
深度学习攻防对抗(JCAI-19 阿里巴巴人工智能对抗算法竞赛)
最近在参加IJCAI-19阿里巴巴人工智能对抗算法竞赛(点击了解),初赛刚刚结束,防御第23名,目标攻击和无目标攻击出了点小问题,成绩不太好都是50多名,由于找不到队友,只好一个人跟一群大佬PK,双拳难敌四手,差点自闭放弃比赛了。由于知道对抗攻击的人很少,于是抽空写篇博客,简单科普一下人工智能与信息安全的交叉前沿研究领域:深度学习攻防对抗。
然后简单介绍一下IJCAI-19 阿里巴巴人工智能对抗算法竞赛
目前,人脸识别、自动驾驶、刷脸支付、抓捕逃犯、美颜直播……人工智能与实体经济深度结合,彻底改变了我们的生活。神经网络和深度学习貌似强大无比,值得信赖。
但是神经网络也有它的缺陷,只要略施小计就能使最先进的深度学习模型指鹿为马,例如:通过细微地改动图片,就可以使神经网络识别出错。
深度学习攻防对抗的历史:
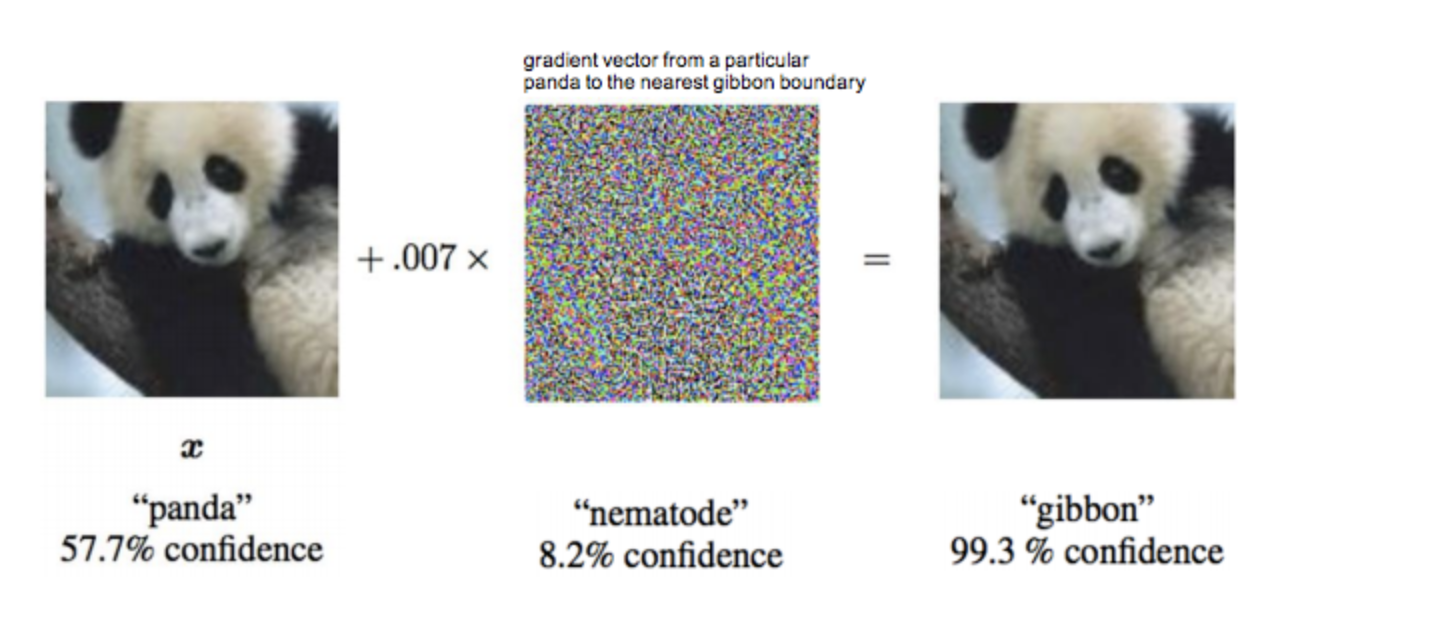
早在2015年,“生成对抗神经网络GAN之父”Ian Goodfellow在ICLR会议上展示了攻击神经网络欺骗成功的案例,在原版大熊猫图片中加入肉眼难以发现的干扰,生成对抗样本。就可以让Google训练的神经网络误认为它99.3%是长臂猿。
2017NIPS对抗样本攻防竞赛案例:阿尔卑斯山图片篡改后被神经网络误判为狗、河豚被误判为螃蟹。对抗样本不仅仅对图片和神经网络适用,对支持向量机、决策树等算法也同样有效。

在2018年,Ian Goodfellow在一篇论文中提出了首个可以欺骗人类的对抗样本。下图左图为猫咪原图,经过对抗样本干扰之后生成右图,对于右图,神经网络和人眼都认为是狗。不仅欺骗了神经网络,还能欺骗人眼。

这就是对机器学习模型的逃逸攻击,它能绕过深度学习的判别并生成欺骗结果。攻击者在原图上构造的修改被称为“对抗样本”。神经网络对抗样本生成与攻防是一个非常有趣且有前景的研究方向。
黑盒攻击与白盒攻击:
白盒攻击是在已经获取机器学习模型内部的所有信息和参数上进行攻击,令损失函数最大,直接计算得到对抗样本;黑盒攻击则是在神经网络结构为黑箱时,仅通过模型的输入和输出,逆推生成对抗样本。
攻击方法:
FGSM(Fast Gradient Sign Method):
Ian Goodfellow等人在年2014提出了一种生成对抗性例子的简单方法FGSM
![]()

与L- BFGS等复杂方法相比,该方法简单,计算效率高,但通常成功率较低。采用FGSM的方法,可使ImageNet模型识别错误率大约63%−69%。
I-FGSM(Iterative Fast Gradient Sign Method):
FGSM方法的一种扩展,通过简单的多步迭代FGSM,找到损失函数最大值,每一步迭代的步长会相应减小。
![]()

攻击方:
通过生成更具迷惑性的对抗样本,使现有的深度学习模型识别出错。
防御方:
训练更具鲁棒性的模型,使模型练就一双“火眼金睛”,正确识别对抗样本。
对抗训练:
在训练模型的时候就加上对抗样本,相当于让深度学习模型在做一份考试真题,等真正上战场的时候,碰到对抗样本也无所畏惧。
IJCAI-19 阿里巴巴人工智能对抗算法竞赛
比赛主要针对图像分类任务,包括模型攻击与模型防御。采用电商场景的图片识别任务进行攻防对抗。总共会公开110,000左右的商品图片,来自110个商品类目,每个类目大概1000个图片。
本次比赛包括以下三个任务:
- 无目标攻击: 生成对抗样本,使模型识别错误。
- 目标攻击: 生成对抗样本,使模型识别到指定的错误类别。
- 模型防御: 构建能够正确识别对抗样本的模型。
比赛为三组选手互相进行攻防,参赛选手既可以作为攻击方,对图片进行轻微扰动生成对抗样本,使模型识别错误;也可以作为防御方,通过构建一个更加鲁棒的模型,准确识别对抗样本。
关于比赛更多细节暂时不宜公开,比赛仍在进行中。。。
(待比赛结束后更新)

