

mysql数据库优化
1.数据库自身的优化
a. 如何选择mysql的存储引擎:
innodb:事务要求高,保存的数据都是重要数据,如订单表,账号表.;
myisam:事务要求不高,查询和添加为主的,如bbs中的发帖表,回复表,但是不支持外键( 一定要定时进行碎片整理,因为数据删了文件大小没有变:optimize table 表名;);
Memory:数据变化频繁,不需要入库,同时又频繁的查询和修改,速度极快;
b.数据和日志文件分开存放在不同磁盘上
数据文件和日志文件的操作会产生大量的I/O。在可能的条件下,日志文件应该存放在一个与数据和索引所在的数据文件不同的硬盘上以分散I/O,同时还有利于数据库的灾难恢复。
c.数据库参数配置,比如缓存大小,最大连接数等
d.读写分离或者分布式数据库
2.数据库表的优化
a. 表的设计遵循3范式
首先符合1NF, 才能满足2NF , 进一步满足3NF。
1NF: 即表的列的具有原子性,不可再分解,即列的信息,不能分解, 只有数据库是关系型数据库(mysql/oracle/db2/informix/sysbase/sql server),就自动的满足1NF;
2NF: 表中的记录是唯一的, 就满足2NF, 通常我们设计一个主键来实现;
3NF: 即表中不要有冗余数据, 就是说,表的信息,如果能够被推导出来,就不应该单独的设计一个字段来存放
反3NF : 但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。
b. 添加适当索引(index) [四种: 普通索引、主键索引、唯一索引unique、全文索引(文件、文本检索,只对MyISAM有效)]
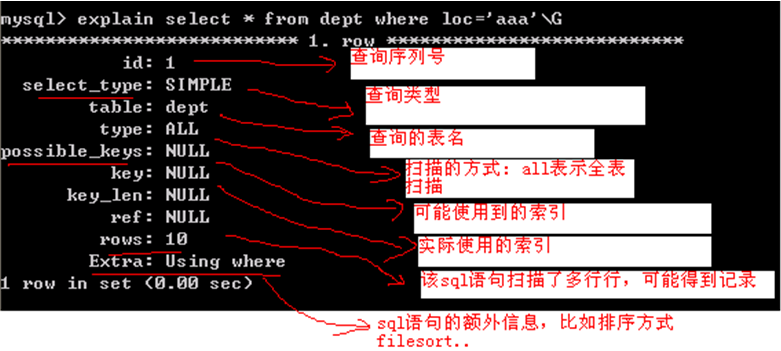
查看是否索引方式:show create table aaa;/desc aaa;/show index from aaa;/show keys from aaa;/explain select * from emp where empno = 345678\G
添加主键索引:alter table 表名 add primary key (列名);不能为NULL,也不能重复.
添加唯一索引:create unique index 索引名 on 表名 (列表..);可以为NULL,并可以有多NULL
添加普通索引:create index 索引名 on 表 (列1,列名2);
添加全文索引:alter table 表名 add fulltext index fulltext_article(title,body);
使用全文索引:select * from 表名 where match(title,body) against(‘搜索词’);
注意事项:在mysql中fulltext索引只针对 myisam生效;
mysql自己提供的fulltext针对英文生效->sphinx (coreseek) 技术处理中文;
使用方法是 match(字段名..) against(‘关键字’)
全文索引一个 叫 停止词, 因为在一个文本中,创建索引是一个无穷大的数,因此,对一些常用词和字符,就不会创建,这些词,称为停止词.
索引的代价(查询一般远多于增删改,可忽略):
a.占用磁盘空间;b.对增删改操作有影响会变慢(增删改后需要维护BTREE二叉树算法的索引文件);
满足创建索引的条件:
a.where条经常使用; b.该字段的内容不是唯一的几个值(sex); c.字段内容不是频繁变化.
查看索引使用的情况:
show status like 'Handler_read%';
handler_read_key:这个值越高越好,越高表示使用索引查询到的次数。
handler_read_rnd_next:这个值越高,说明查询低效。
c.分库分表分区
开源数据库中间件MyCat:部署环境只要把数据库连接改成mycat连接即可。
记住几个关键词:逻辑库schema(可以看成mycat),逻辑表table(由分片表和非非分片表组成),分片节点dataNode(表分片后所在的数据库),
节点主机dataHost(分片节点(dataNode)所在的机器),分片规则rule(按主键范围分片rang-long,一致性哈希murmur等)
3.sql语句的优化
查看mysql运营状态:
show [session|global] status命令了解各种SQL的执行频率: session表示当前会话(当前连接),global表示全局的(指数据库上次启动至今),默认是session
show status like 'Com_%'; //获取Com开头的转台,如Com_select:执行SELECT操作的次数;
show status like "Connections" : 表示试图连接MySQL服务器的次数;
show status like "Uptime":表示服务器工作时间;
show status like "Slow_queries":慢查询的次数;
修改mysql的慢查询:
show variables like ‘long_query_time’ ; //可以显示当前慢查询时间
set long_query_time=1 ;//可以修改慢查询时间
定位慢查询:
在默认情况下,我们的mysql不会记录慢查询,开启慢查询方式如下,可以在data目录下查询**-slow.log:
a.show variables like '%slow%';set global slow_query_log=1;
b.先关闭mysql,再启动,启动mysql使用命令:bin\mysqld.exe --safe-mode --slow-query-log [mysql5.5 可以在my.ini指定]
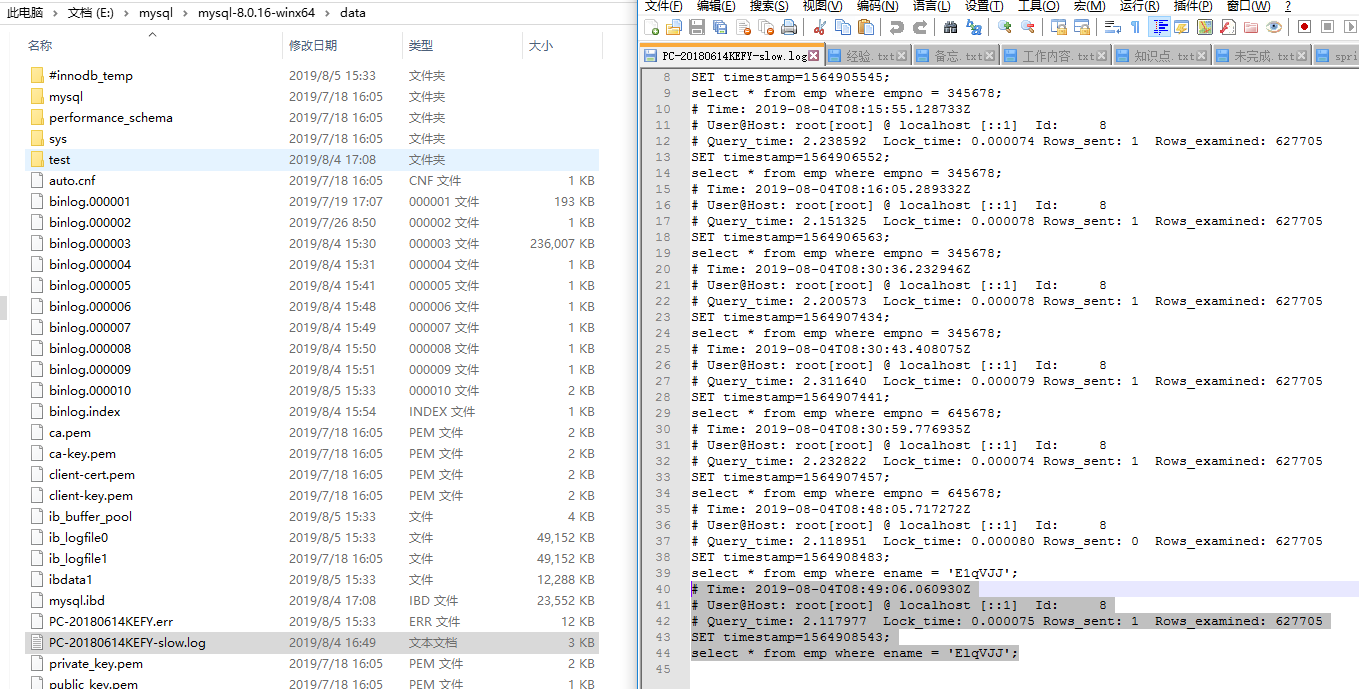
sql优化小技巧:
a.多列索引注意“最左前缀”原则;
b.like使用%开头不会使用到索引;
c.select中对索引字段使用了表达式/函数会放弃使用索引;
d.如果条件中有or,要求使用的所有字段,都必须建立索引,建议避免使用or 关键字;
e.Not IN 不走索引的是绝对不能用的,可以用NOT EXISTS 代替;
f. IS NULL 、IS NOT NULL、<>不会用到索引的;
g.Not IN 不走索引的是绝对不能用的,可以用NOT EXISTS 代替;
h.列类型是字符串一定要在条件中将数据使用引号引用起来;
i.在group by 后面增加 order by null 就可以防止排序;
j.使用top/limit等限制行提升查询性能;
k.使用索引、存储过程、视图、函数、触发器等封装业务,减少重新编译;
4.数据库备份
a.手动备份
mysqldump –u root –proot 数据库 [表名1 表名2..] > 文件路径,恢复数据source d:\temp.dept.bak
比如: 把temp数据库备份到 d:\temp.bak:mysqldump –u root –proot temp > d:\temp.bak
如果你希望备份是,数据库的某几张表:mysqldump –u root –prot temp dept > d:\temp.dept.bak
b.定时器备份
备份数据库的指令,写入到 bat文件, 然后通过任务管理器去定时调用 bat文件(linux下可以使用crontab命令)
c.增量备份
my.ini或者my.cof开启binlog日志,记录数据库表结构变更(例如CREATE、ALTER TABLE…)以及表数据修改(INSERT、UPDATE、DELETE…)的二进制日志,从而解析达到增量备份的目的;
查看binlog日志方式:在bin路径下命令查询:mysqlbinlog E:\mysql\mysql-8.0.16-winx64\data\binlog.000010;
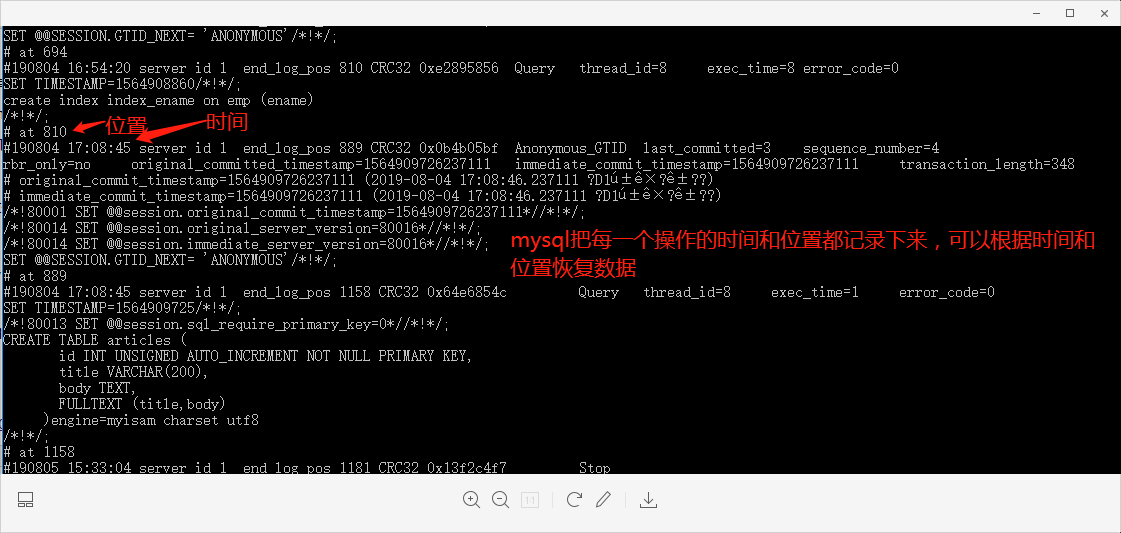
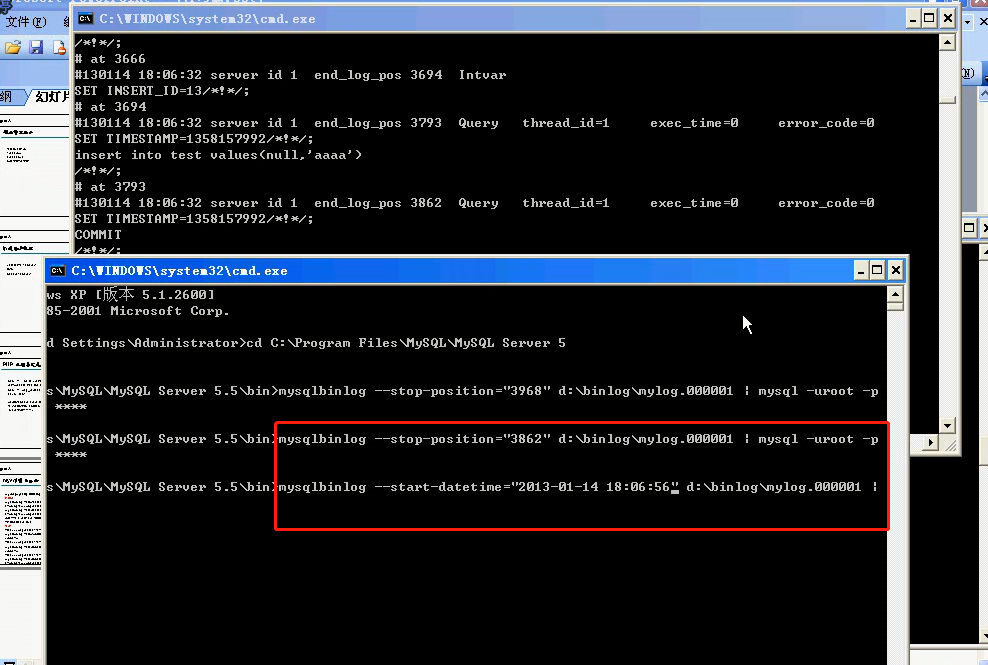
可以使用命令恢复到某个时间或者某个位置,也可以指定执行某个时间段的脚本:
如何在工作中将全备份和增量备份配合使用:
每周做一个全备份mysqldump,启动增量备份,把binlog日志过期时间设置大于等于7天,如果出现数据崩了,可以通过binlog日志查看并且恢复。
参考博客:https://www.cnblogs.com/AK2012/archive/2012/12/25/2012-1228.html
