
物理引擎Havok教程
物理引擎Havok教程(一)
搭建开发环境
网上关于Havok的教程实在不多,而且Havok学习起来还是有一定难度的,所以这里写了一个系列教程,希望能够帮到读者。这是第一期。
一、Havok物理引擎简介
Havok引擎,全称为Havok游戏动力开发工具包(Havok Game Dynamics SDK),一般称为Havok,是一个用于物理系统方面的游戏引擎,为电子游戏所设计,注重在游戏中对于真实世界的模拟。使用碰撞功能的Havok引擎可以让更多真实世界的情况以最大的拟真度反映在游戏中。
开发商Havok成立于1998年,目前Havok物理引擎被超过200款游戏使用,许多电影也应用了这家公司的软件技术。
2007年9月Havok被Intel收购,为了和NVIDIA的PhysX竞争,Intel在去年的(08年)免费开放了Havok的Physics和Animation组件,内容包括Havok SDK库、样例、技术文档以及支持Maya、3ds Max和Avid XSI等3D建模软件的格式转换工具。
按照Havok的授权文档,即使使用它开发商业游戏也是不需要付费的,这对国内的爱好者应该是一个好消息。
同PhysX相比,个人觉得,Havok无论在稳定性还是功能上,都要略胜一筹。NVIDIA的PhysX在硬件加速上,暂时领先,但随着AMD加入到Havok硬件加速的开发,未来Havok的功能肯定会更加的强大。
二、Havok开发环境的搭建
1.安装SDK
首先,到Havok的官网下载SDK,http://software.intel.com/sites/havok/,填写自己的姓名和邮箱,注册后即可下载。

Content Tools是内容工具,包括一些3D建模软件的导出工具。Behavior Tool是给游戏美工或设计师用的角色编辑工具,具有所见即所得的功能。对程序员来讲最重要的就是SDK了,我下载的是6.0.0这个版本。因为Intel只开放了物理和动画两个组件,所以下载的SDK是只包含这两个组件,其他的如布料(Cloth)和破坏(Destruction)还是需要付费才能使用。
Havok SDK使用的是C++语言,开发环境是Visual Studio,我用的版本是2005。
Demo目录下面是SDK的样例程序和源代码,Docs是文档,包括chm和pdf两种格式。Lib是链接库,库分为Debug和release及动态链接和静态链接。Source下面是SDK的包含文件。Tools下面是工具,包括了Visual Debugger这个可视化调试器。
2.设置Visual Studio
这里以我使用的Visual Studio 2005为例。
头文件包含目录的设置。打开Visual Studio 2005,依次选择工具-》选项-》项目与解决方案-》VC++目录
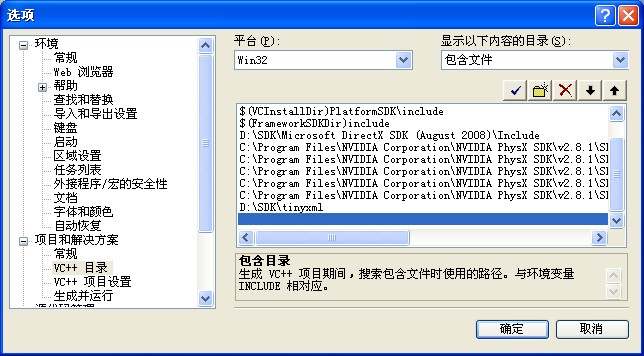
选择包含文件,添加新的一行,路径指向Havok SDK安装目录的Source目录。建议建立一个叫HAVOK_HOME的环境变量,这样可以避免使用绝对路径。
库目录不能在这里设置,而应该为debug和release版本设置不同的库包含目录。因为不论是debug还是release,它们的库名都是相同的。你可以打开Demo/Demos下面的工程,看看它是如何设置为不同版本设置链接包含目录的。
三、第一个Havok程序
这里以SDK自带的一个控制台演示程序为例,使用Visual Debugger来观察Havok的具体效果。首先运行Tools/VisualDebugger目录下的Visual Debugger程序,使用它我们可以观察到Havok实际运行的效果,而省去渲染步骤,而且可以把场景记录下来,供以后观看。演示程序在Demo/StandAloneDemos/ConsoleExampleMt目录下,这个程序模拟一个快速运动的刚体,撞击墙壁的效果。运行它,然后就可以在VisualDebugger中看到实际的效果了。

好了,第一期教程就是这样。下期会接触到具体的编码问题。如果你有任何问题,欢迎和我交流,我的邮箱songnianhu@163.com,博客blog.csdn.net/shangguanwaner,下期再见。
物理引擎Havok教程(二)
Havok基础库简介
Havok的SDK可以说比较复杂,并不是适合用来学习。拿它用来演示效果的Demo程序的框架来说,它的实现实在是非常的神秘,初学者一开始就接触海量的代码,估计会很大的挫伤积极性。所以为了降低大家学习的难度,我在做教程的时候会主要使用实际的代码来介绍SDK的各种特性,代码编写时我会尽量的简洁和通俗一点。示例代码我会整理好,提供链接,供大家下载。觉得好的话,大家要支持啊!
Havok SDK可以分为三大部分,Havok基础库、Havok物理组件、Havok动画组件。基础库,为Havok的其他组件提供了通用功能的支持,Havok物理组件负责实时的刚体模拟,Havok动画组件负责处理骨骼和角色动画,与物理组件配合,可以实现强大的角色动画控制功能。
关于Havok SDK的代码习惯,这里要说明一下,Havok SDK所有的类名基本上都以hk*开头,然后后面跟一个字符表示它所属的组件,例如,hkpWorld,说明它属于物理组件(Havok Physics),hkaBone,说明它属于动画组件(Havok Animation),hk后不跟一个表示组件的字符,则表明它是Havok基础库的一部份。
Havok基础库
Havok基础库定义了一些基本的数据类型和容器类,它还包括与平台无关的接口,用于访问操作系统的资源,比如内存管理、时钟等。基础库中的许多类都可以修改或者替换,这样通过提供的源代码,你可以灵活地扩展基础库的功能。不过有些部分,因为编译进了Havok库,所以不能被替换,包括那些有内联函数的容器类,还有config目录下面的构造配置选项(它保存了在编译Havok库时的配置,对它进行任何更改,都需要重新构建整个Havok库)。
使用基础库,只需要简单的包含hkBase.h即可。hkBase.h内,还定义了一些最基本的数据类型,比如浮点型(hkReal),有符号和无符号整形等等。
1. Havok基本系统
1.1 Havok的初始化
hkBaseSystem类负责创建所有Havok子系统。这些子系统中大部分都是单态类(singleton),各自都有特定的功能,比如内存管理、错误处理、流处理。
这些类的主要接口是init和quit方法。调用init方法来初始化Havok子系统。
static hkResult HK_CALL init( hkMemory* memoryManager,
hkThreadMemory* threadMemory,
hkErrorReportFunction errorReportFunction
void* errorReportObject = HK_NULL );
参数memoryManager,是一个将被Havok在内部使用的内存管理器的实现。这个参数允许你在初始化的过程中指定内存管理器而不必重新构建hkBase。Havok本身提供了许多默认的内存管理器的实现,如果没有特殊要求的话,就可以使用它们。当然,你也可以实现自己的一个内存管理器,Havok推荐使用hkPoolMemory类。这个内存管理器的实现以及其他的可用的实现可以在<hkbase/memory/impl>目录下面找到。
参数threadMemory,是当前线程的内存管理器,它可以用于优化内存分配和释放的性能。如果你传入了HK_NULL作为参数,默认的,hkBaseSystem::init()会为你创建一个hkThreadMemory实例。
errorReportFunction和errorReportObject参数被Havok的错误处理器使用,错误处理器主要负责处理断言、错误、警告,或者在引擎内部报告这些事件的发生。默认的错误处理器是<hkBase/hkerror/hkDefaultError.h>,它只是简单的调用errorReportFunction打印错误消息。
下面举一个使用hkPoolMemory初始化hkBaseSystem的代码示例:
#include <Common/Base/System/hkBaseSystem.h> // include for hkBaseSystem
#include <Common/Base/Memory/Memory/Pool/hkPoolMemory.h> // hkPoolMemory
extern "C" int printf(const char* fmt, ...); // For printf, used by the error handler
// Stub function to print any error report functionality to stdout
// std::puts(...) could be used here alternatively
static void errorReportFunction(const char* str, void* errorOutputObject)
{
printf("%s", str);
}
{
...
hkBaseSystem::init( new hkPoolMemory(), HK_NULL, errorReportFunction );
...
}
hkBaseSystem还有一个quit方法,它退出内存系统并销毁所有的hkSingleton实例。
1.2 Havok多线程模式的初始化
和PhysX不同,Havok现阶段采用的是CPU计算,所以Havok采用了多线程来提高性能。
Havok使用的每一个线程,都有它自己的hkThreadMemory内存管理器,必须在线程开始时初始化,线程结束时销毁。hkThreadMemory可以用于在销毁和重分配内存时缓存内存块。
下面的代码演示在主线程中的初始化。
hkMemory* memoryManager = new hkPoolMemory();
hkThreadMemory threadMemory(memoryManager, 16);
hkBaseSystem::init( memoryManager, &threadMemory, errorReportFunction );
memoryManager->removeReference();
1.2 管理Havok对象
Havok使用引用计数来管理对象。
hkBaseObject是所有Havok类的基类,只有虚函数。hkReferencedObject是hkBaseObject的子类,他是Havok对象管理的最基本单元,刚体(Rigid bodies)、约束(constraints)和动作(actions)都是hkReferencedObject。hkReferencedObject刚创建时,引用计数是1,每当它被引用一次时,引用计数加一,删除引用时,引用计数减一。当不使用hkReferencedObject时,调用removeReference()引用计数减一。
m_world->addEntity(rigidBody);
rigidBody->removeReference();
2. Havok容器类
Havok提供了两种容器类,Arrays和Maps。
hkArray是Havok默认的数组类。它和STL的数组类非常相似,但有一些关键的不同之处。首先它只支持那些简单的数据类型,如果你要建立一个对象的数组,那么你应该使用hkObjectArray,而不是hkArray。还有就是hkArray的方法的命名和STL也是不同的,例如STL中是push_back(),而在hkArray中就变成了pushBack()。而且,hkArray不保存元素的次序,例如当调用removeAt()删除了一个元素,为了提高性能,会用最后一个元素替换这个被删除的元素,而方法removeAtAndCopy()则可以提供和STL一样的实现,依然保存元素的次序。另外还有hkInplaceArray,它是hkArray的子类,在性能上要优于hkArray。关于数组类的其它方法你可以查看SDK文档,这里就不一一介绍了。
3. Havok数学库
Havok数学库提供了线性代数的一些相关的数据类型,如向量(vector)、矩阵(matrix)、4元数。hkMath的数据类型在不同的平台上实现是不同的,Havok针对不同的平台作出了相应的优化。
首先来看hkMath提供的基本数据类型,有
hkReal 默认的浮点类型,即float
hkQuadReal 这个类型使用了CPU的SIMD寄存器,占用4个hkReal的空间。
hkSimdReal 当SIMD启用时,一个单独的hkReal保存在SIMD寄存器内,x部分是一个hkQuadReal。
SIMD被禁用时,他就仅仅是个简单的hkReal类型。
其他的hkMath函数还有hkMath::sqrt(),hkMath::sin()等等,可以查看SDK文档。
SDK中称与线性代数相关的数据类型为混合类型(Compund Types)。它们有:
hkVector4 这个Havok内通用的向量类。它针对大多数平台进行了相应的优化,而且其他的数学类多数由它组成。每个hkVector4有四个hkReal元素,为了方便进行运算,一般只使用前三个元素x,y,z,后面的w部分,默认值是零。
hkQuaternion 四原数类,可以用来表示旋转。多数情况下,认为它是一个单位化的四元数。
hkMatrix3 hkReal组成的3X3的矩阵。
hkRotation 这个类保存正交的旋转矩阵。Havok中,有两种方法保存旋转:hkQuaternion和 hkRotation。如果你处理的旋转是hkVector4,旋转hkVector4的操作要比旋转hkQuaternion快。而在需要大量保存旋转的情况下,使用hkQuaternion效率要更高一些。
hkTransform 这个类表示一个旋转和平移(rotation,translation)。它分别由一个hkRotation和hkVector4组成。
hkQsTransform 一个分解的Transform(平移向量+四原数+缩放向量)。Havok的动画系统会经常使用它。
数学库,就简单的介绍到这里,它们的使用以及需要注意的地方,我在讲分析具体代码的时候会说。
4. 串行化(Serialization)
所谓串行化就是通过一定的处理将数据转换为一种可写的格式。串行化之后,原始数据还应该能够被精确的还原。就是说串行化之后的数据可以安全的保存到磁盘或通过网络传输。在游戏开发领域,串行化通常用于保存和装载资源。
Packfiles(这个不知如何翻译)
使用Havok的串行化工具,可以串行化任意的数据对象。一个对象被串行化了之后,它的所有信息和状态都会被精确地保存。在需要的时候,这个对象还可以被再次装载。
串行化后的数据都被保存在一个称作packfiles的结构中。它既可以保存为XML或者二进制的形式。使用Havok的导出插件,可以从Maya和3D Studio Max中将数据保存到packfiles,然后就可以在Havok的 SDK中转载了。
向游戏装载packfiles使用类hkXmlPackfileReader和hkBinaryPackfileReader。XML形式的packfile与平台无关,可以在任意平台上创建和装载。而二进制形式的packfiles则特定于对应的平台,所以它只能在指定的目标平台上装载。
Packfiles也可以从一种形式转换成另一种形式。使用hkXmlPackfileReader读取XML,再用hkBinaryPackfileWriter转换成二进制形式。反之,二进制形式的packfile,用hkBinaryPackfileReader读取数据,hkXmlPackfileWriter转换数据成XML形式。
4.1 装载游戏数据
装载游戏数据的功能,由命名空间hkSerializeUtil和hkLoader工具类提供。它们检测数据的格式是XML还是二进制形式。并且如果提供的数据是是另一个版本的SDK中建立的,它们还会在装载的时候将内容更新为最新的版本。
下面的代码演示了hkLoader工具类的用法:
hkResource* loadedData = hkSerializeUtil::load("filename.hkx");
hkRootLevelContainer* container = loadedData->getContent<hkRootLevelContainer>();
// 装载后的数据属于hkResource。必须确保在访问container的时候,hkResource没有被销毁
hkLoader loader;
hkRootLevelContainer* container = loader.load("filename.hkx");
// 装载后的数据属于hkLoader,同上,也必须确保在访问container的时候,hkLoader没有被销毁
packfile被装载之后,还需要做一些附加的处理。例如,需要设置多态对象的虚函数表,未串行化数据的缓存数据或指针也要被初始化。任何需要做最后处理的类都通过被hkTypeInfoRegistry注册,来完成最后处理。一旦数据装载完成,packfile读取器为每个需要做最后处理的的对象调用注册函数。
4.2 保存游戏数据
游戏中的含有元数据的对象,也可以被串行化并保存为packfile,使用的类是hkXmlPackfileWriter和hkBinaryPackfileWriter。如果碰到指针指向的对象不包含任何元数据这样的情况,操作会被跳过,并写入一个空指针。
hkOstream ostream(FILENAME);
kXmlPackfileWriter writer;
writer.setContents(&simpleobject, SimpleObjectClass);
kPackfileWriter::Options options; // use default options
writer.save(ostream.getStreamWriter(), options);
使用hkBinaryPackfileWriter可以为不同的平台导出不同二进制形式的packfile。要实现这样的操作,设置hkPackfileWriter::Options::m_layout为想要的平台即可。hkStructureLayout包含了若干支持的平台/编译环境。要读取的导出的数据,在目标平台上使用hkBinaryPackfileReader,用和上面一样的方法来读取数据。
hkOstream ostream(FILENAME);
hkBinaryPackfileWriter writer;
writer.setContents(&simpleobject, SimpleObjectClass);
hkPackfileWriter::Options options;
// 将数据导出为PlayStation®2 gcc3.2 格式
options.m_layout = hkStructureLayout::Gcc32Ps2LayoutRules;
writer.save(ostream.getStreamWriter(), options);
5. 快照工具集
Havok还提供了快照工具集(snapshot utility),它可以方便的保存world,很好地隐藏了底层的细节。
下面的代码演示如何保存world:
// Save the world into the file at "path"
static hkResult saveWorld( hkpWorld* world, const char* path, bool binary )
{
hkOstream outfile( path );
return hkpHavokSnapshot::save(world, outfile.getStreamWriter(), binary);
}
注意,在保存文件的过程中,如果碰到不明白的对象,会在控制台上打印警告消息。
装载快照,和保存差不多,代码如下:
// Loads snapshot at "path".
static hkpWorld* loadWorld( const char* path, hkPackfileReader::AllocatedData** allocsOut )
{
hkIstream infile( path );
hkpPhysicsData* physicsData = hkpHavokSnapshot::load(infile.getStreamReader(), allocsOut);
return physicsData->createWorld();
}
6. 多线程
Havok被专门设计成运行于多线程环境。这一小节将简单的介绍Havok的多线程的工作原理,以及如何在物理模拟时使用多线程。要实现Havok的多线程运行,需要两个类,hkJobQueue和hkJobThreadPool类。
hkJobQueue类。工作队列是所需完成job的核心容器。job是一项可以被任意线程处理的工作的单元。一个线程可以向队列添加job,也可以向队列请求job。
hkJobQueue::processAllJobs()可以被多个线程同时调用,然后每个线程都会开始处理job知道队列中没有任何job为止。hkJobThreadPool是一个抽象类,它允许多线程从工作队列处理job。典型的,在整个应用程序的生命周期内,只创建一个hkJobThreadPool的实例。这样就保证了始终有一组线程在运行。调用hkJobThreadPool::processAllJobs()方法,会导致它简单的在所有的工作线程上调用hkJobQueue::processAllJobs()方法。这个函数直到所有工作都完成之后才会返回。
Havok的物理、动画、碰撞查询、布料、Bihavior都支持在多线程环境下执行。理论上,向hkJobQueue添加job,调用processAllJobs(),可以并行的进行以上所有的计算。但仅仅是理论上而,其中还有许多同步的问题,导致完全并行是不可能的。
我们这里只介绍如何在多线程环境下运行Havok的物理模拟。其他组件与之类似。
6.1 物理模拟的多线程
Havok SDK随带了一个单独的示例,演示了如何进行物理模拟的多线程计算。代码在Demo/StandAloneDemos/ConsoleExampleMt目录下。
要启用多线程物理模拟,你在创建world的时候需要将hkpWorldCinfo::m_simulationType设置成hkpWorldCinfo::SIMULATION_TYPE_MULTITHREAD。代码演示如下:
...
// Create thread pool and job queue
hkJobThreadPool* threadPool = new hkCpuJobThreadPool( threadPoolCinfo );
hkJobQueue* jobQueue = new hkJobQueue();
// Create a physics world as usual.
//Make sure the simulation type in worldCinfo is SIMULATION_TYPE_MULTITHREADED
hkpWorld* physicsWorld = new hkpWorld(worldCinfo);
// Register physics job handling functions with job queue
physicsWorld->registerWithJobQueue( &jobQueue );
while( simulating )
{
// Step the world using this thread, and all the threads or SPUs in the thread pool
physicsWorld->stepMultiThreaded( &jobQueue, threadPool, timestep );
}
stepMultiThreaded()内部调用hkJobQueue::processAllJobs()和hkJobThreadPool::processAllJobs()完成实际的多线程运算。
好了,第二期教程到此结束,因为Havok SDK的基础库,比较大,所以我只是取了其中比较重要,经常用到的内容,拿出来讲。具体的可以查看SDK的文档。
物理引擎Havok教程(三)
物理组件初探
作者:上官婉儿
这一期将初步介绍Havok最重要的一个组件Physics组件。这个组件主要做刚体物理学的模拟。这一期讲一下它的工作原理和流程。
1.它是如何工作的?
在游戏中使用Havok,一般遵循这样的步骤,先创建好一个连续的模拟并准备好渲染系统,然后进行一次模拟,渲染器取得模拟的结果,在一秒内进行若干次的渲染。在Havok的SDK中,就称这样的一个时间片叫一帧。我们来看一下,Havok的工作流程。假设所有工作都已经初始化好了,Havok在每一帧的工作流程如下所示:
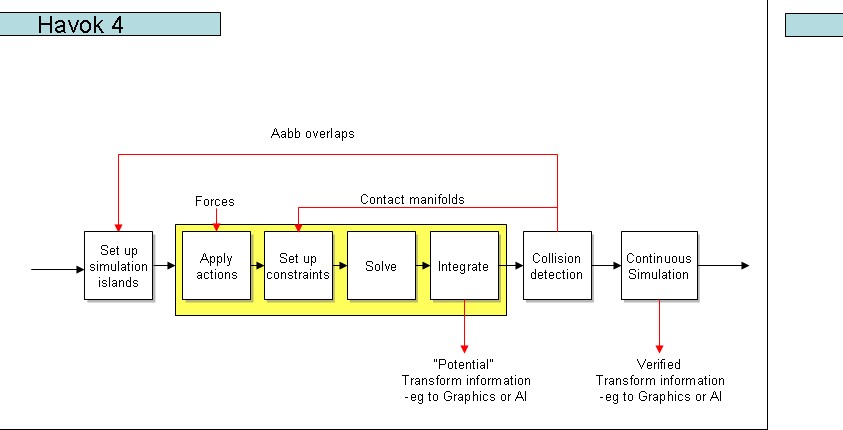
图片取自Havok的SDK文档。
下面分别介绍各个步骤。
1.1 建立模拟区域(Set up simulation islands)
Havok使用模拟区域来划分一组一组的物理对象。通过将所有整个物理世界的对象划分为各个小的区域来进行模拟,可以更好的利用系统的CPU和内存资源。而且,如果某个区域内的所有对象都已失效(deactivated),那么简单的失效整个区域即可,以后就不必再参与模拟。模拟区域是由系统自动设置的,用户不必自己建立。
模拟区域还管理Havok的失效系统(deactivation system),任何停止移动的对象,都符合失效的条件,一个失效的对象就不必再模拟了,这样可以节约CPU资源。每一个对象都有一个失效器(deactivator),通过查询自己的状态,它可以告诉系统,是否可以安全的使自己失效。
如果使用默认的失效类型,如果一个模拟区域内的所有对象都符合失效的条件,整个区域就会被失效。而一旦区域内的某个刚体重新有效,这个区域内的所有其他刚体也会被重新有效。
下面的步骤都是基于每一个模拟区域来说的。
1.2 施加作用(Applying actions)
通过施加作用,你可以在模拟的过程中控制物体的状态。每一个模拟步骤,系统都会调用你向物理世界中添加的每一个作用的applyAction()方法。使用Havok提供的接口,可以实现自定义的作用(actions)。
1.3 建立约束(Setup Constraints)
场景中的约束都是经过处理的。包括接触约束,它可以防止两个物体相互穿插。你也可以在物体之间指定特定的约束类型,比如,铰链或者球状关节(hinges,ball-and-socket joints)。当然你也可以创建自定义的约束。
1.4 Solve
在刚体世界里,物体是不应该相互穿插的,如果出现,就是一个错误。为了避免这样的错误,我们需要移动一下物体。而解决器(Solver)的职责就是计算避免这个错误所需要的移动量,并把这个信息传递给下一个步骤,整合。
1.5 整合(Integration)
整合器(integrator)计算新的运动状态(初始和终了的位置的旋转,速度,加速度等等),对每个模拟的对象,会考虑解决器提供的信息。然后对象新的位置和旋转就可以传递给游戏,更新游戏对象。
1.6 碰撞检测(Collision detection)
在Havok中,碰撞检测被分成了三个阶段。broadphase碰撞检测,它可以快速地得到一个近似的结果,它查找所以潜在的可能碰撞的一对对的物体。midphase碰撞检测,它从潜在的碰撞中提取更多的细节信息。最后是narrowphase碰撞检测,它确认这些成对的物体中到底哪些实际碰撞了。如果发现了碰撞,narrowphase就用这些信息,创建碰撞代理(collision agents)和碰撞接触点。这些碰撞代理和接触点,会提供给接下来的一个模拟帧使用。
每个物理对象都有hkpCollidable成员,它有一个hkpShape成员,定义用于碰撞检测的对象的形状。物体可以有各种形状,从简单的方体、球体到更复杂的混合形状以及网格。
说明,这里我讲SDK中的专用术语都翻译成了中文,翻译得不一定准确,所以每一个术语后面都有它的英文原词,方便你查看SDK文档。
有任何意见和建议,欢迎联系,我的邮箱songnianhu@163.com
这一期详细分析我在前面发布的那个Havok实例的代码。运行效果和代码下载请参看我之前的一篇文章《物理引擎Havok的一个简单实例(使用Ogre渲染)》。最新的代码可以在这里下载:http://code.google.com/p/ogrehavok/downloads/list
在例子中,我用了开源的Ogre作为渲染引擎。如果你想撇开图形渲染,只看Havok模拟的代码,可以参看Havok中自带的一个实例StandAloneDemos。
一、类HavokSystem
例子中类HavokSystem封装了Havok初始化和运行代码。它初始化基本库和多线程模拟,并创建物理世界。声明如下:
class HavokSystem
{
public:
HavokSystem(void);
~HavokSystem(void);
//创建hkpWorld
virtual bool createHavokWorld(hkReal worldsize);
//初始化VDB
virtual bool InitVDB();
//创建物理场景
virtual void createPhysicsScene();
void setGroundSize(hkReal x,hkReal y,hkReal z);
void setGroundPos(hkReal x,hkReal y,hkReal z);
//step simulation
virtual void simulate();
void setup();
//Physics
hkpWorld* m_World;
protected:
//成员变量
hkPoolMemory* m_MemoryManager;
hkThreadMemory* m_ThreadMemory;
char* m_StackBuffer;
int m_StackSize;
//多线程相关
hkJobThreadPool* m_ThreadPool;
int m_TotalNumThreadUsed;
hkJobQueue* m_JobQueue;
//VDB相关
hkArray<hkProcessContext*> m_Contexts;
hkpPhysicsContext* m_Context;
hkVisualDebugger* m_Vdb;
hkpRigidBody* m_Ground; //地面,即静态刚体
hkVector4 m_GroundSize; //地面尺寸
hkVector4 m_GroundPos; //地面位置
// 省去无关细节
...
};
1.初始化多线程
HavokSystem类的构造函数实现了多线程模拟的初始化,来看具体代码:
首先,要初始化Havok的基本库。初始化内存管理器,然后调用hkBaseSystem的init方法。注意,init调用后,m_MemoryManager被hkBaseSystem拥有,所以要记住将它的引用计数减一。
m_MemoryManager = new hkPoolMemory();
m_ThreadMemory = new hkThreadMemory(m_MemoryManager);
hkBaseSystem::init(m_MemoryManager,m_ThreadMemory,errorReport);
m_MemoryManager->removeReference();
接着初始化堆栈。
m_StackSize = 0x100000;
m_StackBuffer = hkAllocate<char>(m_StackSize,HK_MEMORY_CLASS_BASE);
hkThreadMemory::getInstance().setStackArea(m_StackBuffer,m_StackSize);
最后,真正的初始化多线程。通过hkHardwareInfo,可以获取与系统运行和硬件相关的信息,比如线程数,核心数等。这里只是用它获取在多线程模拟中使用的线程的数目。Havok在创建对象时,一般都使用*Cinfo的形式指定创建的参数,例如创建hkpWorld,就先填充参数到hkpWorldCinfo,然后用new hkpWorld(hkpWorldCinfo&)创建hkpWorld对象,其它与此类似。
int m_TotalNumThreadsUsed;
hkHardwareInfo hwInfo;
hkGetHardwareInfo(hwInfo);
m_TotalNumThreadsUsed = hwInfo.m_numThreads;
hkCpuJobThreadPoolCinfo,CPU线程池的信息,如线程的数目,每个线程的堆栈的大小等。它的成员m_numThreads是可以使用的线程的数目,要减一,因为主线程不在计算内。m_timerBufferPerThreadAllocation,它是为了保存timer的信息,而在每个线程中分配的缓冲区的尺寸。如果使用VDB(可视化调试器),建议设为2000000。
hkCpuJobThreadPoolCinfo gThreadPoolCinfo;
gThreadPoolCinfo.m_numThreads = m_TotalNumThreadsUsed-1;
gThreadPoolCinfo.m_timerBufferPerThreadAllocation = 200000;
m_ThreadPool = new hkCpuJobThreadPool(gThreadPoolCinfo);
创建工作队列。这在前面介绍基本库时有介绍,可以复习一下。
hkJobQueueCinfo info;
info.m_jobQueueHwSetup.m_numCpuThreads = m_TotalNumThreadsUsed;
m_JobQueue = new hkJobQueue(info);
...//省去无关细节
以上就是Havok初始化多线程模拟的过程,完整的代码请查看源代码。
2.创建物理世界
类的createHavokWorld方法负责创建物理世界。一个Havok的模拟可以有一个或多个Havok世界,表现为hkpWorld的实例。它是一个容器,用来承载所有要模拟的物理对象。它有一些基本属性,比如重力,Slover等,具体的可以查看文档。下面演示如何创建hkpWorld实例。
hkpWorldCinfo成员m_simulationType,这里是多线程模拟,所以用SIMULATION_TYPE_MULTITHREADED,另外常用的还有SIMULATION_TYPE_CONTINUOUS,表示连续模拟。m_broadPhaseBorderBehaviour,它指定hkpWorld BroadPhase(粗略检测阶段)的行为,这里设置为BROADPHASE_BORDER_REMOVE_ENTITY,表示当对象超出hkpWorld的尺寸时,就将这个实体对象删除。方法setBroadPhaseWorldSize()用于设置hkpWorld的尺寸,参数是一个hkVector4类型的向量。
hkpWorldCinfo worldInfo;
worldInfo.m_simulationType = hkpWorldCinfo::SIMULATION_TYPE_MULTITHREADED;
worldInfo.m_broadPhaseBorderBehaviour = hkpWorldCinfo::BROADPHASE_BORDER_REMOVE_ENTITY;
//设置world尺寸
worldInfo.setBroadPhaseWorldSize(worldsize);
//worldInfo.m_gravity = hkVector4(0.0f,-16.0f,0.0f);
创建hkpWorld,然后注册碰撞代理(Collision Agent),需要注意的是,在多线程模拟时,hkpWorld提供了markForWrite和unMarkForWrite方法,这样一种类似于临界区的机制来防止竞争的发生。每当要修改hkpWolrd时,都要记得使用这两个方法,或者与之功能类似的lock()和unlock()。
m_World = new hkpWorld(worldInfo);
m_World->m_wantDeactivation = false;
m_World->markForWrite();
//注册碰撞代理
hkpAgentRegisterUtil::registerAllAgents(m_World->getCollisionDispatcher());
m_World->registerWithJobQueue(m_JobQueue);
m_World->unmarkForWrite();
3.创建物理场景
类的createPhysicsScene负责创建物理场景。这里创建了地面。
刚体的创建,通过一个叫hkpRigidBodyCinfo的类,它指定了刚体的各种参数,如形状(shape)、位置、运动类型等。以下演示了如何创建一个静态的刚体。这里是作为地面。注意,在修改hkpWorld之前,要先markForWrite。
m_World->markForWrite();
//创建Ground
hkpConvexShape* shape = new hkpBoxShape(m_GroundSize,0.05f);
hkpRigidBodyCinfo ci;
ci.m_shape = shape;
ci.m_motionType = hkpMotion::MOTION_FIXED;
ci.m_position = m_GroundPos;
ci.m_qualityType = HK_COLLIDABLE_QUALITY_FIXED;
创建刚体,然后添加的物理世界。hkpWorld调用addEntity之后,这个刚体就属于hkpWorld了,不要忘了删除一次引用。shape同理。
m_Ground = new hkpRigidBody(ci);
m_World->addEntity(m_Ground);
shape->removeReference();
m_World->unmarkForWrite();
4.开启模拟
simulate方法负责整个模拟状态的更新,每一帧或者每几帧会调用它一次。为了简单,我把模拟的频率固定在了60帧,即1.0/60,代码如下:
两次模拟的时间间隔,我固定死了,为1.0/60,这个值也是SDK推荐的值。你还可以用更小的1.0f/30,这样可以获得更高的效率。
hkReal timestep = 1.0f/60.0f;
hkStopwatch stopWatch;
stopWatch.start();
hkReal lastTime = stopWatch.getElapsedSeconds();
最重要的一次调用,进行了一次多线程模拟。
m_World->stepMultithreaded(m_JobQueue,m_ThreadPool,timestep);
(...省略无关细节)
hkMonitorStream::getInstance().reset();
m_ThreadPool->clearTimerData();
在这里等待,以固定帧率。
while(stopWatch.getElapsedSeconds()<lastTime+timestep);
lastTime += timestep;
二、绑定Havok和Ogre
为了封装Havok和Ogre,创建了一个OgreHavokBody类,它将Havok的刚体对象与Ogre的场景节点封装在一起,简化了操作。这个类内部会根据刚体的状态改变而自动同步它的渲染对象。做这项工作的是它的update方法。每一帧,这个方法都会被调用,它读取Havok刚体的位置和旋转,然后用这些信息更新Ogre的场景节点。
具体请看代码,注释写的很清楚。
好了就是这样,文章写的比较糟糕,见谅。有问题,可以和我联系,songnianhu@163.com
再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://blog.csdn.net/jiangjunshow


 浙公网安备 33010602011771号
浙公网安备 33010602011771号