
分布式锁
为什么要使用分布式锁
使用分布式锁的目的,无外乎是为了保证共享资源在同一时间只被一个线程操作。
单机时代,通常我们会使用java并发相关API(Lock或synchronized)进行互斥实现。分布式情况下较为复杂,线程分配在不同的进程或机器中,这时候我们需要一种跨JVM的互斥机制来控制共享资源的访问,分布式锁应运而生。
需要具备哪些条件
-
在分布式系统环境下,一个方法在同一时间只能被一个线程执行;
-
高可用、高性能的获取锁和释放锁;
-
具备可重入性;
-
失效机制,防止死锁;
-
具备阻塞锁和非阻塞锁特性(根据业务需要考虑需要);
常见的分布式锁实现方案
-
基于数据库实现方案;
-
基于分布式缓存实现的锁服务:典型代表是使用Redis实现锁服务和基于Redis实现的RedLock方案;
-
基于分布式一致性算法实现锁服务:典型代表zookeeper和google的Chubby;
具体实现
基于数据库
先来了解核心实现:
-
创建一张锁表,以其中一个字段为唯一索引
-
使用方法名向表中插入数据,插入成功则获取锁成功
-
方法结束后删除数据,释放锁
以上三步完成锁的基本要求,实现简单,但工作中为什么我们不使用这种方式呢?
有以下几个问题:
-
数据库的可用性和性能影响分布式锁的可用性及性能
-
锁没有失效时间,可能会导致死锁
-
只能非阻塞,成功失败立刻返回
-
非重入,同一个线程在没有释放锁之前无法再次获得该锁
当然我们也可以在程序上处理这几个问题,但考虑到性能与复杂度又会得不偿失。
基于Redis
先来了解锁核心实现:
-
加锁setnx(key,value)
-
锁超时expire(key,time)
-
解锁del(key)
以上三步满足锁的基本要求,细思量某些场景又会出问题:
场景1:A想获取锁,于是A操作setnx成功,这时A突然挂了,还未来得及expire; 此时锁就无超时时间。
解决:使用SET KEY VALUE [EX seconds] [PX milliseconds] [NX|XX] 替代setnx与expire,变成原子操作;
场景2:A获取锁成功,这时B来了,B获取锁失败,走之前顺便del一下,把锁释放了,这时C来了就和A撞一起了。
解决:使用线程ID存储value,释放锁之前判断是否是自己的锁(不限于此)
场景3:A获取锁成功,但是A干活太慢所已经超时了,这时B来了
解决:启动守护线程重设A的超时时间(考虑程序优化,为什么执行这么慢呢)
基于zookeeper
了解Zookeeper的节点分为4种类型,分别为持久节点、持久顺序节点、时节点、临时顺序节点;这里我们重点关注 【临时顺序节点】,这是实现分布式锁的重要依据。这种节点有如下几个特性:
-
会话结束后节点自动删除,也可手动删除;
-
不能拥有子节点;
-
节点以10位数字序列号为后缀形式命名;(zk_lock_0000000001)
来看一张图:
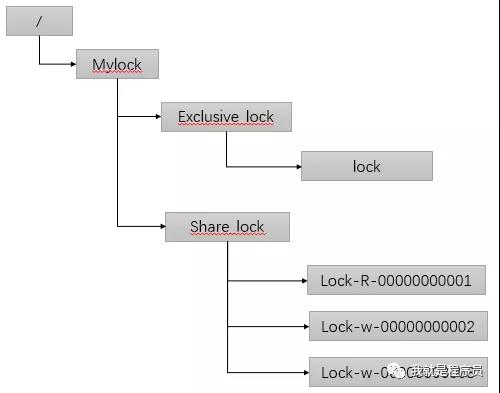
先来分析排它锁(Exclusive_lock),核心过程如下:
-
A、B、C竞争锁资源,创建临时节点lock,A创建成功;
-
B、C设置watch lock节点;
-
A执行操作完成,删除lock节点释放锁,或A挂了,lock节点自动删除;
-
B、C收到zk的通知;
-
B和C竞争创建临时节点lock,同上面4步,直至获取锁成功
排它锁实现简单易于理解,不再多说;下面来分析共享锁(Share_lock);
-
A、B、C分别创建自己的顺序临时节点分别为R1、W2、W3
-
获取zk的 /Share_lock下的所有节点;
-
判断自己的节点是否是Share_lock下的最小节点,A最小获取锁成功,B、C置自身上一个节点的watcher;即B watch R1 , C watch W2;
-
A操作完成,删除R1节点;
-
zk通知B获取锁;
简述优缺点
从三个方面考虑:实现复杂度、性能、可靠性由高到低对三种实现方式比较
实现复杂度:zookeeper > 缓存 > 数据库
可靠性:zookeeper > 缓存 > 数据库
性能:缓存 > zookeeper > 数据库

 浙公网安备 33010602011771号
浙公网安备 33010602011771号