基于深度学习的火焰检测系统(YOLOv5清新界面版,Python代码)
 火焰检测系统用于检测日常是否出现火情,支持图片、视频、摄像头等多方式检测火焰、实现火灾警报功能,提供了登录注册界面。在介绍系统实现原理的同时,给出部分Python的实现代码以及PyQt的UI界面。火焰检测系统主要用于日常生活中火情图像的识别,基于YOLOv5模型识别图像中可能出现火灾的位置、着火点数目、置信度等;可分析图片、视频和摄像画面中的火焰情况,自由切换火焰检测模型;系统设计有注册登录功能,方便用户进行管理和使用;火焰识别结果实时显示,单个目标可逐个标注、显示和数据展示,结果可通过菜单按钮保存。博文提供了完整的Python代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。
火焰检测系统用于检测日常是否出现火情,支持图片、视频、摄像头等多方式检测火焰、实现火灾警报功能,提供了登录注册界面。在介绍系统实现原理的同时,给出部分Python的实现代码以及PyQt的UI界面。火焰检测系统主要用于日常生活中火情图像的识别,基于YOLOv5模型识别图像中可能出现火灾的位置、着火点数目、置信度等;可分析图片、视频和摄像画面中的火焰情况,自由切换火焰检测模型;系统设计有注册登录功能,方便用户进行管理和使用;火焰识别结果实时显示,单个目标可逐个标注、显示和数据展示,结果可通过菜单按钮保存。博文提供了完整的Python代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。
摘要:火焰检测系统用于检测日常是否出现火情,支持图片、视频、摄像头等多方式检测火焰、实现火灾警报功能,提供了登录注册界面。在介绍系统实现原理的同时,给出部分Python的实现代码以及PyQt的UI界面。火焰检测系统主要用于日常生活中火情图像的识别,基于YOLOv5模型识别图像中可能出现火灾的位置、着火点数目、置信度等;可分析图片、视频和摄像画面中的火焰情况,自由切换火焰检测模型;系统设计有注册登录功能,方便用户进行管理和使用;火焰识别结果实时显示,单个目标可逐个标注、显示和数据展示,结果可通过菜单按钮保存。博文提供了完整的Python代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。本博文目录如下:
完整代码下载:https://mbd.pub/o/bread/ZJaXlJdw
参考视频演示:https://www.bilibili.com/video/BV1u24y1t7xo/
离线依赖下载:https://pan.baidu.com/s/1hW9z9ofV1FRSezTSj59JSg?pwd=oy4n(提取码:oy4n)
前言
火灾是最常见的严重灾害之一,容易给灾害处造成重大经济财产损失。火灾的发生具有频率高、时空跨度大的特点,是一种在时空上失去控制的燃烧所引起的灾害。大家都清楚火灾的危害及防火救火的重要性,火焰检测识别预警系统、智能识别烟火检测系统等系统可以全天候、不间断实现火灾监控分析并实时报警,然而目前多数场景的传统安防监控,却没有达到及时主动报警的目的。
如今的火焰检测系统除了可以使用火焰传感器等简单方式监控火情,还可以基于机器视觉深度学习技术利用摄像头监控,能够实现无人值守的不间断工作,并且系统可以主动发现监控区域内的火灾苗头。火焰检测系统以最及时的方式进行告警,同时最大限度降低误报和漏报现象;火焰检测系统智能识别烟火检测系统极大的节约了人员成本,提高了工作效率。
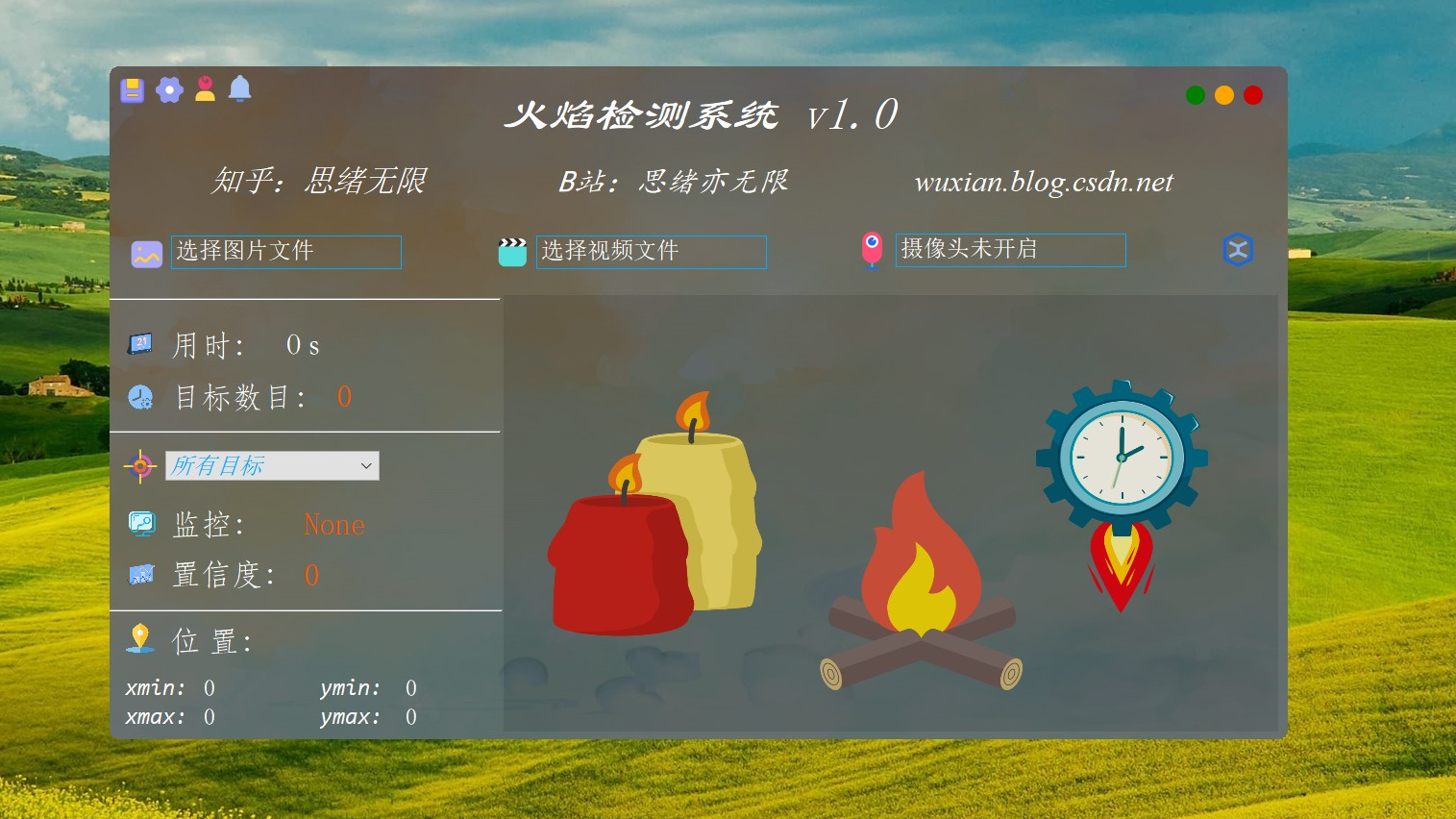
针对住宅、加油站、公路、森林等火灾高发场景,基于机器视觉的火焰检测系统应满足多种情景下的智能检测,可以自动检测监控区域内的烟雾和火灾,帮助相关人员及时应对,最大程度降低人员伤亡及财物损失。这里给出博主设计的软件界面,整体上采用简约风,功能也可以满足图片、视频和摄像头的识别检测,初始界面如下图:

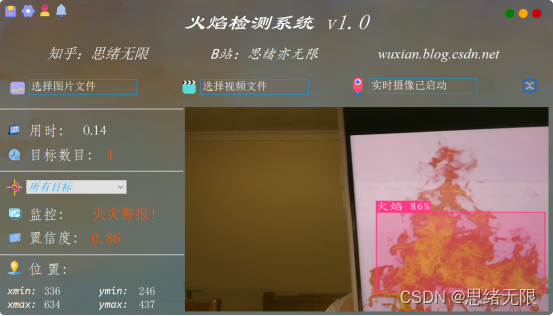
检测火焰时的界面截图(点击图片可放大)如下图,可识别画面中存在的多个着火点,也可开启摄像头或视频检测:

详细的功能演示效果参见博主的B站视频或下一节的动图演示,觉得不错的朋友敬请点赞、关注加收藏!系统UI界面的设计工作量较大,界面美化更需仔细雕琢,大家有任何建议或意见和可在下方评论交流。
1. 效果演示
首先我们还是通过动图看一下识别火焰的效果,系统主要实现的功能是对图片、视频和摄像头画面中的着火位置进行检测,结果可视化显示在界面和图像中,另外提供多个火焰的显示切换功能,演示效果如下。
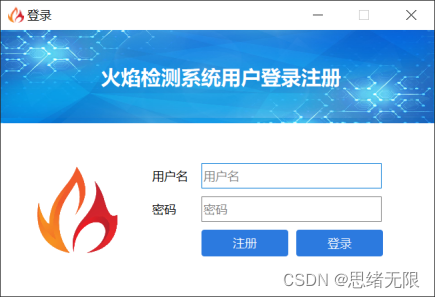
(一)用户注册登录界面
这里设计了一个登录界面,可以注册账号和密码,然后进行登录。界面还是参考了当前流行的UI设计,左侧是一个动图,右侧输入账号、密码、验证码等等。
(二)选择火焰图片识别
系统可选择图片文件进行识别,点击图片选择按钮图标选择图片后,显示所有火焰识别的结果,可通过下拉选框查看单个火焰的结果。本功能的界面展示如下图所示:

(三)火焰视频识别效果展示
有时我们需要识别一段视频中的火焰结果,这里设计了视频选择功能。点击视频按钮可选择待检测的视频,系统会自动解析视频逐帧识别火焰,并将结果记录在右下角表格中,效果如下图所示:

(四)摄像头检测效果展示
在真实场景中,我们往往利用设备摄像头获取实时画面,同时需要对画面中的火焰进行识别,因此本文考虑到此项功能。如下图所示,点击摄像头按钮后系统进入准备状态,系统显示实时画面并开始检测画面中的火焰,识别结果展示如下图:

2. 火焰检测与识别
当前深度学习技术的流行,优秀的目标检测算法不断涌现,YOLO系列由于实现简单、检测速度快、精度高等特点得到了众多应用。这里的火焰检测系统基于YoloV5实现,它可以看作是单阶段目标检测。单阶段目标检测器的体系结构比两阶段目标检测器更简单,不需要生成候选区域,通过卷积神经网络提取特征直接输出目标的类别、概率和位置坐标,从而实现端到端的目标检测。单阶段目标检测器又包含基于锚框(anchor-based)的和非锚框(anchor-free)的两种方法。SSD、YOLO 和 Retina Net 等都是 anchor-based 的单阶段检测器,它们处理速度快而但精度相对有限。Anchor-based 方法使用密集的锚框直接进行目标分类和回归,能有效提高网络的召回能力,但是冗余框很多。Anchor-free 目标检测器则抛弃锚框的设计,取而代之的使用关键点进行目标检测,诸如CornerNet,CenterNet 等,都取得了不俗的效果。
我们使用使用Python爬虫利用关键字在互联网上获得的图片数据,爬取数据包含室内场景下的火焰、写字楼和房屋燃烧、森林火灾和车辆燃烧等场景下的火焰图片,经过筛选后留下质量较好的图片制作成VOC格式的实验数据集。当然也可以参考飞桨发布的火焰与烟雾数据集,数据集截图如下图所示。

深度学习图像标注软件众多,按照不同分类标准有多中类型,本文使用LabelImg单机标注软件进行标注。LabelImg是基于角点的标注方式产生边界框,对图片进行标注得到xml格式的标注文件,并将其转换为YOLO使用的标注文件格式。这里提供了标注好的数据集、训练代码和训练好的模型,包含在本系统的完整资源中。
以下给出本系统项目的文件目录,其中包含了YOLOv5相关的代码以及界面设计代码,如下图所示。对于训练模型部分只需要关注train.py这个文件,训练用到的数据集、标注文件及配置文件在本项目中已配置完成。
首先我们找到训练的py文件。然后找到主函数的入口,这里面有模型的主要参数。修改train.py中的weights、cfg、data、epochs、batch_size、imgsz、device、workers等参数。
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='/Bird/dataset.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=1, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--name', default='', help='renames experiment folder exp{N} to exp{N}_{name} if supplied')
# 设置是否运行GPU训练,若需要设置为0
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--logdir', type=str, default='Bird/logs', help='logging directory')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
opt = parser.parse_args()
然后我们可以执行train.py程序进行训练。在深度学习中,我们通常通过损失函数下降的曲线来观察模型训练的情况。而YOLOv5训练时主要包含三个方面的损失:矩形框损失(box_loss)、置信度损失(obj_loss)和分类损失(cls_loss),在训练结束后,我们也可以在logs目录下找到生成对若干训练过程统计图。下图为博主训练火焰识别的模型训练曲线图。
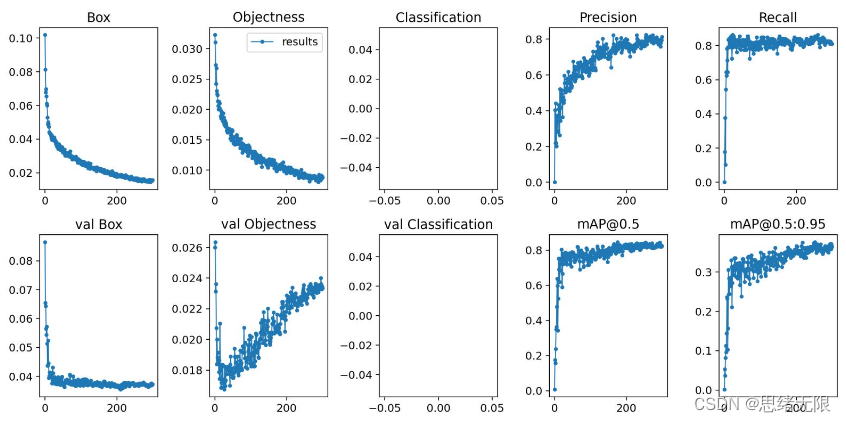
一般我们会接触到两个指标,分别是召回率recall和精度precision,两个指标p和r都是简单地从一个角度来判断模型的好坏,均是介于0到1之间的数值,其中接近于1表示模型的性能越好,接近于0表示模型的性能越差,为了综合评价目标检测的性能,一般采用均值平均密度map来进一步评估模型的好坏。我们通过设定不同的置信度的阈值,可以得到在模型在不同的阈值下所计算出的p值和r值,一般情况下,p值和r值是负相关的,绘制出来可以得到如下图所示的曲线,其中曲线的面积我们称AP,目标检测模型中每种目标可计算出一个AP值,对所有的AP值求平均则可以得到模型的mAP值。
以PR-curve为例,可以看到我们的模型在验证集上的均值平均准确率为0.824。从训练结果和数据集进行分析,其干扰样本多,容易造成误检, 其中有很多物体和烟火是非常接近的,很难区分(比如:云朵、红色的灯光等),容易造成模型误检。
3. 火焰检测识别
在训练完成后得到最佳模型,接下来我们将帧图像输入到这个网络进行预测,运行testPicture.py文件,读取一个图片并运行检测模型,首先将图片数据进行预处理后送predict进行检测,然后计算标记框的位置并在图中标注出来。
def predict(img):
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float()
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
t1 = time_synchronized()
pred = model(img, augment=False)[0]
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes,
agnostic=opt.agnostic_nms)
t2 = time_synchronized()
InferNms = round((t2 - t1), 2)
return pred, InferNms
def cv_imread(filePath):
# 读取图片
cv_img = cv2.imdecode(np.fromfile(filePath, dtype=np.uint8), -1)
if len(cv_img.shape) > 2:
if cv_img.shape[2] > 3:
cv_img = cv_img[:, :, :3]
return cv_img
def plot_one_box(img, x, color=None, label=None, line_thickness=None):
# Plots one bounding box on image img
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
if __name__ == '__main__':
img_path = "./UI_rec/test_/img (31).jpg"
image = cv_imread(img_path)
img0 = image.copy()
img = letterbox(img0, new_shape=imgsz)[0]
img = np.stack(img, 0)
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
pred, useTime = predict(img)
det = pred[0]
p, s, im0 = None, '', img0
if det is not None and len(det): # 如果有检测信息则进入
det[:, :4] = scale_coords(img.shape[1:], det[:, :4], im0.shape).round() # 把图像缩放至im0的尺寸
number_i = 0 # 类别预编号
detInfo = []
for *xyxy, conf, cls in reversed(det): # 遍历检测信息
c1, c2 = (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3]))
# 将检测信息添加到字典中
detInfo.append([names[int(cls)], [c1[0], c1[1], c2[0], c2[1]], '%.2f' % conf])
number_i += 1 # 编号数+1
label = '%s %.2f' % (names[int(cls)], conf)
# 画出检测到的目标物
plot_one_box(image, xyxy, label=label, color=colors[int(cls)])
# 实时显示检测画面
cv2.imshow('Stream', image)
# if cv2.waitKey(1) & 0xFF == ord('q'):
# break
c = cv2.waitKey(0) & 0xff
执行得到的结果如下图所示,图中火焰位置和置信度值都标注出来了,预测速度较快。基于此模型我们可以将其设计成一个带有界面的系统,在界面上选择图片、视频或摄像头然后调用模型进行检测。

博主已经对系统的所有功能进行了详细测试,最终开发出一版流畅得到清新界面,就是博文演示部分的展示,完整的UI界面、测试图片视频、代码文件,以及Python离线依赖包(方便安装运行,也可自行配置环境),均已打包上传,感兴趣的朋友可以通过下载链接获取。

下载链接
若您想获得博文中涉及的实现完整全部程序文件(包括测试图片、视频,py, UI文件等,如下图),这里已打包上传至博主的面包多平台,见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:
在文件夹下的资源显示如下,下面的链接中也给出了Python的离线依赖包,读者可在正确安装Anaconda和Pycharm软件后,复制离线依赖包至项目目录下进行安装,离线依赖的使用详细演示也可见本人B站视频:win11从头安装软件和配置环境运行深度学习项目、Win10中使用pycharm和anaconda进行python环境配置教程。
注意:该代码采用Pycharm+Python3.8开发,经过测试能成功运行,运行界面的主程序为runMain.py和LoginUI.py,测试图片脚本可运行testPicture.py,测试视频脚本可运行testVideo.py。为确保程序顺利运行,请按照requirements.txt配置Python依赖包的版本。Python版本:3.8,请勿使用其他版本,详见requirements.txt文件;
环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文件下载请见参考博客文章里面,或参考视频的简介处给出:➷➷➷
完整代码下载:https://mbd.pub/o/bread/ZJaXlJdw
参考视频演示:https://www.bilibili.com/video/BV1u24y1t7xo/
离线依赖下载:https://pan.baidu.com/s/1hW9z9ofV1FRSezTSj59JSg?pwd=oy4n(提取码:oy4n)
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具