用深度强化学习玩FlappyBird
 学习玩游戏一直是当今AI研究的热门话题之一。使用博弈论/搜索算法来解决这些问题需要特别地进行周密的特性定义,使得其扩展性不强。使用深度学习算法训练的卷积神经网络模型(CNN)自提出以来在图像处理领域的多个大规模识别任务上取得了令人瞩目的成绩。本文是要开发一个一般的框架来学习特定游戏的特性并解决这个问题,其应用的项目是受欢迎的手机游戏Flappy Bird,控制游戏中的小鸟穿过一堆障碍物。本文目标是开发一个卷积神经网络模型,从游戏画面帧中学习特性,并训练模型在每一个游戏实例中采取正确的操作。本文综述了基于深度学习的卷积神经网络模型在模式识别(图像识别)中的应用,主要从典型的网络结构的构建、训练方法和性能表现3个方面进行介绍。
学习玩游戏一直是当今AI研究的热门话题之一。使用博弈论/搜索算法来解决这些问题需要特别地进行周密的特性定义,使得其扩展性不强。使用深度学习算法训练的卷积神经网络模型(CNN)自提出以来在图像处理领域的多个大规模识别任务上取得了令人瞩目的成绩。本文是要开发一个一般的框架来学习特定游戏的特性并解决这个问题,其应用的项目是受欢迎的手机游戏Flappy Bird,控制游戏中的小鸟穿过一堆障碍物。本文目标是开发一个卷积神经网络模型,从游戏画面帧中学习特性,并训练模型在每一个游戏实例中采取正确的操作。本文综述了基于深度学习的卷积神经网络模型在模式识别(图像识别)中的应用,主要从典型的网络结构的构建、训练方法和性能表现3个方面进行介绍。
摘要:学习玩游戏一直是当今AI研究的热门话题之一。使用博弈论/搜索算法来解决这些问题需要特别地进行周密的特性定义,使得其扩展性不强。使用深度学习算法训练的卷积神经网络模型(CNN)自提出以来在图像处理领域的多个大规模识别任务上取得了令人瞩目的成绩。本文是要开发一个一般的框架来学习特定游戏的特性并解决这个问题,其应用的项目是受欢迎的手机游戏Flappy Bird,控制游戏中的小鸟穿过一堆障碍物。本文目标是开发一个卷积神经网络模型,从游戏画面帧中学习特性,并训练模型在每一个游戏实例中采取正确的操作。本文综述了基于深度学习的卷积神经网络模型在模式识别(图像识别)中的应用,主要从典型的网络结构的构建、训练方法和性能表现3个方面进行介绍。
1. 前言
作为深度强化学习的一个很好的入门学习教程,用深度强化学习玩FlappyBird这个示例一直是个很火的代码,网上也有不少的文章介绍。不过其大多从代码角度介绍,如果需要输入了解其理论与原理我们则需要更多论文资料。这里我翻译整理了相关论文并加入些自己的理解写在这篇博文中,详细可参考论文Deep Reinforcement Learning for Flappy Bird,具体关于深度强化学习的代码介绍将在后面的博文中介绍。
2. 简介及问题定义
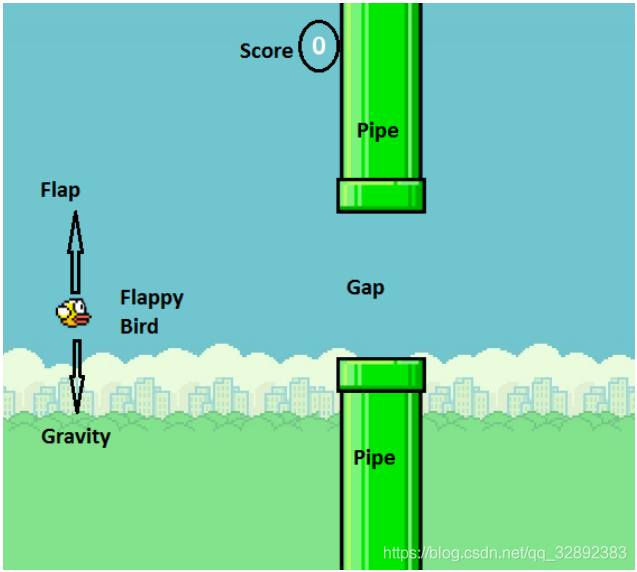
FlappyBird是一款游戏,玩家控制的对象是游戏中的“小鸟”,在游戏运行瞬间有两个可以采取的动作:按下“上升”键,使得小鸟向上跳跃,而未按下任何按键时小鸟则以恒定速率下降。
如今,深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示,使得机器学习模型可以直接学习概念,如直接从原始图像数据进行物体类别分类。深层卷积神经网络采用平铺分层卷积滤波器层来模拟视野接受域的影响,在处理计算机视觉问题上,如分类和检测问题,获得了很大成功。本文目的是开发一个深层神经网络模型,具体地,是利用图像中的不同对象训练卷积神经网络,进行基于游戏画面场景状态分析进行图像识别分类。从原始像素中学习游戏的特性,并决定采取相应行动,本质上是一个对游戏场景中特定状态的模式识别过程,在此设计了一个强化学习系统,通过自主学习来玩这款游戏。
当通过很少预定的行为进行编程不能充分解决问题时,可采用强化学习方式,这是一种通过进行场景训练,使算法在输入未知和多维数据(如彩色图片)时做出正确的决策方式。通过这种方式,可以进行在线学习,而且算法可以学会自动对图像进行特征提取,对于训练中未出现的场景和状态也同样可以进行分类和预测。
3. 相关工作与实现方法
3.1 相关工作
谷歌DeepMind利用深度学习技术玩游戏的影响,为从一个完全不同的视角去看待人工智能问题铺平了道路。其最新成果人工智能AlphaGo,在其与围棋大师的激烈竞争中向人们展示了深度学习的巨大潜力。DeepMind以前仅仅根据游戏原始图片就能学习和玩2600种雅达利游戏。Mnih等人,使用强化学习成功训练玩这些游戏的模型,在多种游戏[1],[2]中超过了人类专家级别。他们提出了一种新的模型,即结合了深层神经网络的强化学习的深度Q网络(DQN)模型,以深层神经网络作为近似函数代表Q学习中的Q值(动作值)。他们还论述了一些提高训练效率和稳定性的技术,使用以前经验的“经验回放”,从中随机抽取小批量来更新网络,以便将模型得到的经验和延迟更新联系起来,从而获得目标值(稍后详细介绍)以提高稳定性。该通道的另一个优点是完全无需标记的数据,该模型通过与游戏模拟器的交互,并随着时间的推移学会做出很好的决策。正是这种简单的学习模型以及在玩Atari游戏时的惊人结果,启发我们采用一个类似的算法来完成本文所涉及的项目。
3.2 实现方法
本文是通过训练一个深度卷积神经网络模型(深度Q学习网络)进行特定游戏状态下图像的识别与分类。深度Q学习网络是一个经改进过的Q学习算法训练得到的卷积神经网络,其输入是原始的游戏画面,输出是一个评价未来奖励的价值函数。人工智能系统的任务是提取游戏运行的图像,并输出从可采取的操作集合中提取的必要执行动作。这相当于一个分类问题,不过与常见的分类问题不同,这里没有带标记的数据来训练模型。可以采用强化学习,根据执行游戏并基于所观察到的奖励来评价一个给定状态下的动作,以此来进行模型训练。
3.3 构建模型
游戏中小鸟可以采取的动作是煽动翅膀向上飞()或不做任何动作()。当前状态(框架)是由经预处理的当前帧原始图像()与有限数量的先前帧图像(, ,…)构成。这样,每一个状态都将唯一地对应小鸟运动到某一位置所遵循的运动轨迹,从而向模型提供实时信息,先前存储的帧数成为超参数。理想情况下,是从开始的所有帧的函数,不过为了减少状态空间,只使用有限的数量帧。如前所述,当鸟撞到管道或屏幕边缘时,可以给其一个负面奖励,如果通过了间隙,可得到一个正面的奖励。这样可以像人类玩家一样,尽量避免死亡并尽可能多得分。因此,有两个奖励,分别是rewardPass和rewardDie。折扣系数()为0.9,用于从未来动作贴现的奖励。
4. Q学习算法
强化学习的目标是使总回报(奖励)最大化。在Q学习中,它是非策略的,迭代更新使用的是贝尔曼方程 其中和分别是下一帧的状态和动作,是奖励,是折扣因子。是为矩阵在第i次迭代的Q值。这种更新迭代将收敛得到一个最佳的Q函数。为了防止学习僵化,这个动作值函数可以用一个函数(这里为深度学习网络)近似,以便能更好概括不可预见的状态。学习算法的输入点由, , , ,的列表构成,函数能够通过这些输入点来构建一个能最大限度提高整体回报并以此预测动作的模型。将这里的函数构建为一个卷积神经网络,并使用上述方程中的更新规则更新其参数。以下两个方程为使用损失函数及其梯度来模拟这个函数。
其中,是训练后的DQN参数, (在后面的章节中解释)是Q值函数的非更新参数。因此,可以简单地使用上述损失函数的随机梯度下降法和反向传播算法更新神经网络权重()。算法1是为训练而设计的算法,是一种加强探索的贪婪算法。当训练进行时,有的概率会随机选择动作或选择最优动作,其中随着更新次数的增加逐渐减小到0。
4.1 预处理
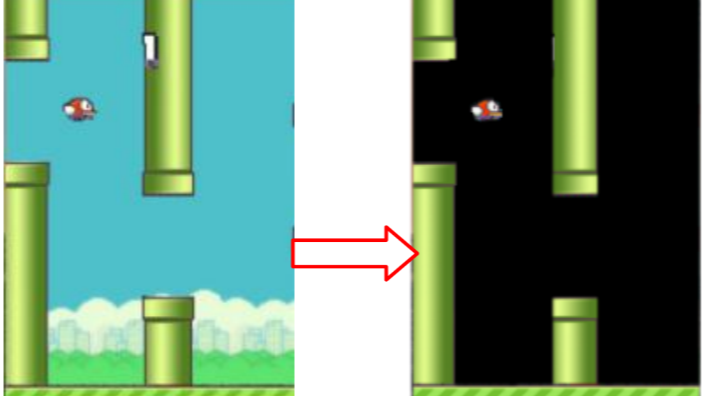
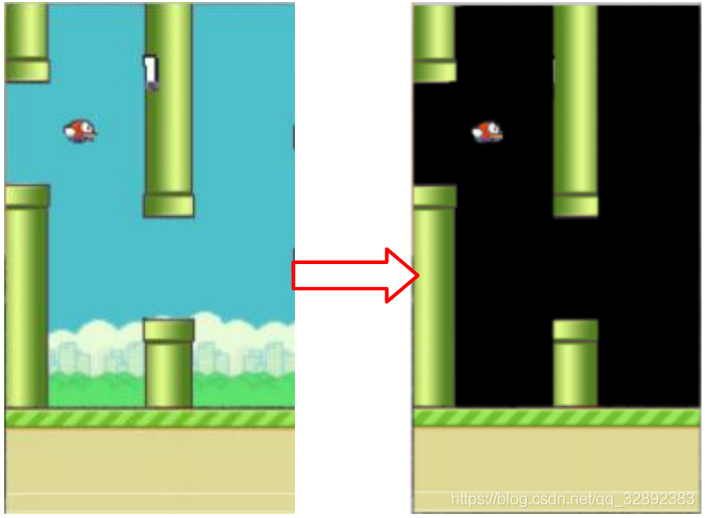
Flappy Bird游戏直接输出的像素是284×512的,但为了节省内存将其缩小为84×84大小的图像,每帧图像色阶都是0-255。此外,为了提高卷积神经网络的精度,在这一步去除背景层并用纯黑色背景代替,以去除噪声,如图2所示。依次对所得游戏图像进行缩放、灰度化以及调整亮度处理。在当前帧进入一个状态之前,处理几帧图像叠加组合的多维图像数据(如在模型构建部分提到的),当前帧与先前帧重叠时,灰度稍有降低,当我们远离最新帧时强度降低。因此,这样输入的图像将提供关于小鸟当前所在轨迹的良好信息,其处理过程如图3所示。
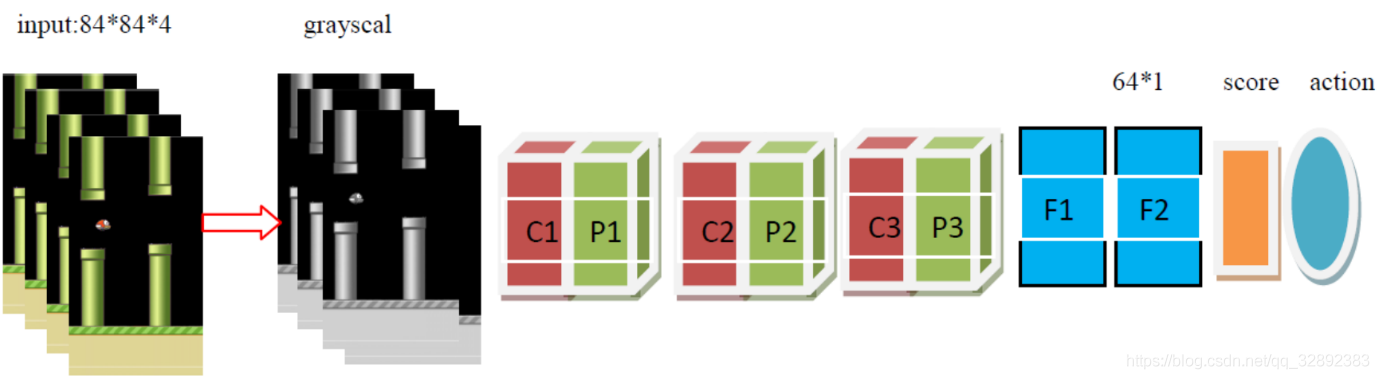
4.2 DQN结构
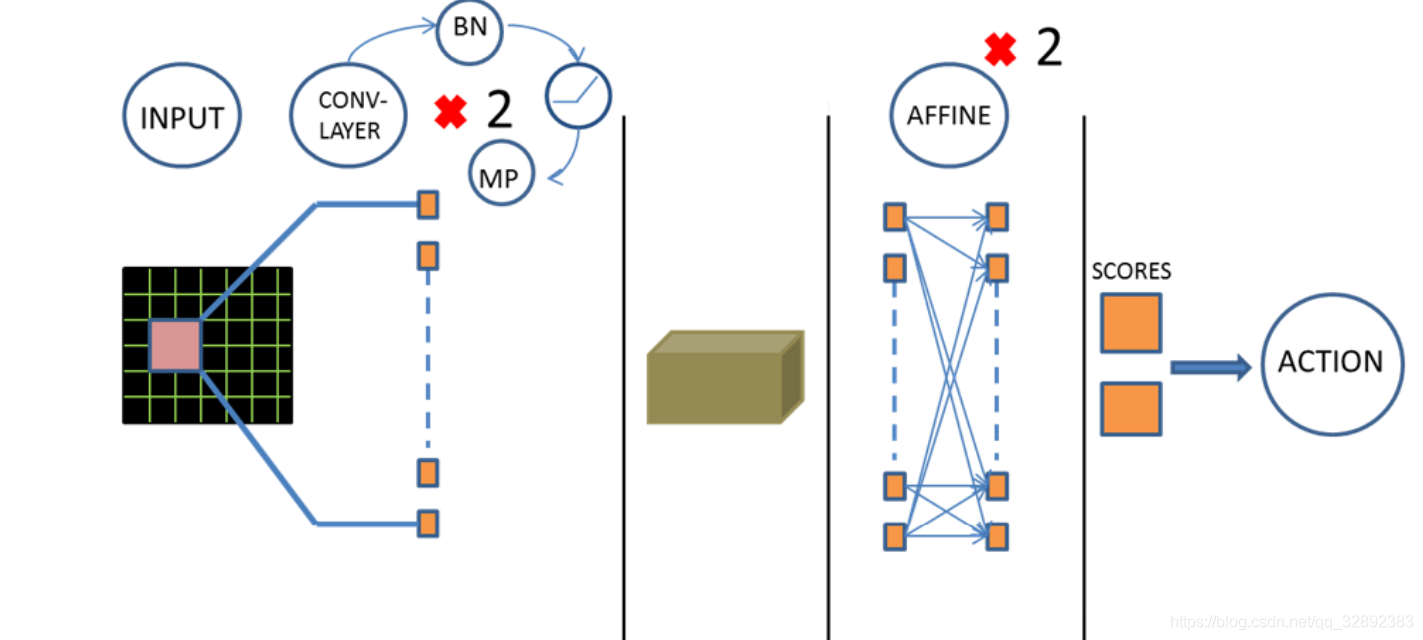
如图4所示,在当前模型结构中,有3个隐藏层。首先有两个卷积层,然后是两个完全连接层,最终完全连接层的输出是两个动作的得分,结果由损失函数得出。改进的损失函数自动进行Q学习参数设置。遵循空间批量规范,在每个卷积层后都添加ReLu和最大池化层。此外,在第一个仿射层(该批规范输出反馈到最终的仿射层)后是一个ReLu激活函数和批量处理标准层。卷积层采用32个大小为3,步长为1,带有2×2最大池化核的滤波器。输入图像的大小84×84,每个时刻有两种可能的输出操作,每次动作将会获得一个得分值,以此决定最佳动作。
| Layer | Input | Filter size | Stride | Num filters | Activation | Output |
|---|---|---|---|---|---|---|
| conv1 | 84×84×4 | 8×8 | 4 | 32 | ReLU | 20×20×32 |
| pooling1 | 20×20×32 | 10×10×32 | ||||
| conv2 | 10×10×32 | 3×3 | 1 | 64 | ReLU | 8×8×64 |
| pooling2 | 8×8×64 | 4×4×64 | ||||
| conv3 | 4×4×64 | 3×3 | 1 | 64 | ReLU | 2×2×64 |
| pooling3 | 2×2×64 | 1×1×64 | ||||
| Fc1 | 1×1×4 | 64×1 | ||||
| Fc2 | 1×64 | 2×1 |
考虑到模型处理的精度,可以适当提高模型的复杂度,这里将卷积层的数目改进为3个,同时有3个池化层,两个全连接层,开始时叠加连续4帧预处理后的图像作为输入,表1详细列出了后的模型在每个步骤上的数据尺寸变化及各层参数。
4.3 经验回放与稳定性
在Q学习中,以连续方式记录的经验数据是高度相关的。若使用相同的顺序更新DQN参数,训练过程就会受到干扰。与从一个标记的数据集中采样小批量训练分类模型类似,这里同样应该在抽取出的获得更新的DQN经验中引入一定的随机性。为此设置一个经验回放存储器,用来存储每帧游戏画面的经验数据(,,,),直到达到其最大存储容量。重现的经验数据填充到一定的数量,随机抽取小批经验并用于进行DQN参数上的梯度下降。以固定的时间间隔更新DQN参数。由于小批量选择结果的随机性,用于更新DQN参数的数据是去相关的。
为了提高损失函数收敛的稳定性,使用方程2中提到的带参数的贝尔曼更新方程重现DQN模型。参数是每次DQN的C值更新之后的更新值,用来计算算法1中的值。
4.4 训练设计
整个DQN训练流程如算法1所示。如本节前面部分提到的,经验数据都存储在回放存储器中,每隔一段时间,从存储器随机采样出一小批样本,用于对DQN参数进行梯度下降运算。同网络参数一样,必要时需要适当更新探索的概率。

游戏输出的得分作为唯一的评价指标,为了使结果具有健壮性,取几次游戏的平均得分而不是一次的得分。设置一个衰减值,使因子在测试和训练中逐渐减小为零。这是在更多的训练和学习时,进行模型决策的保证。
5. 实验与结果
5.1 训练参数
模型参数:Flappy Bird游戏每秒播放10帧,最近的4帧图像处理后进行组合,生成一个状态;贴现因子设置为0.9;奖励设置:rewardPass = + 1.0, rewardDie=-1.0。
DQN参数:探索概率在600000更新中从0.6线性下降到0。回放存储器的大小设置为20000,每有500次经验,就对存储器数据进行一次小批量采样。每次C更新到100时,目标模型的参数更新一次。小批量的32次经验数据中,随机抽取每5帧更新DQN参数。
训练参数:来更新DQN参数的梯度下降更新法是学习率为,,的Adam优化器。在试错基础上选择这些参数,用来观察损失值的收敛性。卷积权重初始化为均值为0,方差为的正态分布。
5.2 结果与分析
训练结束后,用模型测试了一些游戏状态,以检测是否能得出合理的结果。图5示出了一些游戏场景及其相应的预测分数,其结果显示模型准确地对状态进行了分类。
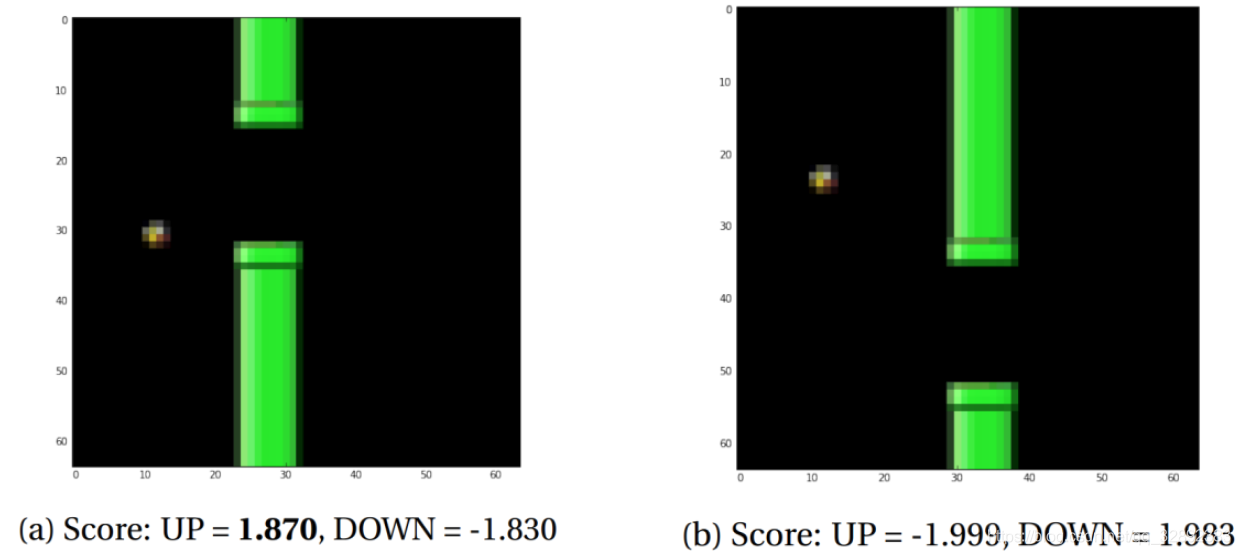
为了更好地理解经过训练的卷积神经网络模型的工作原理,输出图像5b在经过卷积层后的图像,以实现可视化。可以看出,大多数激活显示出空隙和鸟的边缘处清晰的斑块(图6)。可以明显地推断,神经网络在学习寻找小鸟与空隙的相对位置。

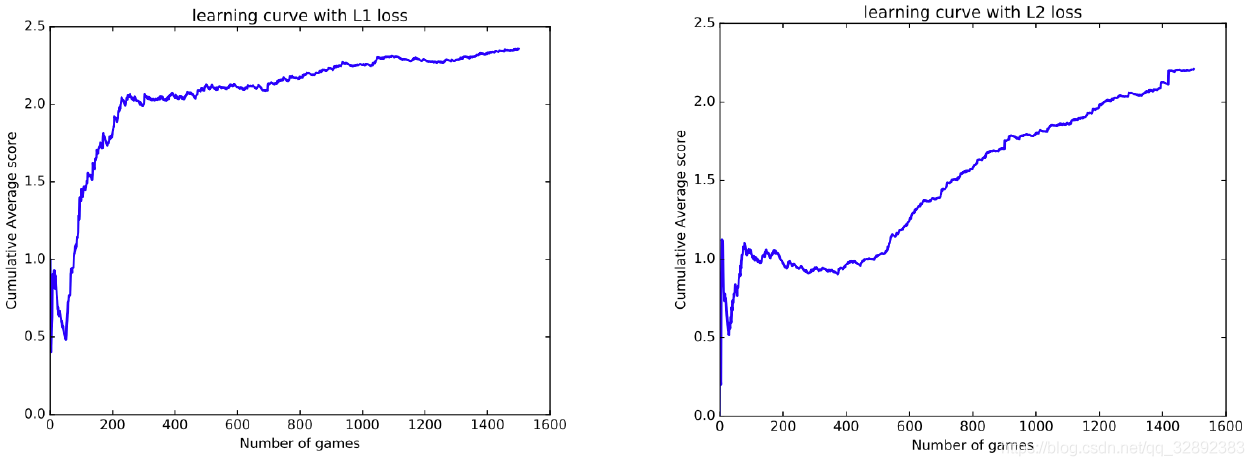
在大多数的在雅达利游戏上所做得实验[3],采用L2的损失函数。这里尝试了L1的损失函数(下式)来引入一些正则化。这使得学习率的图像一开始就非常陡峭,如图7所示。通过这两种情况可以看出,平均得分稳步上升,表明该模型正在稳步学习。
从表2中可以看出,训练出的DQN模型取得了远超人类水平的良好成绩,在这样一个角色扮演的动画游戏中,可以看到,尽管有时鸟儿会死亡,但它总是力图通过水管间的空隙,最可能撞毁的是在间隙的边缘处。对此可以做的是提高模型的能力,可行的解决方案是使用不同的奖励方案,让小鸟走一条远离管道顶部和底部的路径。而人类玩家在玩游戏时也是尽力使小鸟保持在水管间隙中心位置,这同样可以通过一个精心设计的奖励方案实现。
| Human | DQN with L1 | DQN with L2 | |
|---|---|---|---|
| Avg score | 4.25 | 65 | 72 |
| Max score | 21 | 215 | 309 |
5.3 训练时间
| Training iterations | Score |
|---|---|
| 99000 | 43.6 |
| 199000 | 101.8 |
| 299000 | 35.7 |
| 399000 | 201.3 |
训练迭代的次数指的是DQN更新的次数,结果如表3所示,可以看出,更多的训练次数并不意味着一定能提高模型预测结果的准确性(这里是对瞬时游戏状态下,最佳执行动作的判断分类)。实际上,更多次的训练存在许多不稳定性以及结果振荡情况,过多次数的训练,模型会出现过拟合情况。这些情况需要在进一步的研究中加以解决,一个可能采取的解决方法是训练时减小学习率或者构建复杂度神经网络模型。
6. 结束语
本文能够成功地运用深度的强化学习模型来玩游戏FlappyBird,和传统的分类任务不同,这里进行图像识别任务采用的加强学习有个重要优点,即不需要带标记的数据,完成前面叙述的工作后即可保存训练好的模型。模型实现了特定游戏状态(模式)下,游戏执行的最佳动作预测,成功将一个游戏决策问题转换成对瞬时多维图像的分类识别问题并运用卷积神经网络加以解决。总的来说,结果显示了深度神经网络在处理图像信息上的能力,这为许多潜在的应用开辟了道路。
除了强化学习的方式,完成FlappyBird游戏也可以采用其他方法,如论文Exploring Game Space Using Survival Analysis的通过生存分析的方法,有兴趣的可以查阅原文。由于博主能力有限,博文中提及的方法与代码即使经过测试,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。
参考文献:
[1] C. Clark and A. Storkey. Teaching deep convolutional neural networks to play go. arXiv preprint arXiv:1412.3409, 2014. 1, 2
[2] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013. 1, 2
[3] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al. Human-level control through deep reinforcement learning. Nature, 518(7540):529–533, 2015. 3, 5
[4] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, et al. Mastering the game of go with deep neural networks and tree search. Nature, 529(7587):484–489, 2016. 1


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义