
ElasticSearch
ElasticSearch介绍
ElasticSearch是开源的,它可以快速的存储、搜索和分析海量数据,是全文搜索引擎的首选。维基百科、Stack Overflow、Github都采用它。
Elastic的底层是开源的Lucene,但Lucene必须自己写代码去调用它的接口,Elastic是Lucene的封装,提供了REST API的操作接口,开箱即用。
ElasticSearch6.4.2安装
1.下载elastic
https://www.elastic.co/downloads/elasticsearch
解压:tar -xvf elasticsearch-6.4.2.tar.gz
2.创建用户(从5.0开始,ElasticSearch 安全级别提高了,不允许采用root帐号启动,所以我们要添加一个用户)
创建组:groupadd es 创建用户:useradd es 设置密码:passwd es 将用户添加到组:usermod -G es es 设置sudo权限:visudo 在在root ALL=(ALL) ALL 下面加一行es ALL=(ALL) ALL
3.配置
elasticsearch.yml
cluster.name: my-application node.name: node-1 network.host: 0.0.0.0 http.port: 9200 bootstrap.memory_lock: false bootstrap.system_call_filter: false
path.data &path.logs
如果您正在使用.zip或.tar.gz文件归档,data和logs 目录在$ES_HOME下。如果这些重要文件夹保留在默认位置,则Elasticsearch升级到新版本时,很有可能被删除。在生产中使用,肯定要更改数据和日志文件夹的位置。
path: logs: /var/log/elasticsearch data: /var/data/elasticsearch
path.data可以同时指定多个路径,所有的路径都会被用来存储数据(但所有属于同一个分片的文件,都会全部保存到同一个数据路径)
path: data: - /mnt/elasticsearch_1 - /mnt/elasticsearch_2 - /mnt/elasticsearch_3
cluster.name
某个节点只有和集群下的其他节点共享它的cluster.name才能加入一个集群,用于描述集群的名称。一定要确保不要在不同的环境中使用相同的集群名称。否则,节点可能会加入错误的集群中。
cluster.name: rpms
node.name
默认情况下,Elasticsearch 将使用随机生成的uuid的前7个字符作为节点id,请注意,节点ID是持久化的,并且在节点重新启动时不会更改,因此默认节点名称也不会更改。推荐为节点配置更有意义的名称。
node.name: prod-data-2
也可以使用服务器的${HOSTNAME}作为节点的名称
node.name: ${HOSTNAME}
bootstrap.memory_lock
由于当jvm开始swapping时es的效率会降低,所以要保证它不swap,这对节点健康极其重要。实现这一目标的一种方法是将bootstrap.memory_lock设置为true,内存锁定。
network.host
默认情况下,Elasticsearch 仅仅绑定回环地址,比如127.0.0.1 和[::1] 。这足以在服务器上运行单个开发节点。事实上,一台机器上可以启动多个节点。这可对于测试Elasticsearch集群的能力很有用,但不推荐用于生产。为了与其他服务器上的节点进行通信并形成集群,你的节点将需要绑定到非环回地址。虽然这里有很多网络相关的配置,但通常只需要配置一下
network.host: 0.0.0.0
network.host设置一些特殊值也是可以的。比如_local_,_site_,_global_,ip4,ip6。
一旦设置了network.host,Elasticsearch 会假定你正在从开发模式转移到生产模式,并将许多系统启动检查从警告升级到异常。有关详细信息,请参阅“Development mode vs production mode”。
discovery.zen.ping.unicast.hosts
开箱即用,没有任何网络配置情况下,Elasticsearch将绑定到可用的回环地址,并会扫描端口9300至9305以尝试连接到同一服务器上运行的其他节点。这提供了一个自动集群体验,而无需执行任何配置。
如果想和其他服务器的节点形成一个集群,你必须提供集群中其它节点的列表。可以通过以下方式指定:
discovery.zen.ping.unicast.hosts: - 192.168.1.10:9300 - 192.168.1.11 - seeds.mydomain.com
如果没有指定端口,将默认为transport.profiles.default.port,并回退transport.tcp.port
如果输入的是主机名,被解析成多个地址,将会尝试连接所有地址。
discovery.zen.minimum_master_nodes
为了防止数据丢失,discovery.zen.minimum_master_nodes配置至关重要, 以便每个候选主节点知道为了形成集群而必须可见的最少数量的候选主节点。没有这种设置,遇到网络故障的群集有可能将群集分成两个独立的群集(脑裂), 这将导致数据丢失。更详细的解释在“Avoiding split brain with minimum_master_nodes ” 中提供。
为了避免脑裂,候选主节点的数量应该设置为:
(master_eligible_nodes / 2) + 1
换句话说,如果现在有3个节点,最小候选主节点数应该是(3/2)+1=2:
discovery.zen.minimum_master_nodes: 2
4.异常处理
1)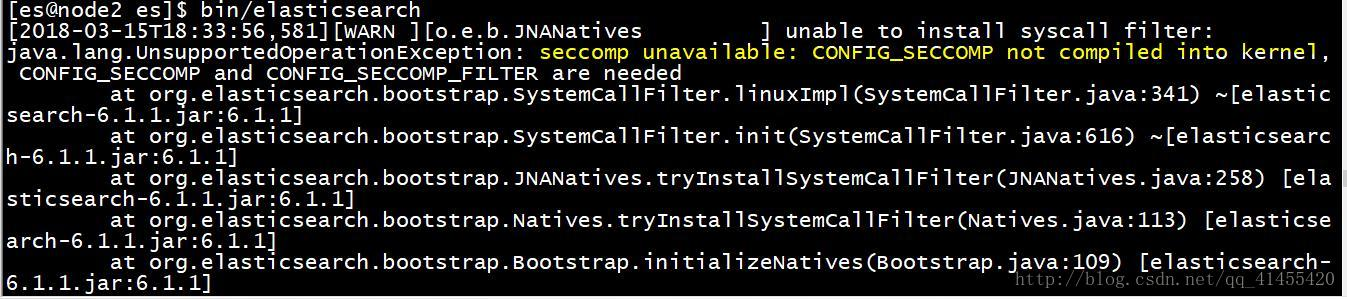
原因:Centos6、7不支持SecComp,而ES默认bootstrap.system_call_filter为true进行检测,所以导致检测失败,失败后直接导致ES不能启动。
解决方案:
在elasticsearch.yml中新增配置:bootstrap.system_call_filter: false
2)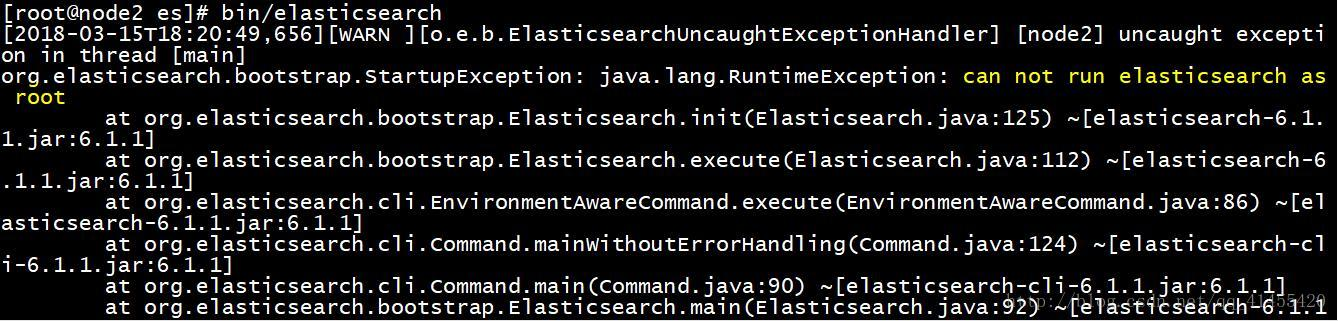
原因:因为安全问题elasticsearch 不让用root用户直接运行,所以要创建新用户es。
3)
第一个原因:无法创建本地文件问题,用户最大可创建文件数太小
解决方案:切换到root用户,编辑limits.conf配置文件, 添加类似如下内容:
vi /etc/security/limits.conf * soft nofile 65536 * hard nofile 131072
第二个原因:无法创建本地线程问题,用户最大可创建线程数太小
解决方案:切换到root用户,进入limits.d目录下,修改90-nproc.conf 配置
vi /etc/security/limits.d/90-nproc.conf * soft nproc 1024 #修改为 * soft nproc 4096
第三个原因:最大虚拟内存太小
每次启动机器都手动执行下。
root用户执行命令:
执行命令:sysctl -w vm.max_map_count=262144
查看修改结果命令:sysctl -a|grep vm.max_map_count 看是否已经修改
永久性修改策略:
echo "vm.max_map_count=262144" >> /etc/sysctl.conf
5.安装ik中文分词器
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.4.2/elasticsearch-analysis-ik-6.4.2.zip
6.启停命令
启动:cd bin目录,执行./elasticsearch 后台启动:./elasticsearch -d 停止:ps -ef | grep elastic 然后kill -9 pid杀掉进程
7.curl 'http://localhost:9200/'得到如下说明启动成功。
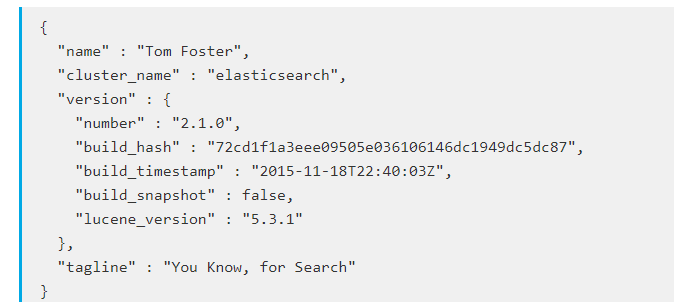
elasticsearch head安装
1.安装node.js、npm
yum -y install nodejs npm
安装最新版本
npm install -g n
n latest
n stable
n lts
2.安装git
yum -y install git
3.下载head
git clone git://github.com/mobz/elasticsearch-head.git
4.安装head
cd elasticsearch-head/
npm install
5.异常处理
1.node npm install Error:CERT_UNTRUSTED ssl验证问题,使用npm config set strict-ssl false取消ssl验证即可 2.code ELIFECYCLE,phantomjs-prebuilt@2.1.16 install: `node install.js` npm install phantomjs-prebuilt@2.1.16 --ignore-scripts
6.配置
1.修改Gruntfile.js cd elasticsearch-head/ vim Gruntfile.js 搜索 /keepalive,在下面增加 hostname: '*' 2.修改app.js cd elasticsearch-head/_site vim app.js 搜索 /localhost,改为内网ip 3.配置elasticsearch.yml,增加跨域配置 在最下面增加 http.cors.enabled: true http.cors.allow-origin: "*"
7.启动
cd elasticsearch-head/node_modules/grunt/bin/
./grunt server &
8.访问
http://47.104.***.***:9100/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号