第六章 【2】Hadoop-Mapreduce原理
目录
- 回顾上节内容
- Mapreduce介绍
- Mapreduce工作流程图
- Mapreduce案例,共9个
回顾上节内容
- Hadoop组成部分
由hdfs和Mapreduce组成,hdfs是分布式文件存储,由nameNode和dataNode组成,nameNode是存储和管理元数据信息;datanode是存储具体的数据,hdfs默认是把文件按照128mb做物理切分一个block,此时hadoop会把block默认复制三份存储到不同机器上;block文件大小可以修改对应hfs.block.size.
mapreduce介绍
在讲解mapreduce之前,大家可能会说spark会取代mapreduce,spark主要是内存计算,如果公司考虑时效性,不考虑运算成本,可以采用spark,公司考虑运算稳定性,不考虑时效性,优先考虑mapreduce;
mapreduce是分布式计算框架(分而治之),mapreduce是有jobtracker和tasktracker,即调度工作和执行工作;一个mapreduce只会有一个jobtracker;组成图:
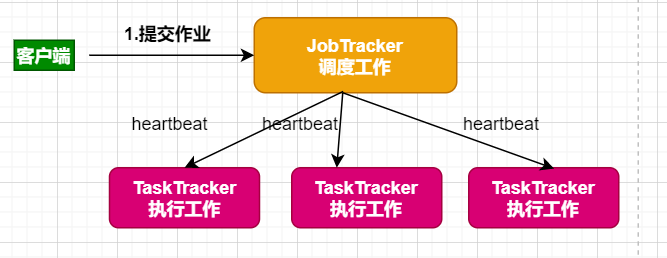
mapreduce核心是shuffle,shuffle的核心是1:对map中key的洗牌 2:reduce网络数据拉取
Mapreduce工作流程图
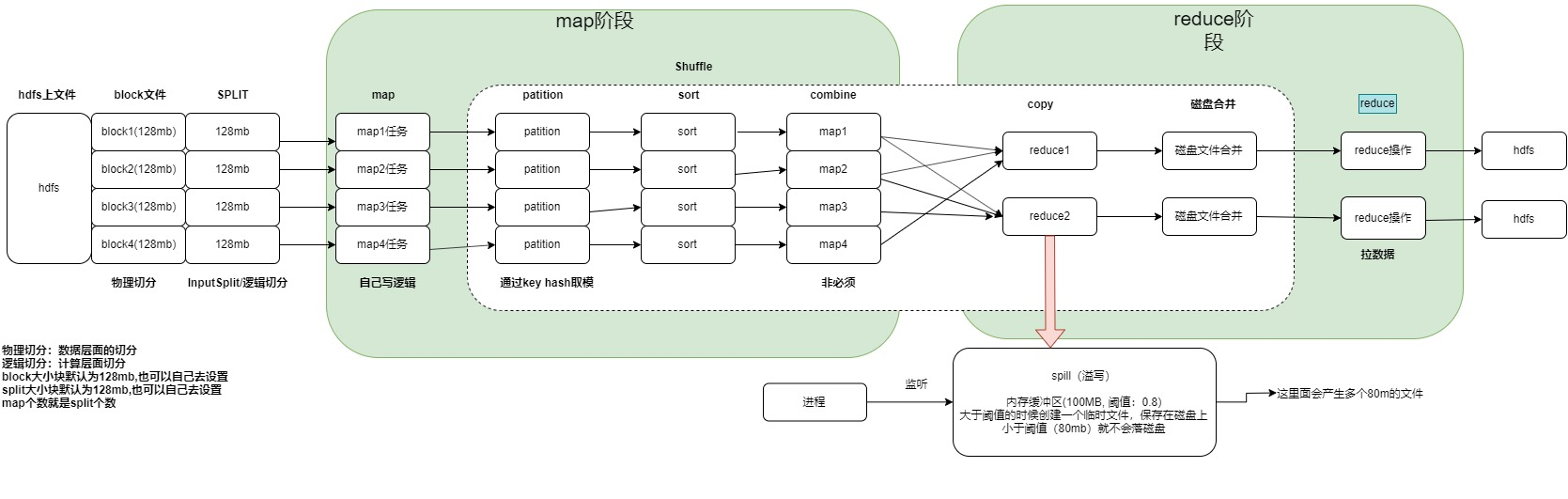
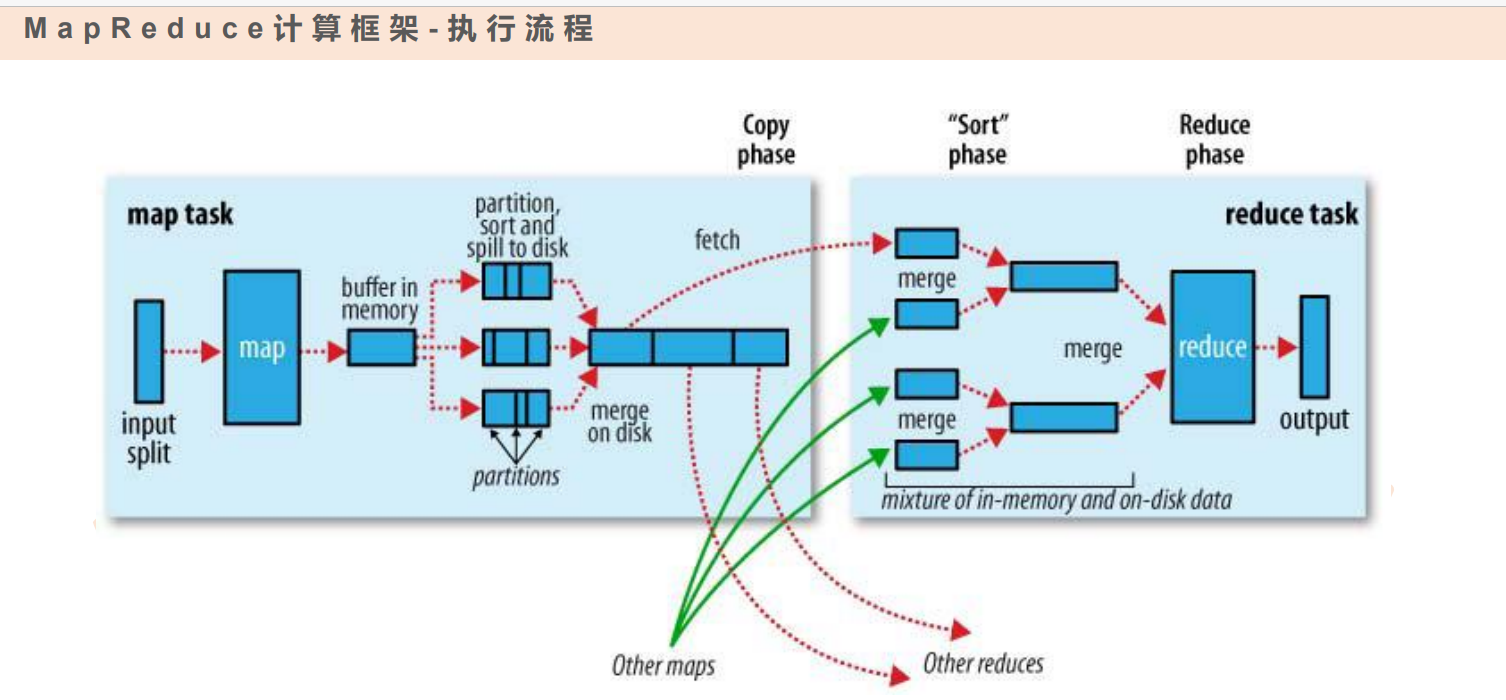
Mapreduce执行流程图
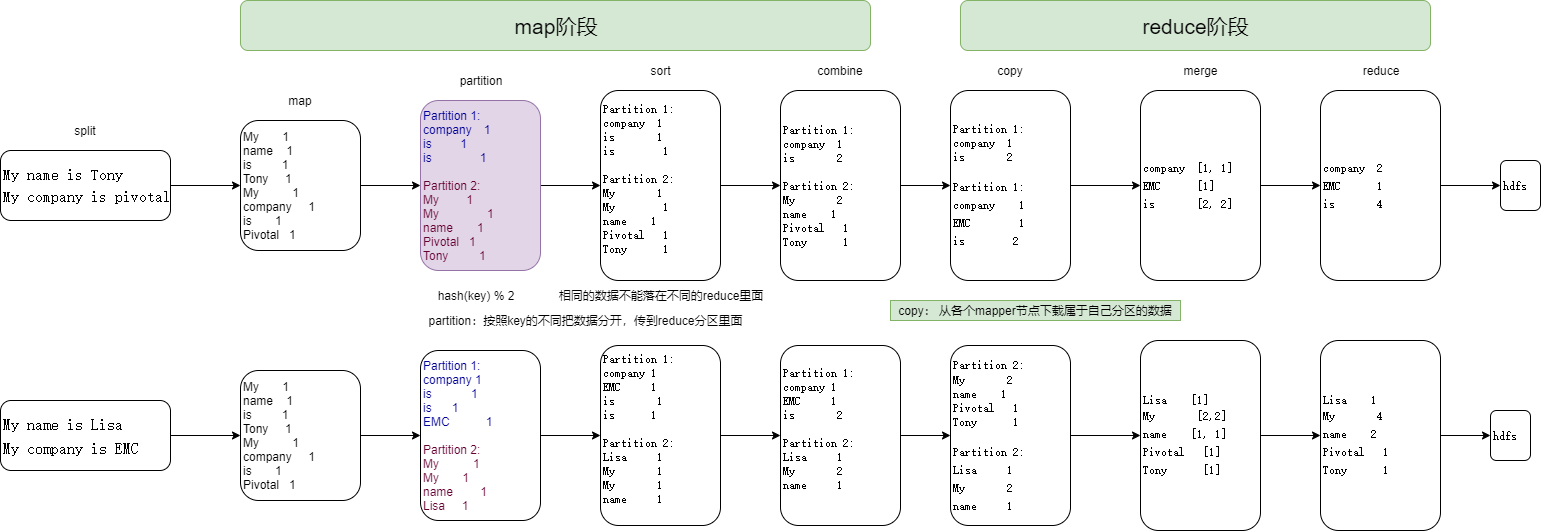
案例图:
mapreduce中shuffle过程遇到数据倾斜如何优化
在进行优化之前,先来说一下什么是数据倾斜,数据倾斜: map阶段shuffle过程中,partition出现大量的数据存在一个reduce上;
- 1.对map中的key做随机打算,分配到不同reduce,使单个reduce减少压力
- 2.在map阶段做combinner,减少传递到reduce的数据压力
mapreduce案例和对应数据优化
- 1.数据去重,对ip数据进行去重
192.168.127.49
192.168.127.78
192.168.127.49
192.168.127.49
192.168.127.23
192.168.127.49
192.168.127.49
192.168.127.49
192.168.127.25
192.168.170.49
192.168.170.49
192.168.170.26
192.168.170.49
.....
192.168.170.27
重点说明:
1、为了减少网络的传输,map中的value值为null
2、本身借助reduce聚合去重进行实现去重功能
** 流程图如下:**
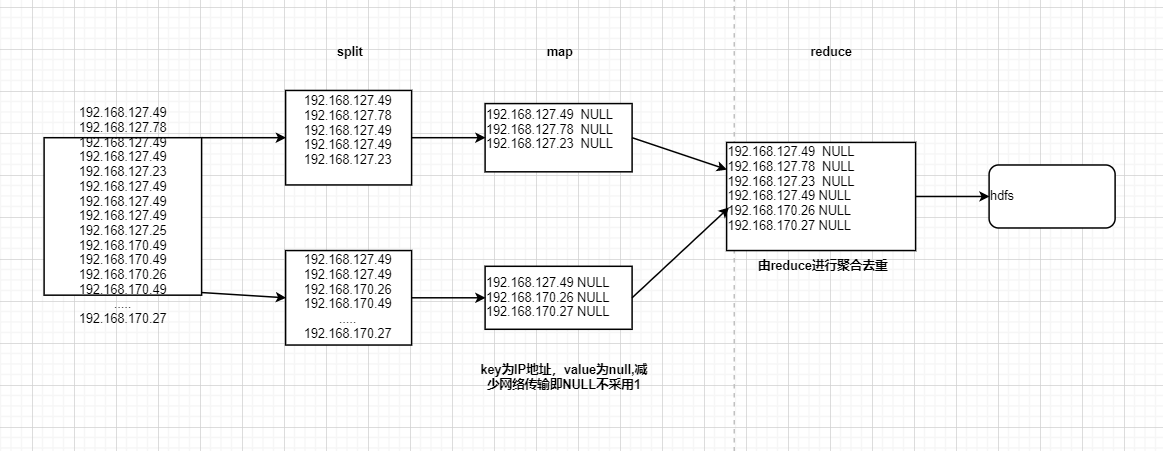
注意 :该案例是否可以采用只有map阶段,没有reduce阶段?欢迎大家讨论和回答
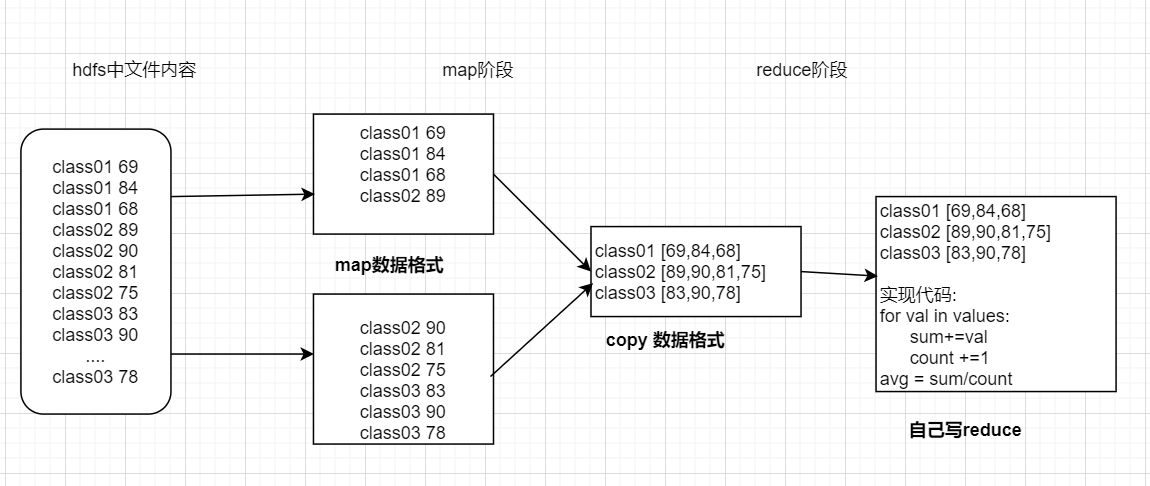
- 2.分组求平均值,每个班的历史成绩求平均值
class01 69
class01 84
class01 68
class02 89
class02 90
class02 81
class02 75
class03 83
class03 90
....
class03 78
重点:
1.map阶段阶段对map进行拆分,拆分格式为:key:年级 value:分数
2.reduce阶段对reduce进行key对应集合迭代汇总并求平均.
** 流程图:**
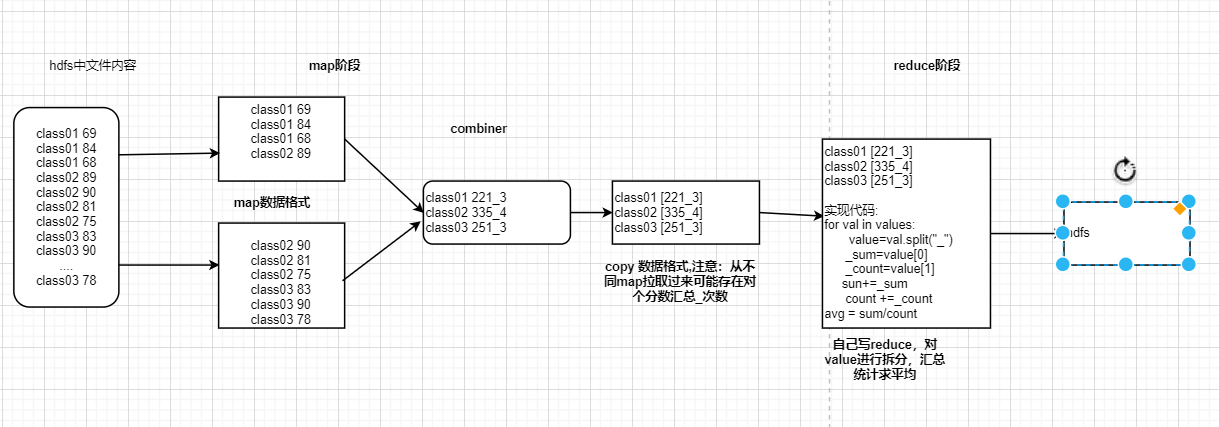
扩展
1、采用combinner进行实现流程:
1)在combinner进行对单个map数据汇总,处理成的格式为🔑名字 value:分数汇总_次数
2)在reduce中对value进行数据拆分,在进行汇总,请平均
3)流程图如下:
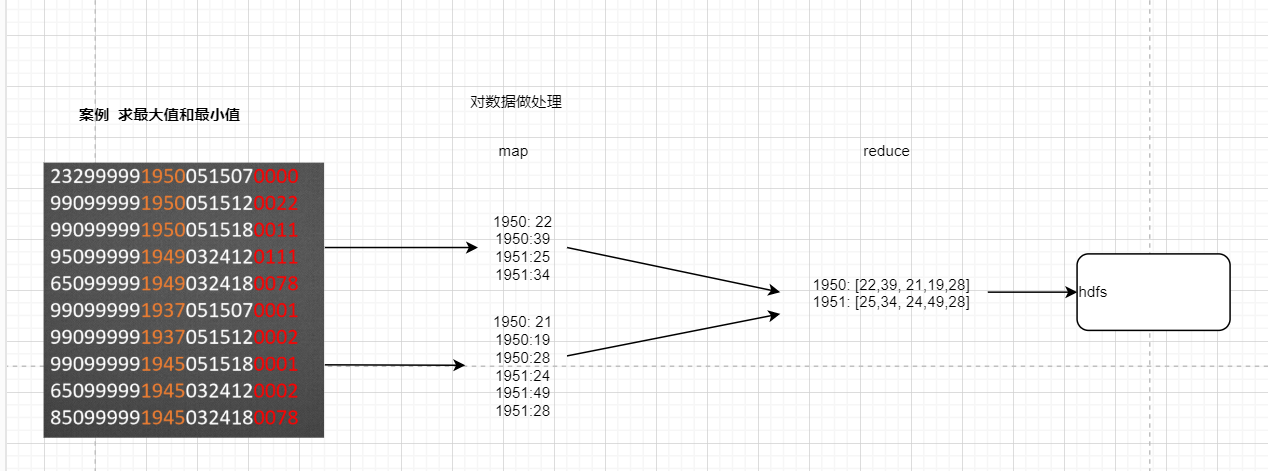
- 3.求最大最小值,
假设我们需要处理一批有关天气的数据,其格式如下:
按照ASCII码存储,每行一条记录。每行共24个字符(包含符号在内)
第9、10、11、12字符为年份,第20、21、22、23字符代表温度,求每年的最高温度
2329999919500515070000
9909999919500515120022
9909999919500515180011
9509999919490324120111
6509999919490324180078
9909999919370515070001
9909999919370515120002
9909999919450515180001
6509999919450324120002
8509999919450324180078
重点:
1.map阶段对map进行数据处理即截取获取年和温度
2.reduce阶段对reduce进行key对应集合迭代汇求最大值和最小值
** 流程图:**
扩展
1、采用combinner进行实现流程:
1)在combinner进行对单个map数据汇总,处理成的格式为🔑名字 value:单个map中最小值_单个map中最大值
2)在reduce中对value进行数据拆分,在进行汇总,求最大值和最小值
3)流程图如下:

- 4.购物金额统计
phone address name consum
13877779999 bj zs 2145
13766668888 sh ls 1028
13766668888 sh ls 9987
13877779999 bj zs 5678
13544445555 sz ww 10577
13877779999 sh zs 2145
13766668888 sh ls 9987
重点:
1.自定义map和reduce输入输出类型,输入和输出类型必须为序列化和反序列化,需要重写Writable中write和readFields
代码
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FlowBean implements Writable{
private String phone;
private String add;
private String name;
private long consum;
// 序列化
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(phone);
out.writeUTF(add);
out.writeUTF(name);
out.writeLong(consum);
}
// 反序列化,跟序列化的顺序不能改变
@Override
public void readFields(DataInput in) throws IOException {
this.phone=in.readUTF();
this.add=in.readUTF();
this.name=in.readUTF();
this.consum=in.readLong();
}
public String getPhone() {
return phone;
}
public String getAdd() {
return add;
}
public String getName() {
return name;
}
public long getConsum() {
return consum;
}
public void setPhone(String phone) {
this.phone = phone;
}
public void setAdd(String add) {
this.add = add;
}
public void setName(String name) {
this.name = name;
}
public void setConsum(long consum) {
this.consum = consum;
}
@Override
public String toString() {
return "FlowBean [phobe="+phone+",add="+add+",name="+name+",consum="+consum+"]";
}
}
import hadoop_test.avro_test_05.domain.FlowBean;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line=value.toString();
//#实例化
FlowBean flowBean=new FlowBean();
//给一个实例的属性赋予初始值,
flowBean.setPhone(line.split(" ")[0]);
flowBean.setAdd(line.split(" ")[1]);
flowBean.setName(line.split(" ")[2]);
flowBean.setConsum(Integer.parseInt(line.split(" ")[3]));
System.out.println(flowBean);
context.write(new Text(flowBean.getName()), flowBean);
}
}
import hadoop_test.avro_test_05.domain.FlowBean;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReducer extends Reducer<Text, FlowBean,Text,FlowBean> {
@Override
protected void reduce(Text name, Iterable<FlowBean> values,
Context context)
throws IOException, InterruptedException {
FlowBean tmp=new FlowBean();
for(FlowBean flowbean:values){
tmp.setAdd(flowbean.getAdd());
tmp.setPhone(flowbean.getPhone());
tmp.setName(flowbean.getName());
tmp.setConsum(tmp.getConsum()+flowbean.getConsum());
}
context.write(name, tmp);
}
}
- 5.分区,按地区分为三个分区并且每个地区输出一个文件
phone address name consum
13877779999 bj zs 2145
13766668888 sh ls 1028
13766668888 sh ls 9987
13877779999 bj zs 5678
13544445555 sz ww 10577
13877779999 sh zs 2145
13766668888 sh ls 9987
重点:
1.每个地区一个文件,可以转换为一个地区对应一个reduce,一个reduce输出一个文件,即可以通过partition分区,进行解决
2.可以通过代码设置partition规则进行实现
import hadoop_test.partition_test_06.domain.FlowBean;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
import java.util.Random;
public class FlowPartitioner extends Partitioner<Text,FlowBean> {
@Override
//<Text,FlowBean>指的是map的key,value
public int getPartition(Text key, FlowBean value, int numPartitions) {
//数据倾斜解决
// Random R = new Random();
// String hash_key=key.toString()+String.valueOf(R.nextInt());
// return (hash_key .hashCode() & Integer.MAX_VALUE) % numPartitions;
if(value.getAddr().equals("sh")){
return 0;
}
if(value.getAddr().equals("bj")){
return 1;
}
else{
return 2;
}
}
}
- 6.排序和全排序,基于电影评分,对电影进行排序
movie1 72
movie2 83
movie3 67
movie4 79
movie5 84
movie6 68
movie7 79
movie8 56
movie9 69
movie10 57
movie11 68
流程图

重点
1、是否只有map,没有reduce就可以实现;map只能做局部排序,但是不能做全局排序;如果想做全局排序:需要一个reduce
2、也可以通过数据范围进行分区,即生成对应reduce,几个reduce生成的文件合并就是全局排序
- 7.排序和全排序
需求说明
利用3个reduce来处理,并且生成的三个结果文件,是整体有序的。生成的三个结果文件:不同位数一个文件。
93 239 231
23 22 213
613 232 614
213 3939 232
4546 565 613
231 231
2339 231
1613 5656 657
61313 4324 213
613 2 232 32
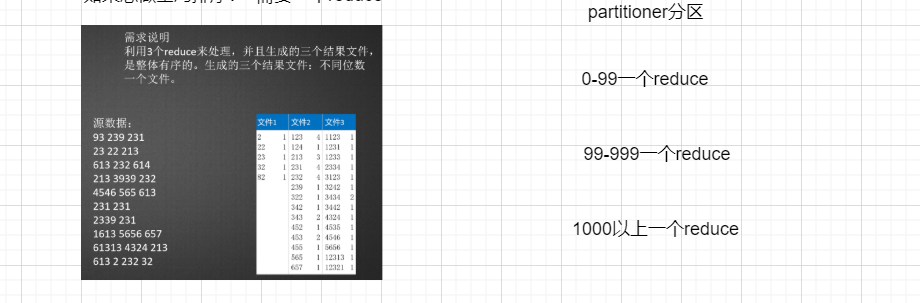
重点
1、通过partitin数据范围进行分区,输入到对应reduce,即生成不同的文件
partiton区分代码
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
/**
*
* 为什么有不用默认分区?因为默认是key 的hashcode分区,这达不到全排序效果,所以需要自定义分区
* 此外,回去复习正则的知识
* @author ysq
*
*/
public class TotalSortPartitioner extends Partitioner<IntWritable,IntWritable> {
@Override
public int getPartition(IntWritable key, IntWritable value, int numPartitions) {
// key.toString().matches("[0-9]")匹配10一下数子key.toString().matches("[0-9][0-9]匹配0-100
if(key.toString().matches("[0-9]")|key.toString().matches("[0-9][0-9]")){
return 0;
}
if(key.toString().matches("[0-9][0-9][0-9]")){
return 1;
}else{
return 2;
}
}
}
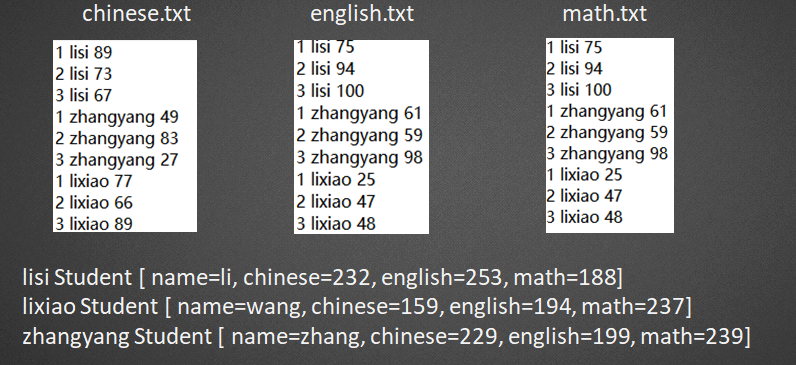
- 8.多文件合并,任务: 计算每个人三个月,每一课的总成绩。
![]()
重点
1、在map中通过获取输入split文件名称,进行业务处理;相关获取文件名称代码如下:
//一行一行处理
@Override
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
//split切片类
FileSplit split=(FileSplit) context.getInputSplit();
//split.getPath().getName();获得正在读取的这个split的文件名
String filename=split.getPath().getName();
//line===》 1 lisi 3
String line=value.toString();
//理解为join 的 key
String name=line.split(" ")[1];
//分数
int score=Integer.parseInt(line.split(" ")[2]);
Score s=new Score();
s.setName(name);
if(filename.equals("chinese.txt")){
s.setChinese(score);
}
if(filename.equals("english.txt")){
s.setEnglish(score);
}
if(filename.equals("math.txt")){
s.setMath(score);
}
context.write(new Text(s.getName()), s);
}
- 9.相似好友查询,基于Mr找出两个用户的共同好友
刘灵薇 孙初丹,孙听兰,李秋翠,李绿春
王访琴 刘忆翠,钱语芙,钱平蝶
赵雅蕊 刘灵薇,刘雅蕊
王含蕾 钱语芙,李书蕾,李忆翠
钱雅蕊 李秋春,李初丹,孙听蓉
王绿春 李含烟,刘谷丝,孙秋春,钱雅蕊,赵语芙,钱南松,钱绿春,王听兰
刘含玉 赵绿春,王幻珊,刘语芙,赵怜菡,孙绿春,赵从蓉,赵南松,刘幻灵,王忆翠
钱凌瑶 孙诗云,王乐瑶,钱海露,孙从蓉
李含蕾 李从蓉,李从蓉,刘怜菡,钱灵雁
钱幻灵 赵书蕾,赵秋翠,刘幻珊,刘幻灵,刘雪青,钱夏彤,赵含蕾
刘夏彤 刘忆翠,钱诗云,王代曼,李雪青,赵白晴
刘初丹 李涵双,钱诗云,钱怜菡,孙含玉,李含烟,李听蓉,李海露,王涵双,钱凌瑶
李忆翠 钱秋翠,钱书蕾,孙灵薇,王夏彤,刘秋翠,赵从梦
王幻灵 孙幻灵,赵凌瑶,王语芙,刘灵薇,王代荷,王夏彤
孙忆翠 刘灵薇,赵涵双,刘夏彤,李雪青
李幻灵 赵凌瑶,王幻珊
王代曼 赵听白,王怜菡,孙南松,赵从梦,钱忆翠
刘代曼 李秋翠,赵听兰
刘绿春 王听白,赵书蕾,李怜菡,孙白晴,王怜菡,孙海露,赵南松
李听蓉 孙雅蕊,王含蕾
孙绿春 赵从蓉,王傲之,王听兰,赵诗云,李平蝶,孙听白,李忆翠,钱灵薇,王从蓉
重点
1.在map中把后面两两组合中间用"_",在组合之前先排序,即map输出为key:孙初丹_孙听兰 value:刘灵薇
2.在shuffle之后,进行到reduce,会自动把key相同进行合并,合并格式为:孙初丹_孙听兰 [刘灵薇,王代曼];
在reduce,把[刘灵薇,王代曼]进行拼接输出字符串格式为:刘灵薇,王代曼
大数据环境下冷启动的问题,以及什么是冷启动?
基于地区热度的冷启动问题
疑问回复
1.在map阶段中自定义的map输出类型需要跟combiner的输入类型保持一致,map和combiner输出类型也需要跟reduce输入类型保持一致。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号