UCI数据集详解及其数据处理(附148个数据集及处理代码)
 摘要:本文对机器学习中的UCI数据集进行介绍,带你从UCI数据集官网出发一步步深入认识数据集,并就下载的原始数据详细讲解了不同类型的数据集整理如何通过程序进行整理。为了方便使用,博文中附上了包括数据集整理及数据预处理在内的所有代码及处理好的数据集,同时对代码进行了解释,其要点如下:UCI数据集介绍、不同数据集的整理程序、148个整理好的数据集与对应程序。
摘要:本文对机器学习中的UCI数据集进行介绍,带你从UCI数据集官网出发一步步深入认识数据集,并就下载的原始数据详细讲解了不同类型的数据集整理如何通过程序进行整理。为了方便使用,博文中附上了包括数据集整理及数据预处理在内的所有代码及处理好的数据集,同时对代码进行了解释,其要点如下:UCI数据集介绍、不同数据集的整理程序、148个整理好的数据集与对应程序。
摘要:本文对机器学习中的UCI数据集进行介绍,带你从UCI数据集官网出发一步步深入认识数据集,并就下载的原始数据详细讲解了不同类型的数据集整理如何通过程序进行整理。为了方便使用,博文中附上了包括数据集整理及数据预处理在内的所有代码及处理好的数据集,同时对代码进行了解释,其要点如下:
下载链接:博主在面包多网站上的完整资源下载页
前言
UCI数据集作为机器学习算法比较中的绝对经典经常出现在大多数论文或研究中。为了验证机器学习算法性能,UCI数据集通常用作为通用数据集,但官网提供的原始数据可能有格式不一致、缺失数据、包含特殊字符等问题,通常不能直接用于算法程序中,数据集的查找、下载、整理等可能会给初学者带来一定困扰。

对于数据集的查找整理确实是件费时费力的事情,是不是总有“论文就一篇,数据找半天”的问题?这里就来探讨下数据集整理的那些事。其实早前作者就写了一篇关于UCI数据集处理的博文:UCI数据集整理(附论文常用数据集)介绍了如何用程序整理数据集,这里会更加深入地介绍不同类型的数据集处理方法及数据预处理。本文较长建议结合右侧的目录阅读。
1.UCI数据集介绍
这一节先从UCI数据集官网出发介绍数据集的属性、格式等信息,在我的博文:UCI数据集整理(附论文常用数据集)中也有部分介绍,对数据集熟悉或想看数据处理代码干货的朋友也可以直接跳转至下一节。下面先看一下对UCI数据集的介绍。
1.1 UCI数据集官网介绍
UCI(University of California Irvine)数据集是美国加州大学欧文分校提出的一种适合模式识别和机器学习方向的开源数据集,很多学者选择使用UCI上的数据集来验证自己所提算法的正确性。博文写作时已拥有488个数据集,数据集还在不断扩充中,这些数据集主要分为二值分类问题、多分类问题以及回归拟合问题。UCI数据集提供了各个数据集的上主要属性,可以根据自己提出的各类算法在其数据集上做实验结果论证,证明自己所提算法的合理性。
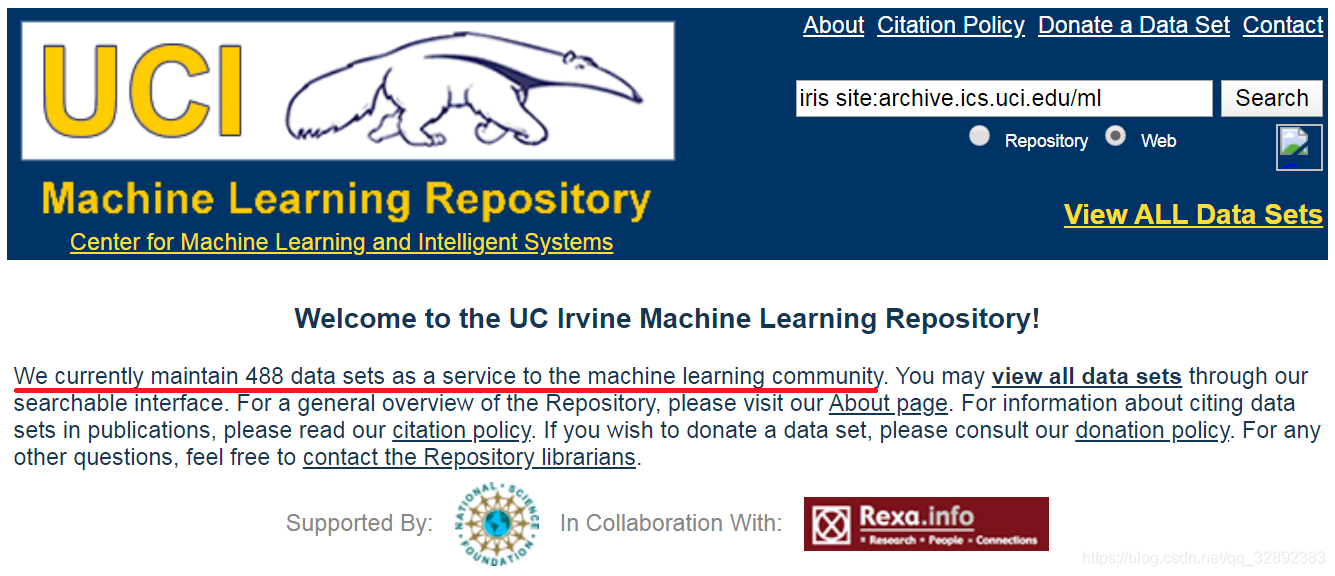
UCI数据集官网地址:https://archive.ics.uci.edu/ml/index.php
UCI数据集数据地址:https://archive.ics.uci.edu/ml/datasets.php
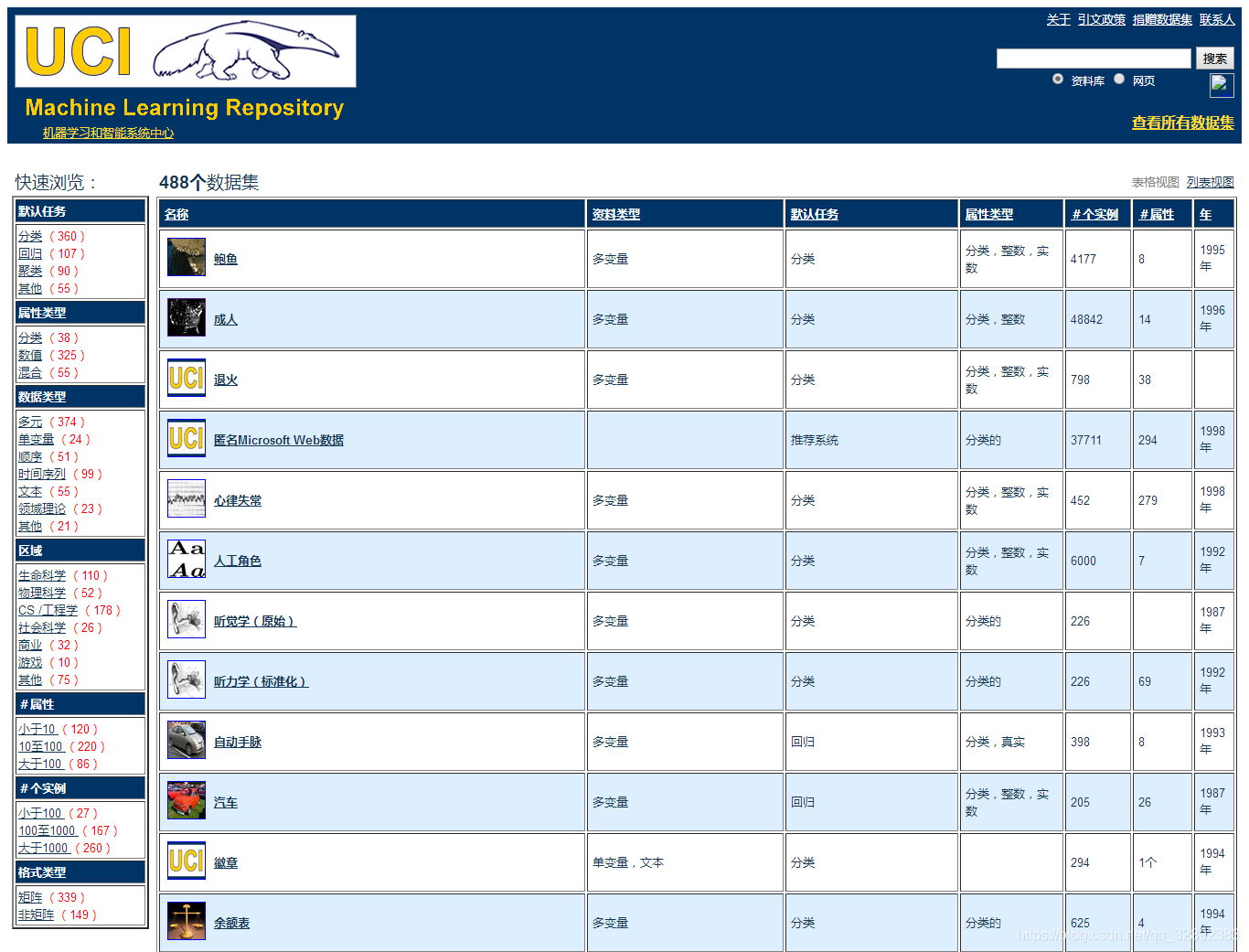
我在下图所示的UCI数据集官网截图中对其页面主要部分进行了标注,可以看出主页中主要包括了数据集页面入口、最新数据集、经典数据集及数据集的最近消息等。数据集页面入口提供了进入官网查看全部数据集的链接,为了方便用户查找在「最新数据集」和「经典数据集」区域整理了最新收录以及引用最多的几个数据集。如果只是简单测试下代码,直接点击页面上提供的数据集链接下载几个数据集就可以了,如果还需要更多数据集那就进入数据集页面入口,该页面发布有全部的数据集。
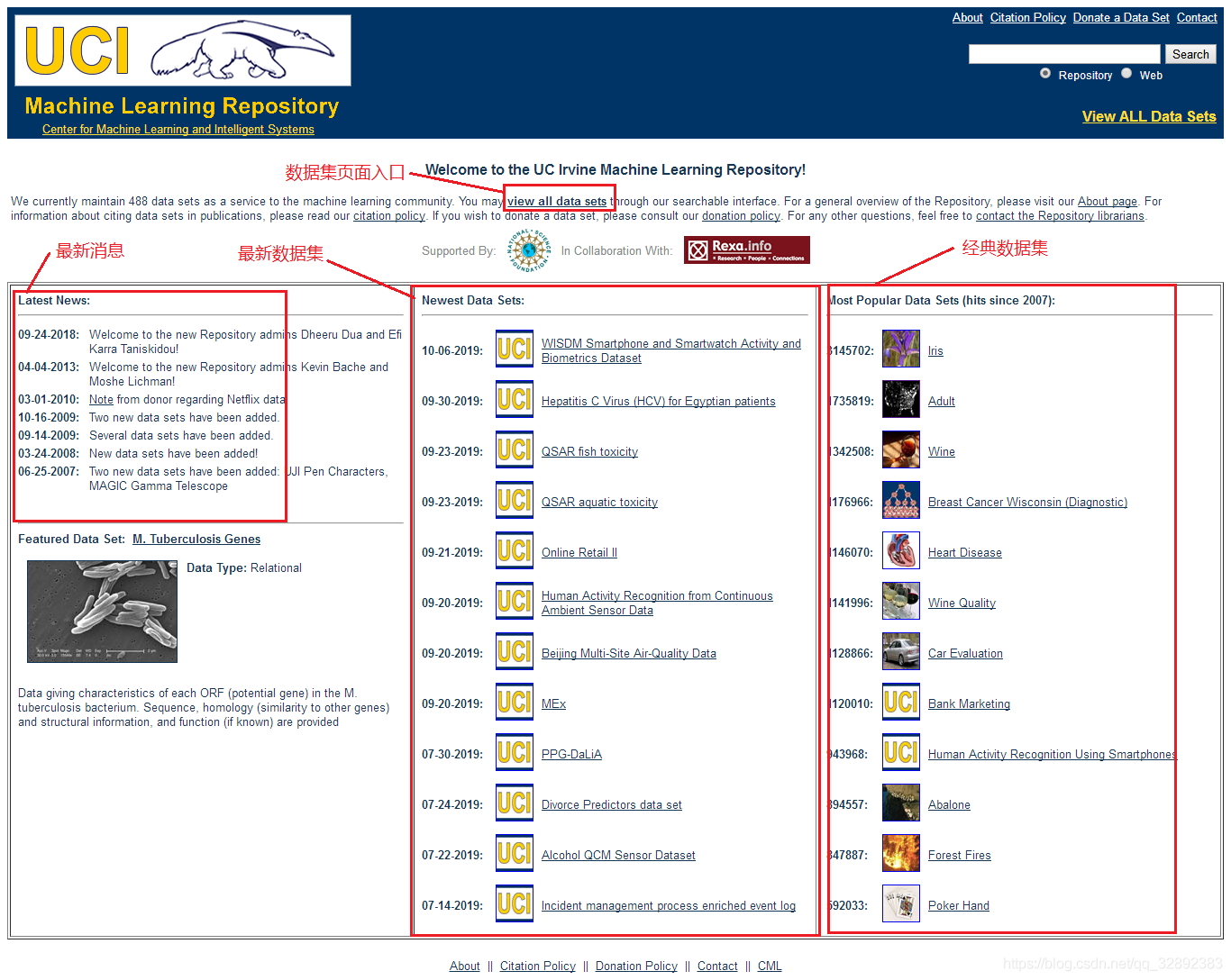
下图(图中页面已翻译)所示的全部数据集页面是一个按类型排列的数据表,可以按照数据集名称、任务类型、属性类型、数据类型等进行排列查找,点击想要的数据集链接可进入该数据集详情页。值得注意的是,右上角有一个搜索框,用户可以通过输入数据集名字搜索数据集,不过比较可惜亲测下来该搜索在没有外网VPN的加持下可能不能打开网页 (当然不能用的还有搜数据集的利器——谷歌数据集搜索)。
现在以官网数据集页面中的Adult(成年人收入)数据集为例,介绍以下数据集详情页面,点击链接进入Adult数据集页面,页面主要情况如下图1.1.1所示。对于需要特别关注的地方我已经用红色标记,主要包括数据集下载页面链接、数据集说明下载链接、数据量、属性数、是否确实数据及属性信息。当然其他的信息不可说没有必要,当我们要选用某个数据集进行测试时,了解更多的相关信息有助于更好根据数据情况对算法做出调整。页面最后面的相关论文和引用文献也能帮助了解专业情况。
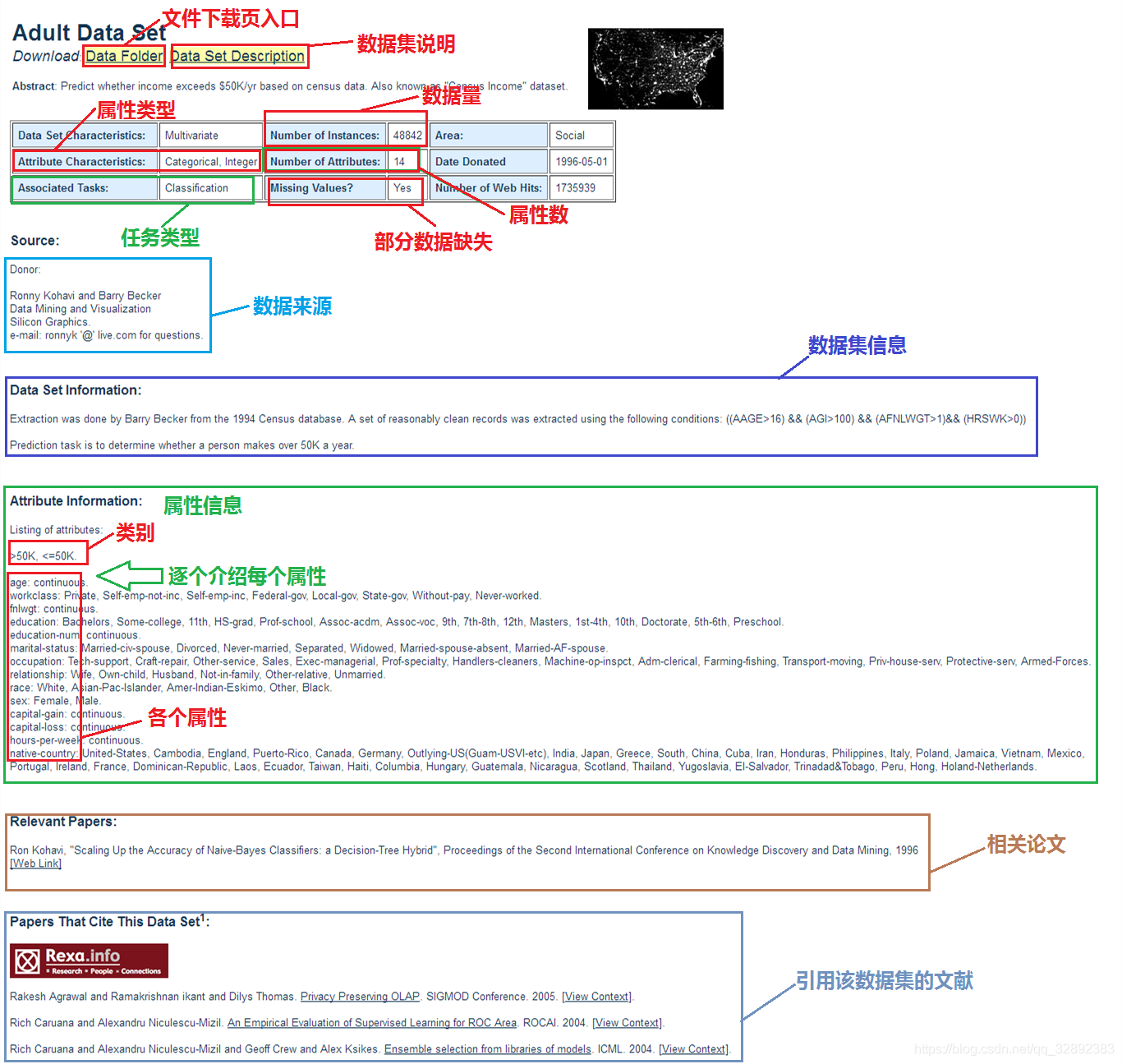
这里对上面提及的几个重要部分做个简介:
- 数据量(Number of Instances):或称实例数,表示数据集有多少行数据。
- 属性数(Number of Attributes):表示数据集每行有多少个特征属性,决定了数据集复杂程度。
- 属性信息(Attribute Information):这里介绍了数据集的分类类别,及每个属性表示的意义。例如上图数据集中介绍了成年人收入的两种分类类别:> 50K, <= 50K,属性情况:年龄、工作类别、教育程度等14个属性。
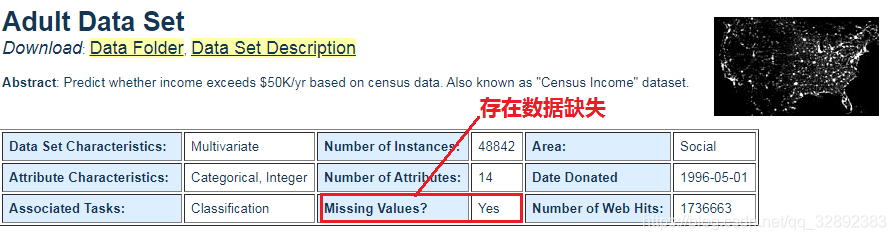
- 是否缺失数据(Missing Values):这体现了数据集中是否有某些数据缺失,如有缺失,则应特别注意在数据处理时需要补充数据或删除无效数据。
- 属性类型(Attribute Characteristics):一般有Categorical(类别型), Integer(整数型), Real(实数型)这三种。值得注意的是,如果这一栏中有Categorical型表示该数据集中可能会包含字符串,处理数据时需要用对应数字代替。
1.2 数据集文件认识

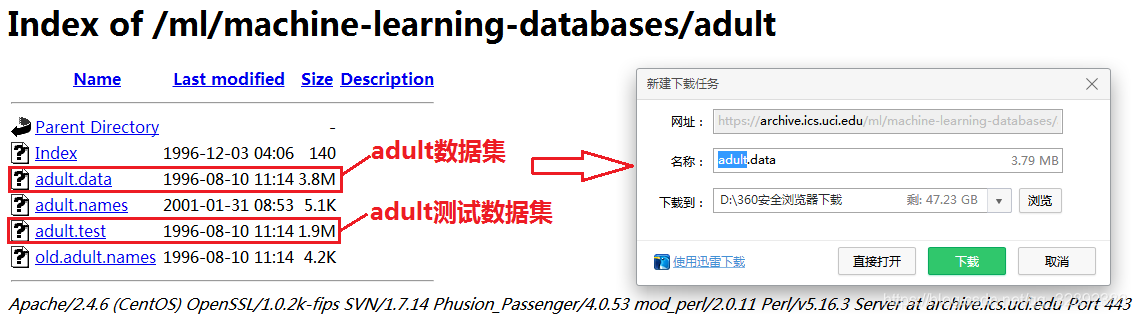
如上图所示,点击Data Folder进入Adult数据集文件下载目录页面,可以看到该数据集的文件目录如下图所示。点击下载链接即可下载该数据集,Adult数据集已经划分好训练和测试数据集(一般的数据集未划分则只有一个数据文件),所以这里需要分别下载下图所示的两处文件,如下在链接上右键,点击“链接另存为”即可下载文件。
上面下载的文件格式类型为data型,该文件在MATLAB中可以直接打开(也可以右击选择打开方式为记事本打开),打开的文件内容如下图(加的红线分割左侧为属性,右侧为标记):

可以看到文件中的数据中既有英文字符串又有整数,果然同前面介绍页中的“属性类型”显示的那样为Categorical型和Integer性。刚学习的朋友可能不太能明白这一堆数据里面到底是些什么,这一堆奇怪的数据真的能被算法直接计算吗?其实在上面一小节中已经有所提及,前面我们看到Adult数据集详情页面中“Attribute Information(属性信息)”那一栏(如图1.2.2)介绍的该数据集的类别有两个:> 50K, <= 50K,也就是收入超过50K和不超过50K两类。这说明每行最后面的那一栏是就标签,这实际是一个二分类任务的数据集,每行前面的14个数据分别是年龄、工作类别、教育程度等14个属性,如下图1.2.2:

再仔细看图1.2.1中的数据,结合图1.2.2可以知道每行的第一个属性表示的是年龄,它是个连续的整数型数据。而第二个属性为工作类别,它是一个英文字符串表示的字符型离散值,在整个数据集中这一属性实际可能取值是:Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked这几个工作类别,也就是前面说的Categorical型,同样的还有第4,6,7...个属性表示的教育程度、婚姻状况、职业等等。这为我们后面用程序整理数据集提供了思路,既然是有限类别的,那我们就可以用类似1,2,3...这样的数字代替对应的英文字符串从而转化为一个纯数字的数据文件供算法程序使用了,后面一章将详细介绍。
前面的图1.2.1中展示的是数据集前12行的数据,但如果我们再仔细浏览后面的数据还有一些值得注意的地方,如下图1.2.3标记的第15行数据。

该行数据的第14个属性表示为“?”意味着该处数据缺失,也就是国籍不详(第14个属性表示国籍),此外还有其他少数的几行有部分数据缺失。这和前面图1.1.1中的描述的“存在数据缺失”相符,数据缺失在机器学习中也很常见,因为数据的采集过程可能比较复杂,有些数据缺失在所难免。对于缺失的数据我们要做的也很简单,那就是“补上还能用的数据,或者删掉无效的数据”就可以了,下一章会详细讲述。
1.3 不同类型的UCI数据集
上面两个小节以Adult数据集为例从头到尾介绍了一遍如何认识和理解数据集文件中的数据,读者应该对UCI数据集有了一个基本认识。其实Adult数据集算是一个比较“复杂麻烦”的数据集了,大多的数据集不会有那么多英文字符和数据缺失。大多的数据集属性为数字,类别标签可能是数字或英文字符,数据也比较完整是无需我们处理缺失数据的。在我的博文《UCI数据集整理(附论文常用数据集)》中也有介绍,有兴趣的可以点过去看一下。之所以说得这么复杂是因为这个数据集几乎包含了UCI数据集中的所有可能的“麻烦问题”。接下来简单列举总结下UCI数据集文件中数据的几种类型,这将决定了我们后面采用怎样的方式整理数据集。
为了后面叙述方便,原谅我不太专业地根据文件中的数据是否部分包含英文字符、是否为纯数字、是否缺失数据将其分为三个难度:“纯数字、无缺失”,“部分英文字符、无缺失”,“部分or全部英文字符、有缺失”来分别介绍。当然还有“纯数字、有缺失”等组合,但是也可以参考第三种对缺失的处理方式,为了避免重复叙述这里就省略了。这三种情况的代表数据集有Glass数据集、Abalone数据集及Adult数据集,三个数据集的部分数据截图如下:
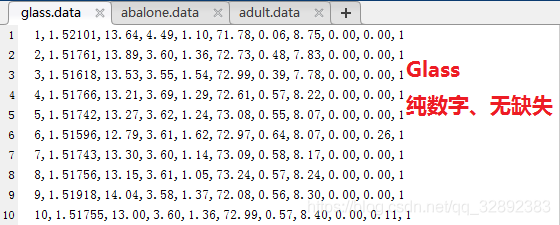


上面的三个数据集建议读者按照前面两小节的方法对照每个数据集详情页面上的介绍再研究一下,对于这三个数据集的介绍这里就不一一展开了,下面一节将以这三个数据集的整理为例讲述如何通过程序整理这三种数据集文件。
2. 不同数据集的整理
这一节就上节提到的UCI数据集中常见三种文件数据类型如何通过程序整理进行详细介绍。首先之所以需要整理数据集,是因为我们下载的UCI数据集文件常常可能含有英文字符串、缺失数据、存在无效数据等问题或者下载下来的数据集文件格式不一致导致我们无法通过统一的程序使用它。那么什么样的数据格式是我们想要的呢?
还是以Adult数据集为例,其中的英文字符需要换成对应的数字表示,缺失的数据需要补充,另外数据集的分类标记:> 50K, <= 50K分别用数字> 0, 1代替并由最后一列移至首位(标记一般在数据首位,也可以放在末尾)。Adult数据集的原始数据文件与整理完成后的数据文件对比如下图所示:

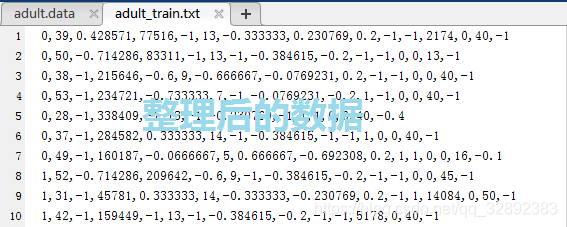
很明显整理后的数据干净整洁、易于读取,而且在部分属性特征上更加适合机器学习算法处理,其中每行数据的第一个数字为分类标记。类似图2.2正是我们需要的数据格式,为了统一使用方便,博文中的数据集都整理为这种形式。接下来从易到难分别介绍“纯数字、无缺失”,“部分英文字符、无缺失”,“部分or全部英文字符、有缺失”三种情况下的数据如何通过程序整理,以下部分全部采用\(\color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b}\)编程实现。
2.1 “纯数字、无缺失”数据集
以Glass数据集为例,首先在Glass数据集下载页下载Glass原始数据集,其数据文件部分数据如下图所示。其特点为纯数字,无缺失和特殊数据因此无需特殊处理技巧。由Glass数据集详情页上的介绍,该数据集为一个分类数为6,属性数为9的数据集。

在下载的数据文件存放路径处新建\(\color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b}\)程序,创建一个命名为main.m的文件,并在编辑器键入如下代码:
% glass
% author: wuxian, website: https://wuxian.blog.csdn.net
clear;
clc;
data_name = 'glass';
fprintf('开始处理数据集: %s ...\n', data_name);
n_entradas= 9; % 属性数
n_clases= 6; % 类别数
n_patrons(1)= 214; % 数据量(行数)
n_fich= 1;
fich{1}= 'glass.data'; % 文件路径名
n_max= max(n_patrons);
x = zeros(n_fich, n_max, n_entradas); % 用于存放提取出的属性数据
cl= zeros(n_fich, n_max); % 用于存放数据标签
n_patrons_total = sum(n_patrons); % 用于显示进度
n_iter=0;
for i_fich=1:n_fich
f=fopen(fich{i_fich}, 'r'); % 打开文件
if -1==f
error('打开数据文件出错 %s\n', fich{i_fich});
end
for i=1:n_patrons(i_fich) % 循环对每行数据进行处理
n_iter=n_iter+1;
fprintf('%5.1f%%\r', 100*n_iter/n_patrons_total); % 显示处理进度
fscanf(f,'%i',1); % 第一个数字为序号,无需记录
for j = 1:n_entradas
temp=fscanf(f, ',%f',1); % 读取下一个数据,以逗号分隔
x(i_fich,i,j) = temp; % 保存一个数值到x
end
t=fscanf(f,',%i',1);
if t >= 5 % 原数据标记中没有5,所以后面标号需要-1
t = t - 1;
end
cl(i_fich,i) = t - 1; % 原标记从1开始,改为从0开始
end
fclose(f);% 关闭文件
end
%% 处理完成,保存文件
fprintf('现在保存数据文件...\n')
data = squeeze(x); % 数据
label = cl';% 标签
dataSet = [label,data];
dir_path=['./预处理完成/',data_name];
if exist('./预处理完成/','dir')==0 %该文件夹不存在,则直接创建
mkdir('./预处理完成/');
end
saveData(dataSet,dir_path); % 保存文件至文件夹
fprintf('预处理完成\n')
%% 子函数,用于保存txt/data/mat三种类型文件
function saveData(DataSet,fileName)
% author:wuxian
% DataSet:整理好的数据集
% fileName:数据集的名字
%% Data为整理好的数据集矩阵
mat_name = [fileName,'.mat'];
save(mat_name, 'DataSet') % 保存.mat文件
data_name = [fileName,'.data'];
save(data_name,'DataSet','-ASCII'); % 保存data文件
% 保存txt文件
txt_name = [fileName,'.txt'];
f=fopen(txt_name,'w');
[m,n]=size(DataSet);
for i=1:m
for j=1:n
if j==n
if i~=m
fprintf(f,'%g \n',DataSet(i,j));
else
fprintf(f,'%g',DataSet(i,j));
end
else
fprintf(f,'%g,',DataSet(i,j));
end
end
end
fclose(f);
% save iris.txt -ascii Iris
% dlmwrite('iris.txt',Iris);
end
以上程序代码的思路是提取每行中每个数据的属性和标签分别保存到与x, cl两个矩阵中,然后通过调用子函数saveData( )保存数据为txt, data, mat格式文件。数据提取的过程是通过遍历每行数据,利用fscanf( )函数逐个读取每个逗号分隔的数据,最后在第52行将得到的属性和标签合并成一个矩阵并将标签放在第一列。运行程序后整理好的文件将保存在“预处理完成”的文件夹中,保存的文件及整理后的数据如下:
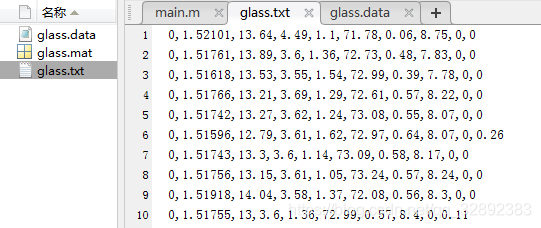
以上整理好的数据集第一列为标签(取值有0, 1, 2, 3, 4, 5),其余列为属性并与原数据集一致。
2.2 “部分英文字符、无缺失”数据集
相比前一小节中纯数字的原始数据集,最为常见的数据恐怕还是部分带一些英文字符的了。有些数据集的某些特征取值为有限个数的离散值,例如Abalone数据集,从Abalone数据集下载页下载该数据集,打开部分数据如下图所示:
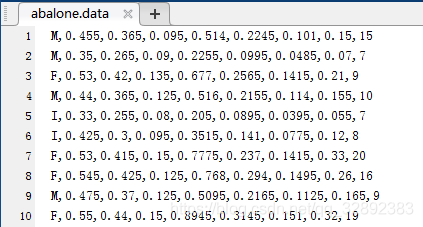
从上图数据中可以看出只有第一列的属性为英文字符,其它属性都是数字,根据Abalone数据集详情页上的介绍,该数据集的第一列属性是鲍鱼的性别,有雄性(M)、雌性(F)及幼期(I)三个取值,所以这里需将第一个属性中的英文字符“M, F, I”分别用数字“-1, 0, 1”代替。
另外该数据集要预测的物理量是鲍鱼的年龄,原始数据集年龄那一列数据(最后一列)实际为连续取值,在该数据集的“属性信息”中有介绍到该数据集既可以作为连续值预测也可以用于分类任务。所以这里在处理Abalone数据集的标签时需要将连续数值离散化,我们可以根据鲍鱼年龄age的取值分为:“\(age<9, 9<age<11, age>11\)”三类,分别用数字“-1, 0, 1”表示。这是针对这一单个数据集而言的,如果数据集标签本身就是可以直接用于分类的,就无需进行离散化了。
按照上面的分析,处理这种数据集时我们只需替换第一列英文字符并将最后一列的标签离散化。在下载的数据文件存放路径处新建\(\color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b}\)程序,创建一个命名为main.m的文件,并在编辑器键入如下代码:
%% abalone
% author: wuxian, website: https://wuxian.blog.csdn.net
clear;
clc;
data_name = 'abalone';
fprintf(['处理数据集: ',data_name,'abalone 原始数据 ...\n']);
fich= [data_name,'.data'];
n_entradas= 8; % 属性数
n_clases= 3; % 分类数
n_fich= 1; % 数据集个数
n_patrons= 4177; % 数据量(行数)
x = zeros(n_patrons, n_entradas); % 用于存放提取出的属性数据
cl= zeros(1, n_patrons);% 用于存放数据标签
f=fopen(fich, 'r');% 打开文件
if -1==f
error('打开文件出错 %s\n', fich);
end
for i=1:n_patrons % 循环对每行数据进行处理
fprintf('%5.1f%%\r', 100*i/n_patrons(1));% 显示处理进度
t = fscanf(f, '%c', 1); % 读取一个字符数据
switch t % 将对应字符替换为数字
case 'M'
x(i,1)=-1;
case 'F'
x(i,1)=0;
case 'I'
x(i,1)=1;
end
for j=2:n_entradas
fscanf(f,'%c',1); % 中间有分隔符,后移1个位置
x(i,j) = fscanf(f,'%f', 1);% 依次读取这一行所有属性
end
fscanf(f,'%c',1);
t = fscanf(f,'%i', 1); % 读取最后的标记值
% 根据范围将连续的标记值离散化为三类
if t < 9
cl(1,i)=0;
elseif t < 11
cl(1,i)=1;
else
cl(1,i)=2;
end
fscanf(f,'%c',1);
end
fclose(f);
%% 处理完成,保存文件
fprintf('现在保存数据文件...\n')
data = x; % 数据
label = cl';% 标签
dataSet = [label,data];
dir_path=['./预处理完成/',data_name];
if exist('./预处理完成/','dir')==0 %该文件夹不存在,则直接创建
mkdir('./预处理完成/');
end
saveData(dataSet,dir_path); % 保存文件至文件夹
fprintf('预处理完成\n')
%% 子函数,用于保存txt/data/mat三种类型文件
function saveData(DataSet,fileName)
% DataSet:整理好的数据集
% fileName:数据集的名字
%% Data为整理好的数据集矩阵
mat_name = [fileName,'.mat'];
save(mat_name, 'DataSet') % 保存.mat文件
data_name = [fileName,'.data'];
save(data_name,'DataSet','-ASCII'); % 保存data文件
% 保存txt文件
txt_name = [fileName,'.txt'];
f=fopen(txt_name,'w');
[m,n]=size(DataSet);
for i=1:m
for j=1:n
if j==n
if i~=m
fprintf(f,'%g \n',DataSet(i,j));
else
fprintf(f,'%g',DataSet(i,j));
end
else
fprintf(f,'%g,',DataSet(i,j));
end
end
end
fclose(f);
% save iris.txt -ascii Iris
% dlmwrite('iris.txt',Iris);
end
和前面整理的思路类似,这里还是使用x, cl两个矩阵保存从原始文件中提取的属性和标签,其中读取每个数值点采用循环调用fscanf( )函数逐个移动文件指针的方式读取,将提取的数据属性保存在x矩阵中。代码第25-33行读取出第一个属性值并根据它的取值不同分别对x的第一个元素赋不同的数字。代码第41-49行读取最后一列数值,并根据其值的取值范围将其划分为三个标签值的其中一个。至于各数据点之间的逗号分割符,程序中使用fscanf( )函数移动指针到下一个数据位置而并未赋值到变量中,从而跳过了逗号分隔符,如代码第36,40,50行。运行以上代码,得到整理完成的数据文件及部分数据截图如下:
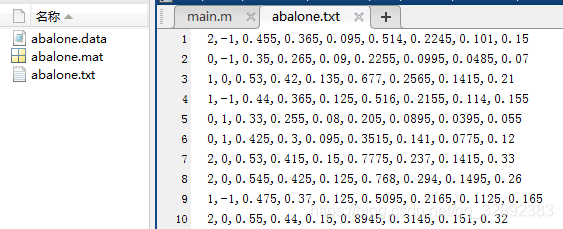
以上整理好的数据集第一列为标签(取值有0, 1, 2),其余列为属性,第一个属性已处理为数字(取值有-1, 0, 1)
2.3 “部分英文字符、有缺失”数据集
经过前面两个例子的介绍我们再来看一个更加复杂点的数据集类型即除了有英文字符还有缺失数据的部分。以Adult数据集为例,这个数据集前面已多有介绍,改数据集有划分好的训练集和测试集,所以从Adult的Data Folder下载adult.data和adult.test两个数据文件,部分数据如下图:

字符型离散值转化为数值型:我们可以将某个需要转化为数值型的字符型属性的全部可能取值存放在一个元胞数组中并记取值个数为\(n\),而转化后的数值范围一般取\([-1, 1]\),所以我们在\([-1, 1]\)的取值范围内平均取\(n\)个实数\(\{-1, \frac{3-n}{n-1}, ..., \frac{2k-1-n}{n-1}, ...,\frac{n-3}{n-1}, 1\}, k=1,2,3, ...,n-1, n\)用来代替这些字符型属性。比方说Adult原始数据的第2个属性表示工作类型有'Private', 'Self-emp-not-inc', 'Self-emp-inc', 'Federal-gov', 'Local-gov', 'State-gov', 'Without-pay', 'Never-worked'将被分别替换为数值\(-1, -\frac{5}{7}, -\frac{3}{7}, -\frac{1}{7}, \frac{1}{7}, \frac{3}{7}, \frac{5}{7}, 1\)。在程序中比对字符串然后可按以上公式顺序赋值为相应的数值。
缺失数据处理:对于缺失数据的处理其实现在并没有一个很好的解决方式,一般来说缺失的数据点较少时可以直接删去,较常见的是采用该属性的均值、中值或众数来填充缺失,当然也可以直接补充为某些特定值。直接删去数据会导致数据量减少,而均值填补主要用于连续资料的缺失,这里的数据集属性大多为离散量,使用均值并不是一个很好的方法。以上方法大家可以分别尝试一下,这里直接对缺失的数据补充特定值0处理。
在下载的数据文件存放路径处新建\(\color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b}\)程序,创建一个命名为main.m的文件,并在编辑器键入如下代码:
%% adult
% author:wx website:https://wuxian.blog.csdn.net
clear;
clc;
data_name = 'adult';% 数据集名
fprintf('lendo problema adult...\n');
n_entradas= 14; % 属性数
n_clases= 2; % 分类数
n_fich= 2; % 文件数,含有训练和测试集
fich{1}= 'adult.data';% 训练数据路径
n_patrons(1)= 32561; % 训练集数据量
fich{2}= 'adult.test'; % 测试数据路径
n_patrons(2)= 16281; % 测试数据量
n_max= max(n_patrons);
x = zeros(n_fich, n_max, n_entradas); % 属性数据
cl= zeros(n_fich, n_max); % 标签
discreta = [0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1]; % 1表示该位置的属性需要将字符型离散值转化为数值型
% 字符型离散值的所有取值
workclass = {'Private', 'Self-emp-not-inc', 'Self-emp-inc', 'Federal-gov', 'Local-gov', 'State-gov', 'Without-pay', 'Never-worked'};
education = {'Bachelors', 'Some-college', '11th', 'HS-grad', 'Prof-school', 'Assoc-acdm', 'Assoc-voc', '9th', '7th-8th', '12th', 'Masters', '1st-4th', '10th', 'Doctorate', '5th-6th', 'Preschool'};
marital = {'Married-civ-spouse', 'Divorced', 'Never-married', 'Separated', 'Widowed', 'Married-spouse-absent', 'Married-AF-spouse'};
occupation = {'Tech-support', 'Craft-repair', 'Other-service', 'Sales', 'Exec-managerial', 'Prof-specialty', 'Handlers-cleaners', 'Machine-op-inspct', 'Adm-clerical', 'Farming-fishing', 'Transport-moving', 'Priv-house-serv', 'Protective-serv', 'Armed-Forces'};
relationship = {'Wife', 'Own-child', 'Husband', 'Not-in-family', 'Other-relative', 'Unmarried'};
race = {'White', 'Asian-Pac-Islander', 'Amer-Indian-Eskimo', 'Other', 'Black'};
sex = {'Male', 'Female'};
country = {'United-States', 'Cambodia', 'England', 'Puerto-Rico', 'Canada', 'Germany', 'Outlying-US(Guam-USVI-etc)', 'India', 'Japan', 'Greece', 'South', 'China', 'Cuba', 'Iran', 'Honduras', 'Philippines', 'Italy', 'Poland', 'Jamaica', 'Vietnam', 'Mexico', 'Portugal', 'Ireland', 'France', 'Dominican-Republic', 'Laos', 'Ecuador', 'Taiwan', 'Haiti', 'Columbia', 'Hungary', 'Guatemala', 'Nicaragua', 'Scotland', 'Thailand', 'Yugoslavia', 'El-Salvador', 'Trinadad&Tobago', 'Peru', 'Hong', 'Holand-Netherlands'};
% 字符型离散值的所有取值个数
n_workclass=8;
n_education=16;
n_marital=7;
n_occupation=14;
n_relationship=6;
n_race=5;
n_sex=2;
n_country=41;
for i_fich = 1:n_fich
f=fopen(fich{i_fich}, 'r');
if -1==f
error('打开数据文件出错 %s\n', fich{i_fich});
end
for i=1:n_patrons(i_fich)
fprintf('%5.1f%%\r', 100*i/n_patrons(i_fich)); % 显示进度
for j = 1:n_entradas
if discreta(j)==1
s = fscanf(f,'%s',1);
s = s(1:end-1); % 去掉字符串末尾的逗号
if strcmp(s, '?') % 对于缺失值补0
x(i_fich,i,j)=0;
else
% 确定具体的属性位置并赋相应变量
if j==2
n = n_workclass; p=workclass;
elseif j==4
n = n_education; p=education;
elseif j==6
n = n_marital; p=marital;
elseif j==7
n = n_occupation; p=occupation;
elseif j==8
n = n_relationship; p=relationship;
elseif j==9
n = n_race; p=race;
elseif j==10
n = n_sex; p=sex;
elseif j==14
n = n_country; p=country;
end
% 根据读取的字符值按排列顺序转化为-1到1之间的分数值
a = 2/(n-1); b= (1+n)/(1-n);
for k=1:n
if strcmp(s, p(k))
x(i_fich,i,j) = a*k + b;
break
end
end
end
else % 为0的位置(原数据就是数值型)直接读取原数据
temp = fscanf(f,'%g',1);
x(i_fich,i,j) = temp;
fscanf(f,'%c',1);
end
end
s = fscanf(f,'%s',1);
% 将标签转化为数值型(0,1)
if strcmp(s, '<=50K')||strcmp(s, '<=50K.')
cl(i_fich,i)=0;
elseif strcmp(s, '>50K')||strcmp(s, '>50K.')
cl(i_fich,i)=1;
else
error('类别标签 %s 读取出错\n', s)
end
end
fclose(f);
end
%% 处理完成,保存文件
fprintf('现在保存数据文件...\n')
dir_path=['./预处理完成/',data_name];
if exist('./预处理完成/','dir')==0 %该文件夹不存在,则直接创建
mkdir('./预处理完成/');
end
data_train = squeeze(x(1,1:n_patrons(1),:)); % 数据
label_train = squeeze(cl(1,1:n_patrons(1)))';% 标签
dataSet_train = [label_train, data_train];
saveData(dataSet_train,[dir_path,'_train']); % 保存文件至文件夹
data_test = squeeze(x(2,1:n_patrons(2),:)); % 数据
label_test = squeeze(cl(2,1:n_patrons(2)))';% 标签
dataSet_test = [label_test,data_test];
saveData(dataSet_test,[dir_path,'_test']);
fprintf('预处理完成\n')
%% 子函数,用于保存txt/data/mat三种类型文件
function saveData(DataSet,fileName)
% DataSet:整理好的数据集
% fileName:数据集的名字
%% Data为整理好的数据集矩阵
mat_name = [fileName,'.mat'];
save(mat_name, 'DataSet') % 保存.mat文件
data_name = [fileName,'.data'];
save(data_name,'DataSet','-ASCII'); % 保存data文件
% 保存txt文件
txt_name = [fileName,'.txt'];
f=fopen(txt_name,'w');
[m,n]=size(DataSet);
for i=1:m
for j=1:n
if j==n
if i~=m
fprintf(f,'%g \n',DataSet(i,j));
else
fprintf(f,'%g',DataSet(i,j));
end
else
fprintf(f,'%g,',DataSet(i,j));
end
end
end
fclose(f);
% save iris.txt -ascii Iris
% dlmwrite('iris.txt',Iris);
end
这里代码在前面一个的基础上做了改进,对于原文件属性是数值型的直接读取到x矩阵中,对于字符型的属性按照顺序对应为[-1, 1]上的离散数值。运行以上代码,得到整理完成的数据文件及部分数据截图如下:
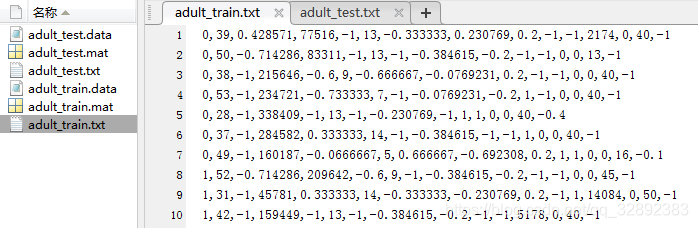
以上整理好的数据集第一列为标签(取值有0, 1),其余列为属性,其中的字符型属性已处理为数值型。
至此不同数据集的整理程序就介绍到这里了,UCI数据集数量众多,虽然没有统一的整理代码但经过这三个例子大家可以参考修改整理自己需要的数据集了。如果您有更好的整理方法欢迎在下方留言哦。
3. 148个整理好的数据集与对应程序
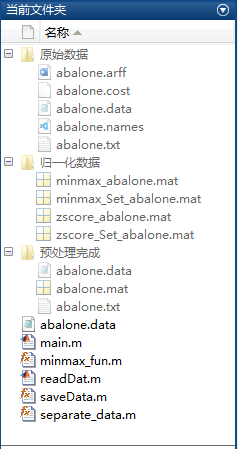
博主在三年的机器学习学习和研究中已累计整理了148个论文和研究中常用的UCI数据集,后面还会继续整理更多数据集并更新下载资源。查找、下载和整理数据集是件费时费力的事情,完整整理好足够论文或研究学习中需要的数据集可能会花费好多天甚至数周的时间,为了减少重复整理数据的繁冗工作,这里博主将自己整理好的148个UCI数据集分享给大家,其中每个文件夹中都包含了以下内容:
- 从官网下载的完整原始数据文件
- 整理数据集、归一化及划分训练测试数据集的完整\(\color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b}\)程序文件
- 整理完成后的数据集文件
您可以直接使用里面整理好的数据集文件,也可以修改或重新运行整理的程序代码,整理好的148个UCI数据集截图如下:
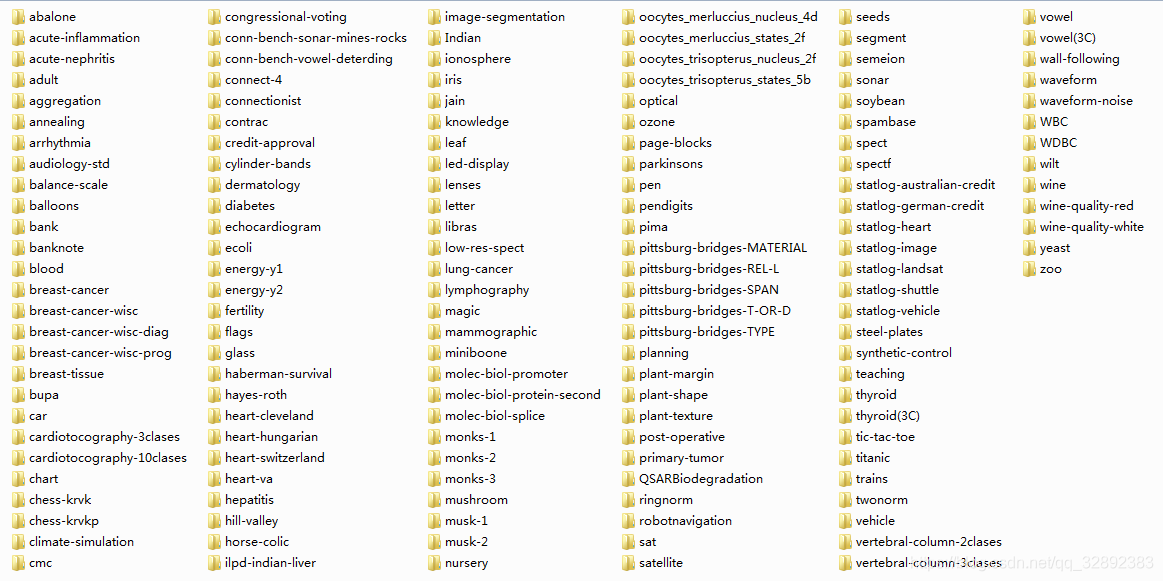
文件中的所有程序代码均在\(\color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b}\) R2016b中测试运行通过,整理的好数据集也是经过检查和自行使用过的,每个子文件夹里面的文件内容截图如下,下面提供了下载链接欢迎前去下载。
【资源获取】
若您想获得博文中介绍的整理Glass数据集、Abalone数据集及Adult数据集涉及的完整程序文件(包含三个数据的原始文件、整理数据集程序代码文件及整理好的文件)扫描以下二维码并关注公众号“AI技术研究与分享”,后台回复“UC20200223”获取。

【148个整理好的UCI数据集下载】
为大家提供优质的资源是博主一直坚持的动力,若您想获得上述介绍的148个整理好的UCI数据集(已包含本文中介绍的三个数据集),可以点击如下链接到博主的面包多网页上下载,面包多网站可以直接点击解锁,完成后可解锁页面下方的下载链接图标,点击即可下载。
下载链接:博主在面包多网站上的完整资源下载页
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。
