
scrapy抓取拉勾网职位信息(七)——数据存储(MongoDB,Mysql,本地CSV)
上一篇完成了随机UA和随机代理的设置,让爬虫能更稳定的运行,本篇将爬取好的数据进行存储,包括本地文件,关系型数据库(以Mysql为例),非关系型数据库(以MongoDB为例)。
实际上我们在编写爬虫rules规则的时候,做了很多的限定,而且没有对翻页进行处理,所以最终提取的信息数量比较少,经我的测试,总共只有4k多条职位。如果要进行数据分析的话,数量量必须要足够,因此我们先将爬虫规则进行修改。
修改lagou_c.py文件rules
rules = ( Rule(LinkExtractor(allow=r'zhaopin/.*/')), #首页职位列表 Rule(LinkExtractor(allow=r'gongsi/j\d+.html')), #公司职位列表 Rule(LinkExtractor(allow=r'jobs/list_.*',restrict_css='.menu-box')), #校园职位列表
Rule(LinkExtractor(allow=r'jobs/\d+.html'),callback='parse_item',follow=True), #详情页继续跟进,因为详情页包含其他的职位推荐,跟进后也是详情页 )
一、数据存储到MongoDB
如果没有MongoDB请先安装,并进行相应配置,并且启动MongoDB服务(出现connect network is unreachable一般都是没有开启服务造成的)
分析:要想把数据放进MongoDB,跟把大象放进冰箱是一样的道理。先连接数据库,把数据存进去,然后把连接关掉。
- 我们在pipelines.py文件下新建一个类,MongoPipeline,这个类包括三个函数,open_spider(),process_item(),close_spider()
import pymongo #第三方包pymongo,用来连接mongodb数据库并对其操作
class MongoPipeline(object): def open_spider(self,spider): #开启爬虫的时候连接数据库 passdef process_item(self,item,spider): #运行爬虫的时候把item数据插入到数据库中 passdef close_spider(self,spider): #爬虫关闭的时候把数据库的连接断开 pass
- 为了让代码更易扩展,我们不把mongodb的地址和名称写在这里,改为写在settings.py文件中,通过crawler来进行获取
class MongoPipeline(object): def __init__(self,mongo_uri,mongo_db): self.mongo_uri = mongo_uri #定义实例变量mongo_uri和mongo_db self.mongo_db = mongo_db @classmethod
'''
这个类方法就是为了使用crawler来获取全局settings中的MONGO_URI和MONGO_DB的值,并复制给mongo_uri和mongo_db
''' def from_crawler(cls,crawler): return cls( mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DB') ) def open_spider(self,spider): self.client = pymongo.MongoClient(self.mongo_uri) #与数据库建立连接 self.db = self.client[self.mongo_db] #打开数据库 def process_item(self,item,spider): self.db[item.collection].insert(dict(item)) #我这里直接获取item.collection字段,而collection我在items.py文件中赋值为’jobs‘,将item数据插入进去 return item #这个item返回才能被其他的中间件获取 def close_spider(self,spider): self.client.close() #关闭数据库连接
- 修改settings.py文件,增加MONGO_URI和MONGO_DB的定义,并且将MongoPipleline激活
ITEM_PIPELINES = { #'lagou.pipelines.LagouPipeline': 300, 'lagou.pipelines.MongoPipeline': 333, } MONGO_URI = 'localhost' MONGO_DB = 'lagou'
- 修改items.py文件,增加collection字段
import scrapy class LagouItem(scrapy.Item): collection = 'jobs' #其他字段不做修改
这样我们就建立了一个与本地MongoDB的连接,数据库名称是lagou,存入的表collection名称是jobs。我们现在可以运行程序。
一段时间后,使用可视话工具查看,就可以看到数据被存储进了MongoDB数据库。
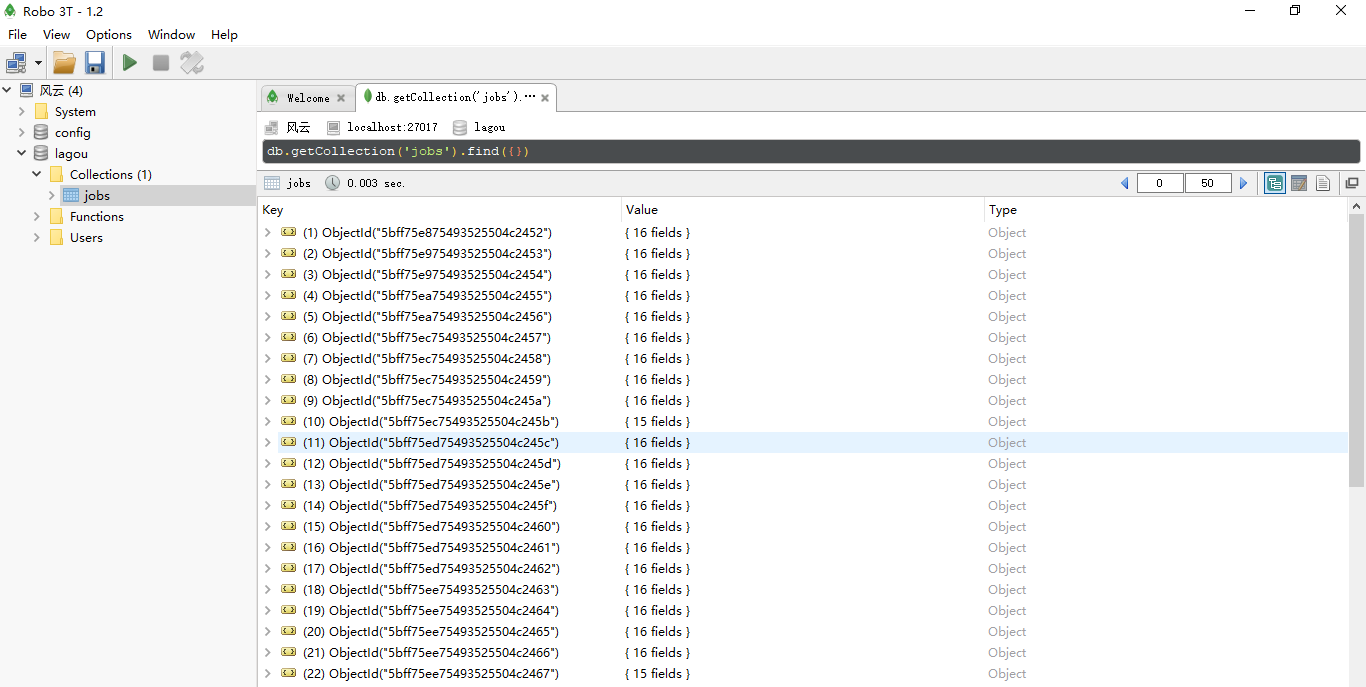
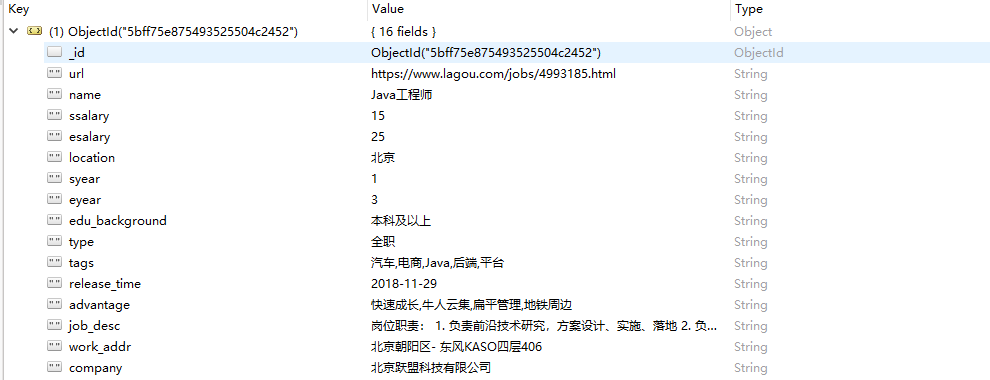
二、数据存储到Mysql
分析:思路与数据存储到MongoDB是一样的,只不过Mysql需要创建表,对各个字段进行定义
- 我们手动创建一个数据库
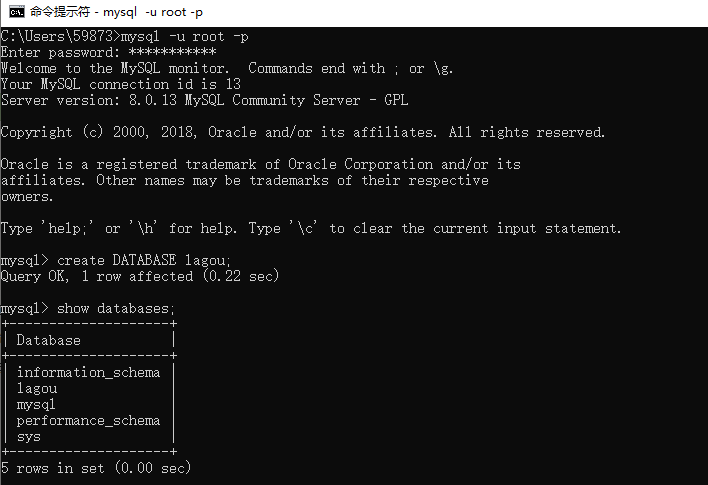
- 进入这个lagou数据库,并且建立一个表
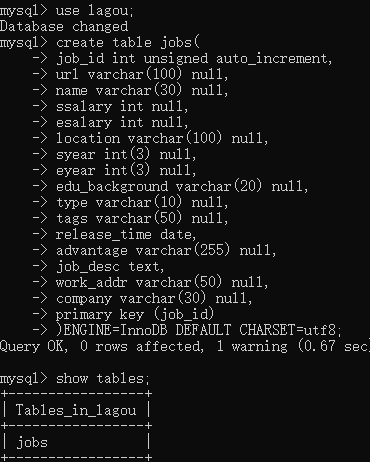
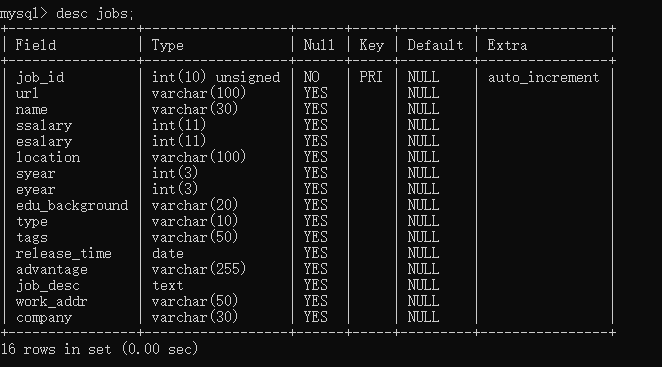
- 使用desc jobs;查看我们建立好的表。
- 开始写爬虫的代码,因为和mongodb的比较类似,我这里直接给出代码
import pymysql class MysqlPipeline(object): def __init__(self, host, database, user, password, port): self.host = host self.database = database self.user = user self.password = password self.port = port @classmethod def from_crawler(cls, crawler): return cls( host=crawler.settings.get('MYSQL_HOST'), database=crawler.settings.get('MYSQL_DATABASE'), user=crawler.settings.get('MYSQL_USER'), password=crawler.settings.get('MYSQL_PASSWORD'), port=crawler.settings.get('MYSQL_PORT'), ) def open_spider(self, spider): self.db = pymysql.connect(host=self.host, database=self.database, user=self.user, password=self.password, port=self.port, charset='utf8') self.cursor = self.db.cursor() def process_item(self, item, spider):
’‘’
这里直接使用值传入也可以,我这里直接把item生成一个字典传入
‘’‘ data = dict(item) keys = ','.join(data.keys()) values = ','.join(['%s'] * len(data)) #sql = 'insert into jobs (url,name,ssalary,esalary,location,syear,eyear,edu_background,type,tags,release_time,advantage,job_desc,work_addr,company) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)' sql = 'insert into jobs (%s) values (%s)' % (keys,values) try: #self.cursor.execute(sql, (item['url'],item['name'],item['ssalary'],item['esalary'],item['location'],item['syear'],item['eyear'],item['edu_background'],item['type'],item['tags'],item['release_time'],item['advantage'],item['job_desc'],item['work_addr'],item['company'])) self.cursor.execute(sql, tuple(data.values())) self.db.commit() except Exception as e: print(e) self.db.rollback() return item def close_spider(self, spider): self.db.close()
- settings.py文件编写,增加mysql地址和端口等相关字段,并且激活MysqlPipeline
ITEM_PIPELINES = { #'lagou.pipelines.LagouPipeline': 300, #'lagou.pipelines.MongoPipeline': 300, 'lagou.pipelines.MysqlPipeline': 300, } MYSQL_HOST = 'localhost' MYSQL_DATABASE = 'lagou' MYSQL_USER = 'root' MYSQL_PASSWORD = '123456' MYSQL_PORT = 3306
- 运行代码一段时间,用可视化工具打开看一下,发现数据已经存进来了

三、数据存储到本地csv文件
分析:因为已经对数据进行了处理,所以保存文件到本地不需要再到pipeline里面去进行。
使用命令行的方式:
- 运行爬虫时使用 scrapy crawl lagou_c -o lagou_jobs.csv,就可以保存一个名为lagou_jobs.csv文件到本地啦。
修改main.py文件的方式(本质上也是调用了命令行):
from scrapy import cmdline cmdline.execute('scrapy crawl lagou_c -o lagou_jobs.csv'.split())
这样我们就分别完成了MongoDB,Mysql以及本地的存储。


