
7月28日学习日记
• 基础字符串算法:
• 哈希
• 使用一个哈希函数将某个特定的数字变成另一个数字,这种操作称之为hash。
• 通常我们会以取模运算来作为哈希函数。
• 举例:hash(key)=key%23, 这样数组 [1,75,324] -> [1,6,2]
• 如果哈希后得到的值相同,我们则可用该值建一个链表,把相同的值都放一起,
这样我们就可以得到一个哈希表。
• 可以采用meet in the middle 策略:
• 一边枚举x1,x2
• 一边枚举x4,x3.
• 具体是:先枚举x1,x2,算出 P-ax1-bx2的值,存入哈希表,注意要统计次数。
• 然后枚举x3,x4,算出cx3+dx4,看它在哈希表里出现了几次。
• 时间复杂度O(n^2)
• KMP算法
• 一个字符串S的Border:最大的i<|S|满足S[1…i]=S[|S|-i+1…|S|],即最长的
前缀满足它同时是一个后缀
• 定义fail(i)为S[1…i]的Border。定义fail(1)=0。
• 算法过程如下:
• (1)如果当前能匹配则直接匹配
• (2)不能匹配则跳fail,重复(1)
• (3)如果跳不了fail则将匹配位置置为开头。注意到fail是最长的满足开头一
段等于末尾一段的,所以这个算法是正确的。
• 扩展kmp
• 我们发现如果 S=T,那么 extend 数组就是 Z 数组。
假设我们现在已经遍历到 S[i], 且 S[1]...S[i-1]都算出来了。
与 Z 算法类似,我们维护两个变量 l 和 r,r 表示能和 T 匹配到的最右边的位
置,l 为 r 对应的起始位置。
• Manacher算法
• 对于一个字符串S,如何计算出它的所有回文串?
• 首先在所有字符前后加入特殊字符#。这样我们就只需考虑由某个字符为
中心的回文串长度。如aab#a#a#b#
• 算法过程如下:记len(i)为以字符i为中心能拓展多少层,一个字符记做0层
。
• (1)计算max(len(i)+i),记做mx;以及对应的i,记做id
• (2)每次从min(len[2*id-i],mx-i)
开始暴力拓展。
我们只需要统计出以 i 为起点的回文串个数 st[i] 和以 i 为终点的回文串个数
ed[i]. 那只需要计算:
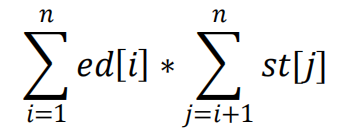
在 manacher 算法过程中,对于每个 i 求出 r[i] 后。我们就需要把当前极大回
文子串 [i-r[i], i+r[i]] 对 st 和 ed 的贡献算进去。
对于 st: [i-r[i], i] 这些点每个位置都 +1.
对于 ed: [i, i+r[i]] 这些点的每个位置 +1.
可以用差分转化为单点修改。
最后总的对数-不想交的对数即是答案
• Trie树
• 首先允许自己异或自己以及a[i]^a[j]和a[j]^a[i]看作两对,k变成2k+n,好处是
可以把每个数字看作A,然后和a[1]~a[n]异或,最后统计。
• 考虑对于A如何直到和a[1]~a[n]异或出来的前k小,显然建Trie跑一跑就可以
了。而且显然是可以依次直到第1小,第2小,第3小……
• 那么类似那个求a[i]+b[j]的第k小的做法,直接用一个堆维护即可。
• AC自动机
• 考虑把S放到一块建类似nxt一样的东西(在AC自动机中叫fail指针)
• 先将S建Trie,考虑在Trie上运行T。
• 当遇到无法匹配的情况时,希望找到T已匹配部分的一个最长后缀,使得这
个后缀也是某个S的前缀。注意这里实际上和T无关,我们只需要对Trie上每
个节点对应的字符串做这件事情即可。
• 换句话说,我们要对每个点找到其最长后缀也是某个S的前缀,而S的前缀必
然对应Trie上一个点,或者说我们需要找到一个失配节点(fail)。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~