图解分布式之:最终一致性,一致只会迟到,但绝不缺席
这篇文章我们继续聊分布式相关的内容。
提到分布式系统,就一定绕不开“一致性”,这次我们说说:最终一致性。
最终一致性是现在大部分高可用的分布式系统的核心思路。
估计有人对最终一致性不太熟,先来个简单介绍:
最终一致性指的是系统中的所有分散在不同节点的数据,经过一定时间后,最终能够达到符合业务定义的一致的状态。
划重点:
- 是数据一致性,不是事务一致性(ACID 是事务一致性);
- 存在条件:多个节点/系统;
- 不一致可能是暂时的,最终要一致(鬼知道“最终”是多久)
好,正文开始。
莫看江面平如镜,要看水底万丈深
最终一致性,一言以蔽之,过程松,结果紧。不管中间过程如何,结果必须符合业务需求,满足数据一致性的要求。
虽然,在实现中,有各种花样百出的方案,但是本质的思想都是一样的。我们现在就来忽略那些乱花迷眼的过程,仔细探讨下最终一致性的本质。
何事居穷道不穷,乱时还与净时同
在我刚入行不久的时候,能力有限,菜鸟一个,只能做一些小的功能模块。我印象最深的就是订单模块。
用户下单,订单模块收到下单请求后,执行对应的订单业务逻辑。最终,会把订单插入到订单表,并返回下单结果给用户。用户结算后,订单模块就会去根据支付情况去更新订单状态。

就这点事儿,对我这个技术渣渣来说,开始也着实费了一番手脚,不过最终也成了熟手,维护起这个模块来也驾轻就熟了。
这种简单的小日子过了一阵子后,新任务来了!
产品经理告诉我,数据审计部门想要我维护的这个订单模块在订单完成后,能及时分发一份订单数据给他们。他们提供了一个接口,让我直接传数据给他们。
两个问题出现了:
问题 1:用户等待时间变长
最简单的实现就是我更新完订单数据后,再顺序去调用数据审计部门给的接口,把订单数据传过去。
但是,从用户结算成功到更新订单状态这一系列的流程是同步的,假设这一系列流程所花费的时间是 n 毫秒。这就意味着,用户需要等待至少 n 毫秒。如果再加上传给数据审计部门的操作时间,假设为 m 毫秒,则整个用户就需要等待就 n+m 毫秒。
整个功能用户等待时间成本上升,体验下降。如下图:
问题 2:部分成功,部分失败
引入新的接口后,某些时候调用这个接口可能会失败,比如网络问题啊,验证问题啊,接口服务失败啊,很多原因。那么问题来了,新接口失败的时候怎么处理?
如果订单更新成功,传给数据审计部门的时候失败了,这种情况会让订单模块的后续处理变得很尴尬。
首先你不可能返回给客户端说你这次结算失败了,请求就没失败,你凭什么说人家失败了?其次,你又不能说这次业务上就是成功的,因为数据审计其实还挺重要的,它是业务逻辑的重要组成部分。
真是进退两难。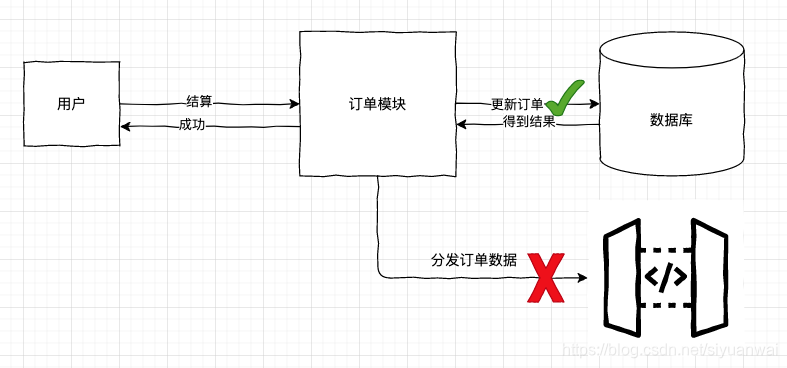
这两个问题的解决方案其中之一就是最终一致性。
我们以前谈到过 CAP,知道如果牺牲一定的一致性就可以保证分区容错性和可用性。而最终一致性则是不能保证同时让所有的数据当时都符合业务需求,但是我们能保证任何时候服务在内部出现问题的时候都是可对外服务的。
四哥我平时喜欢玩游戏,那我们就用一个淘宝买 Switch 的例子,来解释最终一致性:
如果你想在淘宝同时买一个 Switch 的数字版游戏和一台 Switch,那么你付完钱后,你就可以立刻得到数字版的游戏,但是,对于那台购买的 Switch,你就要等几天,等到快递投递到家才可以拿到。
来梳理下这个例子的细节:
- 首先淘宝上肯定得有个对顾客售卖 Switch 和数字游戏的商家去接受我们下的订单,并给你一个单号。
- 你得到了一个数字版游戏,但是没拿到 Switch。
- 你不知道这个商家背后 Switch 是怎么给你准备的,是不是中间他没货了还得跑别的商家串货,又或者没货等了两天才发给你(延迟发货可以给出别的理由,不再赘述)。这些不重要,重要的是你明确对方接单了他就要完成这笔单子。
- 你下单成功之后,你就有了保障,你最终会拿到你的 Switch,只是你可能不太肯定什么时候收到。
过了几天,你终于收到货了,恩,恭喜你成功入坑 Switch。
上面的例子就是我们说的最终一致性。但是,这里有个非常非常重要的东西还没有凸显出来,即到底是什么样的原因在驱使我们使用最终一致性?
答案就是数据的分发。
纸上得来终觉浅,绝知此事要躬行
为什么我们会出现需要最终一致性的情况呢?
因为我们需要把数据分发到不同的地方上去,而由于分发数据到不同的地方,就会导致,可能中间分发过程中出现分发成功或者失败的不一致情况,就需要最终一致性这种思路来处理这些情况。
恩,分发数据……OK,你想到了吧?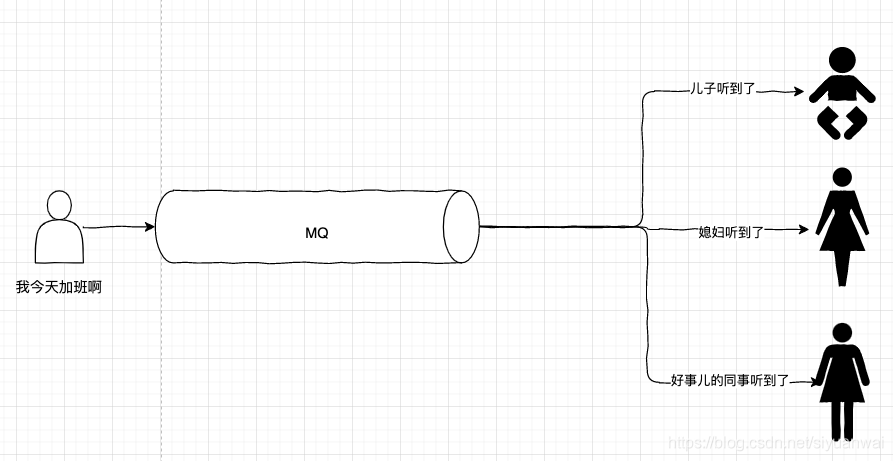
没错,通过 MQ 分发消息就可以处理分发数据的情况,而这正是最终一致性最常用的实现手段。
我们把要分发的数据打包成消息,再发送给 MQ 中间件。中间件会广播这些数据给所有想要收到这些消息的服务。这些收到消息的服务就根据自己的业务情况对数据进行独立的处理。
回到我们订单模块的那个例子,我们可以采用两种方式使用最终一致性。
- 先插入数据库,后发消息给数据审计
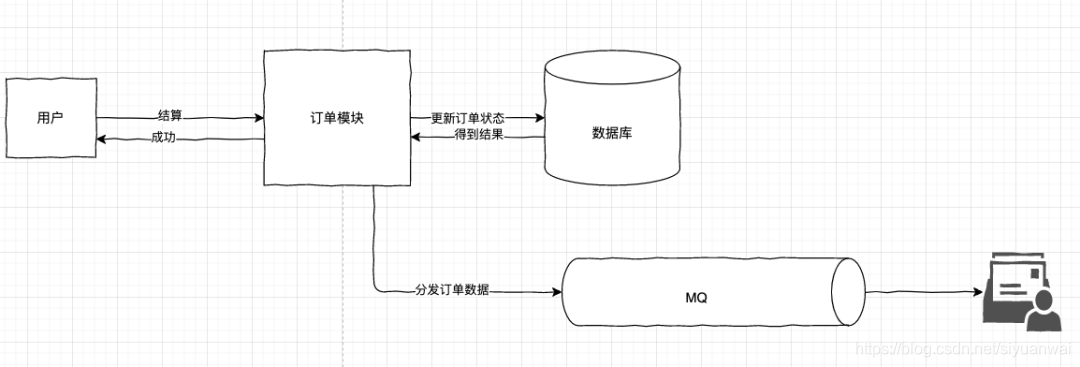
这个方式,订单模块先更新订单状态。然后,把订单数据打包成消息发送到 MQ 中,订单模块的任务就结束了。剩下的任务就是由数据审计部门根据自己的业务,从 MQ 中获取消息后进行对应的处理。
这个方法里,我们既保证数据库更新成功也保证数据被发送到了 MQ 中。最终,当数据审计部门收到消息并根据消息内容做完对应的处理后,则整体数据达到最终一致的状态。
- 只插入到 MQ 中

这个方式,订单模块直接收到请求后,将数据打包成消息放入到 MQ 中。
然后,再由订单模块自己和数据审计部门的服务分别从 MQ 中拿到对应的消息,再各自根据自己的业务逻辑该更新数据库的更新数据库,该走自己的审计的走自己的审计,最终达到一致的状态。
小荷才露尖尖角,早有蜻蜓立上头
在以上的例子中,我们描述了最终一致性的核心思路,不保证数据状态能实时满足业务要求,但是就像我们在线购物一样,我们能保证在间隔了一段时间窗口后肯定能满足业务需求。
然而,虽然说起来简单,但是世间上的事情又哪里那么容易呢?根据业务的不同,最终一致性分化出了多种实现思路。比如,
重试 + 逆向模式
在我们做支付时,需要记账,当记账不成功时,我们可能希望能尽可能的重试。当重试达到某种限制后,甚至我们还要通知上游系统去提供一个重试和取消接口,让下游能通知上游重发消息,或者先暂时取消操作。
补救任务模式
在我们做支付记账失败了,我们又尝试了重试 + 逆向模式取消了操作,那么此时就可以创建一个补救任务,等到后期可以保证记账成功的时候去执行这个任务。
异步消息模式
在我们做转账的时候,我们肯定是要保证 A 转出后 B 转入这种业务是强一致性的。然而,可能此时又需要跨服务。同时,我们还想尽量保证性能。那么,这个时候我们就可以先把本地对数据库的写操作和要跨服务的消息做成事务,然后,后期再根据消息被处理的状态做整体事务的提交和回滚。
可以看到,最终一致性的实现方式是多种多样的,但是,它始终逃不过一个核心,通过消息队列分发数据。在明白了这个根本原则后,以后我们理解各种各样的分布式事务,分布式共识等就会容易许多了。
完

 四猿外
四猿外
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· 展开说说关于C#中ORM框架的用法!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?