ElasticSearch 429 Too Many Requests circuit_breaking_exception
- 错误提示
{ "statusCode": 429, "error": "Too Many Requests", "message": "[circuit_breaking_exception] [parent] Data too large, data for [<http_request>] would be [2087772160/1.9gb], which is larger than the limit of [1503238553/1.3gb], real usage: [2087772160/1.9gb], new bytes reserved: [0/0b], usages [request=0/0b, fielddata=1219/1.1kb, in_flight_requests=0/0b, accounting=605971/591.7kb], with { bytes_wanted=2087772160 & bytes_limit=1503238553 & durability=\"PERMANENT\" }" }
重要解决办法
关闭circuit检查:
indices.breaker.type: none
集群config/jvm.options设置如下
-Xms2g
-Xmx2g
#-XX:+UseConcMarkSweepGC
-XX:+UseG1GC
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
以下这些都不用看了
再尝试其他查询也是如此。经排查,原来是ES默认的缓存设置让缓存区只进不出引起的,具体分析一下。
- ES缓存区概述
ES在查询时,会将索引数据缓存在内存(JVM)中: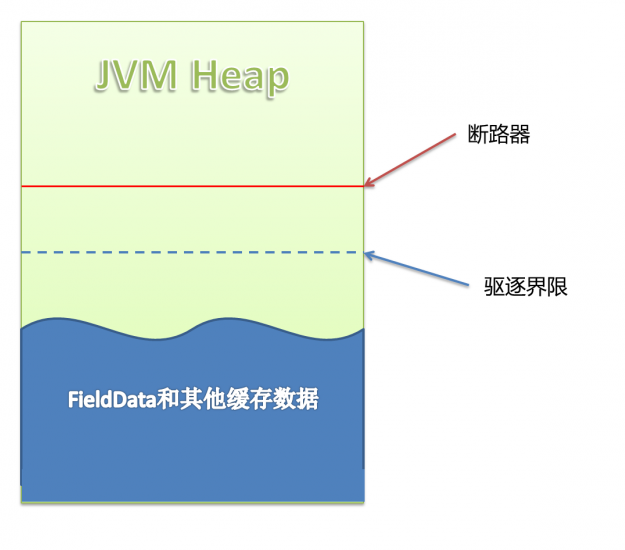
上图是ES的JVM Heap中的状况,可以看到有两条界限:驱逐线 和 断路器。当缓存数据到达驱逐线时,会自动驱逐掉部分数据,把缓存保持在安全的范围内。
当用户准备执行某个查询操作时,断路器就起作用了,缓存数据+当前查询需要缓存的数据量到达断路器限制时,会返回Data too large错误,阻止用户进行这个查询操作。
ES把缓存数据分成两类,FieldData和其他数据,我们接下来详细看FieldData,它是造成我们这次异常的“元凶”。
-
FieldData
ES配置中提到的FieldData指的是字段数据。当排序(sort),统计(aggs)时,ES把涉及到的字段数据全部读取到内存(JVM Heap)中进行操作。相当于进行了数据缓存,提升查询效率。 -
监控FieldData
仔细监控fielddata使用了多少内存以及是否有数据被驱逐是非常重要的。
ielddata缓存使用可以通过下面的方式来监控
# 对于单个索引使用 {ref}indices-stats.html[indices-stats API] GET /_stats/fielddata?fields=* # 对于单个节点使用 {ref}cluster-nodes-stats.html[nodes-stats API] GET /_nodes/stats/indices/fielddata?fields=* #或者甚至单个节点单个索引 GET /_nodes/stats/indices/fielddata?level=indices&fields=* # 通过设置 ?fields=* 内存使用按照每个字段分解了
fielddata中的memory_size_in_bytes表示已使用的内存总数,而evictions(驱逐)为0。且经过一段时间观察,字段所占内存大小都没有变化。由此推断,当下的缓存处于无法有效驱逐的状态。
- Cache配置
indices.fielddata.cache.size 配置fieldData的Cache大小,可以配百分比也可以配一个准确的数值。cache到达约定的内存大小时会自动清理,驱逐一部分FieldData数据以便容纳新数据。默认值为unbounded无限。
indices.fielddata.cache.expire用于约定多久没有访问到的数据会被驱逐,默认值为-1,即无限。expire配置不推荐使用,按时间驱逐数据会大量消耗性能。而且这个设置在不久之后的版本中将会废弃。
看来,Data too large异常就是由于fielddata.cache的默认值为unbounded导致的了。
- FieldData格式
除了缓存取大小之外,我们还可以控制字段数据缓存到内存中的格式。
在mapping中,我们可以这样设置:
{
"tag": {
"type": "string",
"fielddata": {
"format": "fst"
}
}
}
对于String类型,format有以下几种:
paged_bytes (默认):使用大量的内存来存储这个字段的terms和索引。
fst:用FST的形式来存储terms。这在terms有较多共同前缀的情况下可以节约使用的内存,但访问速度上比paged_bytes 要慢。
doc_values:fieldData始终存放在disk中,不加载进内存。访问速度最慢且只有在index:no/not_analyzed的情况适用。
对于数字和地理数据也有可选的format,但相对String更为简单,具体可在api中查看。
从上面我们可以得知一个信息:我们除了配置缓存区大小以外,还可以对不是特别重要却量很大的String类型字段选择使用fst缓存类型来压缩大小。
- 断路器
fieldData的缓存配置中,有一个点会引起我们的疑问:fielddata的大小是在数据被加载之后才校验的。假如下一个查询准备加载进来的fieldData让缓存区超过可用堆大小会发生什么?很遗憾的是,它将产生一个OOM异常。
断路器就是用来控制cache加载的,它预估当前查询申请使用内存的量,并加以限制。断路器的配置如下:
indices.breaker.fielddata.limit:这个 fielddata 断路器限制fielddata的大小,默认情况下为堆大小的60%。
indices.breaker.request.limit:这个 request 断路器估算完成查询的其他部分要求的结构的大小, 默认情况下限制它们到堆大小的40%。
indices.breaker.total.limit:这个 total 断路器封装了 request 和 fielddata 断路器去确保默认情况下这2个部分使用的总内存不超过堆大小的70%。
查询
/_cluster/settings
设置
PUT /_cluster/settings
{
"persistent": {
"indices.breaker.fielddata.limit": "60%"
}
}
PUT /_cluster/settings
{
"persistent": {
"indices.breaker.request.limit": "40%"
}
}
PUT /_cluster/settings
{
"persistent": {
"indices.breaker.total.limit": "70%"
}
}
断路器限制可以通过文件 config/elasticsearch.yml 指定,也可以在集群上动态更新:
PUT /_cluster/settings
{
"persistent" : {
"indices.breaker.fielddata.limit" : 40%
}
}
当缓存区大小到达断路器所配置的大小时会发生什么事呢?答案是:会返回开头我们说的Data too large异常。这个设定是希望引起用户对ES服务的反思,我们的配置有问题吗?是不是查询语句的形式不对,一条查询语句需要使用这么多缓存吗?
在文件 config/elasticsearch.yml 文件中设置缓存使用回收
indices.fielddata.cache.size: 40%
- 总结
1.这次Data too large异常是ES默认配置的一个坑,我们没有配置indices.fielddata.cache.size,它就不回收缓存了。缓存到达限制大小,无法往里插入数据。个人感觉这个默认配置不友好,不知ES是否在未来版本有所改进。
2. 当前fieldData缓存区大小 < indices.fielddata.cache.size
当前fieldData缓存区大小+下一个查询加载进来的fieldData < indices.breaker.fielddata.limit
fielddata.limit的配置需要比fielddata.cache.size稍大。而fieldData缓存到达fielddata.cache.size的时候就会启动自动清理机制。expire配置不建议使用。
3.indices.breaker.request.limit限制查询的其他部分需要用的内存大小。indices.breaker.total.limit限制总(fieldData+其他部分)大小。
4.创建mapping时,可以设置fieldData format控制缓存数据格式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号