基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的个人防具检测系统(Python+PySide6界面+训练代码)
 开发个人防具检测系统对于提升个人安全具有至关重要的意义。本篇博客将详细阐述如何利用深度学习技术构建一个高效的个人防具检测系统,并附上完整的实现代码。本系统采用了先进的YOLOv8算法,同时对YOLOv7、YOLOv6、YOLOv5等其他版本进行了性能比较,包括mAP、F1 Score等关键性能指标。文章深入探讨了YOLOv8的工作原理,并提供了相应的Python实现代码、训练数据集,以及一个基于PySide6的图形用户界面。该系统能够准确地识别个人防具,并支持通过图片、图片文件夹、视频文件以及摄像头进行检测。功能丰富,包括柱状图分析、检测框标注、类别统计、可调整的置信度(Conf)和交并比(IOU)参数,以及结果的图形化展示。此外,还设计了一个基于SQLite的用户管理界面,支持模型的即时切换和用户界面的个性化定制。本文的目的是为深度学习的初学者提供一个实用的指南,完整的代码和数据集可在文末找到。
开发个人防具检测系统对于提升个人安全具有至关重要的意义。本篇博客将详细阐述如何利用深度学习技术构建一个高效的个人防具检测系统,并附上完整的实现代码。本系统采用了先进的YOLOv8算法,同时对YOLOv7、YOLOv6、YOLOv5等其他版本进行了性能比较,包括mAP、F1 Score等关键性能指标。文章深入探讨了YOLOv8的工作原理,并提供了相应的Python实现代码、训练数据集,以及一个基于PySide6的图形用户界面。该系统能够准确地识别个人防具,并支持通过图片、图片文件夹、视频文件以及摄像头进行检测。功能丰富,包括柱状图分析、检测框标注、类别统计、可调整的置信度(Conf)和交并比(IOU)参数,以及结果的图形化展示。此外,还设计了一个基于SQLite的用户管理界面,支持模型的即时切换和用户界面的个性化定制。本文的目的是为深度学习的初学者提供一个实用的指南,完整的代码和数据集可在文末找到。
摘要:开发个人防具检测系统对于提升个人安全具有至关重要的意义。本篇博客将详细阐述如何利用深度学习技术构建一个高效的个人防具检测系统,并附上完整的实现代码。本系统采用了先进的YOLOv8算法,同时对YOLOv7、YOLOv6、YOLOv5等其他版本进行了性能比较,包括mAP、F1 Score等关键性能指标。文章深入探讨了YOLOv8的工作原理,并提供了相应的Python实现代码、训练数据集,以及一个基于PySide6的图形用户界面。
该系统能够准确地识别个人防具,并支持通过图片、图片文件夹、视频文件以及摄像头进行检测。功能丰富,包括柱状图分析、检测框标注、类别统计、可调整的置信度(Conf)和交并比(IOU)参数,以及结果的图形化展示。此外,还设计了一个基于SQLite的用户管理界面,支持模型的即时切换和用户界面的个性化定制。本文的目的是为深度学习的初学者提供一个实用的指南,完整的代码和数据集可在文末找到。本文结构如下:
演示与介绍视频:https://www.bilibili.com/video/BV14y421v72R/
YOLOv8/v7/v6/v5项目合集:https://mbd.pub/o/bread/ZZyUmpdt
YOLOv8/v5项目完整资源:https://mbd.pub/o/bread/ZZubmp9x
YOLOv7项目完整资源:https://mbd.pub/o/bread/ZZucmp9v
YOLOv6项目完整资源:https://mbd.pub/o/bread/ZZyUk5xr
前言
在当今社会,随着工业化进程的加快和各种高风险行业的发展,个人安全防护已经成为了一个不可忽视的重要议题。个人防具,包括安全帽、安全带、防护眼镜等,是保障工人在高危环境中安全的必需品。然而,在实际操作过程中,由于人为疏忽或管理不善,防具的正确佩戴率并不理想,这直接影响到了工人的安全和生命健康。因此,如何有效地监控和提高个人防具的正确使用率,成为了一个亟待解决的问题。

随着计算机视觉和深度学习技术的快速发展,基于机器视觉的个人防具检测系统提供了一种新的解决方案。特别是,YOLO(You Only Look Once)系列算法作为一种先进的实时对象检测技术,因其高效和准确性而受到广泛关注。通过对YOLO算法的不断优化和改进,以及与其他最新类型算法的结合,研究人员已经能够设计出能够快速准确地识别个人是否正确佩戴防具的检测系统。这些进步不仅提高了检测的准确率和实时性,而且还能够适应各种复杂环境下的检测需求,极大地增强了个人防具检测系统的实用性和可靠性。
EfficientDet算法因其优秀的效率和准确性,在个人防具检测中受到了关注。EfficientDet通过采用复合缩放方法(同时对网络的宽度、深度和图像分辨率进行缩放)和一种基于注意力的特征融合技术,显著提升了模型的检测性能。这种架构使得EfficientDet能在较低的计算复杂度下达到高准确性,特别适用于需要实时检测的场景[1]。
FPN (Feature Pyramid Networks) 在个人防具检测领域也得到了广泛应用。FPN通过构建一个多尺度的特征金字塔,能够有效地检测不同尺寸的目标。在个人防具检测中,FPN能够帮助模型更好地识别从远处到近处、不同大小的防护装备,如安全帽、护目镜等。该技术通过融合不同层次的特征来改善检测效果,尤其是在处理小目标时的性能[2]。
Cascade R-CNN 也在这一领域展现了其强大的检测能力。Cascade R-CNN通过构建一个多阶段的检测框架,逐步提高检测的精确度。每个阶段都会对前一个阶段的检测结果进行精细调整,从而逐步提高整体的检测准确性。这种方法特别适合于那些对检测精度要求极高的应用场景,如精确检测工人是否佩戴了所有必需的个人防护装备[3]。
CenterNet,作为一个无锚点(anchor-free)的检测框架,通过直接预测物体的中心点及其尺寸来检测目标,避免了传统检测算法中锚点框架的复杂性和局限性。CenterNet的简洁性和效率使其在个人防具检测任务中表现出色,尤其是在处理密集场景和遮挡问题时[4]。
Swin Transformer,作为一种基于Transformer的视觉模型,近期也被应用于个人防具检测领域。Swin Transformer通过引入一个层次化的Transformer结构,能够有效处理不同尺寸的图像特征,并支持多尺度的特征表示。这使得Swin Transformer在处理复杂的视觉任务时,如个人防具检测,能够提供更加精确和鲁棒的结果[5]。
本博客所做的工作是基于YOLOv8算法构建一个个人防具检测系统,展示系统的界面效果,详细阐述其算法原理,提供代码实现,以及分享该系统的实现过程。希望本博客的分享能给予读者一定的启示,推动更多的相关研究。本文的主要贡献如下:
- 采用最新的YOLOv8算法进行个人防具检测:我们不仅介绍了如何利用YOLOv8进行高效精准的个人防具检测,还通过与YOLOv7、YOLOv6、YOLOv5等早期版本的详细比较,展示了YOLOv8在个人防具检测方面的明显优势。这一部分的详细阐述为相关领域的研究者和从业者提供了新的研究思路和实践手段,推动了个人防具检测技术的发展。
- 开发友好的用户界面:通过利用Python的PySide6库,本文展示了如何开发一个既美观又用户友好的个人防具检测系统界面。这一创新不仅使得个人防具检测过程更加直观便捷,还促进了YOLOv8算法的广泛应用,推动了个人防具检测技术的实际部署和应用。
- 设计登录管理功能:本文还介绍了如何在系统中集成登录管理功能,这一设计旨在提高系统的安全性,同时为未来引入更多个性化功能铺平了道路,体现了系统设计的前瞻性和实用性。
- 对YOLOv8算法进行深入研究:通过对YOLOv8算法性能的全面评估,包括精确度、召回率等关键指标的分析,本文提供了对YOLOv8算法深度理解的宝贵见解。此外,还分析了模型在不同环境和条件下的表现,为算法的进一步优化和改进奠定了基础。
- 提供完整的数据集和代码资源包:为了促进读者的理解和应用,本文提供了完整的数据集和代码资源包,包括用于训练和测试的详细数据集以及实现个人防具检测系统的完整代码。这些资源的分享,不仅使读者能够复现实验结果,还为进一步的研究和开发提供了坚实的基础。
1. 数据集介绍
在个人防具检测系统的开发过程中,构建一个高质量的数据集是实现高效检测模型的基石。我们的数据集包含了4713幅图像,其中4287幅用于训练,385幅用于验证,以及41幅用于测试。这样的数据划分确保了模型可以在一个丰富的训练集上学习,同时在独立的验证集和测试集上公平地评估其性能。

在预处理过程中,我们对图像进行了自动方向校正,并剥离了EXIF方向信息,以确保图像在输入模型前具有统一的方向。为了满足YOLOv8算法的输入需求,所有图像均被重新缩放至640x640像素的固定尺寸,采用拉伸方法以符合模型的规定输入格式。尽管这种方法可能在一定程度上改变了图像的原始比例,但它为算法提供了标准化的输入,有助于减少算法处理不同尺寸图像所需的计算资源,并提高了处理速度。
通过深入分析数据集分布的可视化图表,我们可以看出,一些类别如手套和头盔的实例数量相对较多,这可能是因为在大多数工业环境中,这些防具是最常见和必需的。相比之下,面罩和无背心的实例较少,反映出现实场景中这些防具出现频率的差异。此外,标注框的分布密度图显示了大多数对象都集中在图像的中心区域,这对于设计中心对齐的目标检测算法极为重要。

图像的注释包含了多个类别的个人防具,包括手套、头盔、无头盔、背心、面罩、无手套、无面罩和无背心等类别。这种多类别的设置不仅使模型能够识别特定的个人防具,还能够检测出缺失的防具,这对于完整的安全合规性检查至关重要。博主使用的类别代码如下:
Chinese_name = { "Gloves": "手套", "Helmet": "头盔", "Non-Helmet": "无头盔","Person": "人",
"Vest": "背心", "mask": "口罩","non_gloves": "无手套","non_mask": "无口罩", "non_vest": "无背心"}
在标注框大小的分布上,我们注意到存在一定范围的大小变化,这表明模型需要能够检测各种尺寸的个人防具。大小分布图也揭示了防具对象的高度和宽度比率多样性,表明我们的数据集不仅包括各种类型的个人防具,还包括不同角度和距离拍摄的防具,从而为模型提供了更全面的学习机会。
总的来说,我们的数据集通过多角度、多尺寸和多类别的细致标注,为个人防具检测技术的发展提供了丰富的训练材料。这些精确标注的图像数据对于培养能够准确识别和分类各种个人防具的深度学习模型至关重要,能够大大提高工作场所的安全监测自动化水平。
2. 系统界面效果
系统以PySide6作为GUI库,提供了一套直观且友好的用户界面。下面,我将详细介绍各个主要界面的功能和设计。
(1)系统提供了基于SQLite的注册登录管理功能。用户在首次使用时需要通过注册界面进行注册,输入用户名和密码后,系统会将这些信息存储在SQLite数据库中。注册成功后,用户可以通过登录界面输入用户名和密码进行登录。这个设计可以确保系统的安全性,也为后续添加更多个性化功能提供了可能性。

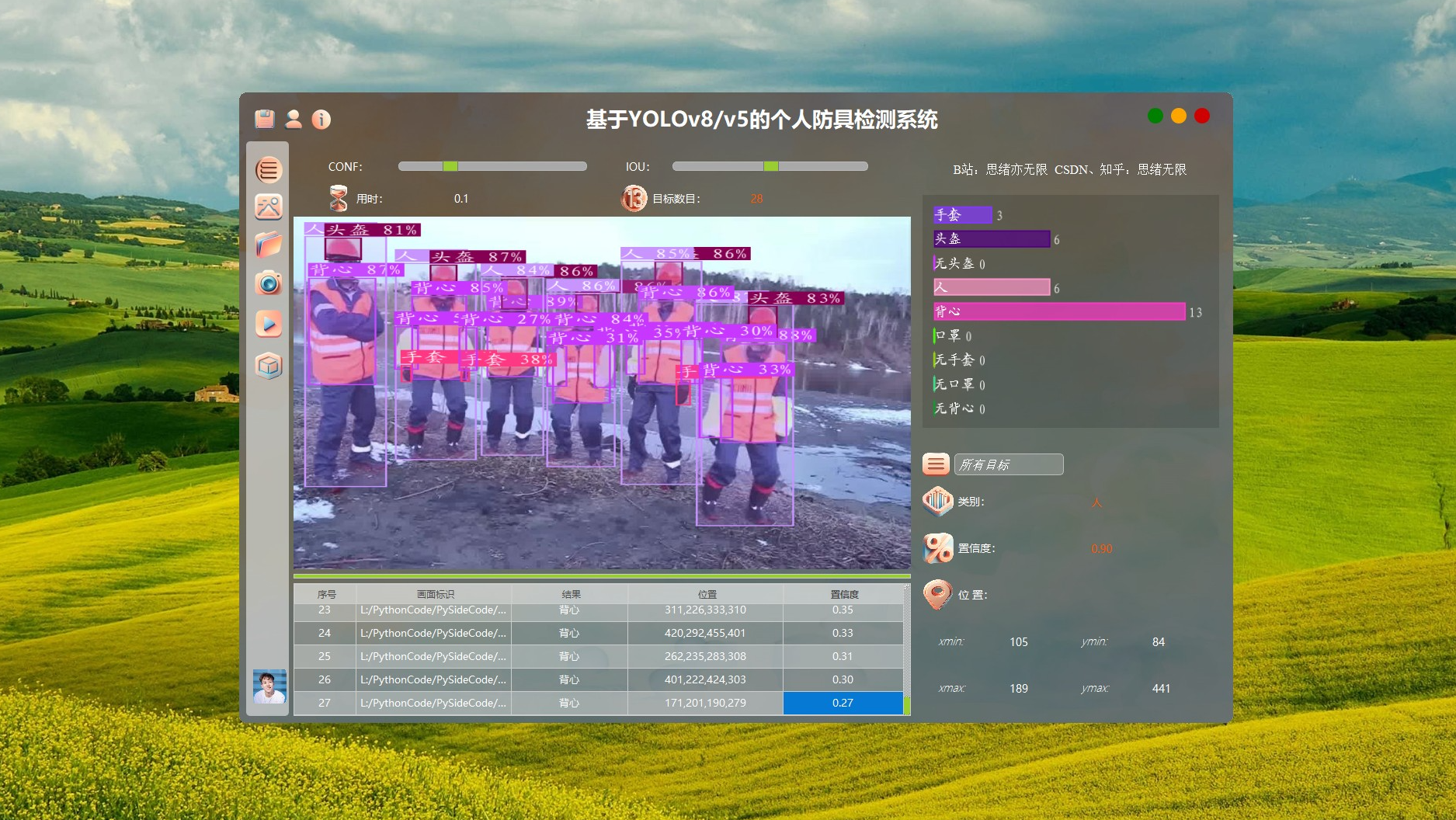
(2)在主界面上,系统提供了支持图片、视频、实时摄像头和批量文件输入的功能。用户可以通过点击相应的按钮,选择要进行个人防具检测的图片或视频,或者启动摄像头进行实时检测。在进行检测时,系统会实时显示检测结果,并将检测记录存储在数据库中。

(3)此外,系统还提供了一键更换YOLOv8模型的功能。用户可以通过点击界面上的"更换模型"按钮,选择不同的YOLOv8模型进行检测。与此同时,系统附带的数据集也可以用于重新训练模型,以满足用户在不同场景下的检测需求。

(4)为了提供更个性化的使用体验,这里系统支持界面修改,用户可以自定义图标、文字等界面元素。例如,用户可以根据自己的喜好,选择不同风格的图标,也可以修改界面的文字描述。

3. YOLOv8算法原理
YOLOv8模型作为目前最新一代的目标检测模型,继承了YOLO系列的核心设计理念,同时引入了创新的架构和技术以提高性能和效率。YOLO(You Only Look Once)系列自从推出以来,就以其高速的检测速度和良好的实时性能赢得了广泛的认可。
YOLOv8模型的基础是将目标检测任务作为一个回归问题来处理,模型仅通过单次前向传播即可预测出图像中各个目标的位置和类别。这与传统的两步检测方法不同,后者通常先生成一系列潜在目标的区域建议,然后再对这些区域进行分类和边界框回归。YOLOv8简化了这一流程,使得检测任务在速度和效率上有了显著提升。
YOLOv8的Backbone,即特征提取网络,采用了CSP结构。CSP,即Cross Stage Partial networks,是一种高效的网络设计,它通过部分地跨阶段连接以提高信息流的效率,并减少计算资源的消耗,同时保持或提高模型的特征提取能力。CSP结构在减少计算复杂度的同时,提高了模型对特征的识别能力,对于提升模型的准确性和速度提供了强有力的支持。

Neck部分,YOLOv8采用了SPP(Spatial Pyramid Pooling)和CFP(Coarse-to-fine)结构,这些结构能够有效地聚合多尺度的特征,并保证检测器在不同尺寸的目标上都能保持高效和准确。SPP层能够在不同尺寸的感受野中提取特征,增加了模型对不同尺寸目标的识别能力。而CFP结构则进一步细化了特征,使得模型能够在尽可能多的尺寸层面上进行准确的预测。
此外,YOLOv8在模型设计阶段引入了AutoML技术,即自动化机器学习技术,这一策略通过自动化的网络架构搜索(Neural Architecture Search, NAS)来优化模型架构。这一进程利用机器学习算法,如Cloud TPUs或者GPUs等强大的计算资源,来进行极其广泛的网络结构搜索,从而找到在特定任务上性能最优的模型架构。
YOLOv8在训练和预测过程中,利用先进的损失函数对模型进行优化,这包括对位置误差、类别误差以及置信度误差的精确控制,以此确保模型能够精确地定位目标并准确分类。损失函数的设计直接关系到模型训练的有效性,对于模型性能有着重要的影响。
最终,YOLOv8在保证实时性和准确性的同时,也考虑到了在资源有限的设备上的部署需求。通过精心设计的网络结构以及采用的训练技巧,YOLOv8成功地减少了模型大小,同时提高了推断速度和精确度,这使得YOLOv8能够在实时的应用场景中实现高效和精确的目标检测。
4. 代码简介
在本节中,我们将详细介绍如何使用YOLOv8进行个人防具检测的代码实现。代码主要分为两部分:模型预测和模型训练。
4.1 模型预测
在模型预测部分,首先导入了OpenCV库和YOLO模型。OpenCV库是一个开源的计算机视觉和机器学习软件库,包含了众多的视觉处理函数,使用它来读取和处理图像。YOLO模型则是要用到的目标检测模型。
import cv2
from ultralytics import YOLO
接着,加载自行训练好的YOLO模型。这个模型是在大量的图像上预训练得到的,可以直接用于目标检测任务。
model.load_model(abs_path("weights/best-yolov8n.pt", path_type="current"))
然后,使用OpenCV读取了一个图像文件,这个图像文件作为要进行目标检测的图像输入。
img_path = abs_path("test_media/1.jpg")
image = cv_imread(img_path)
在读取了图像文件之后,将图像大小调整为850x500,并对图像进行预处理,就可以使用模型进行预测了。
image = cv2.resize(image, (850, 500))
pre_img = model.preprocess(image)
pred, superimposed_img = model.predict(pre_img)

4.2 模型训练
在本博客中,我们将深入探索使用YOLOv8构建高效的个人防具检测系统。本节将分步介绍如何通过代码来实现这一目标,讲解每一段代码的功能与它在整个训练过程中的作用。
我们首先引入了torch库,它是PyTorch框架的核心,用于深度学习模型的构建和训练。os和yaml用于文件操作和配置文件的解析。通过ultralytics库中的YOLO类,我们可以访问预训练的YOLOv8模型,而QtFusion.path的abs_path函数则帮助我们获得操作系统无关的文件路径。最后,device变量确定了模型训练的执行环境,优先选用GPU。
import os
import torch
import yaml
from ultralytics import YOLO # 导入YOLO模型
from QtFusion.path import abs_path
device = "cuda:0" if torch.cuda.is_available() else "cpu"
接着,我们设定了一些基本的训练参数,如工作进程数和批次大小。这些参数会影响数据加载和模型训练的速度。abs_path保证了无论在哪种操作系统上,我们都能够准确地访问数据集的配置文件。通过将路径中的分隔符替换为UNIX风格的/,我们确保了路径的一致性,避免了跨平台文件路径的问题。
workers = 1
batch = 8
data_name = "PPEMonitor"
data_path = abs_path(f'datasets/{data_name}/{data_name}.yaml', path_type='current') # 数据集的yaml的绝对路径
unix_style_path = data_path.replace(os.sep, '/')
# 获取目录路径
directory_path = os.path.dirname(unix_style_path)')
在这里,我们使用with语句安全地打开配置文件,利用yaml库将其内容加载为一个字典对象。如果配置数据中包含path键,我们就会更新它的值为当前目录的路径。这一步确保了模型在训练时能够正确找到数据。最后,我们将改动的数据写回配置文件,完成数据集路径的更新。
# 读取YAML文件,保持原有顺序
with open(data_path, 'r') as file:
data = yaml.load(file, Loader=yaml.FullLoader)
# 修改path项
if 'path' in data:
data['path'] = directory_path
# 将修改后的数据写回YAML文件
with open(data_path, 'w') as file:
yaml.safe_dump(data, file, sort_keys=False)
接下来是模型的加载和训练过程。我们使用YOLO类创建一个模型实例,并加载预训练权重。最后,我们调用model.train()方法来开始训练过程,指定了数据路径、设备、工作进程数、图像大小、训练周期和批次大小等参数。我们为训练任务指定了一个唯一的名称,以便于区分不同的训练实验。
model = YOLO(abs_path('./weights/yolov5nu.pt', path_type='current'), task='detect') # 加载预训练的YOLOv8模型
# model = YOLO('./weights/yolov5.yaml', task='detect').load('./weights/yolov5nu.pt') # 加载预训练的YOLOv8模型
# Training.
results = model.train( # 开始训练模型
data=data_path, # 指定训练数据的配置文件路径
device=device, # 自动选择进行训练
workers=workers, # 指定使用2个工作进程加载数据
imgsz=640, # 指定输入图像的大小为640x640
epochs=120, # 指定训练100个epoch
batch=batch, # 指定每个批次的大小为8
name='train_v5_' + data_name # 指定训练任务的名称
)
model = YOLO(abs_path('./weights/yolov8n.pt'), task='detect') # 加载预训练的YOLOv8模型
results2 = model.train( # 开始训练模型
data=data_path, # 指定训练数据的配置文件路径
device=device, # 自动选择进行训练
workers=workers, # 指定使用2个工作进程加载数据
imgsz=640, # 指定输入图像的大小为640x640
epochs=120, # 指定训练100个epoch
batch=batch, # 指定每个批次的大小为8
name='train_v8_' + data_name # 指定训练任务的名称
)
在深度学习模型的训练过程中,损失函数的变化趋势是评估模型性能的重要指标之一。从提供的图像中,我们可以对YOLOv8模型在个人防具检测任务上的训练过程进行详细的分析。
我们可以观察到train/box_loss、train/cls_loss、和train/df1_loss这三个损失指标随着迭代次数的增加而稳定下降,这表明模型在识别物体的边框、类别及对应的特征方面正在逐渐提升其精确性。同样,val/box_loss、val/cls_loss和val/df1_loss的验证损失也表现出类似的下降趋势,这表明模型在验证数据上的表现也在提升,并且模型没有出现过拟合的情况,因为验证损失的下降表明模型具有良好的泛化能力。
接下来,我们分析效果评估指标,包括精确度(metrics/precision)和召回率(metrics/recall),以及平均精度(metrics/mAP50和metrics/mAP50-95)。这些指标为我们提供了模型预测质量的量化评估。从图表上看,随着训练的进行,模型的精确度和召回率逐渐趋于稳定,在高水平上波动。精确度表明了模型预测为正类的样本中有多少是正确的,而召回率则表示所有正类样本中有多少被模型正确预测。在本次训练中,精确度和召回率都表现出了很好的性能,说明模型能够较为准确地识别目标,并且漏检较少。

同时,mAP(特别是metrics/mAP50-95)作为一个综合评估指标,它在多个IoU阈值下考察了模型的性能。我们看到mAP的值随着训练逐渐升高并趋于平稳,这表示模型在不同程度的检测难度上均有均衡的表现,而且对于目标检测任务的鲁棒性有显著提升。
在深度学习模型的评估过程中,F1分数是一个非常重要的指标,它在精确度(Precision)和召回率(Recall)之间提供了一个平衡,特别是在类别分布不均的数据集中。这里我们看到的是一个F1与置信度阈值(Confidence)的关系曲线,通过这个曲线图,我们可以对模型的性能进行深入的分析。

我们可以看到,当置信度阈值增加时,F1得分先增加后减少,呈现出一个类似山峰的形状。这是因为当置信度阈值较低时,模型倾向于标记更多的正样本,这可能包括一些错误标记,导致精确率降低。而当置信度阈值提高时,模型则变得更加保守,只标记那些最有可能是正样本的候选区域,从而提高精确率,但召回率可能会下降。因此,存在一个最佳的置信度阈值,能平衡模型的精确率和召回率,达到最高的F1得分。
在图中,各个颜色代表不同的类别,曲线越接近顶端,说明模型对该类别的检测效果越好。从图中可以看出,某些类别如“Gloves”(手套)和“Helmet”(头盔)的F1得分较高,这表明模型在检测这些类别的物品上性能良好。相对地,“non_vest”(非背心)类别的F1得分较低,这可能意味着模型在识别非背心物品方面存在一些困难。值得注意的是,所有类别的综合得分为0.82,在置信度为0.345时达到。这个结果表明,当模型的置信度阈值设置为0.345时,我们可以获得对所有类别的最优平均检测性能。
通过详细分析这些曲线,我们可以为每个类别调整模型的置信度阈值,以最大化每个特定类别的F1得分。此外,对于那些性能不佳的类别,我们可能需要收集更多的数据或者改进模型的训练过程,以提高模型对这些类别的识别能力。
4.3 YOLOv5、YOLOv6、YOLOv7和YOLOv8对比
(1)实验设计:
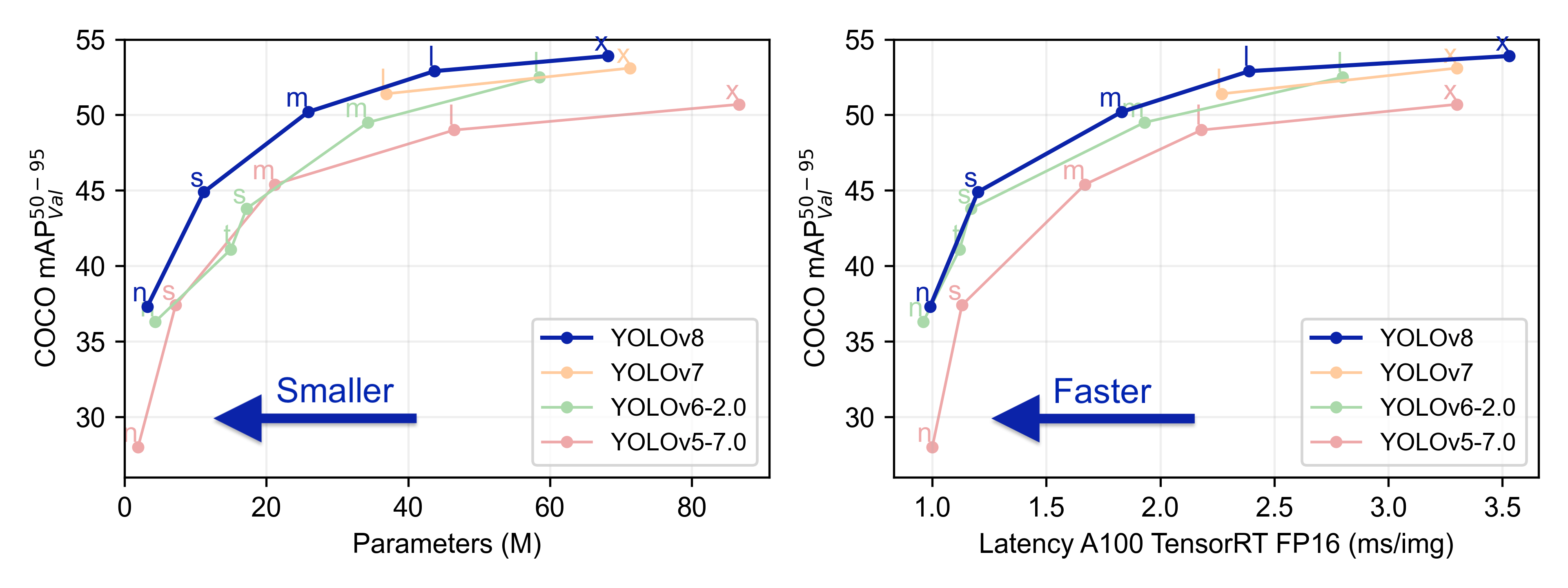
本实验旨在评估和比较YOLOv5、YOLOv6、YOLOv7和YOLOv8几种模型在个人防具检测任务上的性能。为了实现这一目标,博主分别使用使用相同的数据集训练和测试了这四个模型,从而可以进行直接的性能比较。本文将比较分析四种模型,旨在揭示每种模型的优缺点,探讨它们在工业环境中实际应用的场景选择。
| 模型 | 图像大小 (像素) | mAPval 50-95 | CPU ONNX 速度 (毫秒) | A100 TensorRT 速度 (毫秒) | 参数数量 (百万) | FLOPs (十亿) |
|---|---|---|---|---|---|---|
| YOLOv5nu | 640 | 34.3 | 73.6 | 1.06 | 2.6 | 7.7 |
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv6N | 640 | 37.5 | - | - | 4.7 | 11.4 |
| YOLOv7-tiny | 640 | 37.4 | - | - | 6.01 | 13.1 |
(2)度量指标:
- F1-Score:F1-Score是精确率(Precision)和召回率(Recall)的调和平均值。精确率是指模型正确识别的正例与所有识别为正例的案例之比,而召回率是指模型正确识别的正例与所有实际正例之比。F1-Score对于不平衡的数据集或者需要同时考虑精确率和召回率的任务特别重要。
- mAP(Mean Average Precision):mAP是衡量模型在多个类别上平均检测准确度的指标。它计算了模型在所有类别上的平均精度,是目标检测领域中常用的性能度量。
| 名称 | YOLOv5nu | YOLOv6n | YOLOv7-tiny | YOLOv8n |
|---|---|---|---|---|
| mAP | 0.855 | 0.691 | 0.795 | 0.851 |
| F1-Score | 0.83 | 0.67 | 0.71 | 0.82 |
(3)实验结果分析:
在深度学习领域,持续的算法迭代和更新是提升模型性能的关键途径。我们通过在相同的数据集上实施一系列实验,旨在比较和评估不同版本的YOLO模型——包括YOLOv5nu、YOLOv6n、YOLOv7-tiny以及YOLOv8n——在个人防具检测任务上的性能。实验的设计和目的是为了明确各版本模型在准确性和检测效率上的差异,以便为实际应用提供更具指导性的见解。
首先,让我们来看mAP值。mAP是一种衡量目标检测模型整体精度的重要指标,它考虑了不同阈值下模型的精度和召回率。在我们的实验中,YOLOv5nu以0.855的mAP值领先,紧随其后的是YOLOv8n,其mAP值为0.851。这两个版本的YOLO算法展现了出色的整体性能,特别是在处理个人防具检测这类复杂任务时。YOLOv5nu微弱的领先可能归因于其在特定数据集上的更优泛化能力或者可能是更加精细的模型调优。YOLOv8n的表现紧随其后,这也体现了YOLO系列算法随着版本更新持续改进的趋势。

相比之下,YOLOv6n的表现相对较差,mAP值为0.691,这可能是由于网络结构或是训练策略上的差异导致的。YOLOv7-tiny作为轻量化的版本,其mAP为0.795,表现出了可观的性能,尤其是在可能的资源受限的部署场景下。尽管它没有达到YOLOv5nu和YOLOv8n的水平,但考虑到其较小的模型尺寸和计算需求,这仍然是一个十分不错的结果。
转向F1-Score,这是一个单一指标,结合了精确率和召回率,适用于那些需要平衡假阳性和假阴性检测的场景。在我们的实验中,YOLOv5nu同样以0.83的F1-Score领先,其次是YOLOv8n,得分为0.82。这两个模型的高F1得分进一步证实了它们在个人防具检测方面的可靠性和准确性。尽管YOLOv6n和YOLOv7-tiny的F1得分分别为0.67和0.71,相对较低,但这些得分在考虑到模型复杂度和运行速度的情况下仍然有其应用价值。特别是在需要快速检测并且资源有限的移动设备上,YOLOv7-tiny可能是一个更实用的选择。
总体来说,通过这一系列的实验,我们可以观察到YOLO算法随版本更新而逐步提升的趋势,尤其是在F1得分和mAP这两个关键性能指标上。每个版本的YOLO算法都有其独特的优势和适用场景,而选择哪个版本将取决于特定任务的需求、资源可用性以及性能要求。
4.4 代码实现
在本篇博客中,我们将深入解析如何利用YOLOv8模型结合Qt框架进行实时的个人防具检测。本段内容旨在为开发者们提供一个实例,展示如何通过集成深度学习模型和图形界面,创建一个用户友好的实时视频监控系统。
(1)引入必要的库
首先,我们从导入基础库开始,包括用于图像处理的OpenCV库,和PySide6库,它是Qt应用程序框架的Python接口,非常适用于开发跨平台的桌面应用程序。这些库的引入为我们处理视频数据、显示结果以及构建用户界面提供了基础。
import sys # 导入sys模块,用于处理Python运行时环境的一些操作
import time # 导入time模块,用于处理时间相关的操作
import cv2 # 导入OpenCV库,用于处理图像和视频
from QtFusion.path import abs_path
from QtFusion.config import QF_Config
from QtFusion.widgets import QMainWindow # 从QtFusion库中导入FBaseWindow类,用于创建主窗口
from QtFusion.handlers import MediaHandler # 从QtFusion库中导入MediaHandler类,用于处理媒体数据
from QtFusion.utils import drawRectBox # 从QtFusion库中导入drawRectBox函数,用于在图像上绘制矩形框
from QtFusion.utils import get_cls_color # 从QtFusion库中导入get_cls_color函数,用于获取类别颜色
from PySide6 import QtWidgets, QtCore # 导入PySide6库的QtWidgets和QtCore模块,用于创建GUI和处理Qt的核心功能
from YOLOv8Model import YOLOv8Detector # 从YOLOv8Model模块中导入YOLOv8Detector类,用于进行YOLOv8物体检测
from datasets.PPEMonitor.label_name import Label_list
QF_Config.set_verbose(False)
(2)设置主窗口
在引入必要的库后,我们定义了MainWindow类,这是我们应用程序的核心界面。MainWindow继承自Qt的QMainWindow类,我们对其进行扩展以适应我们的需求。这个类的实例化过程中,我们设置了窗口的大小和显示标签,确保了视频流的图像能够在窗口中恰当地显示。
class MainWindow(QMainWindow): # 定义MainWindow类,继承自FBaseWindow类
def __init__(self): # 定义构造函数
super().__init__() # 调用父类的构造函数
self.resize(640, 640) # 设置窗口的大小为850x500
self.label = QtWidgets.QLabel(self) # 创建一个QLabel对象,用于显示图像
self.label.setGeometry(0, 0, 640, 640) # 设置QLabel的位置和大小
def keyPressEvent(self, event): # 定义键盘按键事件处理函数
if event.key() == QtCore.Qt.Key.Key_Q: # 如果按下的是Q键
self.close() # 关闭窗口
(3)图像帧处理
接下来,我们关注于视频流的处理。我们定义了frame_process函数,它负责处理视频帧,执行必要的预处理,并将帧传递给YOLOv8模型进行目标检测。我们使用OpenCV来调整视频帧的尺寸,并将其转换成模型所需的格式。同时,我们记录并打印出处理每帧所花费的时间,这对于评估系统性能至关重要。在预处理之后,我们调用模型的predict方法进行实时检测,并对检测结果进行后处理。然后,使用自定义的drawRectBox函数在检测到的个人防具上绘制边界框,通过get_cls_color为不同的类别分配颜色。
def frame_process(image): # 定义帧处理函数,用于处理每一帧图像
image = cv2.resize(image, (850, 500)) # 将图像的大小调整为850x500
pre_img = model.preprocess(image) # 对图像进行预处理
t1 = time.time() # 获取当前时间
pred = model.predict(pre_img) # 使用模型进行预测
t2 = time.time() # 获取当前时间
use_time = t2 - t1 # 计算预测所花费的时间
print("推理时间: %.2f" % use_time) # 打印预测所花费的时间
det = pred[0] # 获取预测结果
# 如果有检测信息则进入
if det is not None and len(det):
det_info = model.postprocess(pred) # 对预测结果进行后处理
for info in det_info: # 遍历检测信息
name, bbox, conf, cls_id = info['class_name'], info['bbox'], info['score'], info[
'class_id'] # 获取类别名称、边界框、置信度和类别ID
label = '%s %.0f%%' % (name, conf * 100) # 创建标签,包含类别名称和置信度
# 画出检测到的目标物
image = drawRectBox(image, bbox, alpha=0.2, addText=label, color=colors[cls_id]) # 在图像上绘制边界框和标签
window.dispImage(window.label, image) # 在窗口的label上显示图像
(4)初始化检测模型和设备
最后,整个应用程序是通过Qt的事件循环驱动的。我们创建了MainWindow和MediaHandler实例,用于处理视频流。MediaHandler将新帧的处理信号与frame_process函数连接起来,而MainWindow则负责将处理后的图像显示出来。
cls_name = Label_list # 定义类名列表
model = YOLOv8Detector() # 创建YOLOv8Detector对象
model.load_model(abs_path("weights/best-yolov8n.pt", path_type="current")) # 加载预训练的YOLOv8模型
colors = get_cls_color(model.names) # 获取类别颜色
app = QtWidgets.QApplication(sys.argv) # 创建QApplication对象
window = MainWindow() # 创建MainWindow对象
filename = abs_path("test_media/防具检测.mp4", path_type="current") # 定义视频文件的路径
videoHandler = MediaHandler(fps=30) # 创建MediaHandler对象,设置帧率为30fps
videoHandler.frameReady.connect(frame_process) # 当有新的帧准备好时,调用frame_process函数进行处理
videoHandler.setDevice(filename) # 设置视频源
videoHandler.startMedia() # 开始处理媒体
# 显示窗口
window.show()
# 进入 Qt 应用程序的主循环
sys.exit(app.exec())
通过这种方式,我们不仅展示了如何将深度学习模型与图形用户界面结合,还演示了如何在实际应用中实时处理和展示模型的预测结果。
5. 个人防具检测系统实现
在实现一款实时个人防具检测系统时,我们旨在创建一个直观、高效并且用户友好的应用程序。这个系统不仅集成了先进的目标检测算法,还提供了丰富的用户交互界面,让用户能够轻松地监控和分析实时视频流中的个人防具使用情况。
5.1 系统设计思路
我们的设计初衷是创建一个既直观又高效的工具,用于加强工作场所的安全监督。为此,我们设计了一个MainWindow类,它是整个应用的核心,将用户界面(UI)、媒体处理和目标检测模型紧密集成。在设计过程中,我们确保了各个功能模块能够独立运行,并且相互协作,提供一个无缝的用户体验。

架构设计
我们构建的架构体现了模块化设计,其中包括处理层、界面层和控制层,每层都有其独立的职责。
- 处理层(Processing Layer):在处理层,我们集成了YOLOv8Detector类,这个类封装了预训练的YOLOv8目标检测模型及其方法,负责从视频流中检测个人防具。这一层的设计使得模型能够独立于用户界面进行工作,保证了处理的效率和准确性。
- 界面层(UI Layer):在界面层,我们通过Ui_MainWindow类生成了一个直观的用户界面。这个界面包括多种交互元素,如按钮和标签,这些都是为了让用户能够更容易地与系统互动,并即时获取关于检测对象的反馈。用户可以通过这些交互元素来控制视频流的播放,或是调整模型的设置,从而对监控的细节有更深的控制。
- 控制层(Control Layer):控制层是我们系统的指挥中心。在MainWindow类中,我们实现了多个槽函数和其他方法,这些方法响应来自界面层的用户操作,并指挥媒体处理器和检测模型的行为。通过精心设计的控制逻辑,我们确保了所有操作都是响应迅速且可靠的。
总的来说,我们的系统是在模块化和功能独立性的原则下构建的,这样既提高了可维护性,也方便了未来的功能扩展。我们采用了Qt框架强大的信号和槽机制,这让各个独立模块之间的数据传递和事件响应变得格外简单。这样的设计不仅优化了应用程序的内部逻辑,更提升了用户与系统互动的体验。
系统流程
本篇文章专注于介绍一个交互式个人防具检测系统的流程设计。该系统通过集成最先进的目标检测算法YOLOv8,为用户提供了一个高效且直观的工具,以增强对工作场所安全的监控。

- 当用户启动我们的应用程序时,系统首先会实例化MainWindow类。这个类的实例化过程不仅包括界面的初始化,同时还会设置一系列参数,为用户的操作提供了一个清晰的起点。这个界面作为用户与系统交互的平台,提供了一系列选择,如输入源的选择——无论是实时摄像头捕捉的图像流,本地视频文件播放,还是单个静态图片的加载,都可以通过这个界面进行。
- 用户通过UI选择了输入源之后,系统将启动媒体处理器来处理这些输入数据。这个过程可能包括配置摄像头参数、解码视频文件或加载图像到内存中,这些都是为了准备好数据以供后续处理。一旦输入源准备就绪,系统便进入了一个连续的处理循环,该循环的每一步骤都是自动执行的。
- 在预处理阶段,系统将对每帧图像进行一系列的标准化处理,比如调整尺寸、变换颜色空间和归一化操作。这些处理步骤是为了确保图像数据符合YOLOv8模型的输入规格。然后,这些预处理过的图像将送入YOLOv8模型,进行目标检测和识别。模型会返回检测到的防具位置及其类别信息。
- 随着检测结果的产出,我们设计的界面将被实时更新。这些更新不仅包括显示检测框和类别标签,还包括在界面上显示的检测统计数据,如表格或图表。这些实时反馈为用户提供了一个动态的视觉效果,使他们能够立即看到系统的检测结果。
- 此外,我们还考虑了用户可能需要与系统进行更深层次交互的情况。因此,我们提供了多种操作选项,用户可以通过界面上的按钮来保存检测结果、查看系统信息,或通过下拉菜单对特定的检测结果进行更细致的筛选和分析。
- 最后,媒体控制功能让用户能够更自由地操控媒体播放状态。用户可以根据需要启动或暂停摄像头捕捉、视频播放或对图像的分析。这种控制的灵活性是我们系统设计中的一大亮点,它使用户能够根据实际需求调整系统的运行。
整体而言,我们的个人防具检测系统旨在提供一个全面的解决方案,不仅在后端集成了强大的YOLOv8目标检测模型,而且在前端提供了丰富的交互功能,使得用户可以轻松地使用本系统,并从中获得实时、准确的检测反馈。
5.2 登录与账户管理
在我们的技术博客中,我们细致地介绍了一个综合性的个人防具检测系统,它不仅具备强大的目标检测功能,还包含了一个完整的用户账户管理系统。这个账户管理系统的设计是为了增强用户体验,提供个性化服务,并确保用户数据的安全性和私密性。
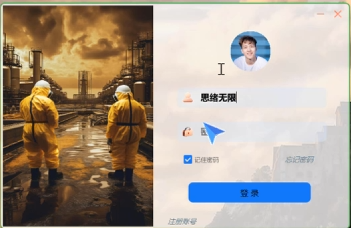
我们的账户管理系统基于PySide6——一个提供Qt图形界面功能的Python库——来构建用户界面,以及使用SQLite数据库进行数据存储,这使得我们的系统即便在没有网络连接的情况下也能够顺畅运行。账户管理的实现包括了用户注册、密码修改、头像设置等基础功能。这不仅使得用户能够在首次使用时快速创建个人账户,还能够在使用过程中对其个人信息进行管理和更新。
通过这样的设计,我们确保了每位用户都能有一个自己的私密空间,在这里,他们可以存储和管理自己的检测结果和偏好设置。用户在登录系统后,可以直接访问主界面,并进行个人防具的检测。系统的灵活性允许用户在任何时候更改密码、更新头像或者注销账户,确保了用户隐私和安全。
进一步地,个人防具检测系统还集成了多物体识别和检测的能力。用户在主界面中不仅能够实时看到包括检测框、类别标签以及置信度信息的视频流,还能通过不同的输入模式,如图片、视频、实时摄像头捕捉或批量文件处理,对各种场景进行分析和识别。无论是单个的图像文件还是连续的视频流,系统都能够实时识别其中的个人防具,并记录下来,这为用户提供了极大的便利。
综上所述,我们的个人防具检测系统不仅仅是一个高效的目标检测工具,它还是一个全面的解决方案,结合了深度学习的先进技术和用户账户管理的便捷性。用户不仅可以依靠这个系统来增强工作环境的安全性,还能享受到一个定制化的用户体验。
下载链接
若您想获得博文中涉及的实现完整全部资源文件(包括测试图片、视频,py, UI文件,训练数据集、训练代码、界面代码等),这里已打包上传至博主的面包多平台,见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:

完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文件下载请见演示与介绍视频的简介处给出:➷➷➷
演示与介绍视频:https://www.bilibili.com/video/BV14y421v72R/
YOLOv8/v7/v6/v5项目合集:https://mbd.pub/o/bread/ZZyUmpdt
YOLOv8/v5项目完整资源:https://mbd.pub/o/bread/ZZubmp9x
YOLOv7项目完整资源:https://mbd.pub/o/bread/ZZucmp9v
YOLOv6项目完整资源:https://mbd.pub/o/bread/ZZyUk5xr
在文件夹下的资源显示如下,下面的链接中也给出了Python的离线依赖包,读者可在正确安装Anaconda和Pycharm软件后,复制离线依赖包至项目目录下进行安装,另外有详细安装教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境配置教程;
离线依赖安装教程:https://www.bilibili.com/video/BV1hv421C7g8/
离线依赖库下载链接:https://pan.baidu.com/s/1y6vqa9CtRmC72SQYPh1ZCg?pwd=33z5 (提取码:33z5)
6. 总结与展望
在本博客中,我们详细介绍了一个基于YOLOv8模型的实时个人防具检测系统。系统以模块化的方式设计,充分采用了合理的架构设计,带来良好的可维护性和可扩展性。其用户界面友好,能够提供实时的个人防具检测和识别结果展示,同时支持用户账户管理,以便于保存和管理检测结果和设置。
该系统支持摄像头、视频、图像和批量文件等多种输入源,能够满足用户在不同场景下的需求。在后面可以添加更多预训练模型,增加检测和识别的种类;优化用户界面,增强个性化设置;并积极聆听用户反馈,以期不断改进系统,以更好地满足用户的需求。
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。
Tan, M., and Le, Q. V. (2020). EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). ↩︎
Lin, T.-Y., Dollár, P., Girshick, R., He, K., Hariharan, B., and Belongie, S. (2017). Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). ↩︎
Cai, Z., and Vasconcelos, N. (2018). Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). ↩︎
Zhou, X., Wang, D., and Krähenbühl, P. (2019). Objects as Points. arXiv preprint arXiv:1904.07850. ↩︎
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., and Guo, B. (2021). Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). ↩︎

