基于支持向量机的图像分类(上篇)
 本文通过图文详细介绍如何利用支持向量机对图像进行分类。这篇文章从什么是图像分类任务开始一步步详细介绍支持向量机原理,以及如何用它解决图像多分类任务。将这部分内容分为上下两篇:上篇重点详细介绍实现原理,下篇衔接上篇进行编程实现并对程序进行解释,本篇为上篇。本文将主要介绍以下几个方面:图像分类任务、收集训练集与测试集、支持向量机分类基本原理、特征选择与提取、用SVM 进行图像分类、分类结果评价。
本文通过图文详细介绍如何利用支持向量机对图像进行分类。这篇文章从什么是图像分类任务开始一步步详细介绍支持向量机原理,以及如何用它解决图像多分类任务。将这部分内容分为上下两篇:上篇重点详细介绍实现原理,下篇衔接上篇进行编程实现并对程序进行解释,本篇为上篇。本文将主要介绍以下几个方面:图像分类任务、收集训练集与测试集、支持向量机分类基本原理、特征选择与提取、用SVM 进行图像分类、分类结果评价。
摘要:本文通过图文详细介绍如何利用支持向量机对图像进行分类。这篇文章从什么是图像分类任务开始一步步详细介绍支持向量机原理,以及如何用它解决图像多分类任务。将这部分内容分为上下两篇:上篇重点详细介绍实现原理,下篇衔接上篇进行编程实现并对程序进行解释,本篇为上篇。本文将主要介绍以下几个方面:
- 图像分类任务
- 收集训练集与测试集
- 支持向量机分类基本原理
- 特征选择与提取
- 用SVM 进行图像分类
- 分类结果评价
实现代码博文参考:基于支持向量机的图像分类(下篇:MATLAB实现))
博主相关博文参考:基于支持向量机的图像分类系统(MATLAB GUI界面版)
博主其他博文参考:基于支持向量机的手写数字识别详解(MATLAB GUI代码,提供手写板)
1. 图像分类任务
图像分类是模式分类(Pattern C1assification)在图像处理中的应用,它完成将图像数据从二维灰度空间转换到目标模式空间的工作。分类的结果是将图像根据不同属性划分为多个不同类别的子区域。一般地,分类后不同的图像区域之问性质差异应尽可能的大,而区域内部性质应保证平稳特性。
应用SVM进行分类的步骤如下:首先收集各个类的训练集和测试集,接着选择合适的用来分类的图像特征,从训练集中提取特征,然后用SVM分类器训练从而得到分类模板,最后通过模板对待分类图像进行分类。
2. 收集训练集与测试集
在进行图像分类前,从待处理的数据中取出相当数量的具有代表性的数据作为训练样本。另外,取出一定数量的样本作为测试样本。这个工作很重要,在算法上没有改进的空间时,通常通过建立好的训练集来提高分类效果。训练集要满足以下的条件:(1)训练集要有代表性。(2)训练集中不能有错误的样本。(3)训练集要尽量完备
cifar10图像集是常用的图像分类数据集,由多伦多大学的Geoffrey Hinton教授等人收集整理,包含了60000张大小为32*32的彩色图像,其中50000张作为训练数据,10000张用于测试数据。50000张训练图片分为5个子集,分别命名为data_batch_1~5。每个子集都包含正好10000张图片,cifar10包含的图片类别如下图所示

3. 支持向量机分类基本原理
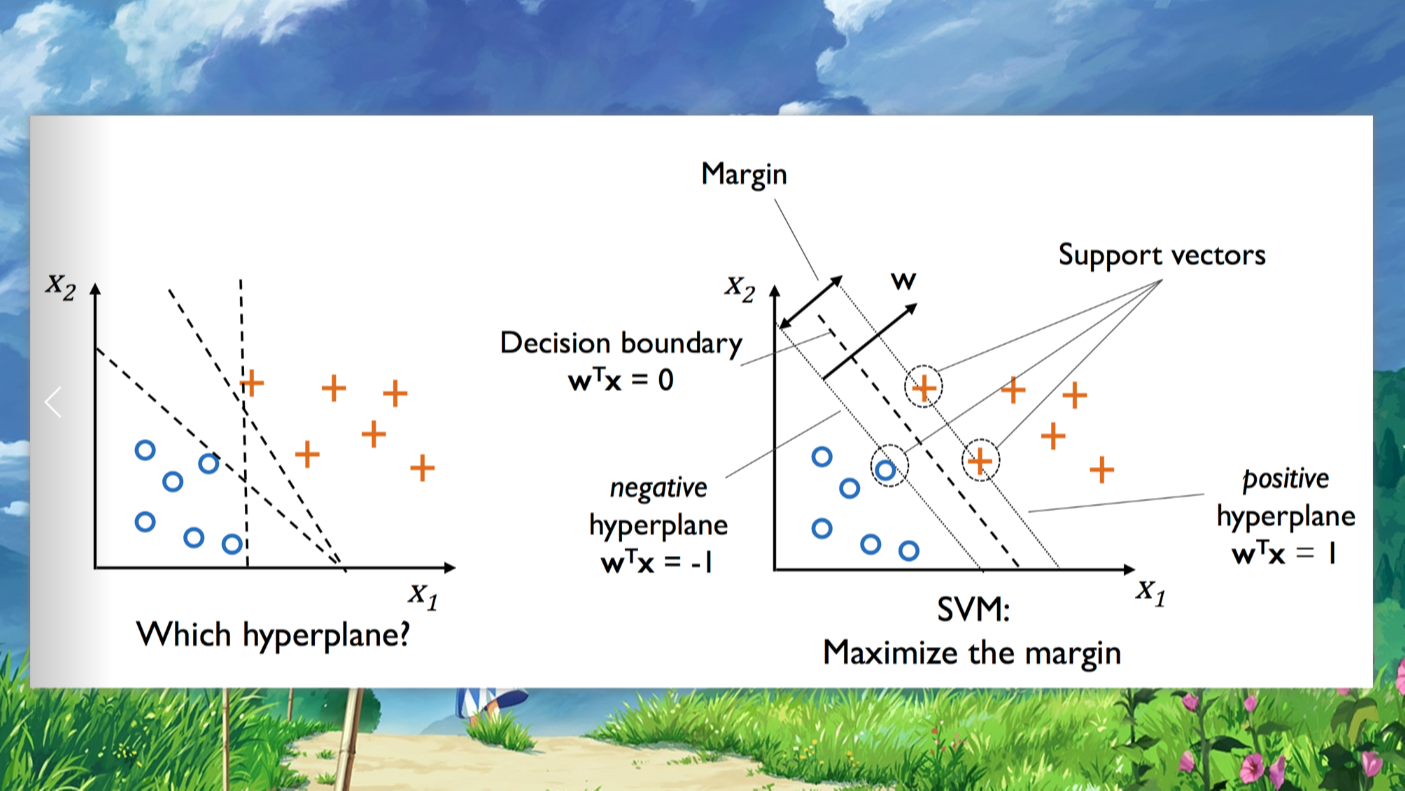
SVM是以最优化理论为基础来处理机器学习的新方式。它的提出主要是用来解决两类分类的问题,在两类中寻找一个最优超分平面将两类分开,来提高分类的正确率。
分类问题主要包括两方面:一个是线性可分,一个是非线性可分。能使两类正确分开且使两类之间的距离最大的分类平面称为最优超平面,其方程记为:
对其进行归一化,使得样本
满足
是表示的是最优分类超平面,图中m1为分类超平面,m2、m3分别为与超分平面平行且是过两类中离分类超平面最近的样本,他们间的距离称作分类间隔,间距为。
3.1 线性可分情况
设线性可分样本集为,,则超平面,使得训练样本中的正类输入和负类输入分别位于该超平面的两侧。即存在参数对,使得,即最优分类平面应使两类之间的间隔最大,则求取最优平面问题转化为了下面的优化问题:
其中,为约束的拉格朗日乘子,因为都是不等式约束,所以这些乘子都是非负的。对式(1)求偏导得:
此式称为式(1)的对偶形式。同时,优化问题的最优解必须满足如下KKT条件:,任意,可求得b。因为$\sum_{i=1}^{N}a_i y_i=0 a_ia_i$不等于0所对应的样本称为支持向量
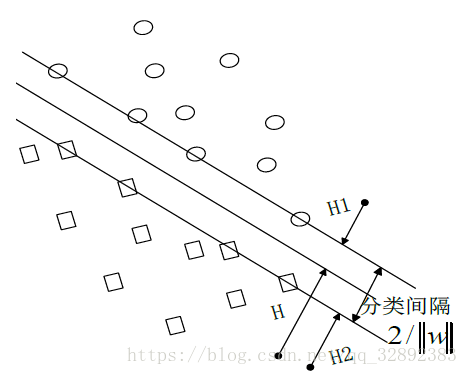
分类平面由支持向量确定,也就是说只需少量样本就可构成最优分类面。
3.2 非线性可分
支持向量机实现非线性分类是通过某种事先选择的非线性映射(核函数)将输入向量映射到一个高维特征空间,在这个空间中构造最优分类超平面。使用SVM进行数据集分类工作的过程中,首先是通过预先选定的一些非线性映射将输入空问映射到高维特征空间。变换后空间的分类平面为:,和线性情况类似,优化方程为:
其中,是]是变换后的空间内积。此时,我们并不知道的具体形式。

如果能在原空问构造一个函数使之等于变换后空间的内积运算,那么尽管通过非线性变换将样本数据映射到高维甚至无穷维空问,并在高维空间中构造最优分类超平面。但是,在求解最优化问题和计算分类平面时并不需要显式计算该非线性函数,甚至不需知道其具体形式。而只需计算函数,即核函数。常用的核函数如下所示,这些核函数已被证明适合绝大部分非线性分类问题。
- 多项式核函数:;
- 基于径向基函数RBF核函数形式:;
- Sigmoid核函数:。
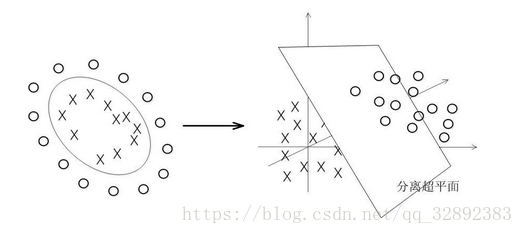
SVM数据集形成的分类函数具有这样的性质:它是一组以支持向量为参数的非线性函数的线性组合。因此,分类函数的表达式仅和支持向量的数量有关,而独立于空间的维度。在处理高维输入空间的分类时,这种方法尤其有效。
3.3 一对一SVM(1-VS-1 SVMS)
支持向量机是用来处理二分类问题的,但现实中碰到的多是多类分类问题,因此支持向量机采用不同方式来达到多类分类的目的。目前支持向量机多类分类方法主要分为两个方向:一个是一次求解法,即通过一个优化的公式来优化所有类别的参数:还有一种通过组合多个SVM分类来解决多类分类问题。
一对一方式就是对每两个类样本之问构建出一个分类超平面,所有K类样本共能构造出K(K一1)12个分类超平面。具体分类操作如下:
取出所有满足条件,通过两分类法构造最优分类函数:
这种方式的优点:对于每个子,由于训练样本少,因此其训练速度显而易见快于l对多SVM方式,同时其精度也较高。这种方式的缺点:随着类数K的增多,SVM的个数也越来越大,随着k个数的增多,其训练速度也会越来越慢,这是需要改进的地方。
4. 特征选择与提取
特征的选择过程分为两个步骤:(1)目测。对两类图像的颜色、纹理、形状进行分析,选择可能分开两类的特征。(2)实验。提取特征,用SVM进行训练,看测试效果好坏来决定是否进行优化(如分块)或更换其他特征。本文实验中选择了2个特征:方向梯度直方图、灰度共生矩阵。
4.1 方向梯度直方图
HOG特征描述子,它通过计算和统计图像局部区域的梯度方向直方图来构成特征,广泛应用于图像处理中进行物体检测。提取HOG特征包括以下几个步骤:
1) 归一化图像。首先把输入的彩色图像转灰度图像,然后对图像进行平方根Gamma压缩,从而达到归一化效果。这种压缩处理能够有效地降低图像局部的阴影和光照变化,从而提高HOG特征对于光照变化的鲁棒性。
2) 计算图像梯度。首先用一维离散微分模版[-1,0,1]及其转置分别对归一化后的图像进行卷积运算,得到水平方向的梯度分量以及垂直方向的梯度分量。然后根据当前像素点的水平梯度和垂直梯度,得到当前像素点的梯度幅值和梯度方向。公式如下:
其中,分别表示当前像素点的水平梯度,垂直梯度和像素值。分别为当前像素点的梯度幅值和梯度方向。
3) 为每个细胞单元构建梯度方向直方图。首先把尺寸为64×128的图像分为8×16个cell,即是每个cell为8×8个像素。然后把梯度方向限定在[0, π],并将梯度方向平均分为9个区间(bin),每个区间20度。最后对cell内每个像素用梯度方向在直方图中进行加权投影,也就是说cell中的每个像素点都根据该像素点的梯度幅值为某个方向的bin进行投票,这样就可以得到这个cell的梯度方向直方图,也就是该cell对应的9维特征向量。
4) 把细胞单元组合成大的块(block),块内归一化梯度直方图。把相邻的2×2个cell形成一个block,这样每个block就对应着36维的特征向量。由于局部光照的变化以及前景和背景对比度的变化,使得梯度强度的变化范围非常大。为了进一步消除光照的影响,最后对block内的36维特征向量进行归一化。公式如下:
其中,v 是未经归一化的描述子向量是v的2范数,ε是一个极小的常数。
5) 收集HOG特征。如图1所示,采用滑动窗口的方法,用block对样本图像进行扫描,扫描步长为一个cell,所以block之间其实是有重叠的。最后把所有归一化后的block特征串联起来就得到3780维特征向量。

4.2 灰度共生矩阵
一幅图像的灰度共生矩阵能反映出图像灰度关于方向、相邻间隔、变化幅度的综合信息,它是分析图像的局部模式和它们排列规则的基础。1973年Haralick从纯数学的角度,研究了图像纹理中灰度级的空间依赖关系,提出灰度共生矩阵的纹理描述方法,其实质是从图像中灰度为i的像素(其位置为(x,y))出发,统计与其距离为d灰度为J的像素(x+Dx,y+Dy)同时出现的次数p(i,j,d,θ),数学表达式为:式中:是图像中的像素坐标;是灰度级;是位置偏移量;d为生成灰度共生矩阵的步长;θ生成方向,可以取四个方向,从而生成不同方向的共生矩阵。要使其特征值不受区域范围的影响,还需对此灰度共生矩阵进行归一化处理:
由灰度共生矩阵能够导出许多纹理特征,可以计算出14种灰度共生矩阵特征统计量。对图像上的每一像元求出某种邻域的灰度共生矩阵,再由该灰度共生矩阵求出各统计量.就得到对应纹理图像的统计量。若干统计量可以组成图像分类的特征向量。
这四个特征之间不相关,可以有效地描述光学或遥感图像的纹理特征,便于计算又具有较好的鉴别能力。由于要处理的原始图像灰度级比较大,从计算时间和纹理可分性上对其灰度级压缩至9级,考虑到参数的旋转不变性,选取4个方向上的均值作为纹理特征参数,步长d为1。由灰度共生矩阵的的定义进而求出原始图像的灰度共生矩阵,并依据公式进行归一化处理,计算出灰度共生矩阵下的4个纹理特征,作为分类器的输入。
5. 用SVM进行图像分类
在支持向量机中,采用不同的内积函数将导致不同的支持向量机算法,因此内积函数的选择对支持向量机的构建有重要作用,本文采用高斯径向基核函数,从而得到径向基函数分类器,因为RBF核可以将样本映射到一个更高维的空间,它可以处理类标签与特征之间的非线性关系,是局部性很强的核函数,具有相当高的灵活性,也是使用最广泛的核函数。使用RBF核函数时要考虑两个参数C 和γ,好的(C,γ)能使分类器正确的预测未知数据,得到高的训练正确率,即分类器预测类别标签的正确率。
图像库选用我们从COREL 图像库中选取4个类别共1000幅图像组成图像数据库,它们包括车辆、猫、花朵、鱼等各100幅图,图4.1 为图像库的每一类的四幅示例图像。随机选取每一类的70幅作为训练数据,剩下的30幅作为测试数据。通过实验比较在提取的各种图像特征加权前后通过支持向量机进行分类的结果。
6. 分类结果评价
混淆矩阵是模式识别领域中一种常用的表达形式。它描绘样本数据的真实属性与识别结果类型之间的关系,是评价分类器性能的一种常用方法。假设对于N 类模式的分类任务,识别数据集D包括个样本,每类模式分别含有个数据(i=1,…,N)。采用某种识别算法构造分类器C ,表示第i类模式被分类器C判断成第j类模式的数据占第i类模式样本总数的百分率,则可得到N×N 维混淆矩阵CM(C,D):
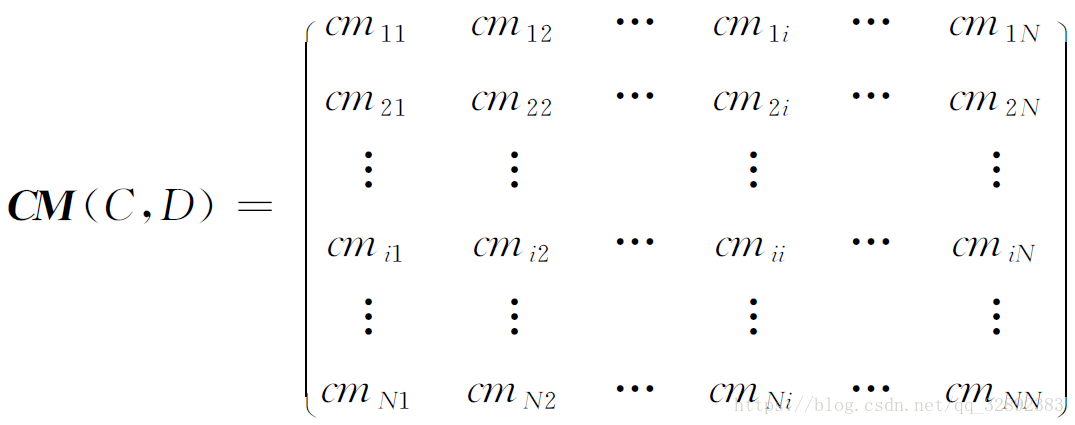
将提取得到的特征向量作为SVM的输入。其中图像划分以及特征提取均利用matlabR2016b完成。利用LIBSVM训练图像的语义分类。我们选取车,猫,花,鱼四类图像。每类图像100幅,按7:3的比例分成训练集和测试集。
本文主要从基本原理上简单介绍了支持向量机,了解了基本原理接下来就需要用程序实现为我所用,具体如何用实现在下篇博文中将详细介绍。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)