第六篇 大数据Hadoop
目录
- 大数据Hadoop组成部分
- HDFS中NameNode介绍
- HDFS中DataNode介绍
- HDFS中NameNode和DataNode工作原理
大数据Hadoop1.0与Hadoop2.0区别
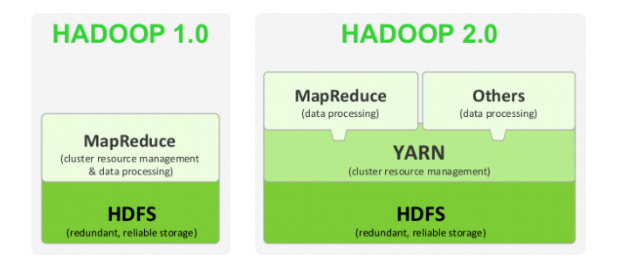
1.Hadoop1.0版本两个核心:HDFS+MapReduce
2.Hadoop2.0版本,引入了HDFS+Yarn+Mapreduce。
Yarn是资源调度框架。能够管理和调度任务。此外,还能够支持其他计算框架基于hdfs的计算,比如spark等。
大数据Hadoop中HDFS组成部分
HDFS是分布式文件存储系统,存储海量数据,单台机器性能纵向扩展的问题,是有硬件瓶颈的,包括成本也会指数型增长。
HDFS主要由NameNode和DataNode组成,如下图:
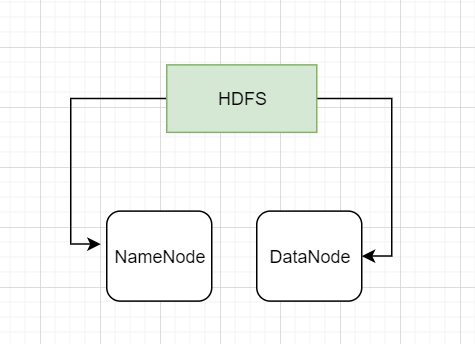
HDFS中NameNode介绍
namenode工作职责
1、管理各个datanode文件信息,文件名、文件多大、文件被切块、存贮位置信息,即管理元数据信息。
2. 基于RPC心跳机制控制集群中各个节点(datanode)的状态。
3. namenode存在单点故障问题,可以在起一个SecondaryNameNode用来保证元数据信息安全。
4. datanode挂掉后,数据丢失,因此需要控制datanode 的备份,默认3份,本机一份。
HDFS中DataNode介绍
- 负责数据的存储,读写和复制等操作
- datanode会定时向namenode报告当前存储的数据块的信息,后续会定时报告修改的信息
- datanode之间保持通信, 复制数据块
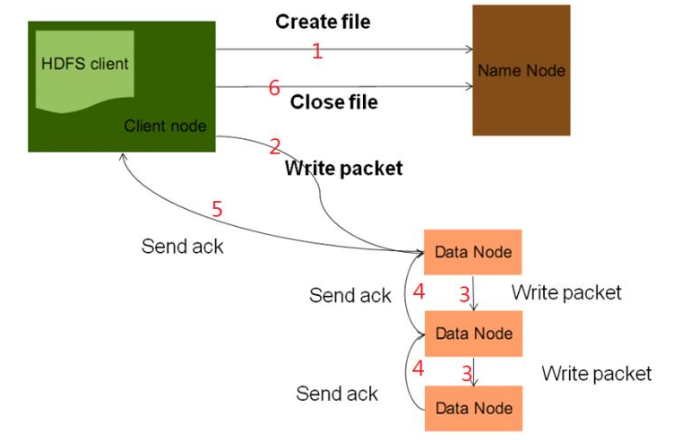
HDFS中NameNode和DataNode工作原理
读取原理图:

写原理图:
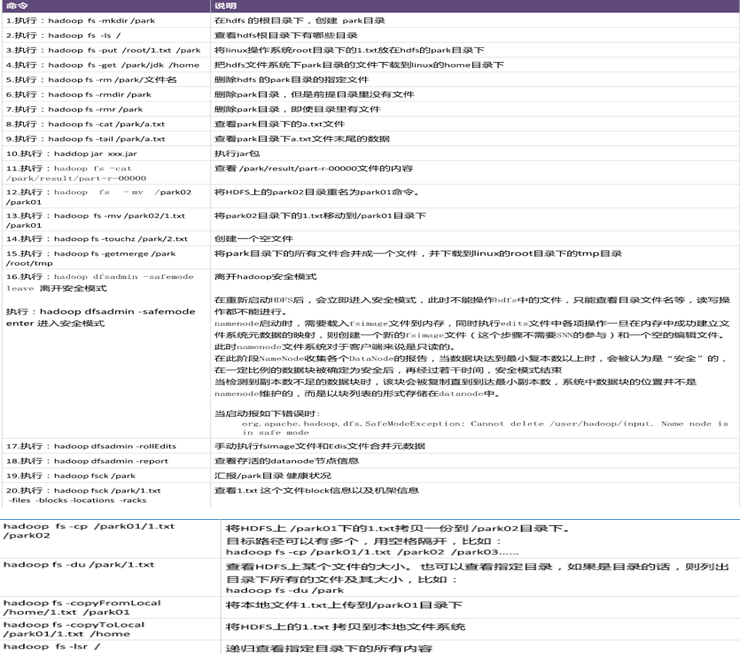
有关hadoop操作命令

 浙公网安备 33010602011771号
浙公网安备 33010602011771号