智能零售柜商品检测软件(Python+YOLOv5深度学习模型+清新界面)
 智能零售柜商品检测软件用于识别零售柜常见商品,检测商品名和位置以了解销售情况,为零售柜商品智能检测和自动销售提供检测功能。本文详细智能零售柜商品检测软件,在介绍算法原理的同时,给出Python的实现代码、训练数据集、以及PyQt的UI界面。在界面中可以选择各种图片、视频进行检测识别;可对图像中存在的多目标进行识别分类,检测速度快、识别精度高。博文提供了完整的Python代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。
智能零售柜商品检测软件用于识别零售柜常见商品,检测商品名和位置以了解销售情况,为零售柜商品智能检测和自动销售提供检测功能。本文详细智能零售柜商品检测软件,在介绍算法原理的同时,给出Python的实现代码、训练数据集、以及PyQt的UI界面。在界面中可以选择各种图片、视频进行检测识别;可对图像中存在的多目标进行识别分类,检测速度快、识别精度高。博文提供了完整的Python代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。

摘要:智能零售柜商品检测软件用于识别零售柜常见商品,检测商品名和位置以了解销售情况,为零售柜商品智能检测和自动销售提供检测功能。本文详细智能零售柜商品检测软件,在介绍算法原理的同时,给出Python的实现代码、训练数据集、以及PyQt的UI界面。在界面中可以选择各种图片、视频进行检测识别;可对图像中存在的多目标进行识别分类,检测速度快、识别精度高。博文提供了完整的Python代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。本博文目录如下:
完整代码下载:https://mbd.pub/o/bread/ZJaXlZlu
参考视频演示:https://www.bilibili.com/video/BV1cX4y1f7iv/
离线依赖库下载:https://pan.baidu.com/s/1hW9z9ofV1FRSezTSj59JSg?pwd=oy4n (提取码:oy4n )
前言
智能零售柜商品检测系统是指利用计算机视觉技术和深度学习算法对零售柜中的商品进行实时检测和识别,以便为消费者提供更加智能和便捷的购物体验。该系统主要通过使用摄像头对零售柜内商品进行实时拍摄和录制,然后利用深度学习算法对商品的特征进行提取和分析,最终实现对商品的检测和识别。智能零售柜商品检测系统的主要功能包括实时监测零售柜中的商品,识别商品的种类、品牌、价格等信息,提供商品库存信息,帮助消费者更加便捷地进行购物,提高消费体验。该系统可以广泛应用于超市、便利店、餐饮等场所,有助于提高商品销售效率和管理效率,减少人工成本和误差率。同时,智能零售柜商品检测系统还可以结合其他技术手段,如语音识别、人脸识别等,实现更加智能化的购物体验,推动零售业的数字化转型和升级。
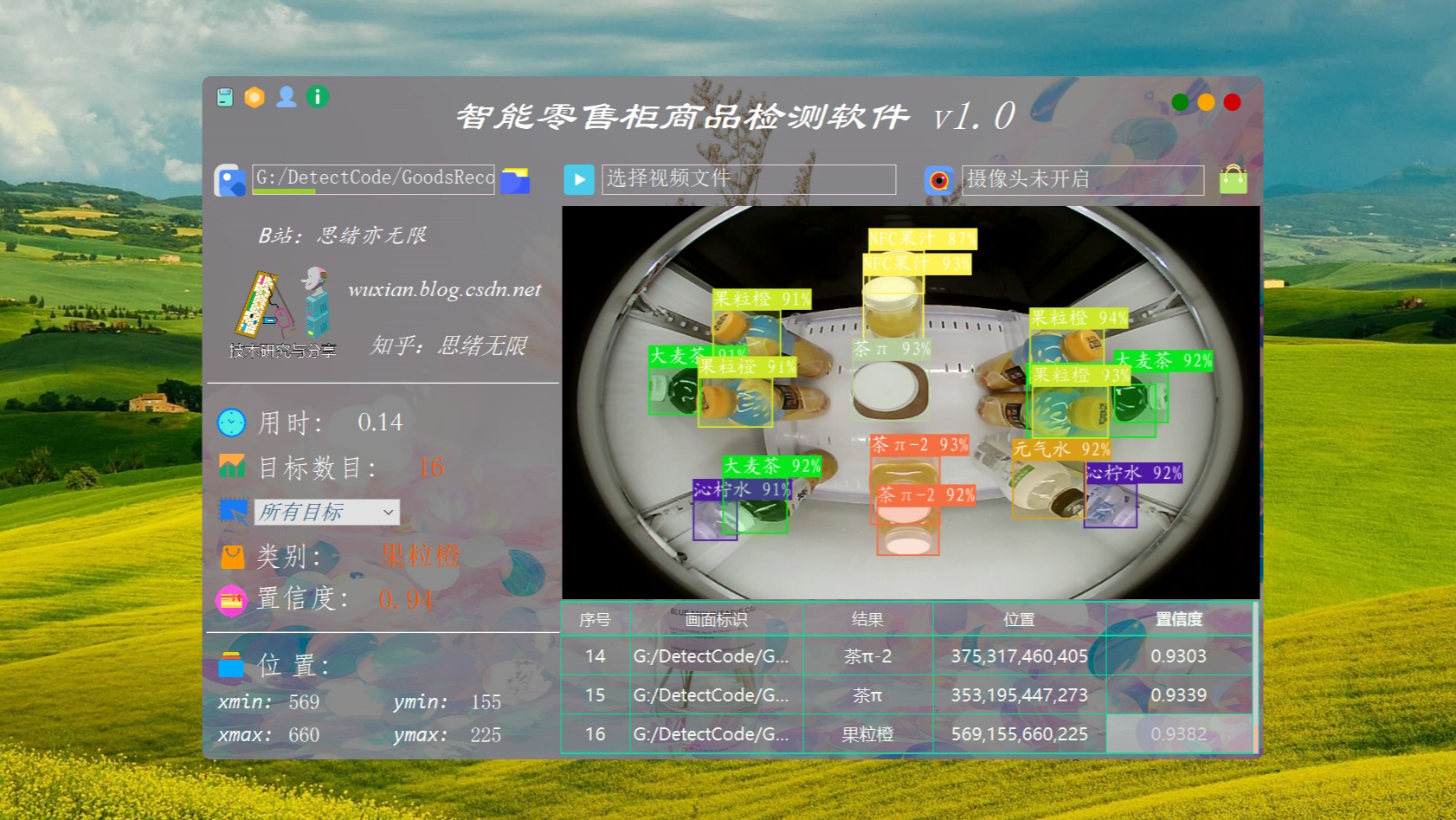
本系统采用登录注册进行用户管理,对于图片、视频和摄像头捕获的实时画面,可检测商品图像,系统支持结果记录、展示和保存,每次检测的结果记录在表格中。对此这里给出博主设计的界面,同款的简约风,功能也可以满足图片、视频和摄像头的识别检测,希望大家可以喜欢,初始界面如下图:

检测类别时的界面截图(点击图片可放大)如下图,可识别画面中存在的多个类别,也可开启摄像头或视频检测:

详细的功能演示效果参见博主的B站视频或下一节的动图演示,觉得不错的朋友敬请点赞、关注加收藏!系统UI界面的设计工作量较大,界面美化更需仔细雕琢,大家有任何建议或意见和可在下方评论交流。
1. 效果演示
软件好不好用,颜值很重要,首先我们还是通过动图看一下识别的效果,系统主要实现的功能是对图片、视频和摄像头画面中的商品进行识别,识别的结果可视化显示在界面和图像中,另外提供多个目标的显示选择功能,演示效果如下。
(一)系统介绍
智能零售柜商品检测软件主要用于零售柜商品的智能检测与识别,利用零售柜顶部鱼眼相机采集的图像,基于深度学习技术识别柜内常见的113种零售商品,输出商品的标记框坐标和类别,以辅助自动化获取商品销售情况;软件提供登录注册功能,可进行用户管理;软件能够有效识别相机采集的图片、视频等文件形式,检测柜内商品销售情况,并记录识别结果在界面表格中方便查看;可开启摄像头实时监测和统计当前视野范围各种类型商品数目,支持结果记录、展示和保存。
(二)技术特点
(1)YoloV5目标检测算法识别商品,模型支持更换;
(2)摄像头实时检测柜内商品,展示、记录和保存销售情况;
(3)检测图片、视频等图像中的零售柜商品;
(4)支持用户登录、注册,检测结果可视化功能;
(5)提供训练数据集和代码,可重新训练模型;
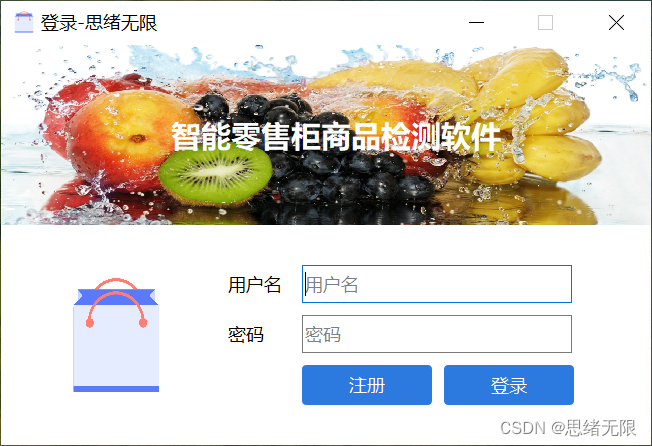
(三)用户注册登录界面
这里设计了一个登录界面,可以注册账号和密码,然后进行登录。界面还是参考了当前流行的UI设计,左侧是一个logo图,右侧输入账号、密码、验证码等等。
(四)选择图片识别
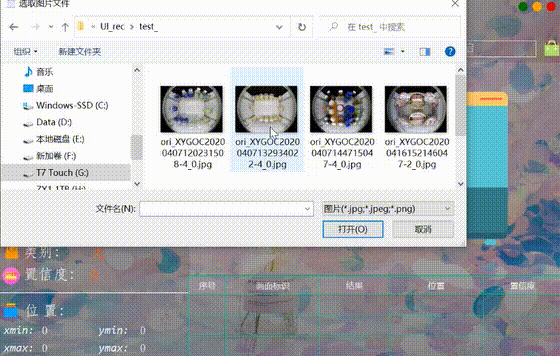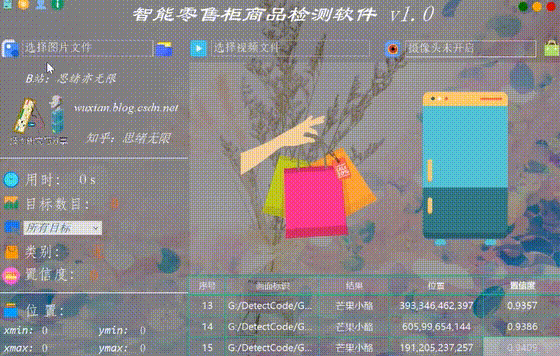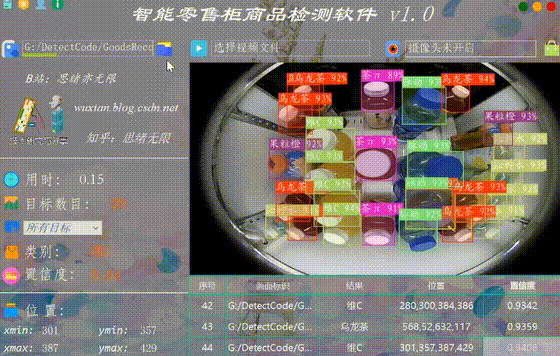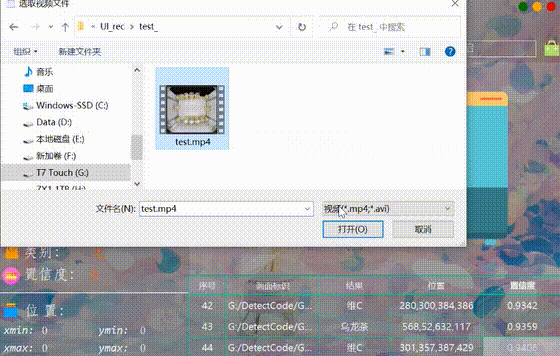
系统允许选择图片文件进行识别,点击图片选择按钮图标选择图片后,显示所有识别的结果,可通过下拉选框查看单个结果,以便具体判断某一特定目标。本功能的界面展示如下图所示:
(五)视频识别效果展示
很多时候我们需要识别一段视频中的多个商品,这里设计了视频选择功能。点击视频按钮可选择待检测的视频,系统会自动解析视频逐帧识别多个商品,并将商品的分类和计数结果记录在右下角表格中,效果如下图所示:
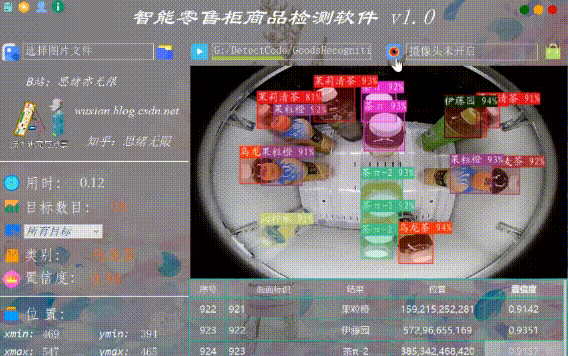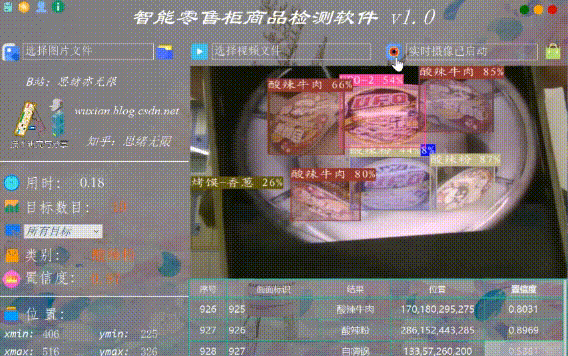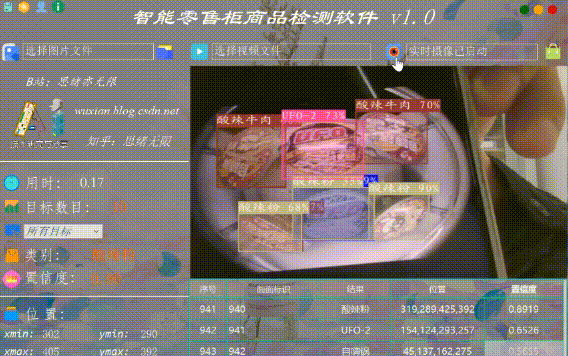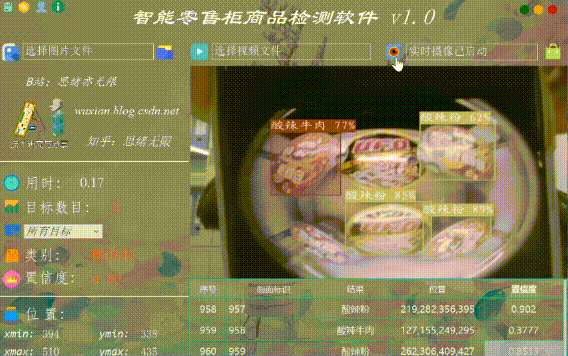
(六)摄像头检测效果展示
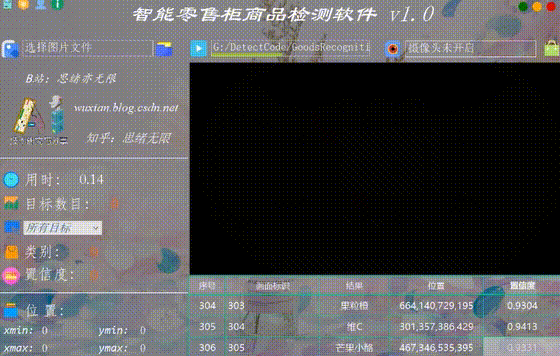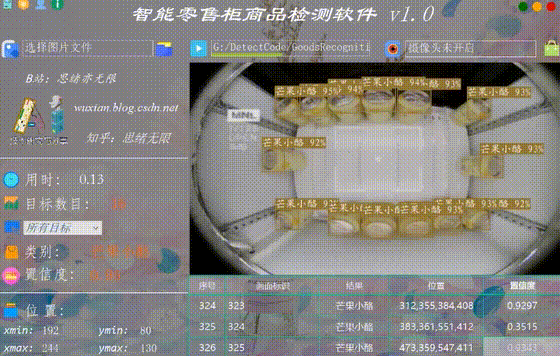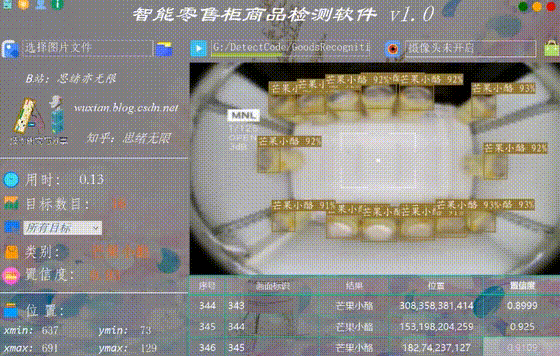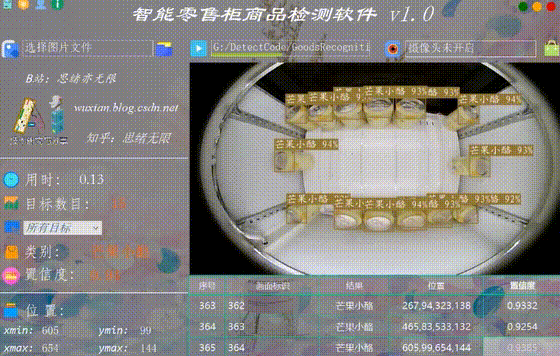
在真实场景中,我们往往利用摄像头获取实时画面,同时需要对零售柜商品进行识别,因此本文考虑到此项功能。如下图所示,点击摄像头按钮后系统进入准备状态,系统显示实时画面并开始检测画面中的零售柜商品,识别结果展示如下图:
2. 数据集及训练
这里我们使用的商品数据集,其中包含零售柜中常见的113种零售商品,比如奶茶、方便面、可乐、果汁等各种商品,其类别如下:
Chinese_name = {'3+2-2': "3+2-2", '3jia2': "3+2", 'aerbeisi': "阿尔卑斯", 'anmuxi': "安慕希", 'aoliao': "奥利奥",
'asamu': "阿萨姆", 'baicha': "白茶", 'baishikele': "百事可乐", 'baishikele-2': "百事可乐-2",
'baokuangli': "宝矿力", 'binghongcha': "冰红茶", 'bingqilinniunai': "冰淇淋牛奶",
'bingtangxueli': "冰糖雪梨", 'buding': "布丁", 'chacui': "茶萃", 'chapai': "茶π", 'chapai2': "茶π-2",
'damaicha': "大麦茶", 'daofandian1': "到饭点-1", 'daofandian2': "到饭点-2", 'daofandian3': "到饭点-3",
'daofandian4': "到饭点-4", 'dongpeng': "东鹏特饮", 'dongpeng-b': "东鹏特饮-b", 'fenda': "芬达",
'gudasao': "顾大嫂", 'guolicheng': "果粒橙", 'guolicheng2': "果粒橙-2", 'haitai': "海苔",
'haochidian': "好吃点", 'haoliyou': "好丽友", 'heweidao': "合味道", 'heweidao2': "合味道-2",
'heweidao3': "合味道-3", 'hongniu': "红牛", 'hongniu2': "红牛-2", 'hongshaoniurou': "红烧牛肉",
'jianjiao': "尖叫", 'jianlibao': "健力宝", 'jindian': "金典", 'kafei': "咖啡", 'kaomo_gali': "烤馍-咖喱",
'kaomo_jiaoyan': "烤馍-椒盐", 'kaomo_shaokao': "烤馍-烧烤", 'kaomo_xiangcon': "烤馍-香葱", 'kebike': "可比克",
'kele': "可乐", 'kele-b': "可乐-b", 'kele-b-2': "可乐-b-2", 'laotansuancai': "老坛酸菜",
'liaomian': "撩面", 'libaojian': "力保健", 'lingdukele': "零度可乐", 'lingdukele-b': "零度可乐-b",
'liziyuan': "李子园", 'lujiaoxiang': "鹿角巷",
'lujikafei': "露吉咖啡", 'luxiangniurou': "卤香牛肉", 'maidong': "脉动", 'mangguoxiaolao': "芒果小酪",
'meiniye': "梅尼耶", 'mengniu': "蒙牛",
'mengniuzaocan': "蒙牛早餐奶",
'moliqingcha': "茉莉清茶", 'nfc': "NFC果汁", 'niudufen': "牛肚粉", 'niunai': "牛奶",
'nongfushanquan': "农夫山泉", 'qingdaowangzi-1': "青岛王子-1",
'qingdaowangzi-2': "青岛王子-2",
'qinningshui': "沁柠水", 'quchenshixiangcao': "屈臣氏香草味苏打水", 'rancha-1': "燃茶", 'rancha-2': "燃茶",
'rousongbing': "肉松饼",
'rusuanjunqishui': "乳酸菌汽水",
'suanlafen': "酸辣粉",
'suanlaniurou': "酸辣牛肉", 'taipingshuda': "太平梳打", 'tangdaren': "汤达人", 'tangdaren2': "汤达人-2",
'tangdaren3': "汤达人-3", 'ufo': "UFO",
'ufo2': "UFO-2",
'wanglaoji': "王老吉", 'wanglaoji-c': "王老吉-c",
'wangzainiunai': "旺仔牛奶", 'weic': "维C", 'weitanai': "维他奶", 'weitanai2': "维他奶-2",
'weitanaiditang': "维他奶低糖",
'weitaningmeng': "维他柠檬", 'weitaningmeng-bottle': "维他柠檬-瓶装",
'weiweidounai': "维他豆奶", 'wuhounaicha': "午后奶茶", 'wulongcha': "乌龙茶", 'xianglaniurou': "香辣牛肉",
'xianguolao': "鲜果捞",
'xianxiayuban': "鲜虾鱼板面", 'xuebi': "雪碧", 'xuebi-b': "雪碧-b",
'xuebi2': "雪碧-2", 'yezhi': "椰汁", 'yibao': "怡宝", 'yida': "益达", 'yingyangkuaixian': "营养快线",
'yitengyuan': "伊藤园",
'youlemei': "优乐美", 'yousuanru': "优酸乳", 'youyanggudong': "有养谷咚",
'yuanqishui': "元气水", 'zaocanmofang': "早餐魔方", 'zihaiguo': "自嗨锅"}
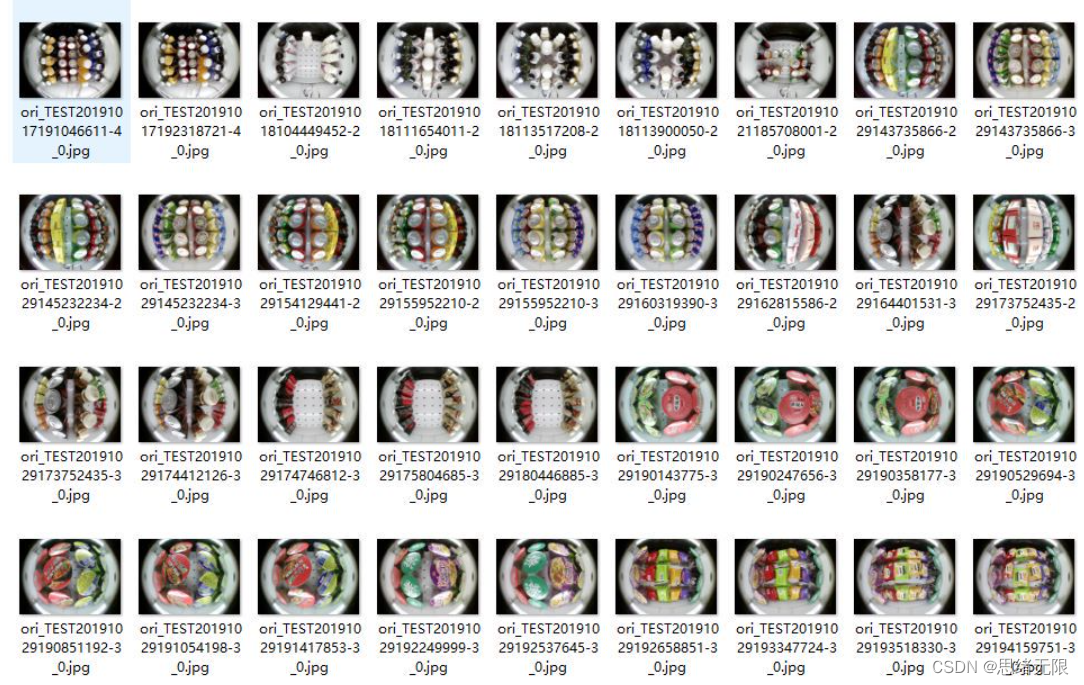
该数据集中,训练集有3796张图片,验证集1084张图片,测试集542张图片,共计5422张图片,选取部分数据部分样本数据集如图所示。

每张图像均提供了图像类标记信息,图像中零售柜商品的bounding box,零售柜商品的关键part信息,以及零售柜商品的属性信息,数据集并解压后得到如下的图片
对于原始的数据集标签文件格式不一致的问题,由于yolov5只认txt而不认json,因此还要有一个转换的过程:批量json转txt。可采用如下代码:
import json
import os
name2id = {'stitches': 0} # 标签名称
def convert(img_size, box):
dw = 1. / (img_size[0])
dh = 1. / (img_size[1])
x = (box[0] + box[2]) / 2.0 - 1
y = (box[1] + box[3]) / 2.0 - 1
w = box[2] - box[0]
h = box[3] - box[1]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def decode_json(json_floder_path, json_name):
txt_name = '/mnt/data/yolov5-master/nxm_data/labels_txt/' + json_name[0:-5] + '.txt'
# 存放txt的绝对路径
txt_file = open(txt_name, 'w')
json_path = os.path.join(json_floder_path, json_name)
data = json.load(open(json_path, 'r', encoding='gb2312', errors='ignore'))
img_w = data['imageWidth']
img_h = data['imageHeight']
for i in data['shapes']:
label_name = i['label']
if (i['shape_type'] == 'rectangle'):
x1 = int(i['points'][0][0])
y1 = int(i['points'][0][1])
x2 = int(i['points'][1][0])
y2 = int(i['points'][1][1])
bb = (x1, y1, x2, y2)
bbox = convert((img_w, img_h), bb)
txt_file.write(str(name2id[label_name]) + " " + " ".join([str(a) for a in bbox]) + '\n')
if __name__ == "__main__":
json_floder_path = '/mnt/data/yolov5-master/nxm_data/labels/'
# 存放json的文件夹的绝对路径
json_names = os.listdir(json_floder_path)
for json_name in json_names:
decode_json(json_floder_path, json_name)
YoloV5原作者给出了4种模型的配置,分别为YoloV5s,YoloV5m,YoloV5l,YoloV5x,根据根据自己的实时性需求选择对应的网络。
接下来只需要在train.py中修改对应的配置文件就好了,对于本数据集配置的yaml文件内容如下:。
train: ./Goods/images/train
val: ./Goods/images/val
test: ./Goods/images/test
nc: 113
names: ['3+2-2', '3jia2', 'aerbeisi', 'anmuxi', 'aoliao', 'asamu', 'baicha','baishikele', 'baishikele-2','baokuangli',
'binghongcha', 'bingqilinniunai', 'bingtangxueli', 'buding', 'chacui', 'chapai', 'chapai2', 'damaicha',
'daofandian1', 'daofandian2', 'daofandian3', 'daofandian4', 'dongpeng', 'dongpeng-b', 'fenda', 'gudasao',
'guolicheng', 'guolicheng2', 'haitai', 'haochidian', 'haoliyou', 'heweidao', 'heweidao2', 'heweidao3',
'hongniu', 'hongniu2', 'hongshaoniurou', 'jianjiao', 'jianlibao', 'jindian', 'kafei', 'kaomo_gali',
'kaomo_jiaoyan', 'kaomo_shaokao', 'kaomo_xiangcon', 'kebike', 'kele', 'kele-b', 'kele-b-2',
'laotansuancai', 'liaomian', 'libaojian', 'lingdukele','lingdukele-b','liziyuan','lujiaoxiang',
'lujikafei','luxiangniurou','maidong','mangguoxiaolao','meiniye','mengniu','mengniuzaocan',
'moliqingcha','nfc','niudufen','niunai','nongfushanquan','qingdaowangzi-1','qingdaowangzi-2',
'qinningshui','quchenshixiangcao','rancha-1','rancha-2','rousongbing','rusuanjunqishui','suanlafen',
'suanlaniurou','taipingshuda','tangdaren','tangdaren2','tangdaren3','ufo','ufo2','wanglaoji','wanglaoji-c',
'wangzainiunai','weic', 'weitanai','weitanai2','weitanaiditang','weitaningmeng','weitaningmeng-bottle',
'weiweidounai','wuhounaicha','wulongcha','xianglaniurou','xianguolao','xianxiayuban','xuebi','xuebi-b',
'xuebi2','yezhi','yibao','yida','yingyangkuaixian','yitengyuan','youlemei','yousuanru','youyanggudong',
'yuanqishui','zaocanmofang','zihaiguo']
(1)train 指定训练集图像路径
(2)val 指定验证集图像路径
(3)test 指定测试集图像路径
(4)nc 指定目标类别数量
(5)目标对应类别名称
以上就是YOLOv5的整体介绍,接下来进行训练。本项目使用Yolov5训练了一个商品目标检测模型,在笔记本的3070显卡下训练了300 epoch,训练过程的截图如下:

在我们的训练过程中,mAP50作为一种常用的目标检测评估指标很快达到了较高水平,而mAP50:95也在训练的过程中不断提升,说明我们模型从训练-验证的角度表现良好。读入一个测试文件夹进行预测,通过训练得到的选取验证集上效果最好的权重best.pt进行实验,得到PR曲线如下图所示。
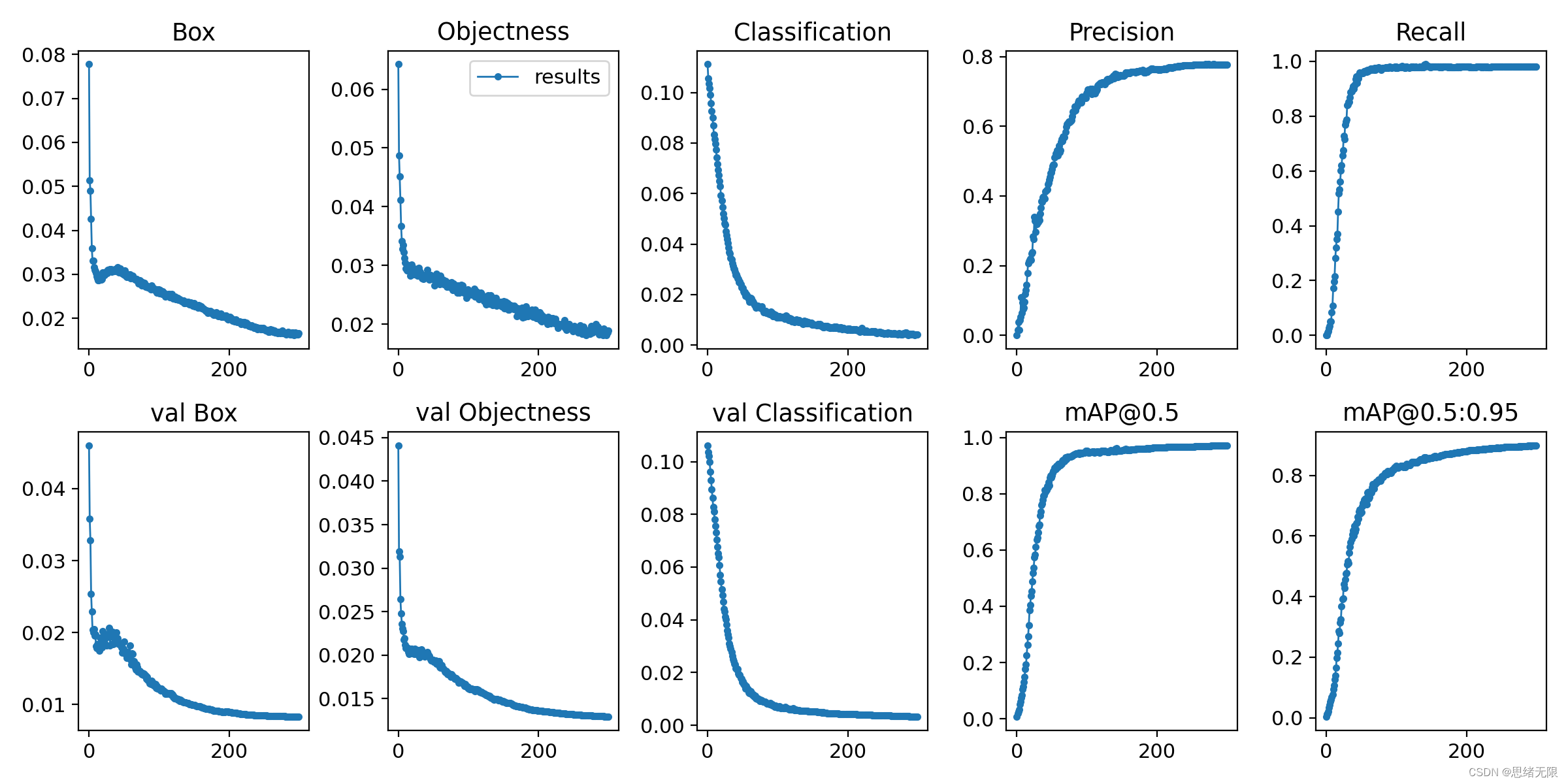
在深度学习中,我们通常通过损失函数下降的曲线来观察模型训练的情况。而YOLOv5训练时主要包含三个方面的损失:矩形框损失(box_loss)、置信度损失(obj_loss)和分类损失(cls_loss),在训练结束后,我们也可以在logs目录下找到生成对若干训练过程统计图。下图为博主训练商品识别的模型训练曲线图。

以PR-curve为例,可以看到我们的模型在验证集上的均值平均准确率为0.971。
3. 智能零售柜商品检测
在训练完成后得到最佳模型,接下来我们将帧图像输入到这个网络进行预测,从而得到预测结果,预测方法(predict.py)部分的代码如下所示:
def predict(img):
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float()
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
t1 = time_synchronized()
pred = model(img, augment=False)[0]
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes,
agnostic=opt.agnostic_nms)
t2 = time_synchronized()
InferNms = round((t2 - t1), 2)
return pred, InferNms
可以运行testPicture或testVideo两个脚本分别对图片和视频进行测试,其效果如下图所示:

博主对整个系统进行了详细测试,最终开发出一版流畅得到清新界面,就是博文演示部分的展示,完整的UI界面、测试图片视频、代码文件,以及Python离线依赖包(方便安装运行,也可自行配置环境),均已打包上传,感兴趣的朋友可以通过下载链接获取。
下载链接
若您想获得博文中涉及的实现完整全部程序文件(包括测试图片、视频,py, UI文件等,如下图),这里已打包上传至博主的面包多平台,见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:

在文件夹下的资源显示如下,下面的链接中也给出了Python的离线依赖包,读者可在正确安装Anaconda和Pycharm软件后,复制离线依赖包至项目目录下进行安装,离线依赖的使用详细演示也可见本人B站视频:win11从头安装软件和配置环境运行深度学习项目、Win10中使用pycharm和anaconda进行python环境配置教程。
注意:该代码采用Pycharm+Python3.8开发,经过测试能成功运行,运行界面的主程序为runMain.py和LoginUI.py,测试图片脚本可运行testPicture.py,测试视频脚本可运行testVideo.py。为确保程序顺利运行,请按照requirements.txt配置Python依赖包的版本。Python版本:3.8,请勿使用其他版本,详见requirements.txt文件;
完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文件下载请见以下链接处给出:➷➷➷
完整代码下载:https://mbd.pub/o/bread/ZJaXlZlu
参考视频演示:https://www.bilibili.com/video/BV1cX4y1f7iv/
离线依赖库下载:https://pan.baidu.com/s/1hW9z9ofV1FRSezTSj59JSg?pwd=oy4n (提取码:oy4n )
界面中文字、图标和背景图修改方法:
在Qt Designer中可以彻底修改界面的各个控件及设置,然后将ui文件转换为py文件即可调用和显示界面。如果只需要修改界面中的文字、图标和背景图的,可以直接在ConfigUI.config文件中修改,步骤如下:
(1)打开UI_rec/tools/ConfigUI.config文件,若乱码请选择GBK编码打开。
(2)如需修改界面文字,只要选中要改的字符替换成自己的就好。
(3)如需修改背景、图标等,只需修改图片的路径。例如,原文件中的背景图设置如下:
mainWindow = :/images/icons/back-image.png
可修改为自己的名为background2.png图片(位置在UI_rec/icons/文件夹中),可将该项设置如下即可修改背景图:
mainWindow = ./icons/background2.png
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。

