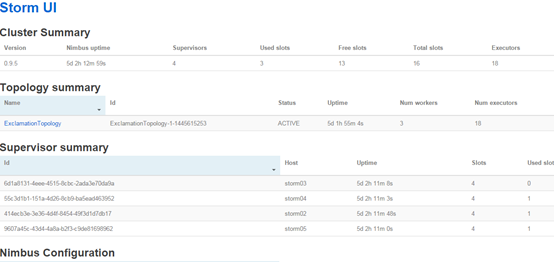
4、Storm常用操作命令
有许多简单且有用的命令可以用来管理拓扑,它们可以提交、杀死、禁用、再平衡拓扑。
l 提交任务命令格式:storm jar 【jar路径】 【拓扑包名.拓扑类名】 【拓扑名称】
bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.6.jar storm.starter.WordCountTopology wordcount
l 杀死任务命令格式:storm kill 【拓扑名称】 -w 10(执行kill命令时可以通过-w [等待秒数]指定拓扑停用以后的等待时间)
storm kill topology-name -w 10
l 停用任务命令格式:storm deactivte 【拓扑名称】
storm deactivte topology-name
我们能够挂起或停用运行中的拓扑。当停用拓扑时,所有已分发的元组都会得到处理,但是spouts的nextTuple方法不会被调用。销毁一个拓扑,可以使用kill命令。它会以一种安全的方式销毁一个拓扑,首先停用拓扑,在等待拓扑消息的时间段内允许拓扑完成当前的数据流。
l 启用任务命令格式:storm activate【拓扑名称】
storm activate topology-name
l 重新部署任务命令格式:storm rebalance 【拓扑名称】
storm rebalance topology-name
再平衡使你重分配集群任务。这是个很强大的命令。比如,你向一个运行中的集群增加了节点。再平衡命令将会停用拓扑,然后在相应超时时间之后重分配工人,并重启拓扑。
5、Storm集群的进程及日志熟悉
5.1、部署成功之后,启动storm集群。
依次启动集群的各种角色
5.2、查看nimbus的日志信息
在nimbus的服务器上
cd /export/servers/storm/logs
tail -100f /export/servers/storm/logs/nimbus.log
5.3、查看ui运行日志信息
在ui的服务器上,一般和nimbus一个服务器
cd /export/servers/storm/logs
tail -100f /export/servers/storm/logs/ui.log
5.4、查看supervisor运行日志信息
在supervisor服务上
cd /export/servers/storm/logs
tail -100f /export/servers/storm/logs/supervisor.log
5.5、查看supervisor上worker运行日志信息
在supervisor服务上
cd /export/servers/storm/logs
tail -100f /export/servers/storm/logs/worker-6702.log

(该worker正在运行wordcount程序)
6、Storm源码下载及目录熟悉
6.1、在Storm官方网站上寻找源码地址
http://storm.apache.org/downloads.html
6.2、点击文字标签进入github
点击Apache/storm文字标签,进入github
https://github.com/apache/storm
6.3、拷贝storm源码地址
在网页右侧,拷贝storm源码地址

6.4、使用Subversion客户端下载
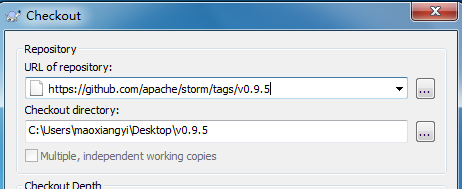
https://github.com/apache/storm/tags/v0.9.5
6.5、Storm源码目录分析(重要)

扩展包中的三个项目,使storm能与hbase、hdfs、kafka交互

7、Storm单词技术案例(重点掌握)
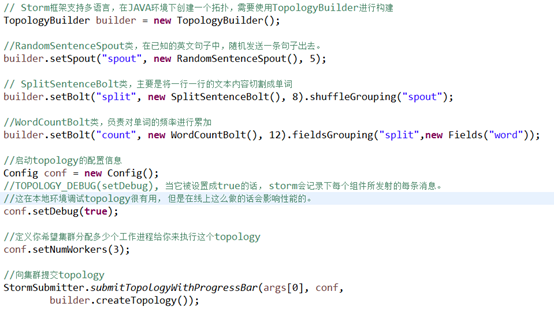
7.1、功能说明
设计一个topology,来实现对文档里面的单词出现的频率进行统计。
整个topology分为三个部分:
l RandomSentenceSpout:数据源,在已知的英文句子中,随机发送一条句子出去。
l SplitSentenceBolt:负责将单行文本记录(句子)切分成单词
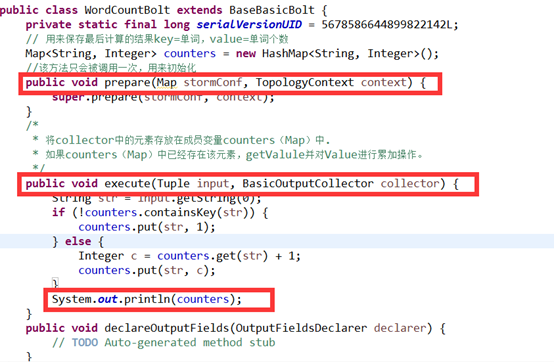
l WordCountBolt:负责对单词的频率进行累加
7.2、项目主要流程
7.3、RandomSentenceSpout的实现及生命周期

7.4、SplitSentenceBolt的实现及生命周期

7.5、WordCountBolt的实现及生命周期
7.6、Stream Grouping详解
Storm里面有7种类型的stream grouping
l Shuffle Grouping: 随机分组, 随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。
l Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。
l All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
l Global Grouping:全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
l Non Grouping:不分组,这stream grouping个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
l Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。
l Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
03_流式计算基础_第1天(Kafka集群安装部署、Kafka生产者、Kafka消费者)
课程介绍
课程名称:Storm上游数据源之Kakfa
课程目标:
通过本课程理解Storm消费的数据来源、理解JMS规范、理解Kafka核心组件、掌握Kakfa生产者API、掌握Kafka消费者API。对流式计算的生态环境有深入的了解,具备流式计算项目架构的能力。
课程大纲:
1、 kafka是什么?
2、 JMS规范是什么?
3、 为什么需要消息队列?
4、 Kafka核心组件
5、 Kafka安装部署
6、 Kafka生产者Java API
7、 Kafka消费者Java API
课程内容
1、Kafka是什么
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
KAFKA + STORM +REDIS
l Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
l Kafka最初是由LinkedIn开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
l Kafka是一个分布式消息队列:生产者、消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。
l Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。
l 无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性
2、JMS是什么
2.1、JMS的基础
JMS是什么:JMS是Java提供的一套技术规范
JMS干什么用:用来异构系统 集成通信,缓解系统瓶颈,提高系统的伸缩性增强系统用户体验,使得系统模块化和组件化变得可行并更加灵活
通过什么方式:生产消费者模式(生产者、服务器、消费者)
jdk,kafka,activemq……
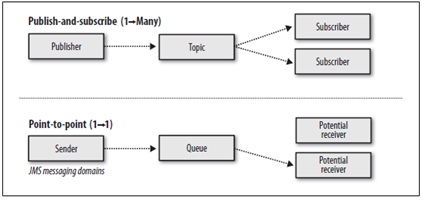
2.2、JMS消息传输模型
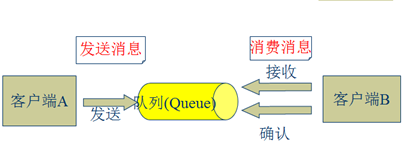
l 点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。
l 发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即时当前订阅者不可用,处于离线状态。
queue.put(object) 数据生产
queue.take(object) 数据消费
2.3、JMS核心组件
l Destination:消息发送的目的地,也就是前面说的Queue和Topic。
l Message [m1] :从字面上就可以看出是被发送的消息。
l Producer: 消息的生产者,要发送一个消息,必须通过这个生产者来发送。
l MessageConsumer: 与生产者相对应,这是消息的消费者或接收者,通过它来接收一个消息。
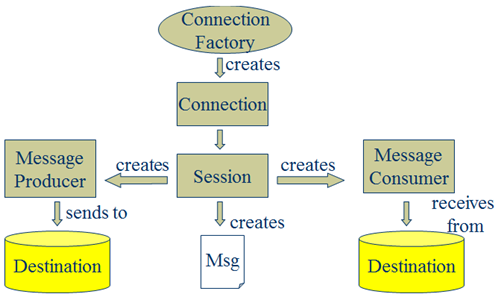
通过与ConnectionFactory可以获得一个connection
通过connection可以获得一个session会话。
2.4、常见的类JMS消息服务器
2.4.1、JMS消息服务器 ActiveMQ
ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线。ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的。
主要特点:
l 多种语言和协议编写客户端。语言: Java, C, C++, C#, Ruby, Perl, Python, PHP。应用协议: OpenWire,Stomp REST,WS Notification,XMPP,AMQP
l 完全支持JMS1.1和J2EE 1.4规范 (持久化,XA消息,事务)
l 对Spring的支持,ActiveMQ可以很容易内嵌到使用Spring的系统里面去,而且也支持Spring2.0的特性
l 通过了常见J2EE服务器(如 Geronimo,JBoss 4, GlassFish,WebLogic)的测试,其中通过JCA 1.5 resource adaptors的配置,可以让ActiveMQ可以自动的部署到任何兼容J2EE 1.4 商业服务器上
l 支持多种传送协议:in-VM,TCP,SSL,NIO,UDP,JGroups,JXTA
l 支持通过JDBC和journal提供高速的消息持久化
l 从设计上保证了高性能的集群,客户端-服务器,点对点
l 支持Ajax
l 支持与Axis的整合
l 可以很容易得调用内嵌JMS provider,进行测试
2.4.2、分布式消息中间件 Metamorphosis
Metamorphosis (MetaQ) 是一个高性能、高可用、可扩展的分布式消息中间件,类似于LinkedIn的Kafka,具有消息存储顺序写、吞吐量大和支持本地和XA事务等特性,适用于大吞吐量、顺序消息、广播和日志数据传输等场景,在淘宝和支付宝有着广泛的应用,现已开源。
主要特点:
l 生产者、服务器和消费者都可分布
l 消息存储顺序写
l 性能极高,吞吐量大
l 支持消息顺序
l 支持本地和XA事务
l 客户端pull,随机读,利用sendfile系统调用,zero-copy ,批量拉数据
l 支持消费端事务
l 支持消息广播模式
l 支持异步发送消息
l 支持http协议
l 支持消息重试和recover
l 数据迁移、扩容对用户透明
l 消费状态保存在客户端
l 支持同步和异步复制两种HA
l 支持group commit
2.4.3、分布式消息中间件 RocketMQ
RocketMQ 是一款分布式、队列模型的消息中间件,具有以下特点:
l 能够保证严格的消息顺序
l 提供丰富的消息拉取模式
l 高效的订阅者水平扩展能力
l 实时的消息订阅机制
l 亿级消息堆积能力
l Metaq3.0 版本改名,产品名称改为RocketMQ
2.4.4、其他MQ
l .NET消息中间件 DotNetMQ
l 基于HBase的消息队列 HQueue
l Go 的 MQ 框架 KiteQ
l AMQP消息服务器 RabbitMQ
l MemcacheQ 是一个基于 MemcacheDB 的消息队列服务器。
3、为什么需要消息队列(重要)
消息系统的核心作用就是三点:解耦,异步和并行
以用户注册的案列来说明消息系统的作用
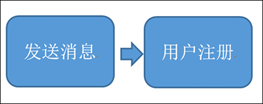
3.1、用户注册的一般流程
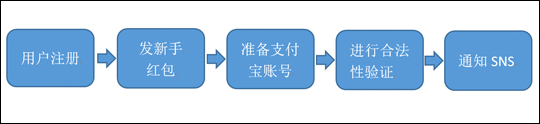
问题:随着后端流程越来越多,每步流程都需要额外的耗费很多时间,从而会导致用户更长的等待延迟。
3.2、用户注册的并行执行
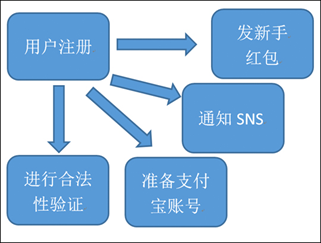
问题:系统并行的发起了4个请求,4个请求中,如果某一个环节执行1分钟,其他环节再快,用户也需要等待1分钟。如果其中一个环节异常之后,整个服务挂掉了。
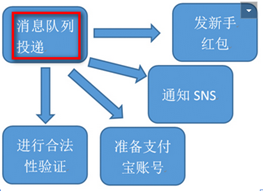
3.3、用户注册的最终一致
1、 保证主流程的正常执行、执行成功之后,发送MQ消息出去。
2、 需要这个destination的其他系统通过消费数据再执行,最终一致。
4、Kafka核心组件
l Topic :消息根据Topic进行归类
l Producer:发送消息者
l Consumer:消息接受者
l broker:每个kafka实例(server)
l Zookeeper:依赖集群保存meta信息。
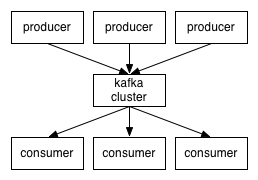
5、Kafka集群部署
5.1集群部署的基本流程
下载安装包、解压安装包、修改配置文件、分发安装包、启动集群
5.2集群部署的基础环境准备
安装前的准备工作(zk集群已经部署完毕)
l 关闭防火墙
chkconfig iptables off && setenforce 0
l 创建用户
groupadd realtime && useradd realtime && usermod -a -G realtime realtime
l 创建工作目录并赋权
mkdir /export
mkdir /export/servers
chmod 755 -R /export
l 切换到realtime用户下
su realtime
5.3 Kafka集群部署
5.3.1、下载安装包
http://kafka.apache.org/downloads.html
在linux中使用wget命令下载安装包
wget http://mirrors.hust.edu.cn/apache/kafka/0.8.2.2/kafka_2.11-0.8.2.2.tgz
5.3.2、解压安装包
tar -zxvf /export/software/kafka_2.11-0.8.2.2.tgz -C /export/servers/
cd /export/servers/
ln -s kafka_2.11-0.8.2.2 kafka
5.3.3、修改配置文件
cp /export/servers/kafka/config/server.properties
/export/servers/kafka/config/server.properties.bak
vi /export/servers/kafka/config/server.properties
输入以下内容:

5.3.4、分发安装包
scp -r /export/servers/kafka_2.11-0.8.2.2 kafka02:/export/servers
然后分别在各机器上创建软连
cd /export/servers/
ln -s kafka_2.11-0.8.2.2 kafka
5.3.5、再次修改配置文件(重要)
依次修改各服务器上配置文件的的broker.id,分别是0,1,2不得重复。
5.3.6、启动集群
依次在各节点上启动kafka
bin/kafka-server-start.sh config/server.properties
5.4、Kafka常用操作命令
l 查看当前服务器中的所有topic
bin/kafka-topics.sh --list --zookeeper zk01:2181
l 创建topic
./kafka-topics.sh --create --zookeeper mini1:2181 --replication-factor 1 --partitions 3 --topic first
l 删除topic
sh bin/kafka-topics.sh --delete --zookeeper zk01:2181 --topic test
需要server.properties中设置delete.topic.enable=true否则只是标记删除或者直接重启。
l 通过shell命令发送消息
kafka-console-producer.sh --broker-list kafka01:9092 --topic itheima
l 通过shell消费消息
sh bin/kafka-console-consumer.sh --zookeeper zk01:2181 --from-beginning --topic test1
l 查看消费位置
sh kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeper zk01:2181 --group testGroup
l 查看某个Topic的详情
sh kafka-topics.sh --topic test --describe --zookeeper zk01:2181
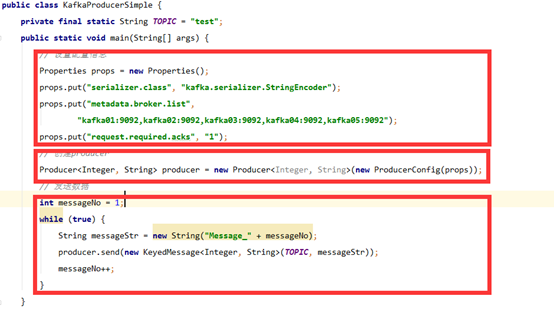
6、Kafka生产者Java API
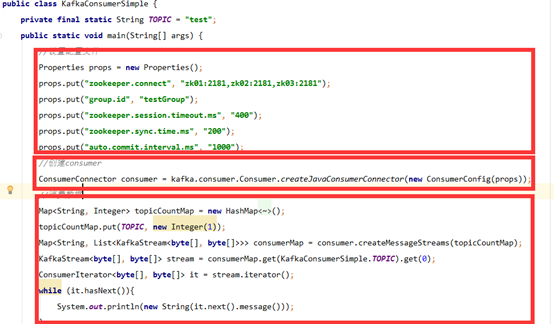
7、Kafka消费者Java API
StreamMessage:Java 数据流消息,用标准流操作来顺序的填充和读取。
MapMessage:一个Map类型的消息;名称为 string 类型,而值为 Java 的基本类型。
TextMessage:普通字符串消息,包含一个String。
ObjectMessage:对象消息,包含一个可序列化的Java 对象
BytesMessage:二进制数组消息,包含一个byte[]。
XMLMessage: 一个XML类型的消息。
最常用的是TextMessage和ObjectMessage。
04_流式计算基础_第1天(流式计算案列-实时业务数据计算)
课程介绍
课程名称:
Storm实时交易金额计算
课程目标:
通过本模块的学习,能够掌握流式计算的基本开发流程,将Kafka+Storm+Redis三门技术集成运用;掌握如何根据业务需求开发一个Storm程序。
课程大纲:
1、 业务背景介绍
2、 业务需求分析
3、 架构设计
4、 功能分析之数据准备
5、 功能分析之数据计算
6、 功能分析之数据展示
7、 工程设计
8、 代码开发
9、 结果展示
课程内容
1、业务背景
根据订单mq,快速计算双11当天的订单量、销售金额。


2、架构设计及思路
支付系统+kafka+storm/Jstorm集群+redis集群
1、支付系统发送mq到kafka集群中,编写storm程序消费kafka的数据并计算实时的订单数量、订单数量
2、将计算的实时结果保存在redis中
3、外部程序访问redis进群中的数据实时展示结果
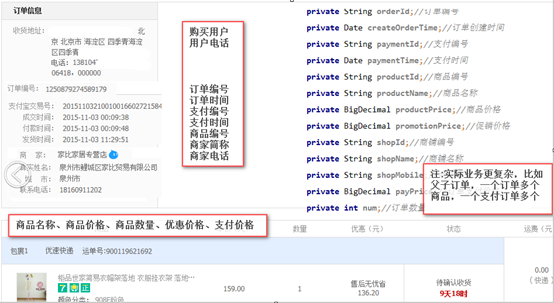
3、数据准备

订单编号、订单时间、支付编号、支付时间、商品编号、商家名称、商品价格、优惠价格、支付金额
4、业务口径
l 订单总数:一条支付信息当一条订单处理,假设订单信息不会重发(实际情况要考虑订单去重的情况,父子订单等多种情况),计算接收到MQ的总条数,即当做订单数。
l 销售额:累加所有的订单中商品的价格
l 支付金额:累加所有订单中商品的支付价格
l 用户人数:一条支付信息当一个人处理,假设订单一个人只下一单(实际情况要考虑用户去重的情况)。
整体淘宝的业务指标,每个品类,每个产品线,每个淘宝店
5、数据展示
读取redis中的数据,每秒进行展示,打印在控制台。
6、工程设计
l 数据产生:编写kafka数据生产者,模拟订单系统发送mq
l 数据输入:使用PaymentSpout消费kafka中的数据
l 数据计算:使用CountBolt对数据进行统计
l 数据存储:使用Sava2RedisBolt对数据进行存储,将结果数据存储到redis中
l 数据展示:编写java app客户端,访问redis,对数据进行展示,展示方式为打印在控制台。
1、获取外部数据源,MQSpout----Open(连接你的RMQ)---nextTuple()-----emit(json)
2、ParserPaymentInfoBolt()----execute(Tuple)------解析Json----JavaBean
productId,orderId,time,price(原价,订单价,优惠价,支付价),user,收货地址
total:原价、total:订单价、total:订单人数……
3、Save2ReidsBolt,保存相关业务指标
问题: 在redis中存放整个网站销售的原价, b:t:p:20160410 ---> value
redis: String----> value1+value2 + value3 + value4 incrBy
b:t:p:20160410
b:t:p:20161111
b:t:p:20160412
7、代码开发
05_流式计算基础_第2天(Storm目录树、任务提交、消息容错)
课程介绍
课程名称:
Storm技术增强
注:学习本课程,请先学习Storm基础
课程目标:
通过本模块的学习,能够掌握Storm底层的通信机制、消息容错机制、storm目录树及任务提交流程。
课程大纲:
1、 Storm程序的并发机制
2、 Storm框架通信机制(worker内部通信与外部通信)
3、 Storm组件本地目录树
4、 Storm zookeeper目录树
5、 Storm 任务提交的过程
课程内容
1、Storm程序的并发机制
1.1、概念
l Workers (JVMs): 在一个物理节点上可以运行一个或多个独立的JVM 进程。一个Topology可以包含一个或多个worker(并行的跑在不同的物理机上), 所以worker process就是执行一个topology的子集, 并且worker只能对应于一个topology
l Executors (threads): 在一个worker JVM进程中运行着多个Java线程。一个executor线程可以执行一个或多个tasks。但一般默认每个executor只执行一个task。一个worker可以包含一个或多个executor, 每个component (spout或bolt)至少对应于一个executor, 所以可以说executor执行一个compenent的子集, 同时一个executor只能对应于一个component。
l Tasks(bolt/spout instances):Task就是具体的处理逻辑对象,每一个Spout和Bolt会被当作很多task在整个集群里面执行。每一个task对应到一个线程,而stream grouping则是定义怎么从一堆task发射tuple到另外一堆task。你可以调用TopologyBuilder.setSpout和TopBuilder.setBolt来设置并行度 — 也就是有多少个task。
1.2、配置并行度
l 对于并发度的配置, 在storm里面可以在多个地方进行配置, 优先级为:
defaults.yaml < storm.yaml < topology-specific configuration
< internal component-specific configuration < external component-specific configuration
l worker processes的数目, 可以通过配置文件和代码中配置, worker就是执行进程, 所以考虑并发的效果, 数目至少应该大亍machines的数目
l executor的数目, component的并发线程数,只能在代码中配置(通过setBolt和setSpout的参数), 例如, setBolt("green-bolt", new GreenBolt(), 2)
l tasks的数目, 可以不配置, 默认和executor1:1, 也可以通过setNumTasks()配置
Topology的worker数通过config设置,即执行该topology的worker(java)进程数。它可以通过 storm rebalance 命令任意调整。
|
Config conf = newConfig(); conf.setNumWorkers(2); //用2个worker topologyBuilder.setSpout("blue-spout", newBlueSpout(), 2); //设置2个并发度 topologyBuilder.setBolt("green-bolt", newGreenBolt(), 2).setNumTasks(4).shuffleGrouping("blue-spout"); //设置2个并发度,4个任务 topologyBuilder.setBolt("yellow-bolt", newYellowBolt(), 6).shuffleGrouping("green-bolt"); //设置6个并发度 StormSubmitter.submitTopology("mytopology", conf, topologyBuilder.createTopology()); |

3个组件的并发度加起来是10,就是说拓扑一共有10个executor,一共有2个worker,每个worker产生10 / 2 = 5条线程。
绿色的bolt配置成2个executor和4个task。为此每个executor为这个bolt运行2个task。
l 动态的改变并行度
Storm支持在不 restart topology 的情况下, 动态的改变(增减) worker processes 的数目和 executors 的数目, 称为rebalancing. 通过Storm web UI,或者通过storm rebalance命令实现:
|
storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10 |
2、Storm通信机制
Worker间的通信经常需要通过网络跨节点进行,Storm使用ZeroMQ或Netty(0.9以后默认使用)作为进程间通信的消息框架。
Worker进程内部通信:不同worker的thread通信使用LMAX Disruptor来完成。
不同topologey之间的通信,Storm不负责,需要自己想办法实现,例如使用kafka等;
2.1、Worker进程间通信
worker进程间消息传递机制,消息的接收和处理的大概流程见下图
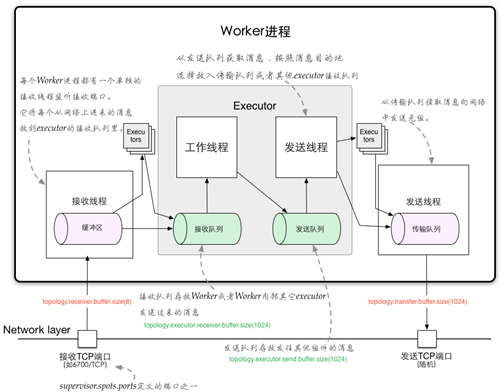
ü 对于worker进程来说,为了管理流入和传出的消息,每个worker进程有一个独立的接收线程[m1] (对配置的TCP端口supervisor.slots.ports进行监听);
对应Worker接收线程,每个worker存在一个独立的发送线程[m2] ,它负责从worker的transfer-queue[m3] 中读取消息,并通过网络发送给其他worker
ü 每个executor有自己的incoming-queue[m4] 和outgoing-queue[m5] 。
Worker接收线程将收到的消息通过task编号传递给对应的executor(一个或多个)的incoming-queues;
每个executor有单独的线程分别来处理spout/bolt的业务逻辑,业务逻辑输出的中间数据会存放在outgoing-queue中,当executor的outgoing-queue中的tuple达到一定的阀值,executor的发送线程将批量获取outgoing-queue中的tuple,并发送到transfer-queue中。
ü 每个worker进程控制一个或多个executor线程,用户可在代码中进行配置。其实就是我们在代码中设置的并发度个数。
2.2、Worker进程间通信分析
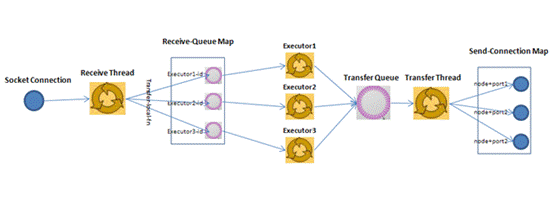
1、 Worker接受线程通过网络接受数据,并根据Tuple中包含的taskId,匹配到对应的executor;然后根据executor找到对应的incoming-queue,将数据存发送到incoming-queue队列中。
2、 业务逻辑执行现成消费incoming-queue的数据,通过调用Bolt的execute(xxxx)方法,将Tuple作为参数传输给用户自定义的方法
3、 业务逻辑执行完毕之后,将计算的中间数据发送给outgoing-queue队列,当outgoing-queue中的tuple达到一定的阀值,executor的发送线程将批量获取outgoing-queue中的tuple,并发送到Worker的transfer-queue中
4、 Worker发送线程消费transfer-queue中数据,计算Tuple的目的地,连接不同的node+port将数据通过网络传输的方式传送给另一个的Worker。
5、 另一个worker执行以上步骤1的操作。
2.3、Worker进程间技术(Netty、ZeroMQ)
2.3.1、Netty
Netty是一个NIO client-server(客户端服务器)框架,使用Netty可以快速开发网络应用,例如服务器和客户端协议。Netty提供了一种新的方式来使开发网络应用程序,这种新的方式使得它很容易使用和有很强的扩展性。Netty的内部实现时很复杂的,但是Netty提供了简单易用的api从网络处理代码中解耦业务逻辑。Netty是完全基于NIO实现的,所以整个Netty都是异步的。
书籍:Netty权威指南
2.3.2、ZeroMQ
ZeroMQ是一种基于消息队列的多线程网络库,其对套接字类型、连接处理、帧、甚至路由的底层细节进行抽象,提供跨越多种传输协议的套接字。ZeroMQ是网络通信中新的一层,介于应用层和传输层之间(按照TCP/IP划分),其是一个可伸缩层,可并行运行,分散在分布式系统间。
ZeroMQ定位为:一个简单好用的传输层,像框架一样的一个socket library,他使得Socket编程更加简单、简洁和性能更高。是一个消息处理队列库,可在多个线程、内核和主机盒之间弹性伸缩。ZMQ的明确目标是“成为标准网络协议栈的一部分,之后进入Linux内核”。
2.4、Worker 内部通信技术(Disruptor)
2.4.1、Disruptor的来历
ü 一个公司的业务与技术的关系,一般可以分为三个阶段。第一个阶段就是跟着业务跑。第二个阶段是经历了几年的时间,才达到的驱动业务阶段。第三个阶段,技术引领业务的发展乃至企业的发展。所以我们在学习Disruptor这个技术时,不得不提LMAX这个机构,因为Disruptor这门技术就是由LMAX公司开发并开源的。
ü LMAX是在英国注册并受到FSA监管(监管号码为509778)的外汇黄金交易所。LMAX也是欧洲第一家也是唯一一家采用多边交易设施Multilateral Trading Facility(MTF)拥有交易所牌照和经纪商牌照的欧洲顶级金融公司
ü LAMX拥有最迅捷的交易平台,顶级技术支持。LMAX交易所使用“(MTF)分裂器Disruptor”技术,可以在极短时间内(一般在3百万秒之一内)处理订单,在一个线程里每秒处理6百万订单。所有订单均为撮合成交形式,无一例外。多边交易设施(MTF)曾经用来设计伦敦证券交易 所(london Stock Exchange)、德国证券及衍生工具交易所(Deutsche Borse)和欧洲证券交易所(Euronext)。
ü 2011年LMAX凭借该技术获得了金融行业技术评选大赛的最佳交易系统奖和甲骨文“公爵杯”创新编程框架奖。
2.4.2、Disruptor是什么
1、 简单理解:Disruptor是一个Queue。Disruptor是实现了“队列”的功能,而且是一个有界队列。而队列的应用场景自然就是“生产者-消费者”模型。
2、 在JDK中Queue有很多实现类,包括不限于ArrayBlockingQueue、LinkBlockingQueue,这两个底层的数据结构分别是数组和链表。数组查询快,链表增删快,能够适应大多数应用场景。
3、 但是ArrayBlockingQueue、LinkBlockingQueue都是线程安全的。涉及到线程安全,就会有synchronized、lock等关键字,这就意味着CPU会打架。
4、 Disruptor一种线程之间信息无锁的交换方式(使用CAS(Compare And Swap/Set)操作)。
2.4.2、Disruptor主要特点
1、 没有竞争=没有锁=非常快。
2、 所有访问者都记录自己的序号的实现方式,允许多个生产者与多个消费者共享相同的数据结构。
3、 在每个对象中都能跟踪序列号(ring buffer,claim Strategy,生产者和消费者),加上神奇的cache line padding,就意味着没有为伪共享和非预期的竞争。
2.4.2、Disruptor 核心技术点
Disruptor可以看成一个事件监听或消息机制,在队列中一边生产者放入消息,另外一边消费者并行取出处理.
底层是单个数据结构:一个ring buffer。
每个生产者和消费者都有一个次序计算器,以显示当前缓冲工作方式。
每个生产者消费者能够操作自己的次序计数器的能够读取对方的计数器,生产者能够读取消费者的计算器确保其在没有锁的情况下是可写的。
核心组件
ü Ring Buffer 环形的缓冲区,负责对通过 Disruptor 进行交换的数据(事件)进行存储和更新。
ü Sequence 通过顺序递增的序号来编号管理通过其进行交换的数据(事件),对数据(事件)的处理过程总是沿着序号逐个递增处理。
ü RingBuffer底层是个数组,次序计算器是一个64bit long 整数型,平滑增长。
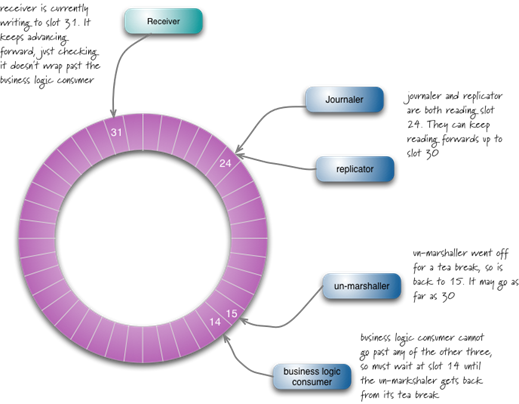
1、 接受数据并写入到脚标31的位置,之后会沿着序号一直写入,但是不会绕过消费者所在的脚标。
2、 Joumaler和replicator同时读到24的位置,他们可以批量读取数据到30
3、消费逻辑线程读到了14的位置,但是没法继续读下去,因为他的sequence暂停在15的位置上,需要等到他的sequence给他序号。如果sequence能正常工作,就能读取到30的数据。
3、Storm组件本地目录树

4、Storm zookeeper目录树

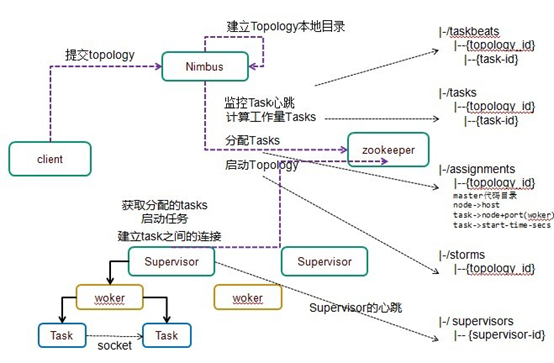
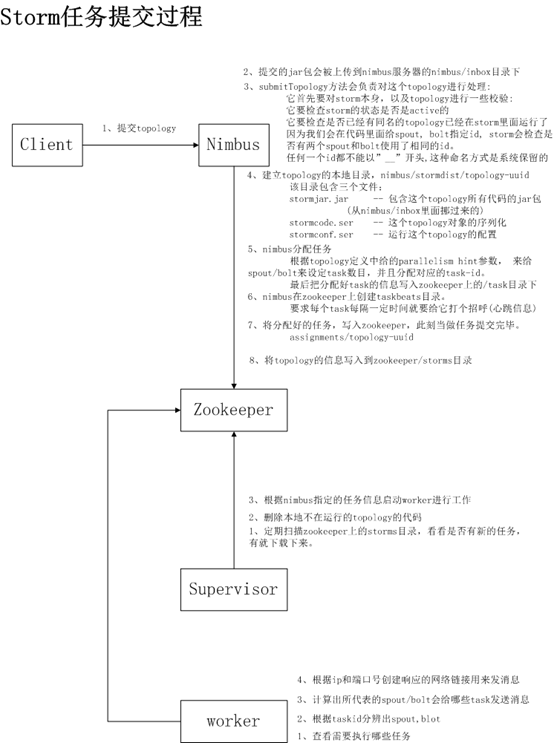
5、Storm 任务提交的过程
|
TopologyMetricsRunnable.TaskStartEvent[oldAssignment=<null>,newAssignment=Assignment[masterCodeDir=C:\Users\MAOXIA~1\AppData\Local\Temp\\e73862a8-f7e7-41f3-883d-af494618bc9f\nimbus\stormdist\double11-1-1458909887,nodeHost={61ce10a7-1e78-4c47-9fb3-c21f43a331ba=192.168.1.106},taskStartTimeSecs={1=1458909910, 2=1458909910, 3=1458909910, 4=1458909910, 5=1458909910, 6=1458909910, 7=1458909910, 8=1458909910},workers=[ResourceWorkerSlot[hostname=192.168.1.106,memSize=0,cpu=0,tasks=[1, 2, 3, 4, 5, 6, 7, 8],jvm=<null>,nodeId=61ce10a7-1e78-4c47-9fb3-c21f43a331ba,port=6900]],timeStamp=1458909910633,type=Assign],task2Component=<null>,clusterName=<null>,topologyId=double11-1-1458909887,timestamp=0] |
6、Storm 消息容错机制
6.1、总体介绍
l 在storm中,可靠的信息处理机制是从spout开始的。
l 一个提供了可靠的处理机制的spout需要记录他发射出去的tuple,当下游bolt处理tuple或者子tuple失败时spout能够重新发射。
l Storm通过调用Spout的nextTuple()发送一个tuple。为实现可靠的消息处理,首先要给每个发出的tuple带上唯一的ID,并且将ID作为参数传递给SoputOutputCollector的emit()方法:collector.emit(new Values("value1","value2"), msgId); messageid就是用来标示唯一的tupke的,而rootid是随机生成的
给每个tuple指定ID告诉Storm系统,无论处理成功还是失败,spout都要接收tuple树上所有节点返回的通知。如果处理成功,spout的ack()方法将会对编号是msgId的消息应答确认;如果处理失败或者超时,会调用fail()方法。
6.2、基本实现
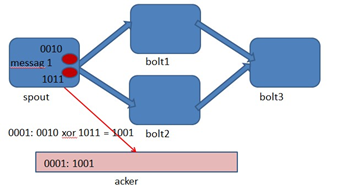
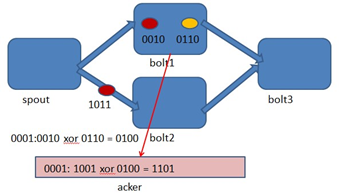
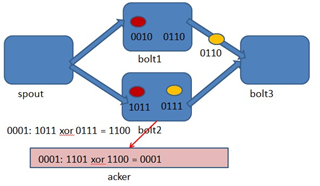
Storm 系统中有一组叫做"acker"的特殊的任务,它们负责跟踪DAG(有向无环图)中的每个消息。
acker任务保存了spout id到一对值的映射。第一个值就是spout的任务id,通过这个id,acker就知道消息处理完成时该通知哪个spout任务。第二个值是一个64bit的数字,我们称之为"ack val", 它是树中所有消息的随机id的异或计算结果。
ack val表示了整棵树的的状态,无论这棵树多大,只需要这个固定大小的数字就可以跟踪整棵树。当消息被创建和被应答的时候都会有相同的消息id发送过来做异或。 每当acker发现一棵树的ack val值为0的时候,它就知道这棵树已经被完全处理了

6.3、可靠性配置
有三种方法可以去掉消息的可靠性:
将参数Config.TOPOLOGY_ACKERS设置为0,通过此方法,当Spout发送一个消息的时候,它的ack方法将立刻被调用;
Spout发送一个消息时,不指定此消息的messageID。当需要关闭特定消息可靠性的时候,可以使用此方法;
最后,如果你不在意某个消息派生出来的子孙消息的可靠性,则此消息派生出来的子消息在发送时不要做锚定,即在emit方法中不指定输入消息。因为这些子孙消息没有被锚定在任何tuple tree中,因此他们的失败不会引起任何spout重新发送消息。
一个worker进程运行一个专用的接收线程来负责将外部发送过来的消息移动到对应的executor线程的incoming-queue中
transfer-queue的大小由参数topology.transfer.buffer.size来设置。transfer-queue的每个元素实际上代表一个tuple的集合
transfer-queue的大小由参数topology.transfer.buffer.size来设置。
executor的incoming-queue的大小用户可以自定义配置。
executor的outgoing-queue的大小用户可以自定义配置
06_流式计算基础_第2天(Kafka负载均衡、Kafka自定义Partition、Kafk文件存储机制)
课程介绍
课程名称:
Kafka技术增强
注:学习本课程请先学习Kafka基础
课程目标:
通过本模块的学习,能够掌握Kafka的负载均衡、Producer生产数据、Kafka文件存储机制、Kafka自定义partition
课程大纲:
1、 Kafka整体结构图
2、 Consumer与topic关系
3、 Kafka Producer消息分发
4、 Consumer 的负载均衡
5、 Kafka文件存储机制
课程内容
1、Kafka整体结构图
Kafka名词解释和工作方式
l Producer :消息生产者,就是向kafka broker发消息的客户端。
l Consumer :消息消费者,向kafka broker取消息的客户端
l Topic :咋们可以理解为一个队列。
l Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
l Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
l Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
l Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka
2、Consumer与topic关系
本质上kafka只支持Topic;
l 每个group中可以有多个consumer,每个consumer属于一个consumer group;
通常情况下,一个group中会包含多个consumer,这样不仅可以提高topic中消息的并发消费能力,而且还能提高"故障容错"性,如果group中的某个consumer失效那么其消费的partitions将会有其他consumer自动接管。
l 对于Topic中的一条特定的消息,只会被订阅此Topic的每个group中的其中一个consumer消费,此消息不会发送给一个group的多个consumer;
那么一个group中所有的consumer将会交错的消费整个Topic,每个group中consumer消息消费互相独立,我们可以认为一个group是一个"订阅"者。
l 在kafka中,一个partition中的消息只会被group中的一个consumer消费(同一时刻);
一个Topic中的每个partions,只会被一个"订阅者"中的一个consumer消费,不过一个consumer可以同时消费多个partitions中的消息。
l kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息。
kafka只能保证一个partition中的消息被某个consumer消费时是顺序的;事实上,从Topic角度来说,当有多个partitions时,消息仍不是全局有序的。
3、Kafka消息的分发
Producer客户端负责消息的分发
l kafka集群中的任何一个broker都可以向producer提供metadata信息,这些metadata中包含"集群中存活的servers列表"/"partitions leader列表"等信息;
l 当producer获取到metadata信息之后, producer将会和Topic下所有partition leader保持socket连接;
l 消息由producer直接通过socket发送到broker,中间不会经过任何"路由层",事实上,消息被路由到哪个partition上由producer客户端决定;
比如可以采用"random""key-hash""轮询"等,如果一个topic中有多个partitions,那么在producer端实现"消息均衡分发"是必要的。
l 在producer端的配置文件中,开发者可以指定partition路由的方式。
Producer消息发送的应答机制
设置发送数据是否需要服务端的反馈,有三个值0,1,-1
0: producer不会等待broker发送ack
1: 当leader接收到消息之后发送ack
-1: 当所有的follower都同步消息成功后发送ack
request.required.acks=0
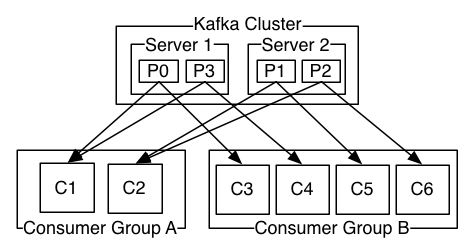
4、Consumer的负载均衡
当一个group中,有consumer加入或者离开时,会触发partitions均衡.均衡的最终目的,是提升topic的并发消费能力,步骤如下:
1、 假如topic1,具有如下partitions: P0,P1,P2,P3
2、 加入group中,有如下consumer: C1,C2
3、 首先根据partition索引号对partitions排序: P0,P1,P2,P3
4、 根据consumer.id排序: C0,C1
5、 计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
6、 然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)]
5、kafka文件存储机制
5.1、Kafka文件存储基本结构
l 在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序序号,第一个partiton序号从0开始,序号最大值为partitions数量减1。
l 每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。默认保留7天的数据。

l 每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。(什么时候创建,什么时候删除)

数据有序的讨论?
一个partition的数据是否是有序的? 间隔性有序,不连续
针对一个topic里面的数据,只能做到partition内部有序,不能做到全局有序。
特别加入消费者的场景后,如何保证消费者消费的数据全局有序的?伪命题。
只有一种情况下才能保证全局有序?就是只有一个partition。
5.2、Kafka Partition Segment
l Segment file组成:由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后缀".index"和“.log”分别表示为segment索引文件、数据文件。

l Segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
l 索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。

3,497:当前log文件中的第几条信息,存放在磁盘上的那个地方
上述图中索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。
其中以索引文件中元数据3,497为例,依次在数据文件中表示第3个message(在全局partiton表示第368772个message)、以及该消息的物理偏移地址为497。
l segment data file由许多message组成, qq物理结构如下:
|
关键字 |
解释说明 |
|
8 byte offset |
在parition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),它可以唯一确定每条消息在parition(分区)内的位置。即offset表示partiion的第多少message |
|
4 byte message size |
message大小 |
|
4 byte CRC32 |
用crc32校验message |
|
1 byte “magic" |
表示本次发布Kafka服务程序协议版本号 |
|
1 byte “attributes" |
表示为独立版本、或标识压缩类型、或编码类型。 |
|
4 byte key length |
表示key的长度,当key为-1时,K byte key字段不填 |
|
K byte key |
可选 |
|
value bytes payload |
表示实际消息数据。 |
5.3、Kafka 查找message
读取offset=368776的message,需要通过下面2个步骤查找。

5.3.1、查找segment file
00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0
00000000000000368769.index的消息量起始偏移量为368770 = 368769 + 1
00000000000000737337.index的起始偏移量为737338=737337 + 1
其他后续文件依次类推。
以起始偏移量命名并排序这些文件,只要根据offset **二分查找**文件列表,就可以快速定位到具体文件。当offset=368776时定位到00000000000000368769.index和对应log文件。
5.3.2、通过segment file查找message
当offset=368776时,依次定位到00000000000000368769.index的元数据物理位置和00000000000000368769.log的物理偏移地址
然后再通过00000000000000368769.log顺序查找直到offset=368776为止。
6、Kafka自定义Partition
见代码
07_流式计算基础_第2天(Redis基础、应用场景、数据结构及案例)
课程介绍
课程名称:
Kafka技术增强
注:学习本课程请先学习Kafka基础
课程目标:
通过本模块的学习,能够掌握Storm底层的通信机制、消息容错机制、storm目录树及任务提交流程。
课程大纲:
课程内容
1、Redis概述
l Redis是一个开源,先进的key-value存储,并用于构建高性能,可扩展的应用程序的完美解决方案。
l Redis从它的许多竞争继承来的三个主要特点:
l Redis数据库完全在内存中,使用磁盘仅用于持久性。
l 相比许多键值数据存储,Redis拥有一套较为丰富的数据类型。String,List,set,map,sortSet
l Redis可以将数据复制到任意数量的从服务器。
2、Redis 优势
l 异常快速:Redis的速度非常快,每秒能执行约11万集合,每秒约81000+条记录。
l 支持丰富的数据类型:Redis支持字符串、列表、集合、有序集合散列数据类型,这使得它非常容易解决各种各样的问题。
l 操作都是原子性:所有Redis操作是原子的,这保证了如果两个客户端同时访问的Redis服务器将获得更新后的值。----计数器
l 多功能实用工具:Redis是一个多实用的工具,可以在多个用例如缓存,消息,队列使用(Redis原生支持发布/订阅),任何短暂的数据,应用程序,如Web应用程序会话,网页命中计数等。
3、Redis安装部署
3.1、Redis下载、编译、安装
l 下载redis3.0.5
wget http://download.redis.io/releases/redis-3.0.5.tar.gz
l 解压文件,并创建软件连接
tar -zxvf redis-3.0.5.tar.gz -C /export/servers/
ln –s redis-3.0.5/ redis
l 编译redis源码
cd /export/servers/redis
make(先安装gcc)
l 将编译后的可执行文件安装到/user/local/redis
make PREFIX=/usr/local/redis install
3.2、启动Redis
l 启动方式一:Redis前台默认启动
进入redis安装目录,并启动Redis服务
cd /usr/local/redis/bin/
./redis-server
l 启动方式二:Redis使用配置文件启动
拷贝源码中的redis.conf文件到redis的安装目录
cp /export/servers/redis/redis.conf /usr/local/redis/
修改redis.conf的属性
daemonize no è daemonize yes
启动redis服务
cd /usr/local/redis
bin/redis-server ./redis.conf
3.3、日志文件及持久化文件配置
l 修改生成默认日志文件位置
logfile "/usr/local/redis/logs/redis.log"
l 配置持久化文件存放位置
dir /usr/local/redis/data/redisData
3.4、Redis客户端使用
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.8.0</version>
</dependency>

4、Redis持久化
有两种持久化方案:RDB和AOF
1) RDB方式按照一定的时间间隔对数据集创建基于时间点的快照。
2)AOF方式记录Server收到的写操作到日志文件,在Server重启时通过回放这些写操作来重建数据集。该方式类似于MySQL中基于语句格式的binlog。当日志变大时Redis可在后台重写日志。
l AOF持久化配置
1)修改redis.config配置文件,找到appendonly。默认是appendonly no。改成appendonly yes
2)再找到appendfsync 。默认是 appendfsync everysec
appendfsync always
#每次收到写命令就立即强制写入磁盘,最慢的,但是保证完全的持久化,不推荐使用
appendfsync everysec
#每秒钟强制写入磁盘一次,在性能和持久化方面做了很好的折中,推荐
appendfsync no
#完全依赖os,性能最好,持久化没保证
l RDB持久化配置
默认情况下,Redis保存数据集快照到磁盘,名为dump.rdb的二进制文件。可以设置让Redis在N秒内至少有M次数据集改动时保存数据集,或者你也可以手动调用SAVE或者BGSAVE命令。
例如,这个配置会让Redis在每个60秒内至少有1000次键改动时自动转储数据集到磁盘
save 60 1000
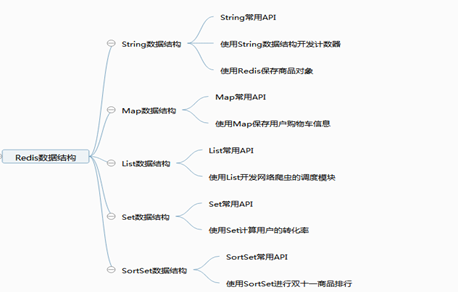
5、Redis数据结构
见代码
