基于支持向量机的手写数字识别详解(MATLAB GUI代码,提供手写板)
 摘要:本文详细介绍如何利用MATLAB实现手写数字的识别,其中特征提取过程采用方向梯度直方图(HOG)特征,分类过程采用性能优异的支持向量机(SVM)算法,训练测试数据集为学术及工程上常用的MNIST手写数字数据集,博主为SVM设置了合适的核函数,最终的测试准确率达99%的较高水平。根据训练得到的模型,利用MATLAB GUI工具设计了可以手写输入或读取图片进行识别的系统界面,同时可视化图片处理过程及识别结果。本套代码集成了众多机器学习的基础技术,适用性极强(用户可修改图片文件夹实现自定义数据集训练),相信会是一个非常好的学习Demo。
摘要:本文详细介绍如何利用MATLAB实现手写数字的识别,其中特征提取过程采用方向梯度直方图(HOG)特征,分类过程采用性能优异的支持向量机(SVM)算法,训练测试数据集为学术及工程上常用的MNIST手写数字数据集,博主为SVM设置了合适的核函数,最终的测试准确率达99%的较高水平。根据训练得到的模型,利用MATLAB GUI工具设计了可以手写输入或读取图片进行识别的系统界面,同时可视化图片处理过程及识别结果。本套代码集成了众多机器学习的基础技术,适用性极强(用户可修改图片文件夹实现自定义数据集训练),相信会是一个非常好的学习Demo。
摘要:本文详细介绍如何利用MATLAB实现手写数字的识别,其中特征提取过程采用方向梯度直方图(HOG)特征,分类过程采用性能优异的支持向量机(SVM)算法,训练测试数据集为学术及工程上常用的MNIST手写数字数据集,博主为SVM设置了合适的核函数,最终的测试准确率达99%的较高水平。根据训练得到的模型,利用MATLAB GUI工具设计了可以手写输入或读取图片进行识别的系统界面,同时可视化图片处理过程及识别结果。本套代码集成了众多机器学习的基础技术,适用性极强(用户可修改图片文件夹实现自定义数据集训练),相信会是一个非常好的学习Demo。本博文目录如下:
完整资源下载链接:https://mbd.pub/o/bread/mbd-YZeUkplu
代码介绍及演示视频链接:https://www.bilibili.com/video/BV1km4y1R7qf/(正在更新中,欢迎关注博主B站视频)
前言
机器学习中支持向量机(SVM)算法可谓是个超级经典,也许很多人倾向于使用深度神经网络解决问题,但在博主看来选择何种算法应该取决于具体的机器学习任务,对于复杂程度不高、数据量较少的任务,也许经典的机器学习算法能够更好地解决问题。手写数字识别这一任务要求正确分类出0-9的手写数字图片,最常用的数据集是MNIST,该数据集也是众多论文中经常用来测试对比算法的对象。博主想说的是其实SVM也可以很好地解决这一问题,本文介绍的代码就可以实现99%的测试准确率,所以想借此为大家提供一个学习的Demo共同交流。
博主之前也曾写过两篇利用SVM进行分类的博文:基于支持向量机的图像分类(上篇)和基于支持向量机的图像分类(下篇:MATLAB实现),详细介绍了特征提取的基本技术和支持向量机的原理,亦可供大家参考。本文给出了MATLAB实现的完整代码供大家参考,有基础的读者可按照文中的介绍复现出完整程序;对于想获取全部数据集及程序文件的朋友,可以点击提供的下载链接获取可直接运行的代码,原创不易,还请多多支持了。如本文对您有所帮助,敬请点赞、收藏、关注!
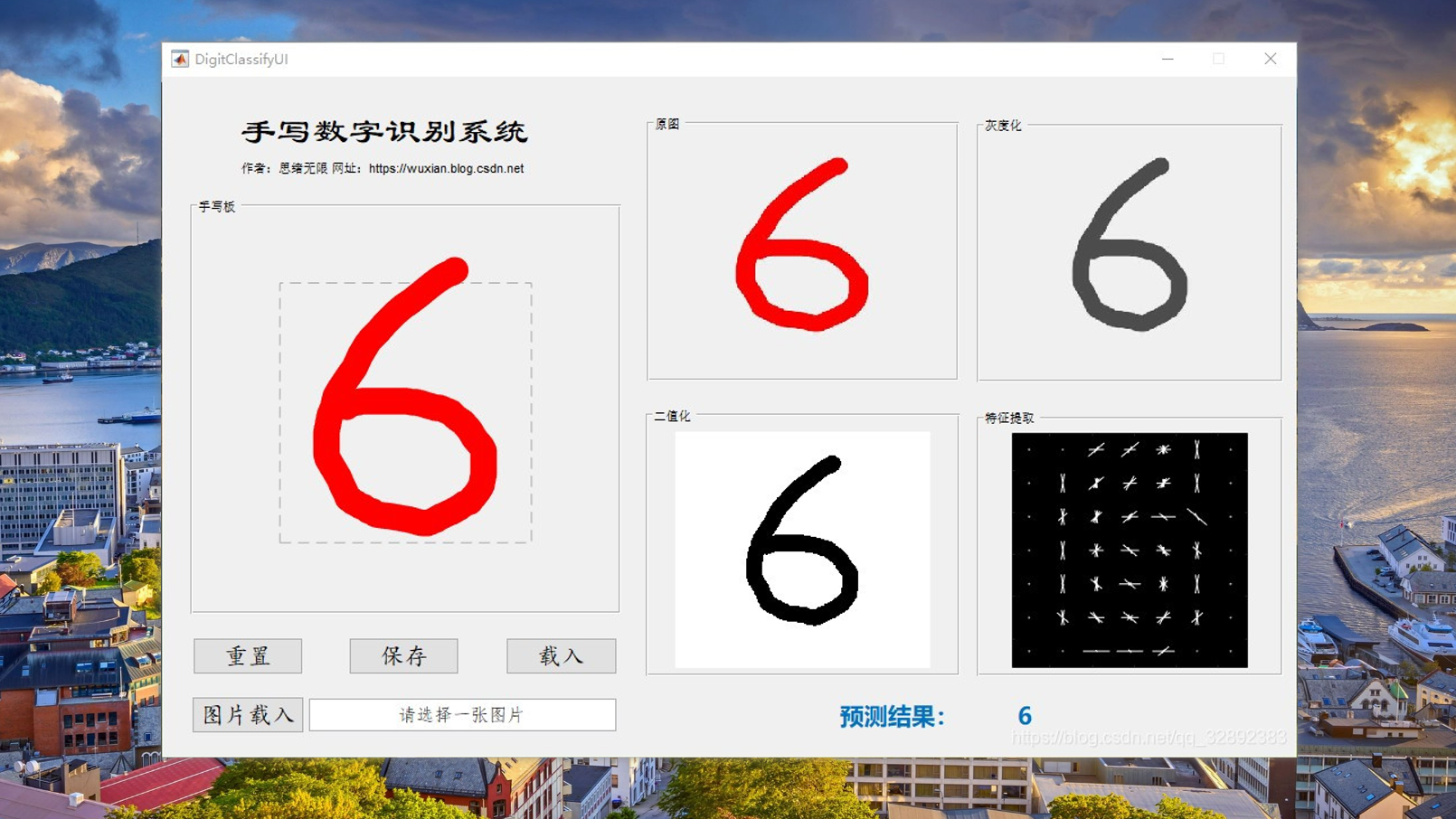
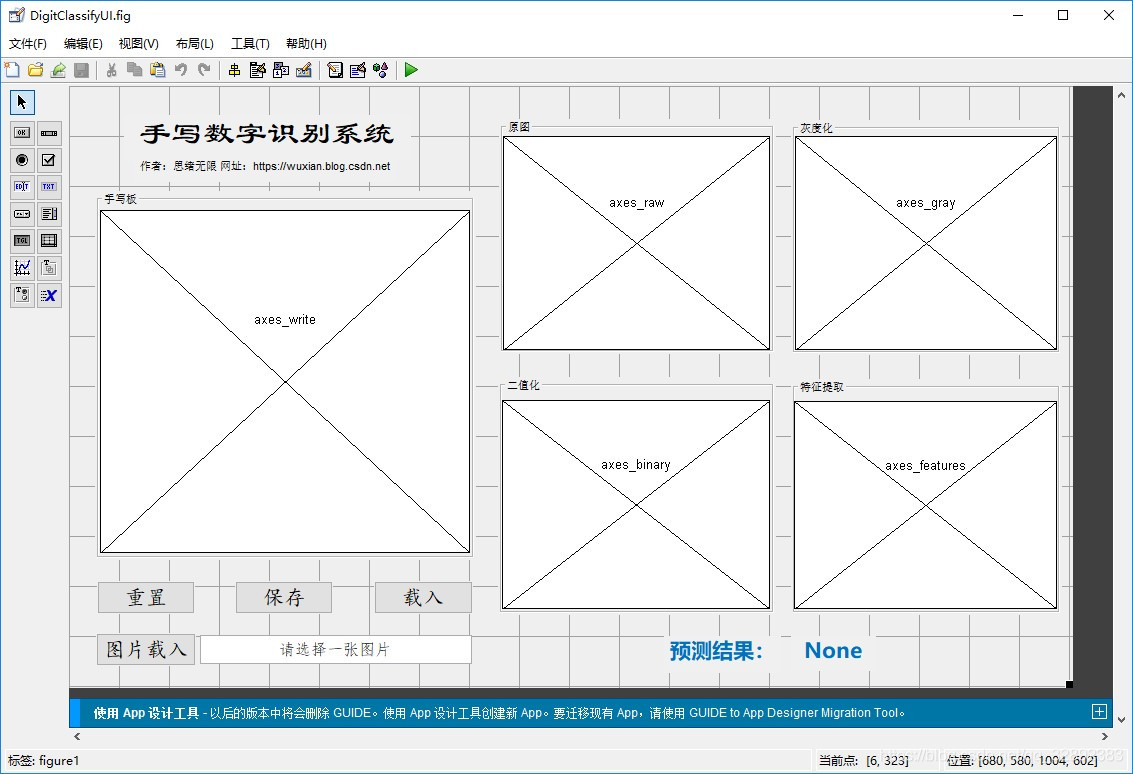
1. 效果演示
找资料的大伙时间宝贵,为了方便大家了解项目,我们老规矩先上效果演示,GUI界面有几个主要功能:通过手写板写入数字进行识别;利用文件浏览器选取一张手写数字的图片进行识别;同步可视化处理过程中的图像,显示最终识别结果。GUI界面如下:
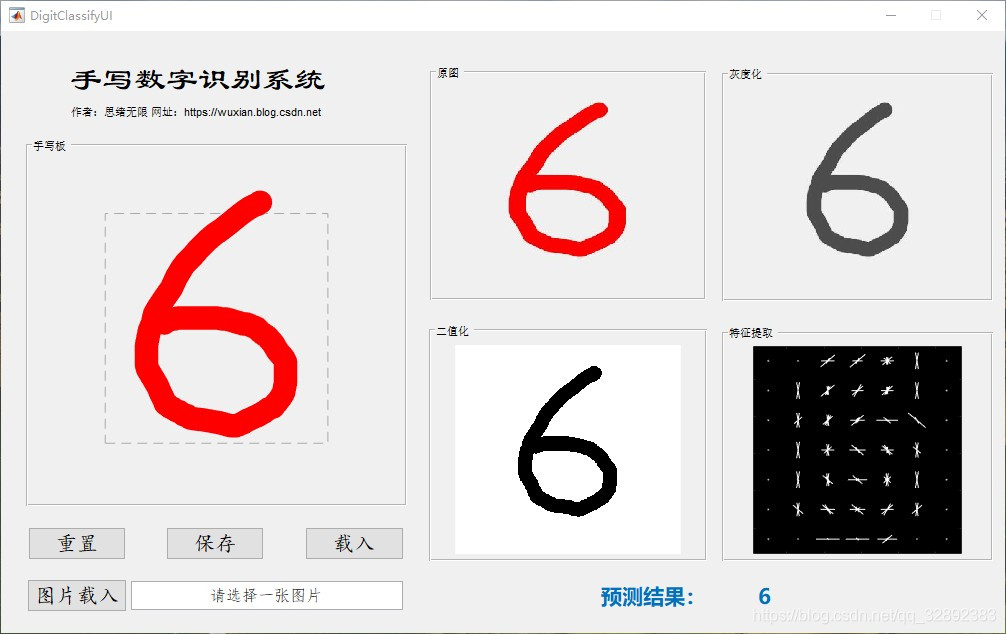
在手写板中写入数字后可点击下方保存按钮保存为图片文件,手写输入及读图输入及保存功能的演示动图如下图所示。右侧为图像原图、灰度化处理、二值化处理及特征提取后的图像,方便了解识别的处理过程:
本项目所有功能均已在MATLAB R2020b中测试通过,更多演示细节敬请前往博主B站观看演示视频,视频具体演示程序运行效果并介绍如何使用代码,欢迎关注!
2. MNIST数据集
MNIST数据集来自美国国家标准与技术研究所(National Institute of Standards and Technology, NIST)。训练集 (Training Set) 由来自250个不同人手写的数字构成,其中50%是高中学生,50%来自人口普查局的工作人员;测试集(Test Set) 也是同样比例的手写数字数据。
MNIST数据集可在 http://yann.lecun.com/exdb/mnist/获取,但由于访问外网下载速度很慢,博主已将该数据集打包上传至百度网盘,大家可以通过博主前面发布的博文:深度学习常用数据集介绍与下载(附网盘链接)进行下载。MNIST数据集包含了四个部分:
- Training set images:train-images-idx3-ubyte.gz (9.9MB,解压后47MB,包含60000个样本)
- Training set labels:train-labels-idx1-ubyte.gz(29KB,解压后60KB,包含60000个标签)
- Test set images:t10k-images-idx3-ubyte.gz (1.6MB,解压后7.8MB,包含10000个样本)
- Test set labels: t10k-labels-idx1-ubyte.gz(5KB,解压后10KB,包含10000个标签)
将下载后的数据集文件放在一个文件夹下,用于后续处理,MNIST数据集文件如下图所示:
由于MNIST的原始文件并非常见的图片格式,因此为了方便后续处理,我们先将这几个文件转化为mat文件,然后逐个读取转换为图像矩阵并保存为图片文件。值得注意的是,我们需按照每条样本数据的标签将其分别放置在不同的文件夹中,如下方式在train文件夹中创建0-9的文件夹用来存放要写入的对应标签的图片:
这里写一个小脚本将数据集图片按标签存入对应文件夹中,其中的mat文件为读取原始数据并转存后的数据集,MNIST每张图片的尺寸均为28×28,所以可以先通过reshape恢复数据尺寸,然后利用imwrite函数写入文件中(路径为对应标签的子文件夹),该部分代码如下:
clear
clc
% P = loadMNISTImages('mnist/train-images.idx3-ubyte');
% T = loadMNISTLabels('mnist/train-labels.idx1-ubyte');
load('test_data.mat', 'test_X')
load('test_label.mat', 'test_Y')
load('train_data.mat', 'train_X')
load('train_label.mat', 'train_Y')
load('validation_data.mat', 'validation_X')
load('validation_label.mat', 'validation_Y')
% 遍历每张图片
disp('现在将训练数据保存为图片文件格式')
for i = 1:length(train_X)
img = reshape(train_X(i, :), 28, 28); % 转换成28*28的图片
img = img';
imwrite(img, ['./mnist/train/', int2str(train_Y(i)), '/', int2str(i), '.jpg']);
disp(i);
end
% 遍历每张图片
disp('现在将测试数据保存为图片文件格式')
for i = 1:length(test_X)
img = reshape(test_X(i, :), 28, 28); % 转换成28*28的图片
img = img';
imwrite(img, ['./mnist/test/', int2str(test_Y(i)), '/', int2str(i), '.jpg']);
disp(i);
end
处理后的子文件夹中将存放对应的图片文件,其中两个子文件夹的截图如下图所示:
数据集准备完毕,现在可以通过文件夹读取图片了。在MATLAB中可使用imageDatastore函数方便地批量读取图片集,它通过递归扫描文件夹目录,将每个文件夹名称自动作为图像的标签,该部分代码如下:
% 给出训练和测试数据路径,利用imageDatastore载入数据集
syntheticDir = fullfile('data','mnist', 'train');
handwrittenDir = fullfile('data','mnist', 'test');
% imageDatastore递归扫描目录,将每个文件夹名称自动作为图像的标签
trainSet = imageDatastore(syntheticDir, 'IncludeSubfolders', true, 'LabelSource', 'foldernames');
testSet = imageDatastore(handwrittenDir, 'IncludeSubfolders', true, 'LabelSource', 'foldernames');
至此训练和测试数据集分别被存放在trainSet、testSet变量中,可以简单查看训练和测试集每类标签的样本个数,显示代码如下:
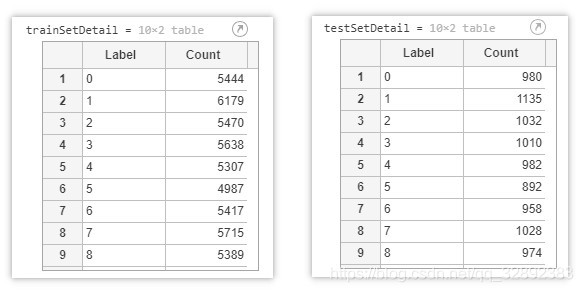
trainSetDetail = countEachLabel(trainSet) % 训练数据
testSetDetail = countEachLabel(testSet) % 测试数据
执行以上代码运行结果如下:
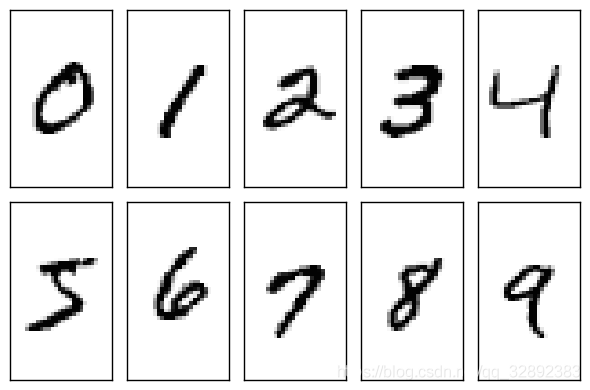
下面读取几张训练和测试集的图片,显示原始图片帮助我们清楚该数据集的实际情况,按照两行显示:第一行为训练图片,第二行为测试图片,该部分代码如下:
figure;
% 显示训练、测试图片(第一行是训练图片、第二行是测试图片)
subplot(2,5,1);imshow(trainSet.Files{4417});
subplot(2,5,2);imshow(trainSet.Files{23696});
subplot(2,5,3);imshow(trainSet.Files{31739});
subplot(2,5,4);imshow(trainSet.Files{46740});
subplot(2,5,5);imshow(trainSet.Files{54784});
subplot(2,5,6);imshow(testSet.Files{53});
subplot(2,5,7);imshow(testSet.Files{4572});
subplot(2,5,8);imshow(testSet.Files{5163});
subplot(2,5,9);imshow(testSet.Files{8381});
subplot(2,5,10);imshow(testSet.Files{9549});
执行该代码可以看到如下的运行结果:

在提取特征前我们对图片进行一些必要的预处理操作,首先读取图片后进行灰度化,然后进行二值化处理,以方便后续的特征提取。这里我们将原始图片和二值化后的图像显示在一个窗口中,其代码如下:
exampleImage = readimage(trainSet, 31739);
if numel(size(exampleImage))==3
exampleImage = rgb2gray(exampleImage); % 灰度化图片
end
processedImage = imbinarize(exampleImage);
figure;
subplot(1,2,1)
imshow(exampleImage)
title('原始图像')
subplot(1,2,2)
imshow(processedImage)
title('二值化后图像')
执行该代码可以看到如下的原始图像与二值化后的对比结果:

3. HOG特征提取
真正用于训练分类器的数据并不是原始图片数据,而是先经过特征提取后得到的特征向量,这里使用的特征类型是HOG,也就是方向梯度直方图。所以这里重要的一点是正确提取出HOG特征,extractHOGFeatures是MATLAB自带的HOG特征提取函数,该函数不仅可以有效提取特征,还可以返回特征的可视化结果以方便展示。这里通过调整每个细胞单元的尺寸大小实现不同尺寸的特征提取,可以通过可视化的结果看到细胞单元的尺寸对图像的形状信息量的影响:
img = readimage(trainSet, 31739);
% 提取HOG特征,并进行HOG可视化
[hog_2x2, vis2x2] = extractHOGFeatures(img,'CellSize',[2 2]);
[hog_4x4, vis4x4] = extractHOGFeatures(img,'CellSize',[4 4]);
[hog_8x8, vis8x8] = extractHOGFeatures(img,'CellSize',[8 8]);
% 显示原始图片
figure;
subplot(2,3,1:3); imshow(img);
title('原始图片');
% 可视化HOG特征
subplot(2,3,4);
plot(vis2x2);
title({'CellSize = [2 2]'; ['Length = ' num2str(length(hog_2x2))]});
subplot(2,3,5);
plot(vis4x4);
title({'CellSize = [4 4]'; ['Length = ' num2str(length(hog_4x4))]});
subplot(2,3,6);
plot(vis8x8);
title({'CellSize = [8 8]'; ['Length = ' num2str(length(hog_8x8))]});
通过以上代码我们分别提取了2×2、4×4、8×8三种尺寸的HOG特征,其运行的可视化结果如下:

从以上结果可以看出2×2的细胞尺寸会编码更多的形状信息,这会显著增加HOG特征向量的维数,相反8×8的细胞尺寸得到的特征量最少。这其实是一个需要调试的参数,一方面应该对足够的空间信息进行编码,另一方面需要减少HOG特征向量的维数,为此可以选择4×4的细胞大小。当然读者还可以通过反复根据分类器训练和测试的效果来调整HOG特征的相关参数,以实现最佳参数设置。
3. 训练和评估SVM分类器
下面我们使用以上提取的HOG特征训练支持向量机,以上的代码只是提取了一张图片的特征,训练前我们对整个训练数据集提取HOG特征并组合,为了方便后面的性能评估,这里对测试数据集也进行特征提取:
cellSize = [4 4];
hogFeatureSize = length(hog_4x4);
% 提取HOG特征
tStart = tic;
[trainFeatures, trainLabels] = extractHogFromImageSet(trainSet, hogFeatureSize, cellSize); % 训练集特征提取
[testFeatures, testLabels] = extractHogFromImageSet(testSet, hogFeatureSize, cellSize); % 测试集特征提取
tEnd = toc(tStart);
fprintf('提取特征所用时间:%.2f秒\n', tEnd);
由于图片数量众多,提取特征过程尚需一定时间,这里对训练集、测试集提取过程进行计时,因计算机算力不同,执行时间可能会不一致。以下代码中extractHogFromImageSet函数为自定义函数,封装了前面所提到的图像灰度化、二值化和HOG特征提取的代码,可以方便我们复用代码,使得程序更加简洁。
cellSize = [4 4];
hogFeatureSize = length(hog_4x4);
% 提取HOG特征
tStart = tic;
[trainFeatures, trainLabels] = extractHogFromImageSet(trainSet, hogFeatureSize, cellSize); % 训练集特征提取
[testFeatures, testLabels] = extractHogFromImageSet(testSet, hogFeatureSize, cellSize); % 测试集特征提取
tEnd = toc(tStart);
fprintf('提取特征所用时间:%.2f秒\n', tEnd);
运行以上代码结果如下:
提取特征所用时间:181.59秒
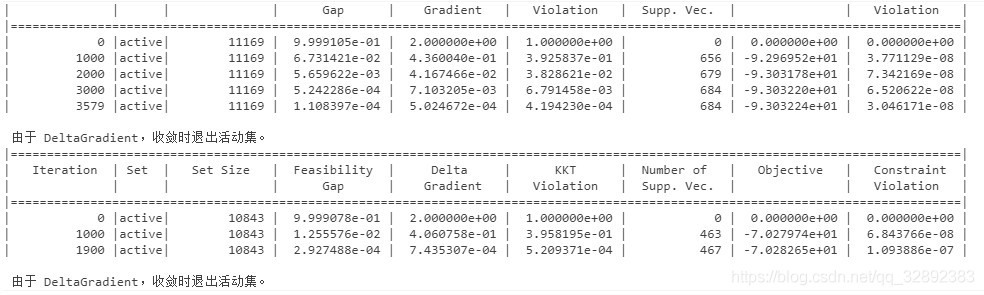
构建支持向量机模型,利用提取的训练集特征进行训练。首先利用templateSVM函数构建支持向量机模板参数,选择polynomial核函数,执行标准化处理数据,显示训练过程;利用fitcecoc函数执行训练过程,其代码如下:
% 训练支持向量机
t = templateSVM('SaveSupportVectors',true, 'Standardize', true, 'KernelFunction','polynomial', ...
'KernelScale', 'auto','Verbose', 1); % 利用polynomial核函数, 标准化处理数据,显示训练过程(verbose取0时取消显示)
tStart = tic; % 计时开始
classifier = fitcecoc(trainFeatures, trainLabels, 'Learner', t); % 训练SVM模型
tEnd = toc(tStart);
fprintf('训练模型所用时间:%.2f秒\n', tEnd);
以上代码开启了训练过程信息显示,训练过程中显示信息如下:
训练模型所用时间:104.96秒
等待训练完成,我们可以使用训练好的分类器进行预测,这里先利用测试集评估模型并计算分类评价指标,对测试集进行预测的代码如下:
tStart = tic;
% 对测试数据集进行预测
predictedLabels = predict(classifier, testFeatures);
tEnd = toc(tStart);
fprintf('模型对测试集进行预测所用时间:%.2f秒\n', tEnd);
运行结果如下:
模型对测试集进行预测所用时间:5.18秒
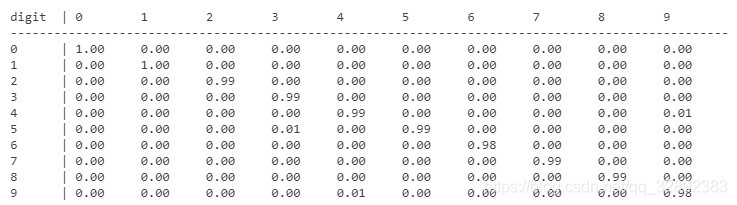
得到了预测结果,可以使用混淆矩阵评估结果,以下代码首先计算混淆矩阵结果,然后将结果打印出来:
% 使用混淆矩阵评估结果
confMat = confusionmat(testLabels, predictedLabels);
dispConfusionMatrix(confMat); % 显示混淆矩阵
运行结果如下:
以上代码显示了混淆矩阵的结果,但可能还不够直观,下面绘制混淆矩阵图帮助更好了解模型性能:
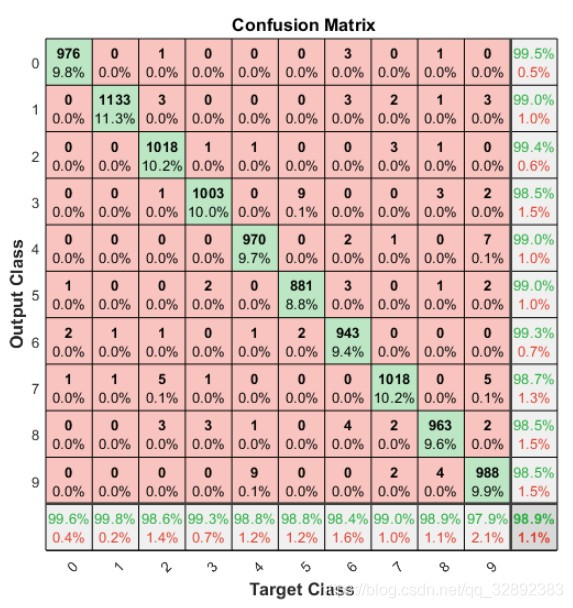
% 绘制混淆矩阵图
plotconfusion(testLabels, predictedLabels);
运行代码后显示混淆矩阵图如下图所示,每行对角线上的网格(绿色网格)处显示了某类样本预测正确的数目及其占比。右下角网格表示分类的准确率,可以看出该分类器具有98.9%的总体分类准确率。
分类准确率还可以通过以下代码进行计算:
accuracy = sum(predictedLabels == testLabels) / numel(testLabels);
fprintf('模型在测试集上的准确率:%.0f%%\n', accuracy*100);
同样可以计算出预测的准确率,这里四舍五入取整可得以下结果:
模型在测试集上的准确率:99%
通过测试集评估结果,可以看出采用核函数的支持向量机准确率为99%,其性能已逼近深度卷积神经网络。得到了一个性能优良的分类器,接下来便可以利用模型设计一些有意思的东西了。为此我将该模型用于实际的手写数字识别中,以下是在MATLAB GUI工具中设计的界面,如若读者反响热烈,后期将很快更GUI的设计介绍,还请关注了!
下载链接
若您想获得博文中涉及的实现完整全部程序文件(包括数据集,m, UI文件等,如下图),这里已打包上传至博主的面包多平台和CSDN下载资源。本资源已上传至面包多网站和CSDN下载资源频道,可以点击以下链接获取,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:
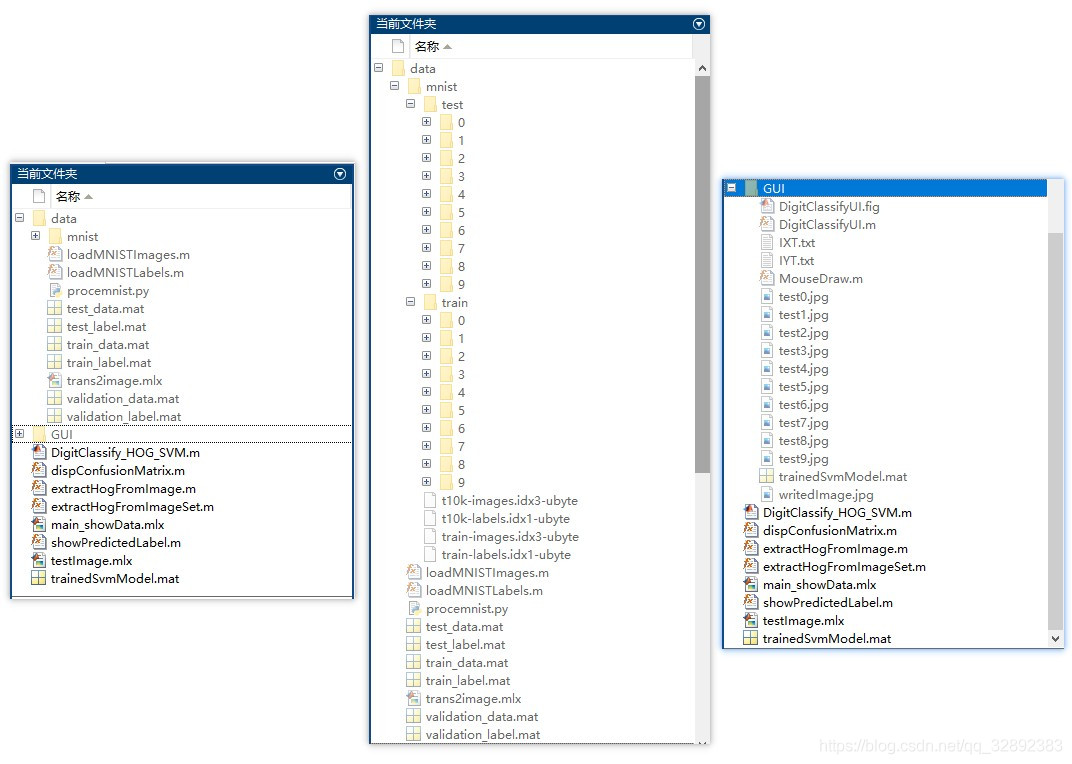
注意:本资源已经过调试通过,下载后可通过MATLAB R2020b运行;训练主程序为main_showData.mlx或DigitClassify_HOG_SVM.m文件,测试程序可运行testImage.mlx,要使用GUI界面请运行DigitClassifyUI.m文件(脚本文件可直接运行);其它程序文件大部分为函数而非可直接运行的脚本,使用时请勿直接点击运行!➷➷➷
完整资源下载链接1:博主在面包多网站上的完整资源下载页
完整资源下载链接2:https://mbd.pub/o/bread/mbd-YZeUkplu
注:以上两个链接为面包多平台下载链接,CSDN下载资源频道下载链接稍后上传。
代码使用介绍及演示视频链接:https://space.bilibili.com/456667721/(尚在更新中,欢迎关注博主B站视频)
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。如果本博文反响较好,其界面部分也将在下篇博文中介绍,所有涉及的GUI界面程序也会作细致讲解,敬请期待!

