基于深度学习的人脸识别与管理系统(UI界面增强版,Python代码)
 摘要:人脸检测与识别是机器视觉领域最热门的研究方向之一,本文详细介绍博主自主设计的一款基于深度学习的人脸识别与管理系统。博文给出人脸识别实现原理的同时,给出Python的人脸识别实现代码以及PyQt设计的UI界面。系统实现了集识别人脸、录入人脸、管理人脸在内的多项功能:包括通过选择人脸图片、视频、摄像头进行已录入人脸的实时识别;可通过图片和摄像头检测人脸并录入新的人脸;通过系统管理和更新人脸数据等功能,检测速度快、识别精度较高。博文提供了完整的Python代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。
摘要:人脸检测与识别是机器视觉领域最热门的研究方向之一,本文详细介绍博主自主设计的一款基于深度学习的人脸识别与管理系统。博文给出人脸识别实现原理的同时,给出Python的人脸识别实现代码以及PyQt设计的UI界面。系统实现了集识别人脸、录入人脸、管理人脸在内的多项功能:包括通过选择人脸图片、视频、摄像头进行已录入人脸的实时识别;可通过图片和摄像头检测人脸并录入新的人脸;通过系统管理和更新人脸数据等功能,检测速度快、识别精度较高。博文提供了完整的Python代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。
摘要:人脸检测与识别是机器视觉领域最热门的研究方向之一,本文详细介绍博主自主设计的一款基于深度学习的人脸识别与管理系统。博文给出人脸识别实现原理的同时,给出Python的人脸识别实现代码以及PyQt设计的UI界面。系统实现了集识别人脸、录入人脸、管理人脸在内的多项功能:包括通过选择人脸图片、视频、摄像头进行已录入人脸的实时识别;可通过图片和摄像头检测人脸并录入新的人脸;通过系统管理和更新人脸数据等功能,检测速度快、识别精度较高。博文提供了完整的Python代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。本博文目录如下:
完整资源下载链接:https://mbd.pub/o/bread/mbd-YpmYlZtw
代码介绍及演示视频链接:https://www.bilibili.com/video/BV1XB4y1U73S(正在更新中,欢迎关注博主B站视频)
前言
近年来,人脸识别的技术愈发成熟,在大型数据集上的训练测试结果已超过人类,其应用也日益广泛,譬如刷脸支付、安防侦破、出入口控制、互联网服务等。人脸识别(Face Recognition)是一种通过获取人面部的特征信息进行身份确认的技术,类似已用于身份识别的人体的其他生物特征(如虹膜、指纹等),人脸具备唯一性、一致性和高度的不可复制性,为身份识别提供了稳定的条件。人脸识别系统是博主一直想做的一个项目,通过人脸面部信息识别可以进行很多有趣的设计,如面部解锁、考勤打卡等。
前面博主撰写了人脸性别识别系统、表情识别系统等,其实是人脸属性识别的一种,即根据人脸面部图像中的相关特征判断其性别或表情属性,该任务本身也同样具有较强的现实意义。这篇博文则回到人脸识别的任务本身,采用深度学习的方法对人脸特征进行提取,计算其与已存在的人脸特征的相似度,判读其是否属于库中的某一人脸,达到身份识别的目的。不过我希望在实现的基础上,能多增加一些可操作性,因此尽可能设计一个功能完善的人脸识别系统。
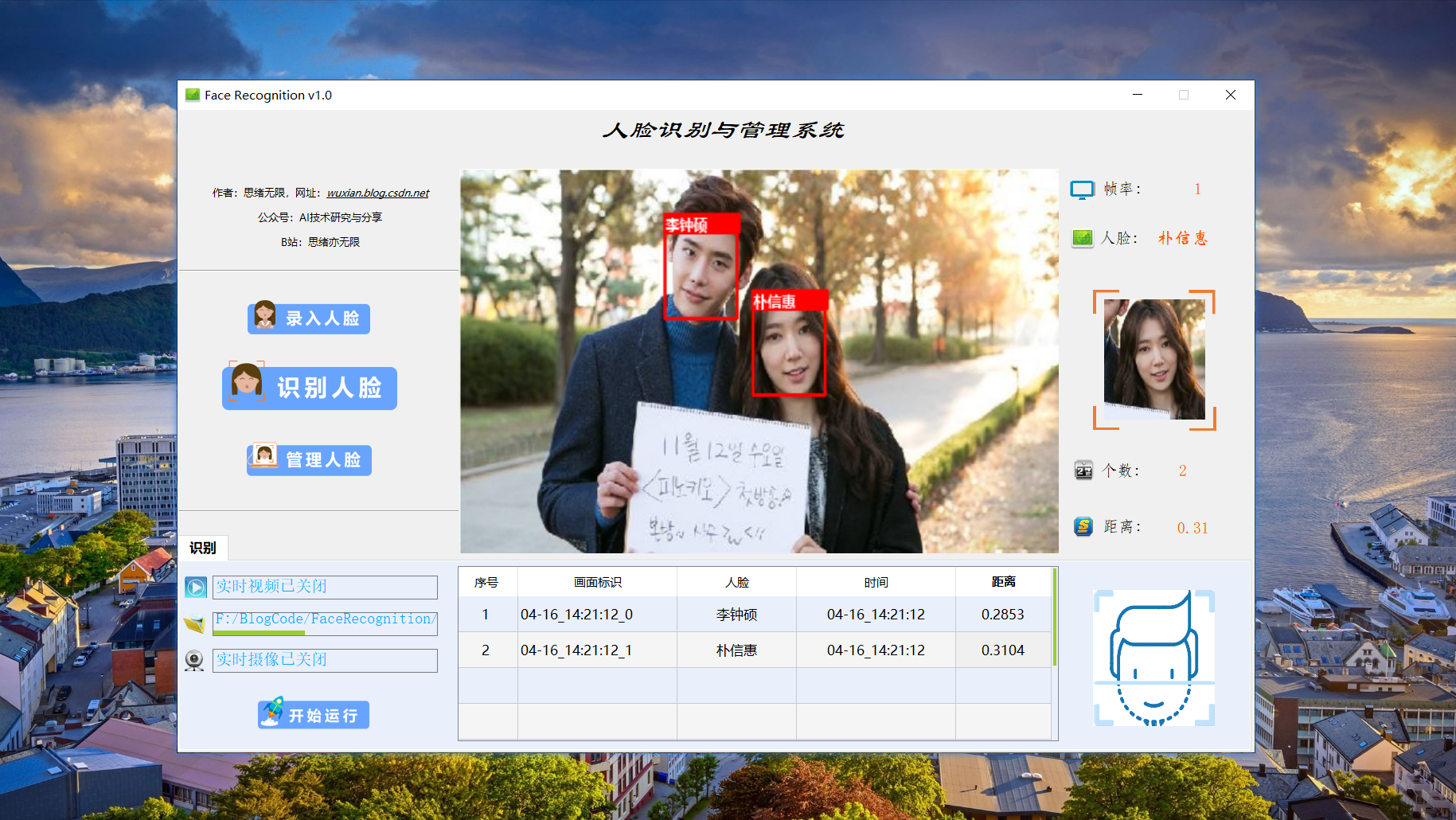
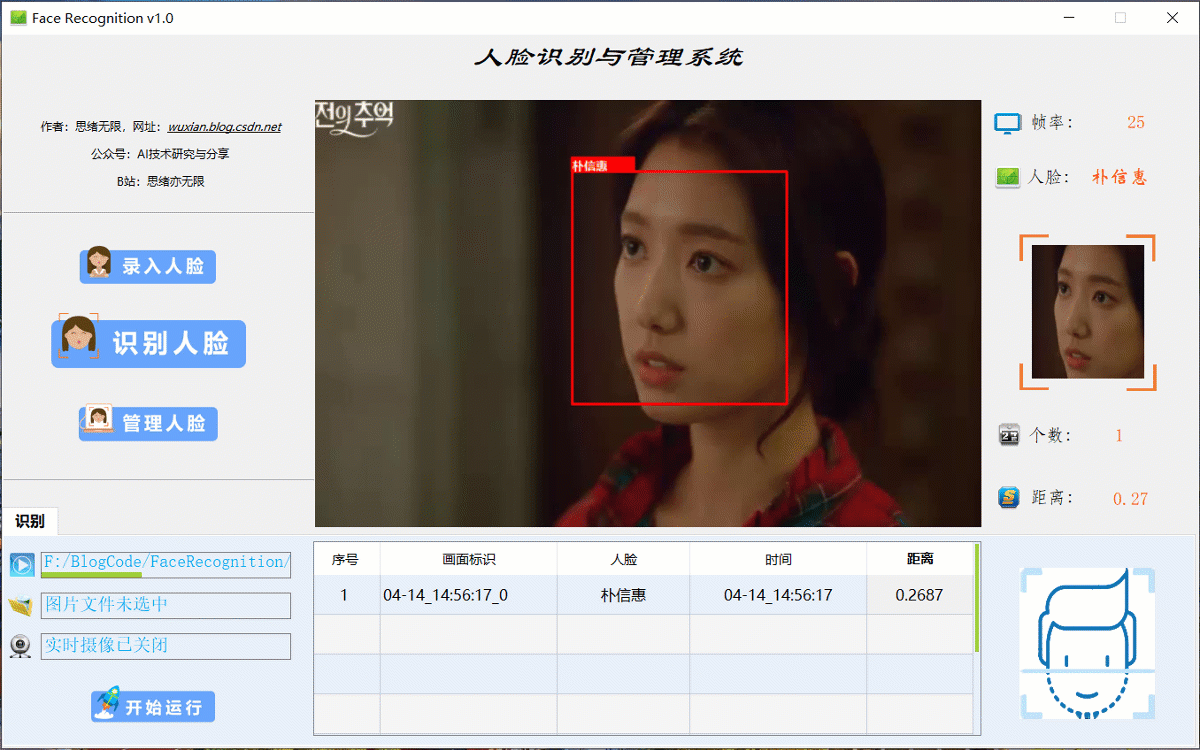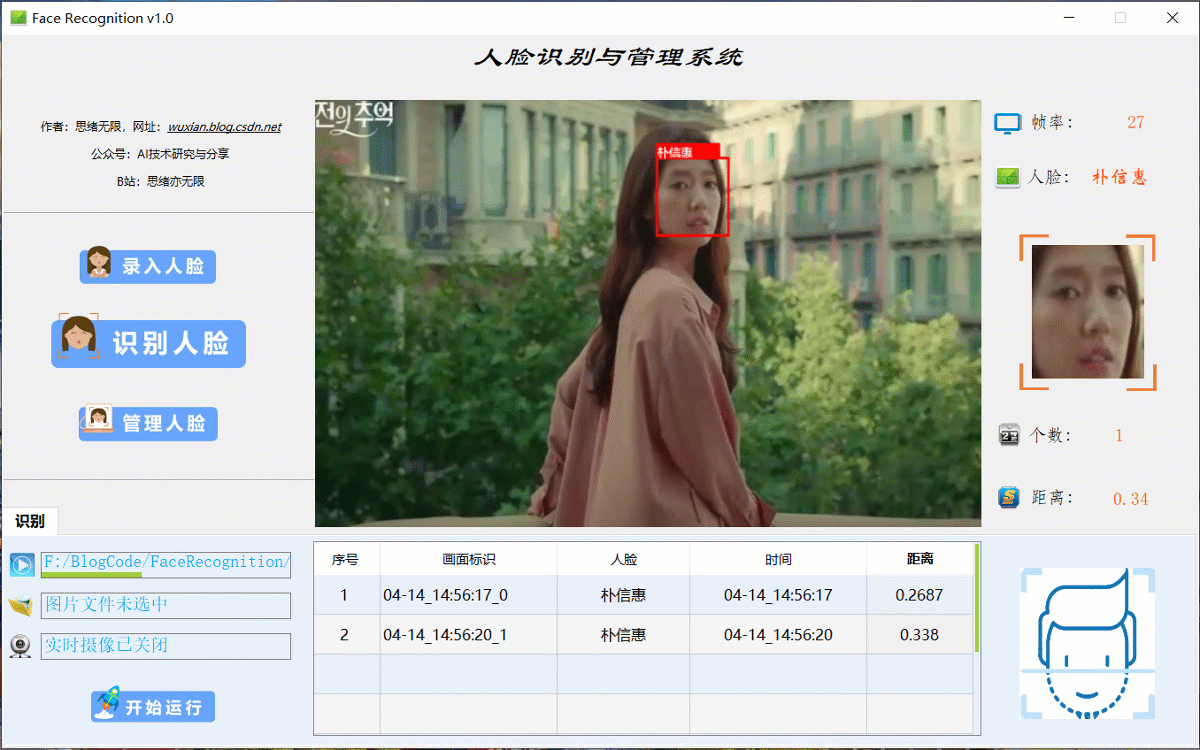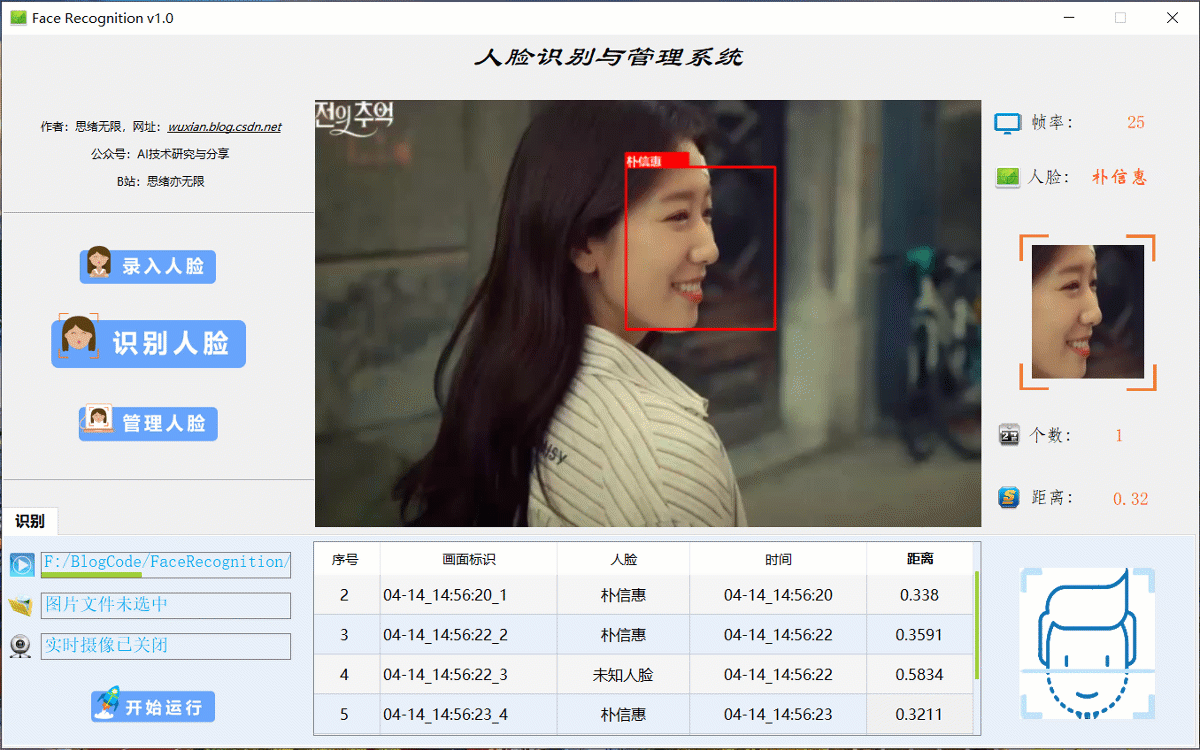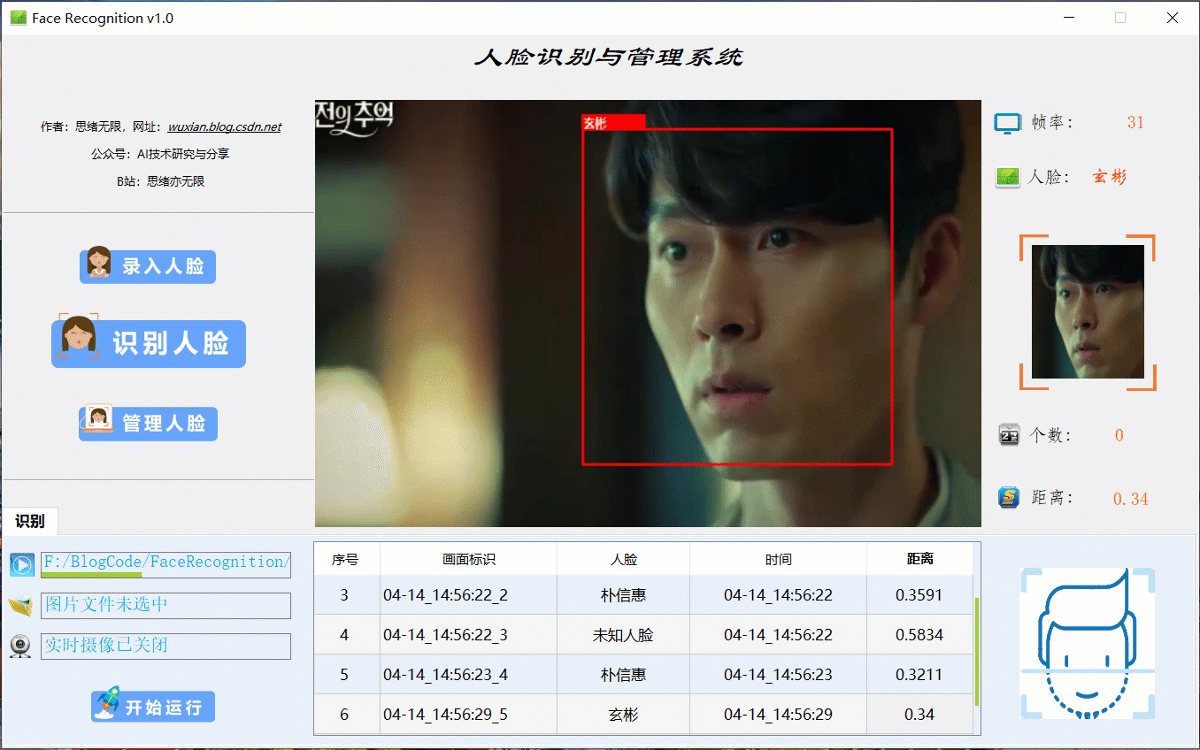
查阅网上资料发现,研究和分享人脸识别技术和代码的大有人在,主要是做一些简单易行的小Demo等,大家可自行查阅参考。这里博主分享一个自主设计的人脸识别项目,包括识别人脸、录入人脸、管理人脸在内的多项功能,以下是界面的截图,供大家参考学习了:
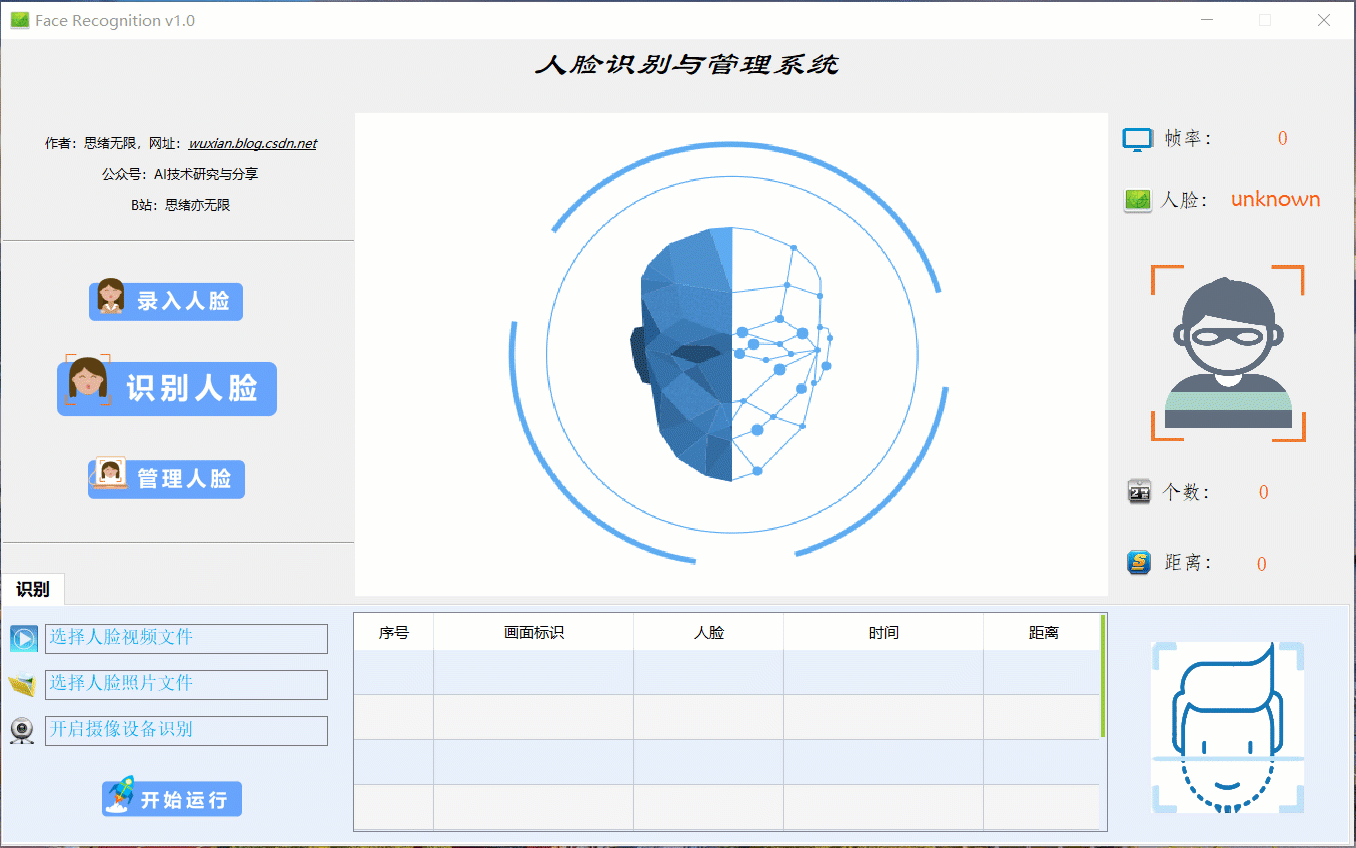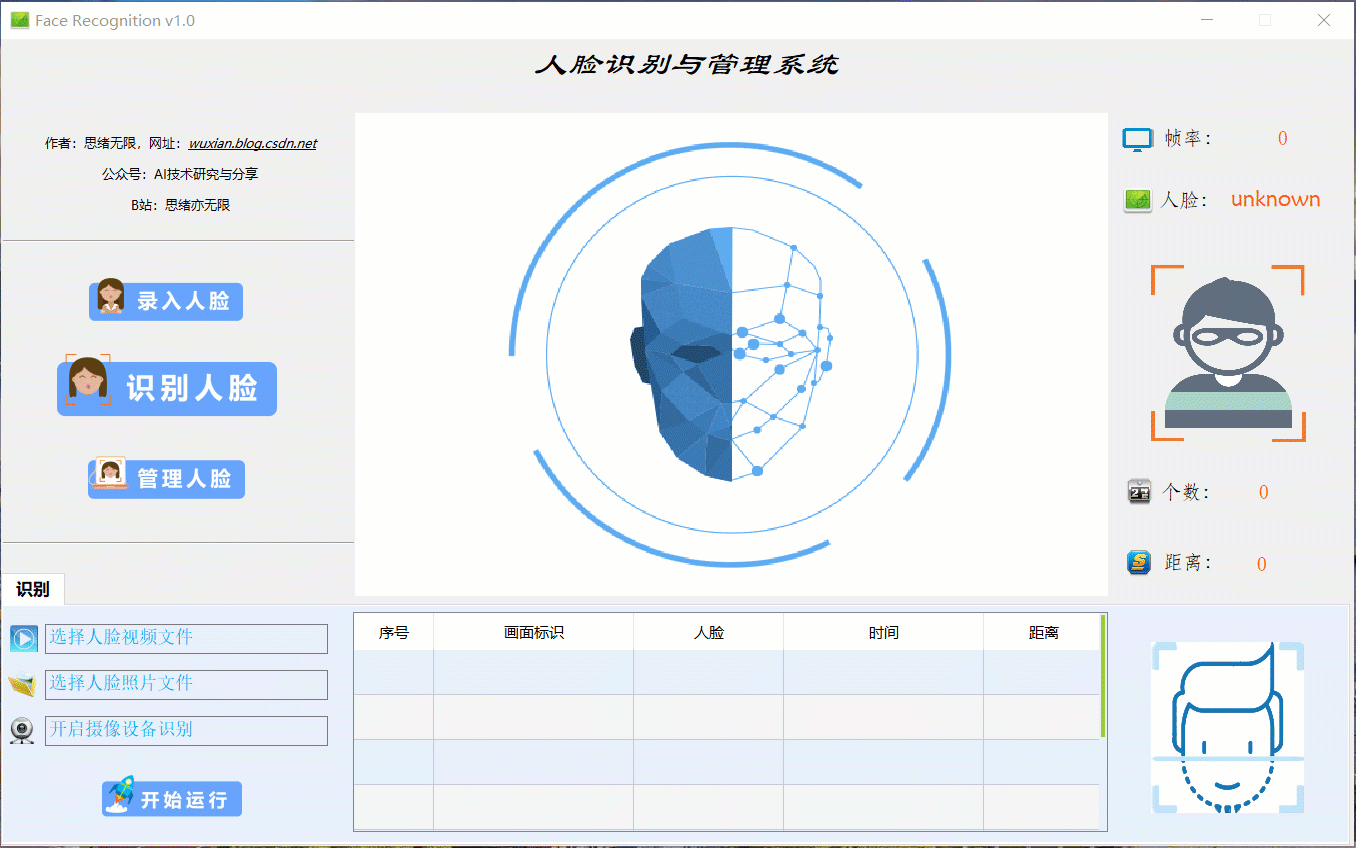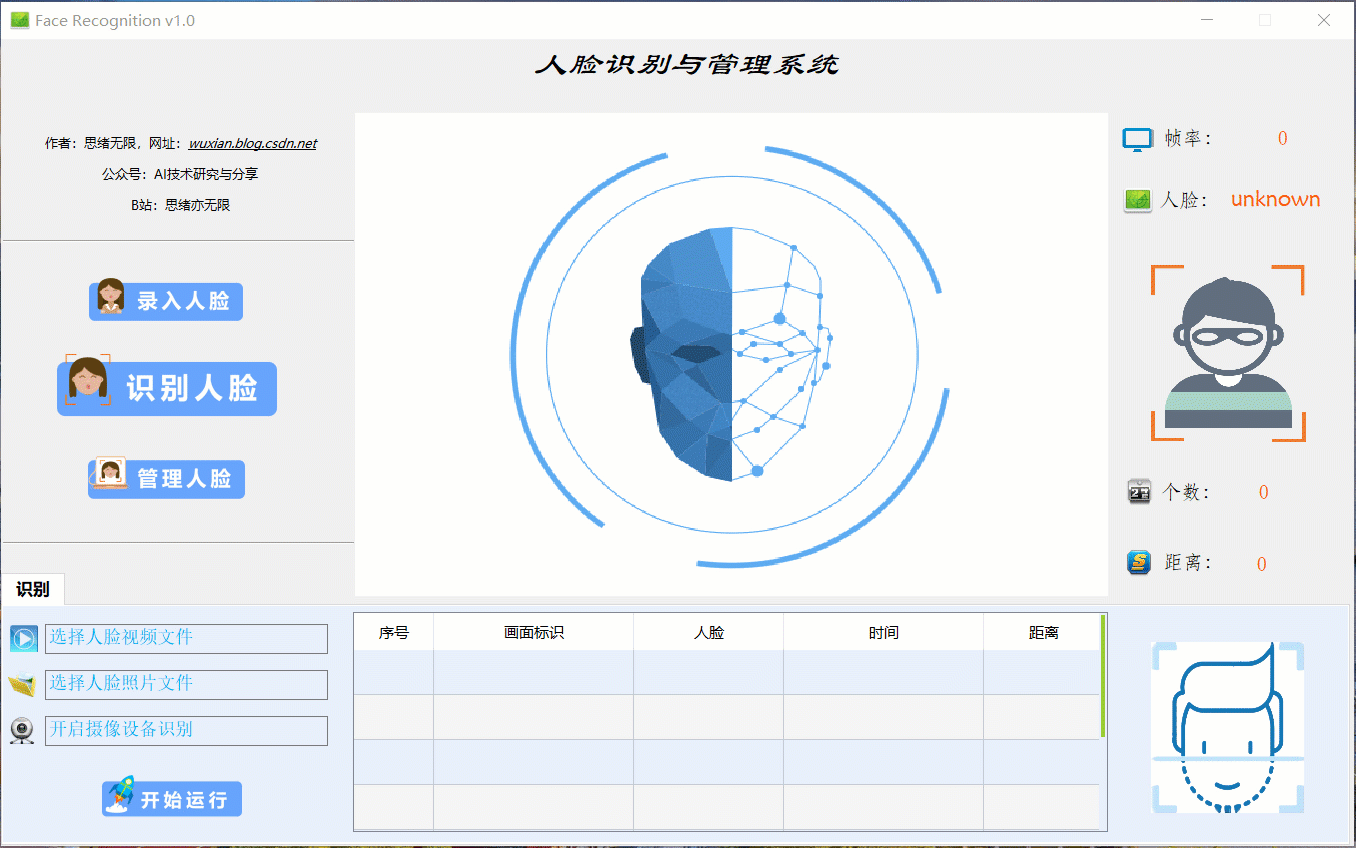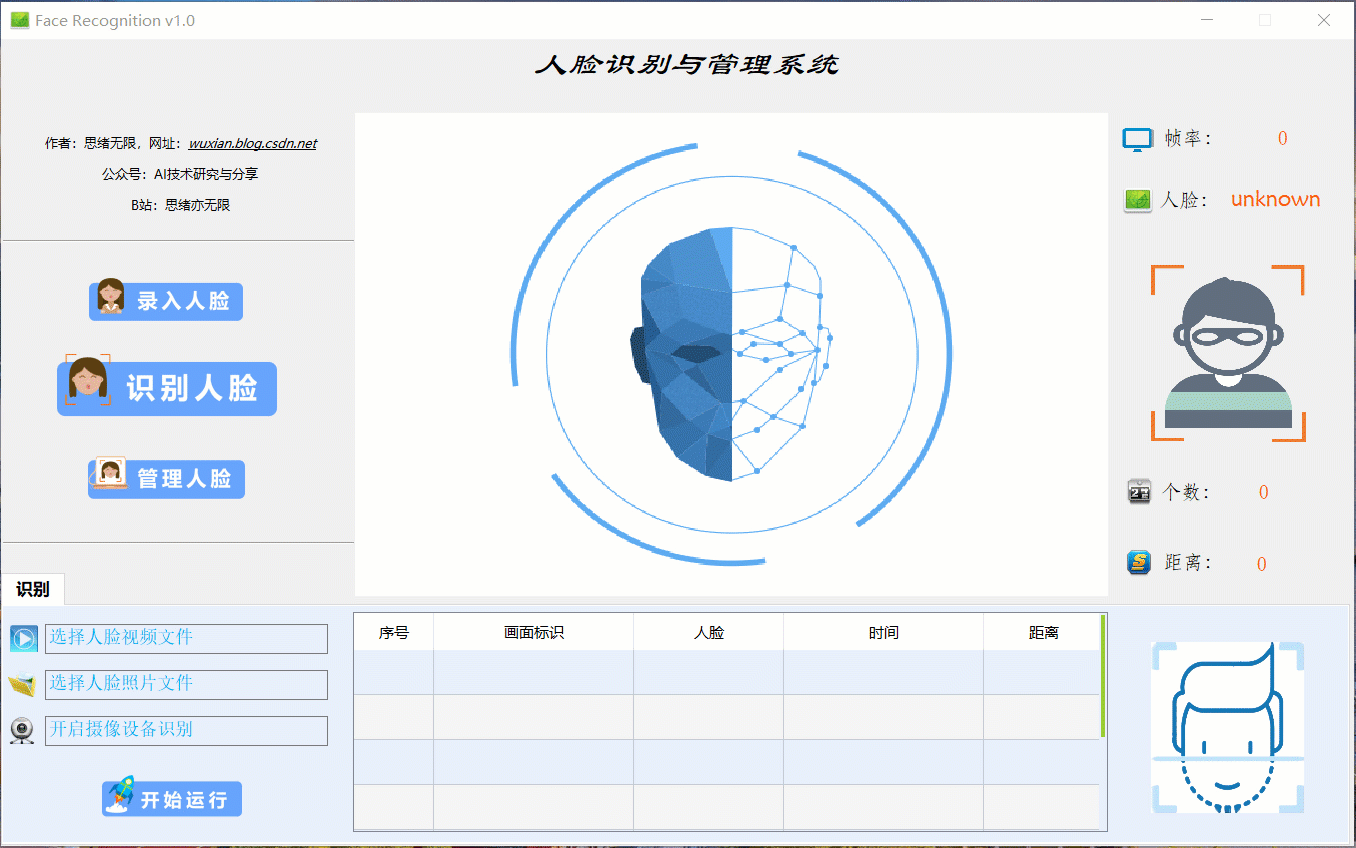
检测识别人脸时的界面截图(点击图片可放大)如下图,可识别画面中存在的多个人脸,也可开启摄像头或视频检测,以及人脸录入管理等功能:
详细的功能演示效果参见博主的B站视频或下一节的动图演示,觉得不错的朋友敬请点赞、关注加收藏!系统UI界面的设计工作量较大,界面美化更需仔细雕琢,大家有任何建议或意见和可在下方评论交流。
1. 效果演示
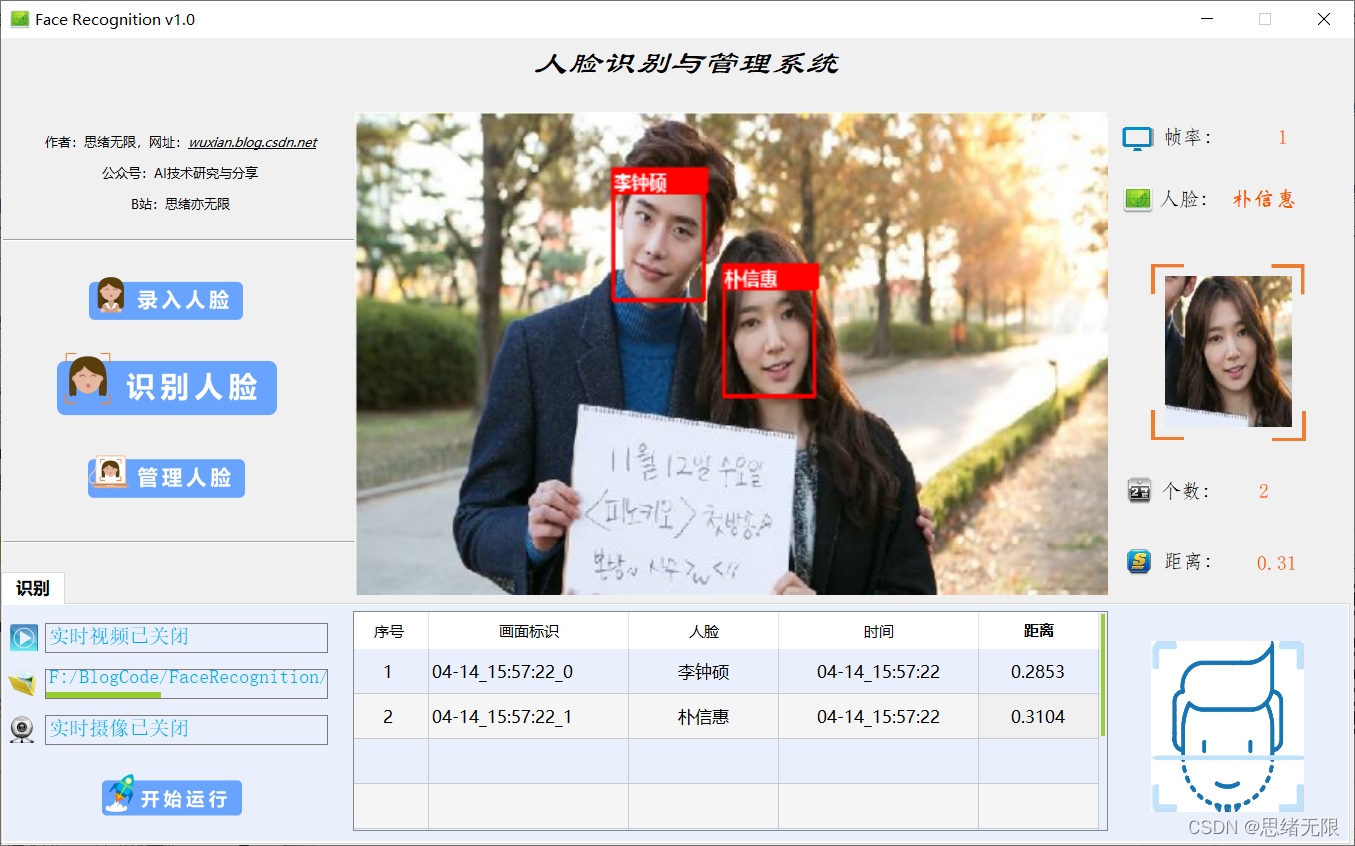
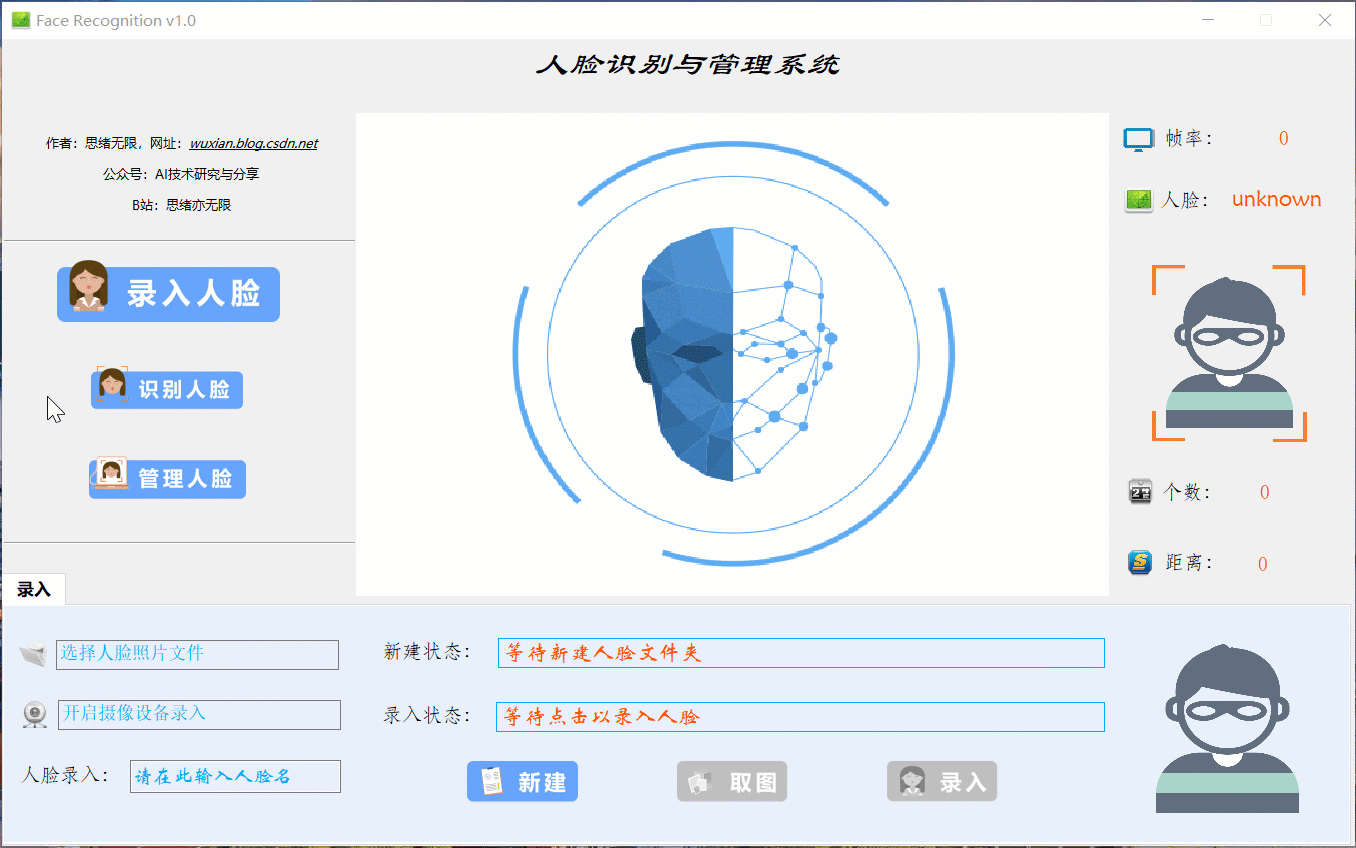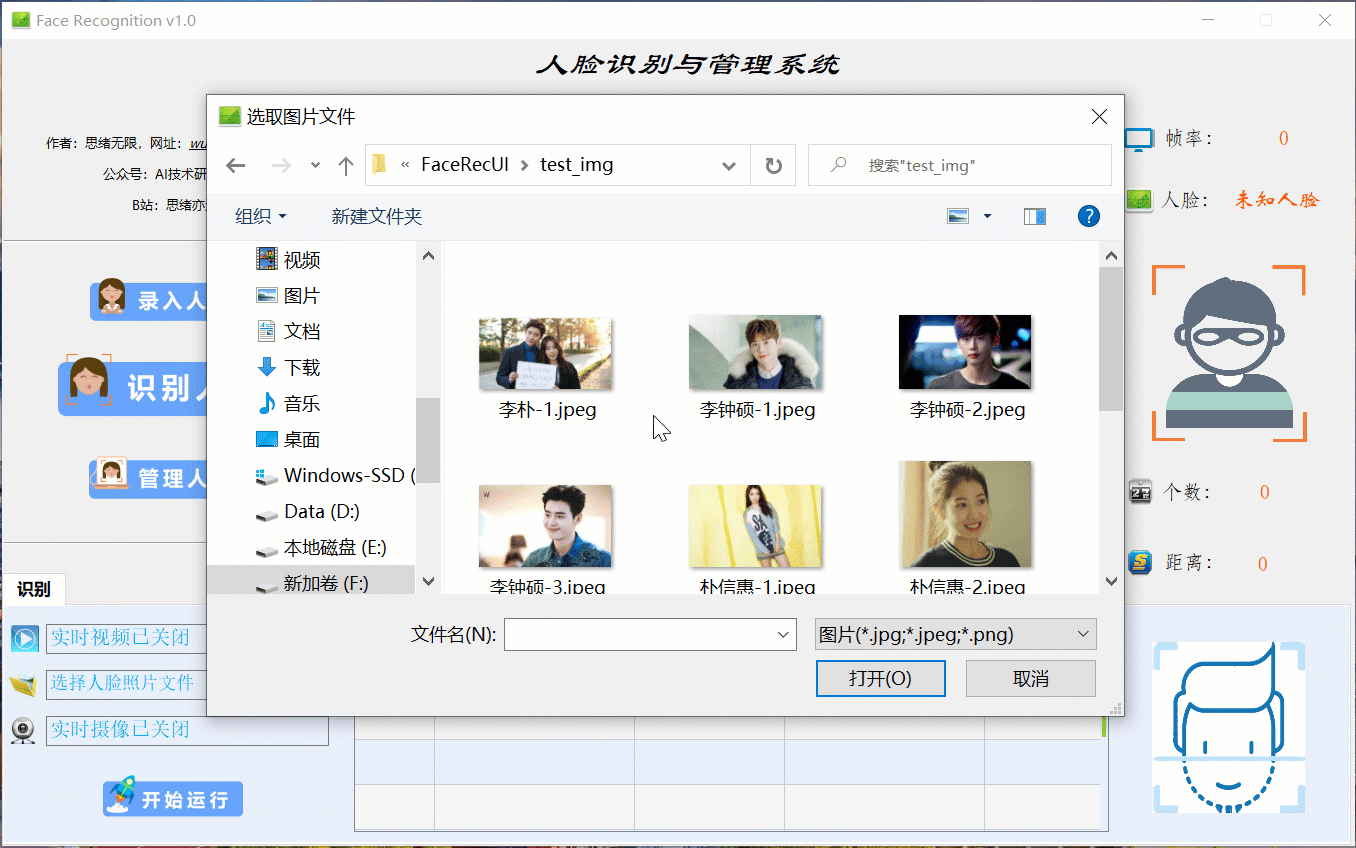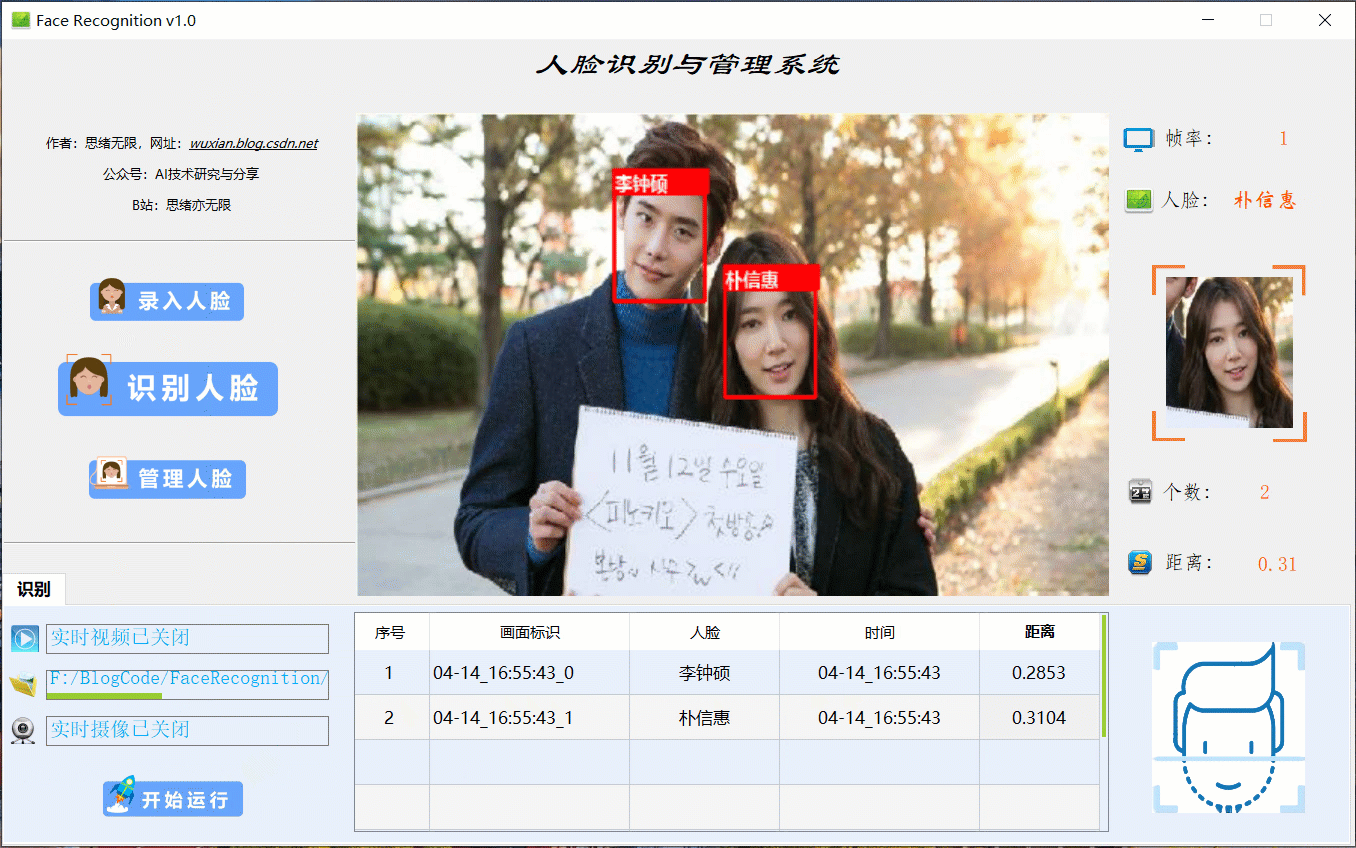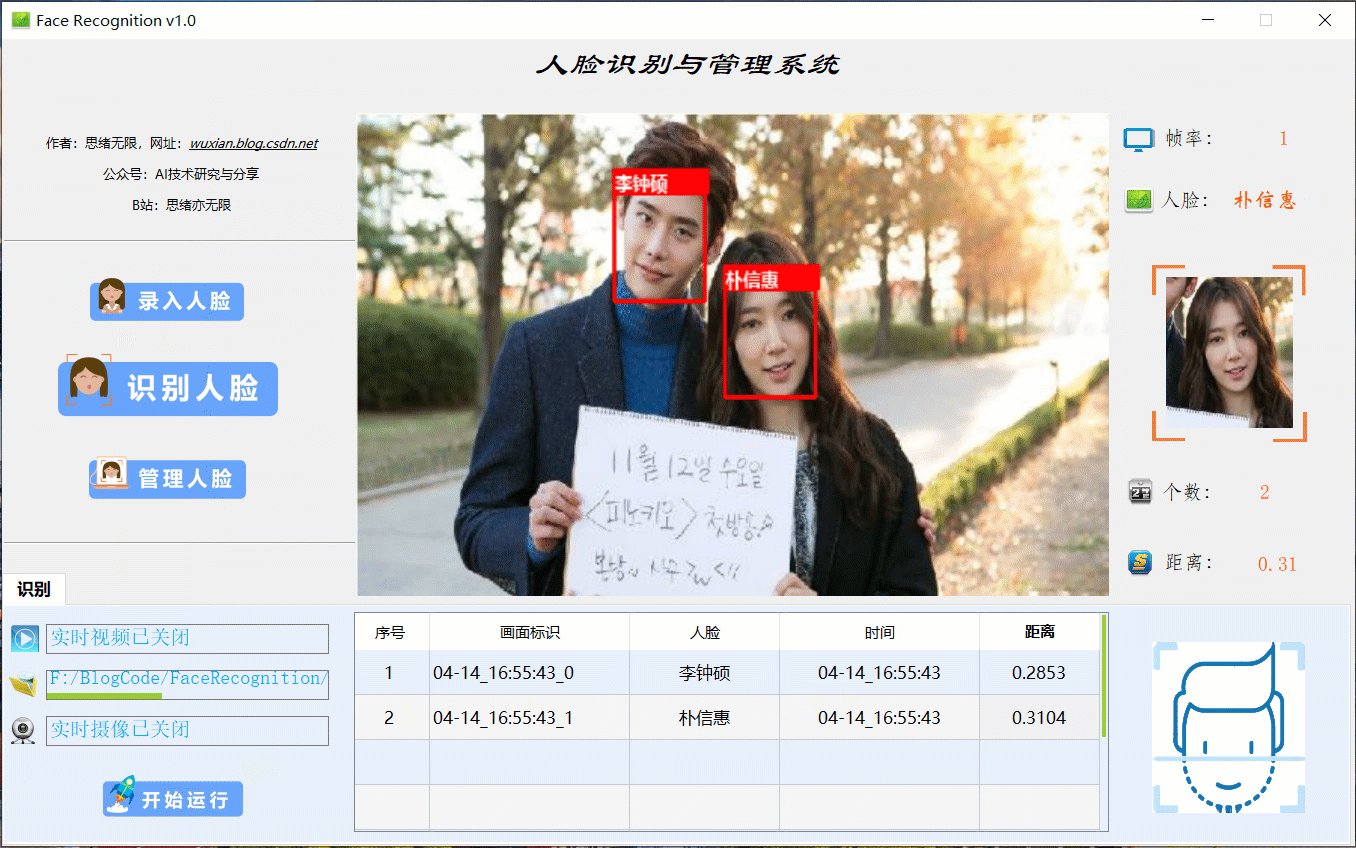
(一)选择人脸图片识别
在系统的功能选项按钮中选择“识别人脸”,点击下方的图片选择按钮图标选择图片后,在主显区域标记所有人脸识别的结果,并被逐条记录在表格中。本功能的界面展示如下图所示:
(二)人脸视频识别效果展示
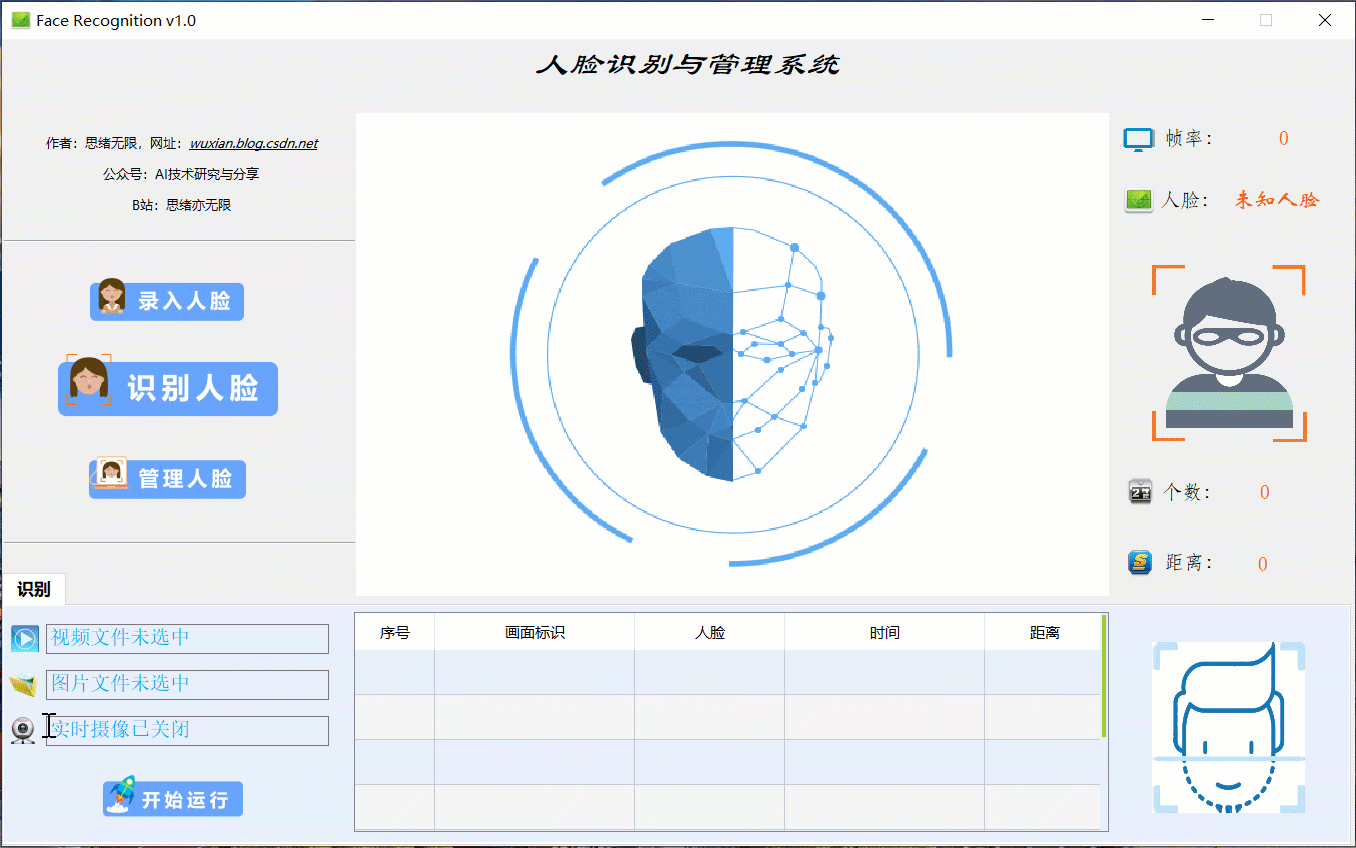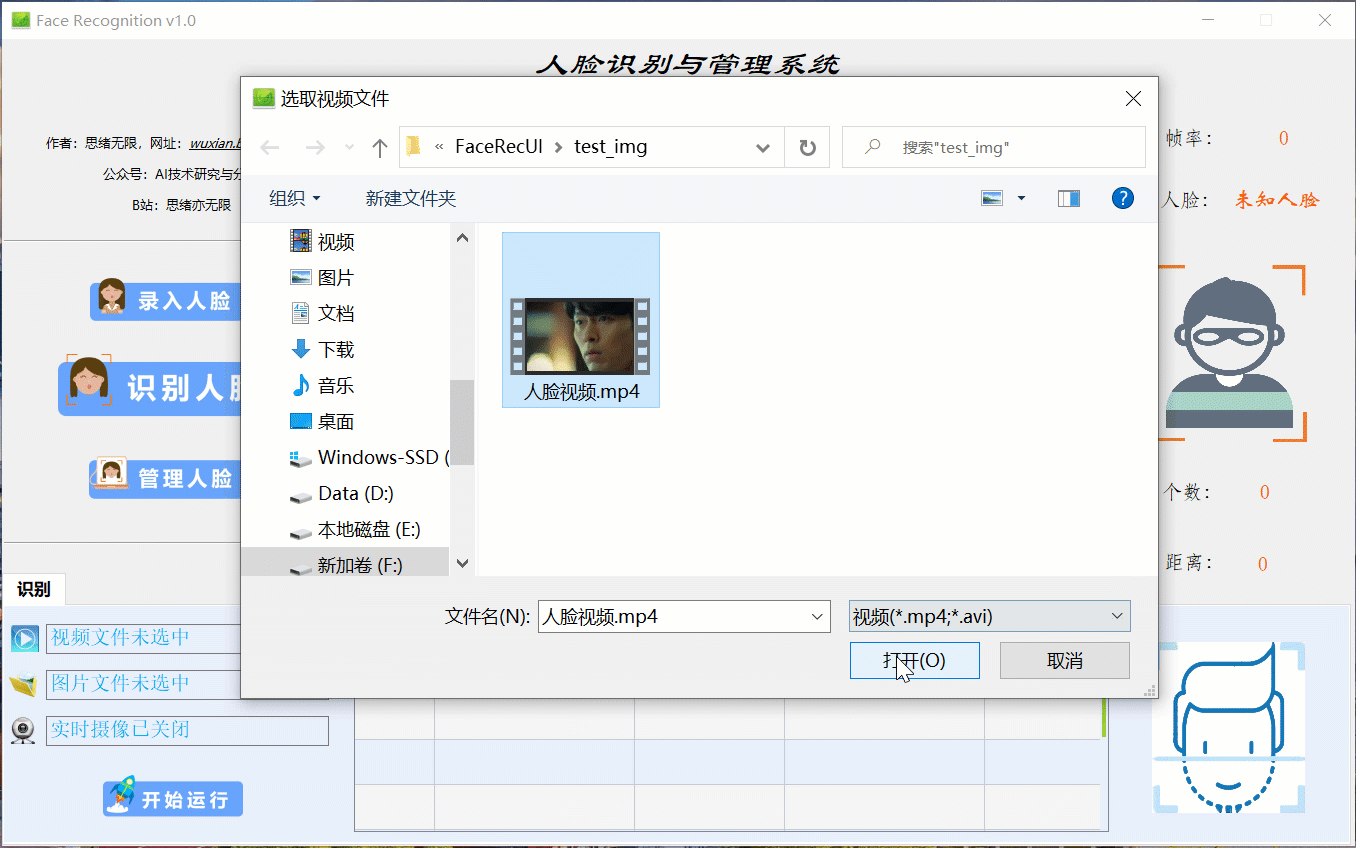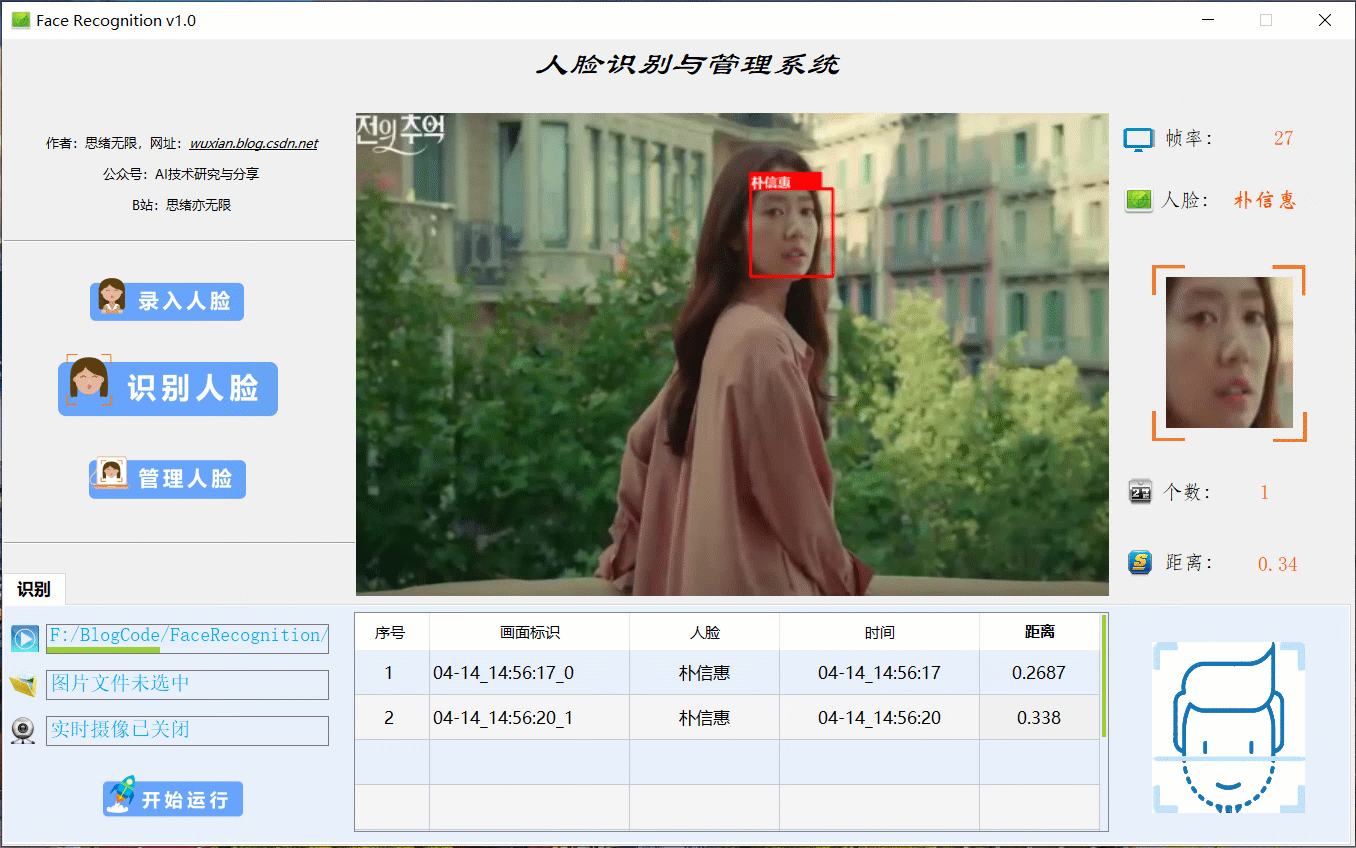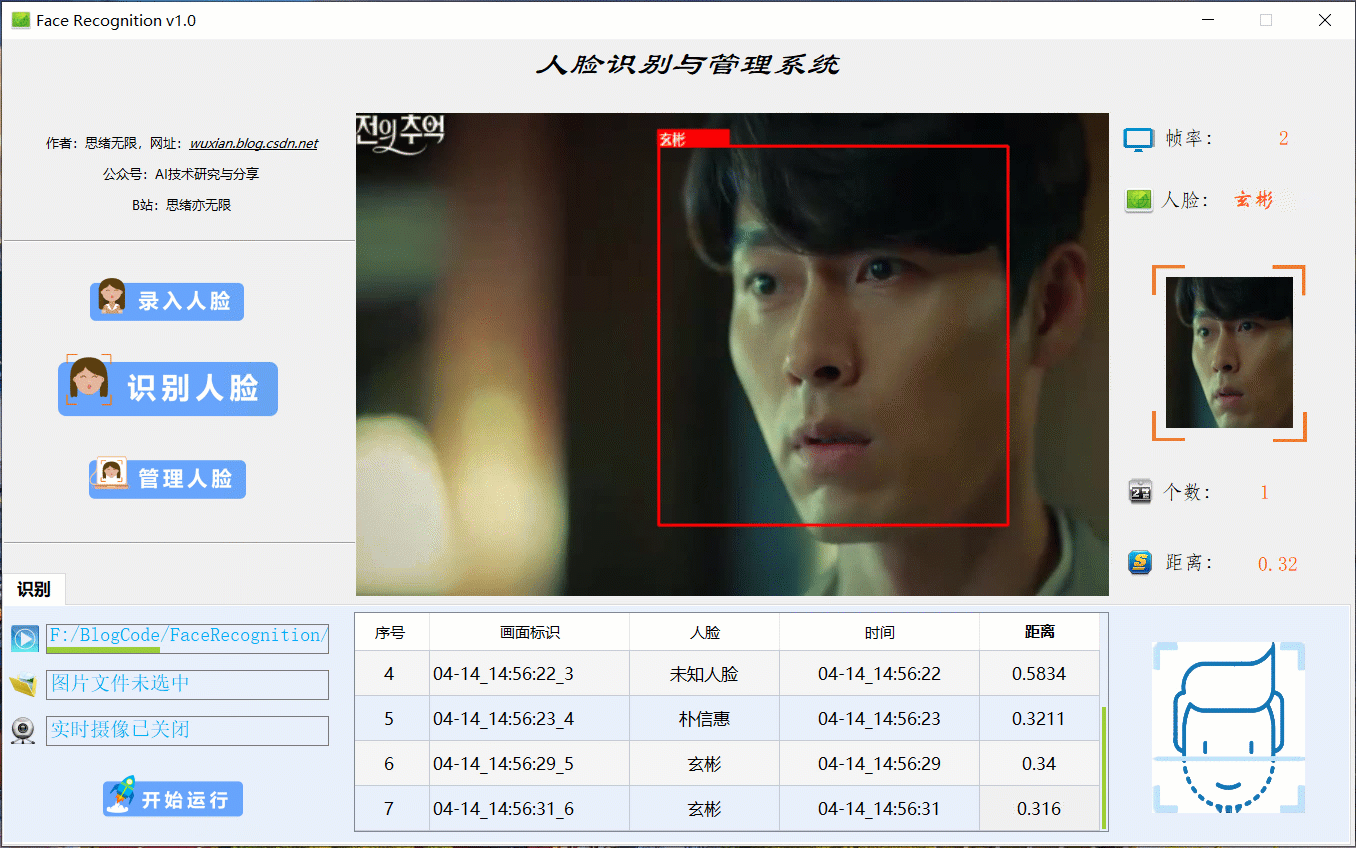
很多时候我们需要识别一段视频中的人脸信息,这里设计了视频选择功能。同样的在“识别人脸”功能选项下,点击视频按钮可选择待检测的视频,系统会自动解析视频逐帧识别人脸,并将结果记录在右下角表格中,效果如下图所示:
(三)摄像头检测效果展示
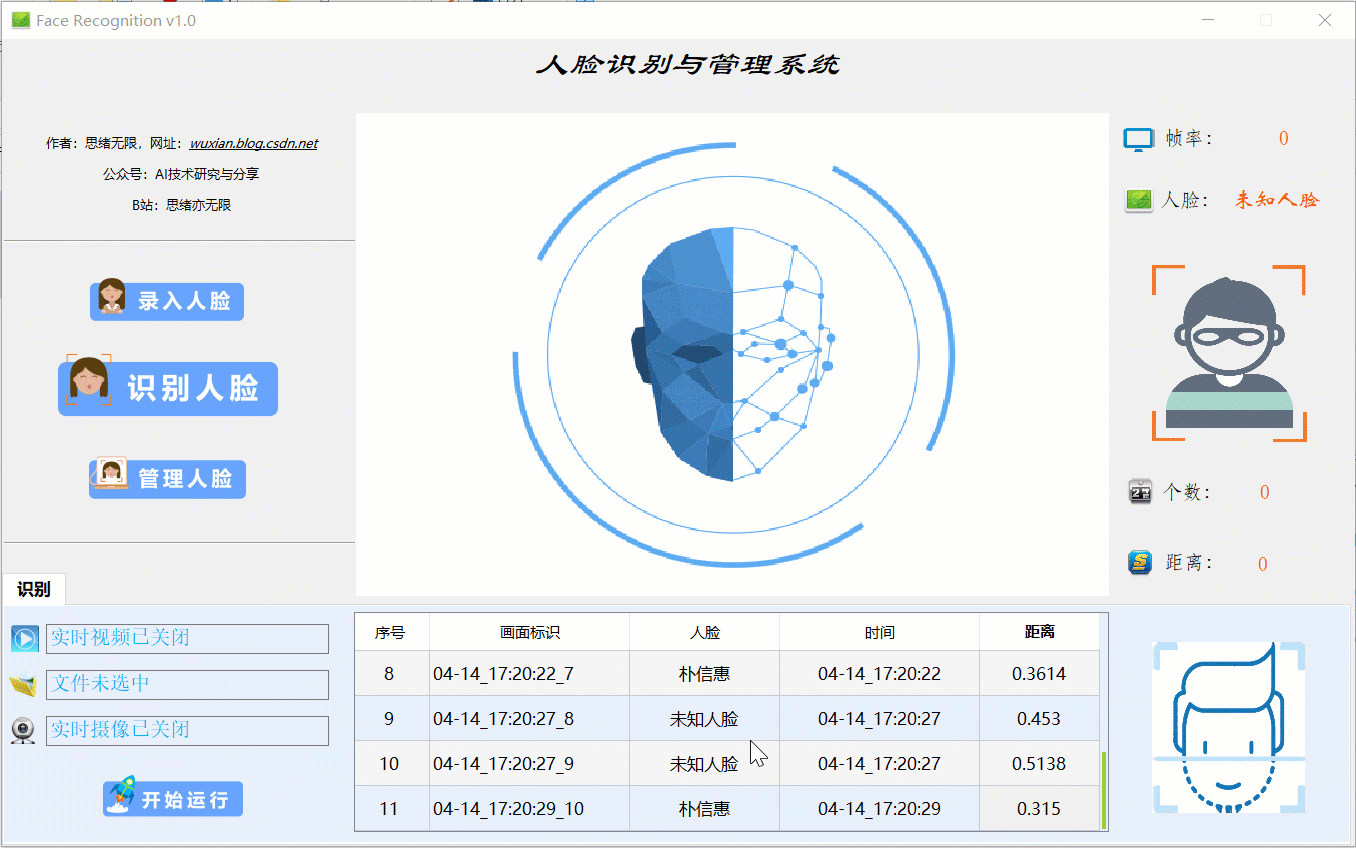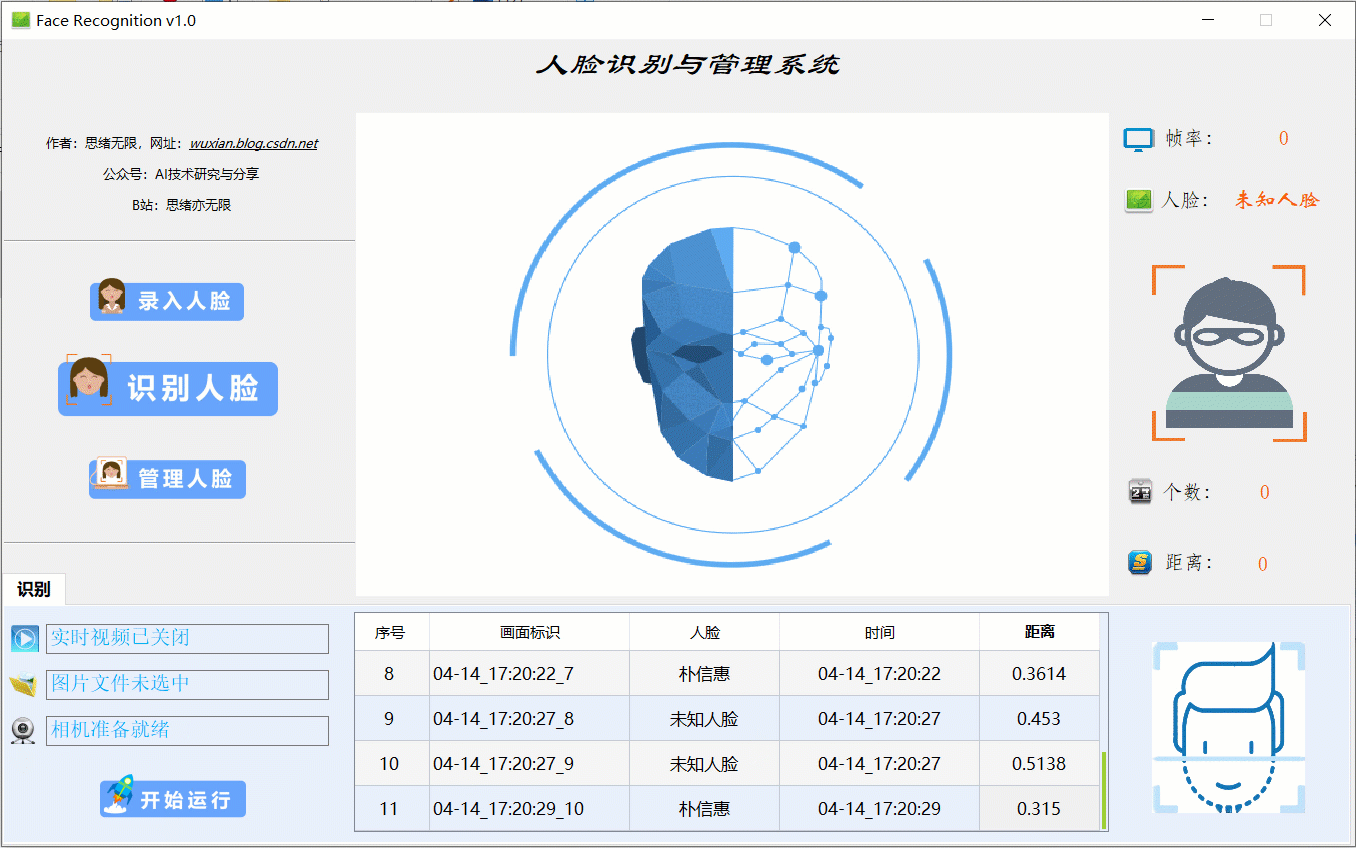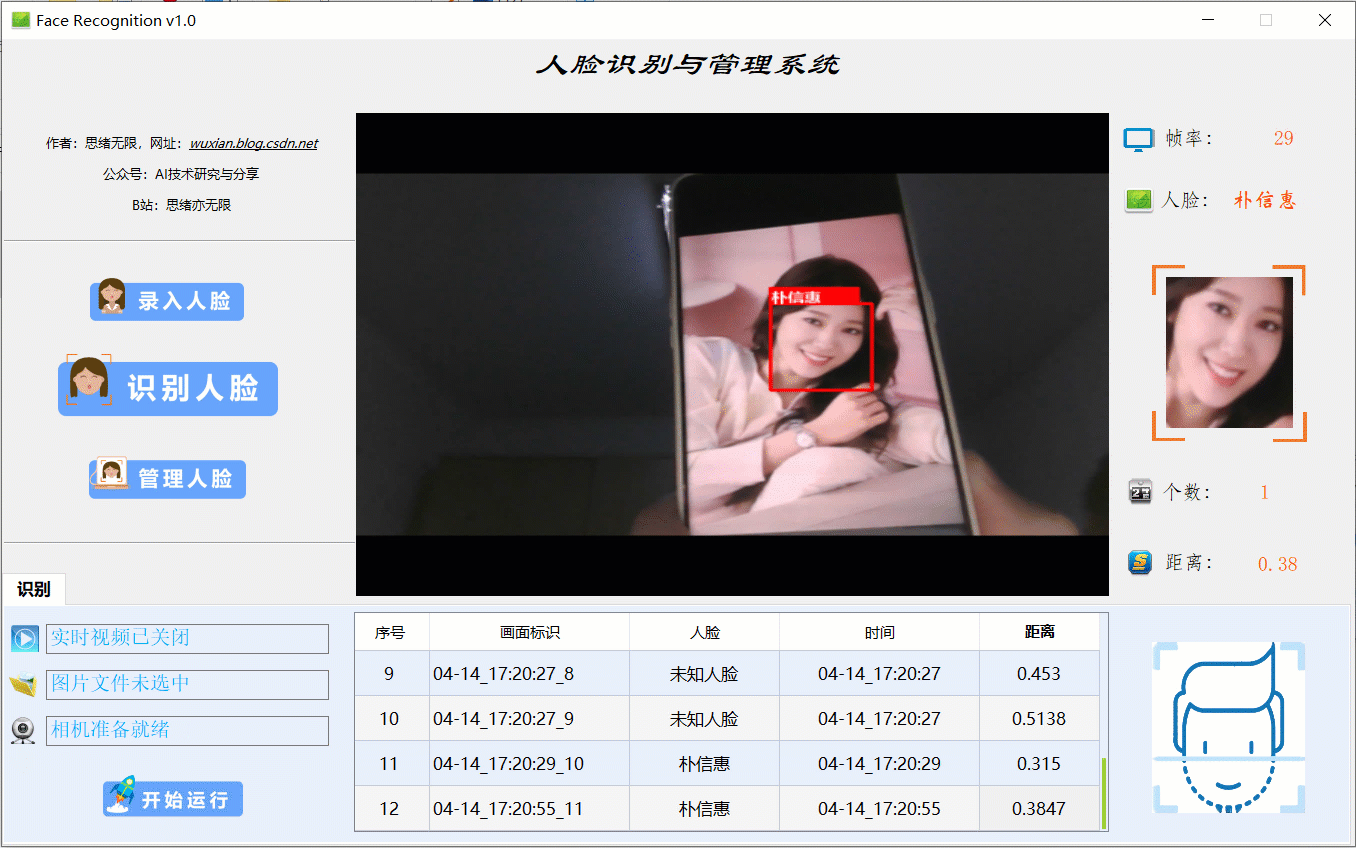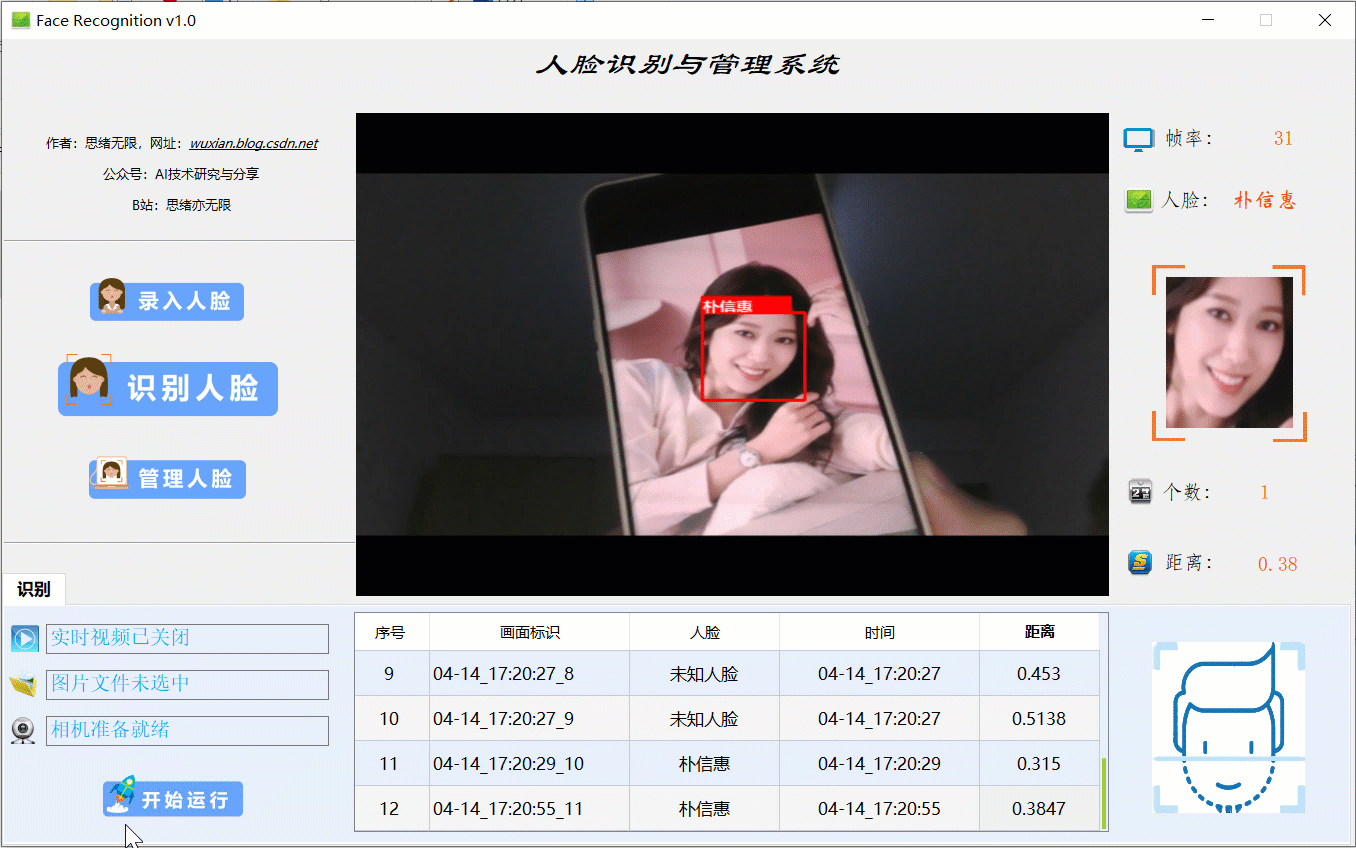
在真实场景中,我们往往利用设备摄像头获取实时画面,同时需要对画面中的人脸进行识别,同样可以在“识别人脸”功能选项下选择此项功能。如下图所示,点击摄像头按钮后系统进入准备状态,系统显示实时画面并开始检测画面中的人脸,识别结果展示如下图:
(四)录入人脸效果展示
当出现一个新的人脸需要录入时,点击“录入人脸”功能选项按钮,此时底部功能界面切换至录入功能,首先输入人脸名字点击“新建”后可通过选择人脸图片或开启摄像头进行画面捕捉,系统检测到人脸后可选择“取图”,系统得到捕获的人脸区域图片,最后点击“录入”按钮,则提取所有人脸图片特征并写入系统库中,演示效果如下:
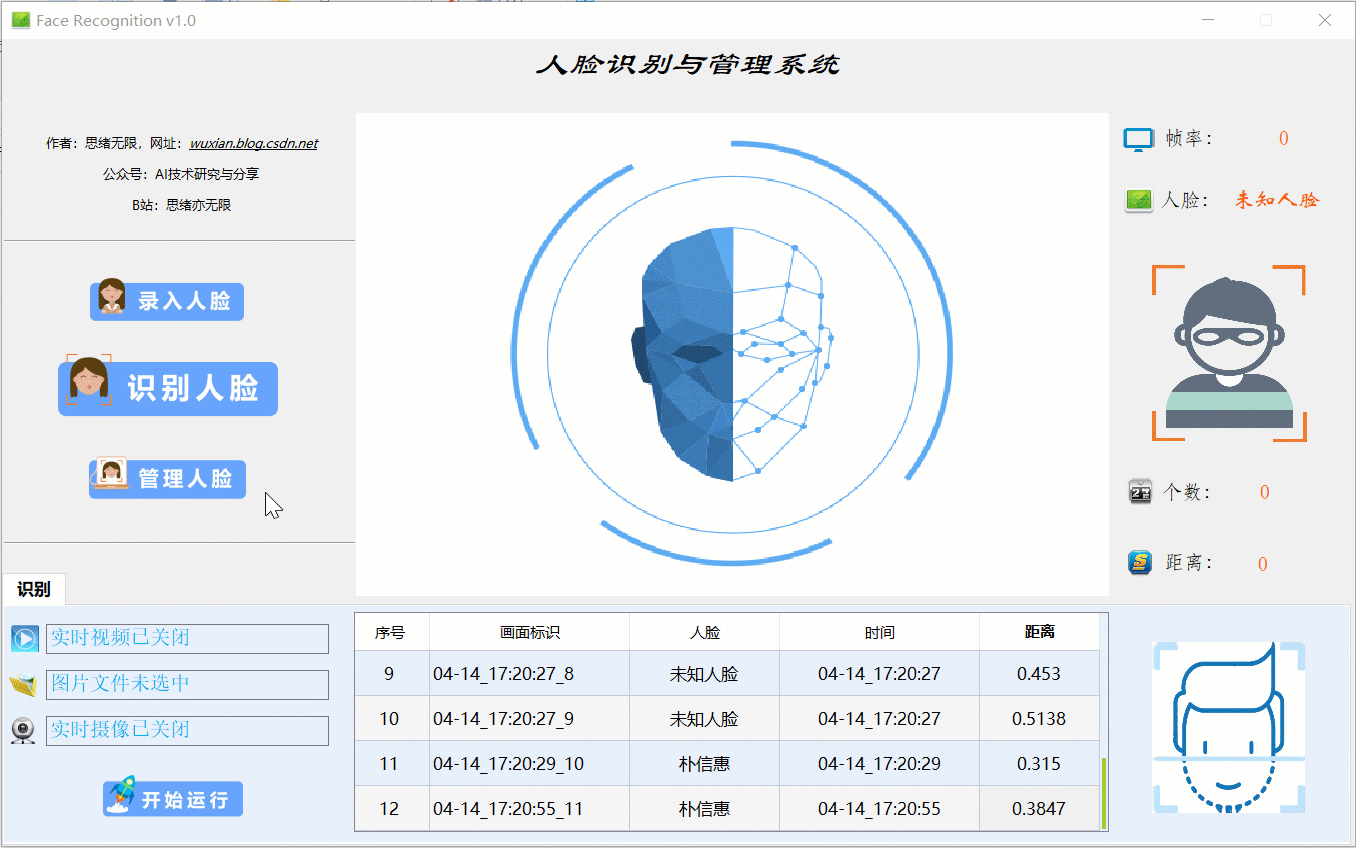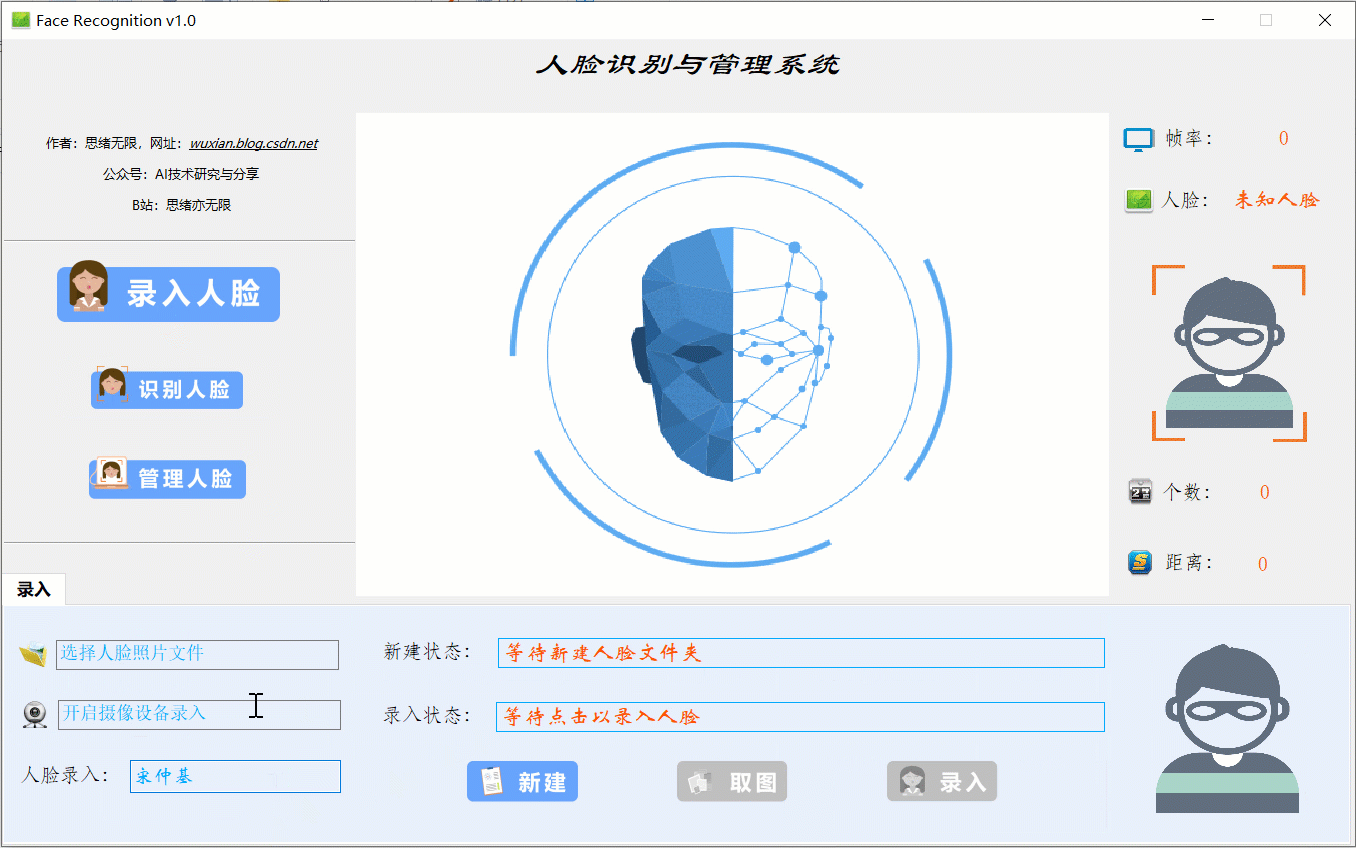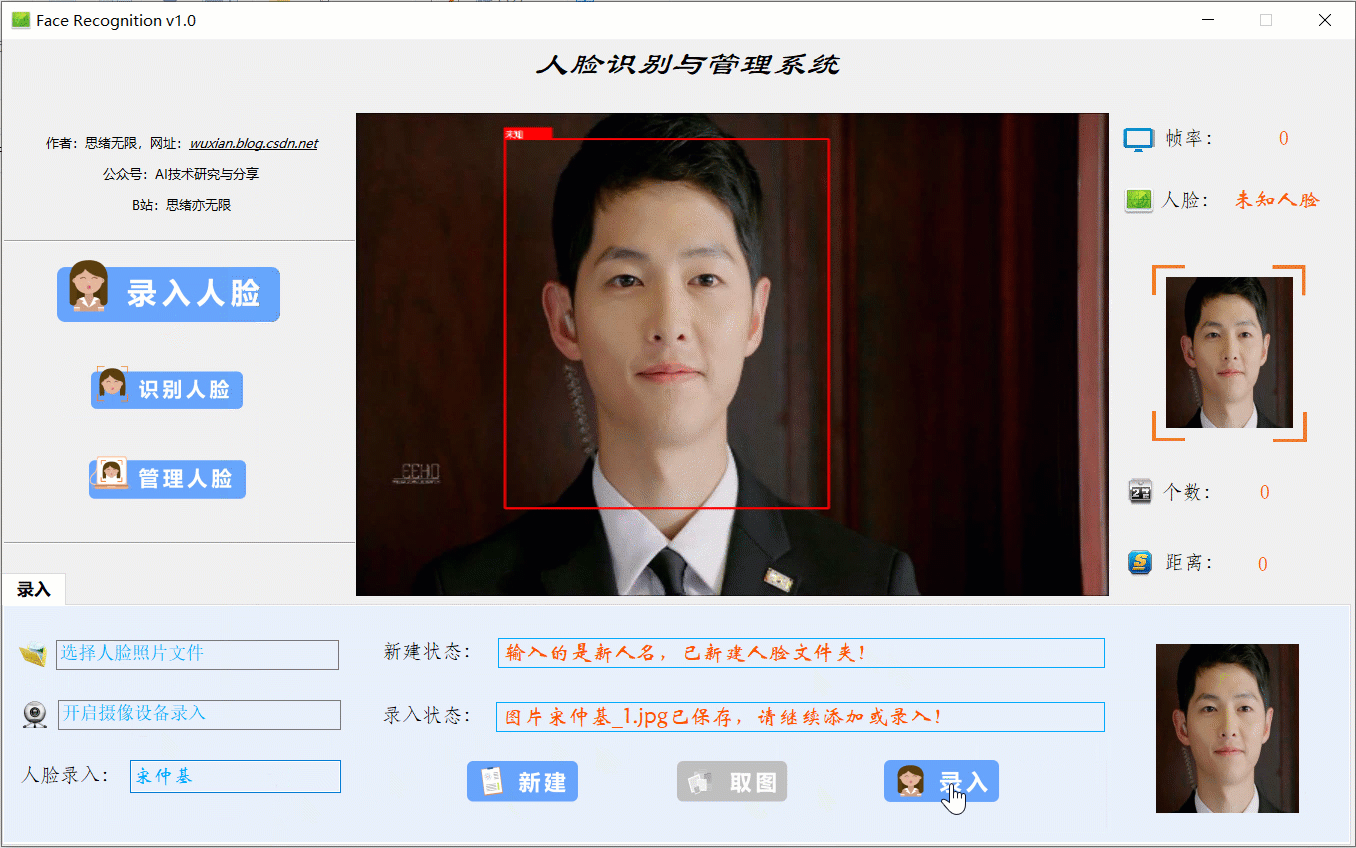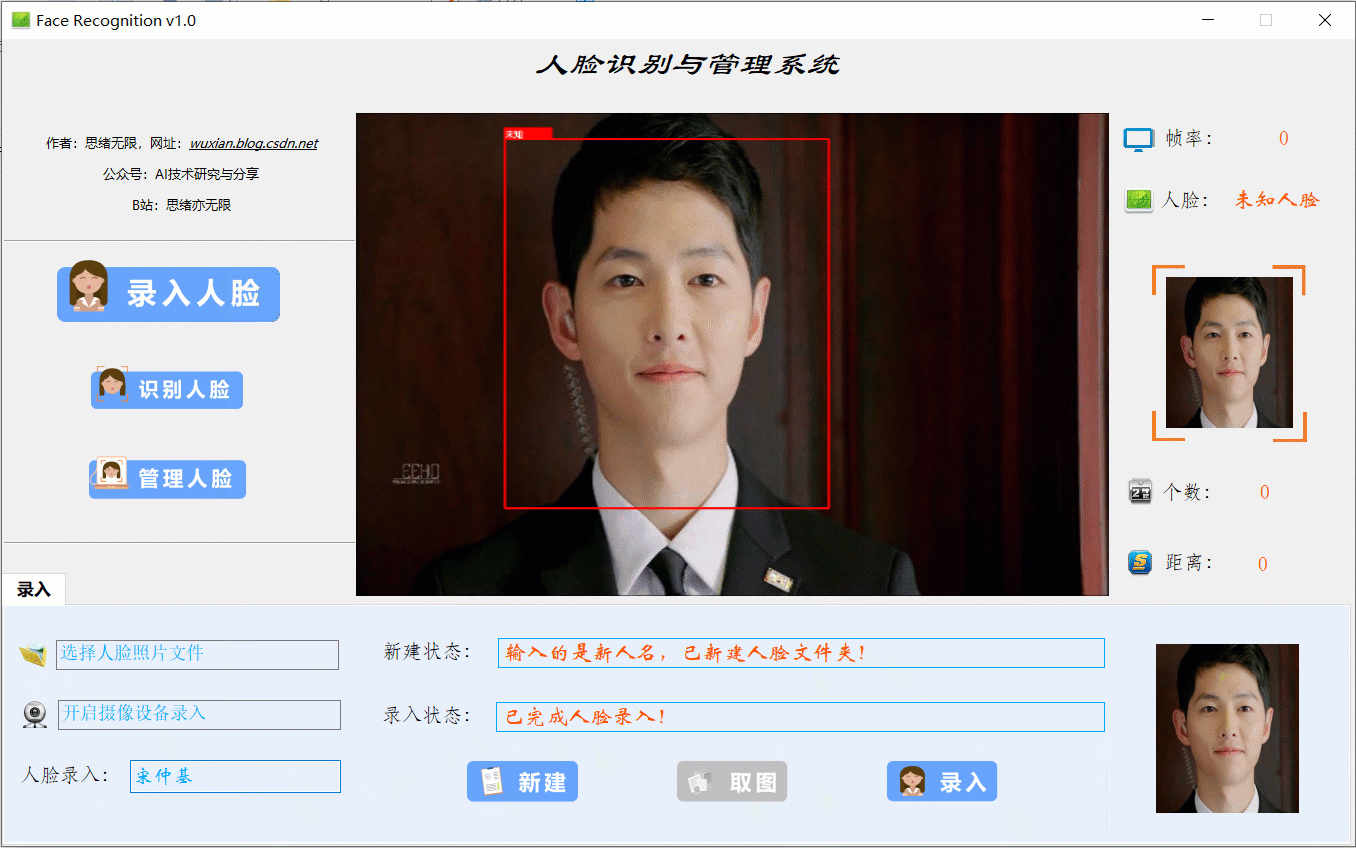
(五)管理人脸效果展示
对于已经存在的人脸数据可选择“管理人脸”功能选项按钮,切换至管理界面,选择表格中要删除或更新的人脸数据栏,点击确定后系统自动更新人脸数据库,该功能展示如下图:
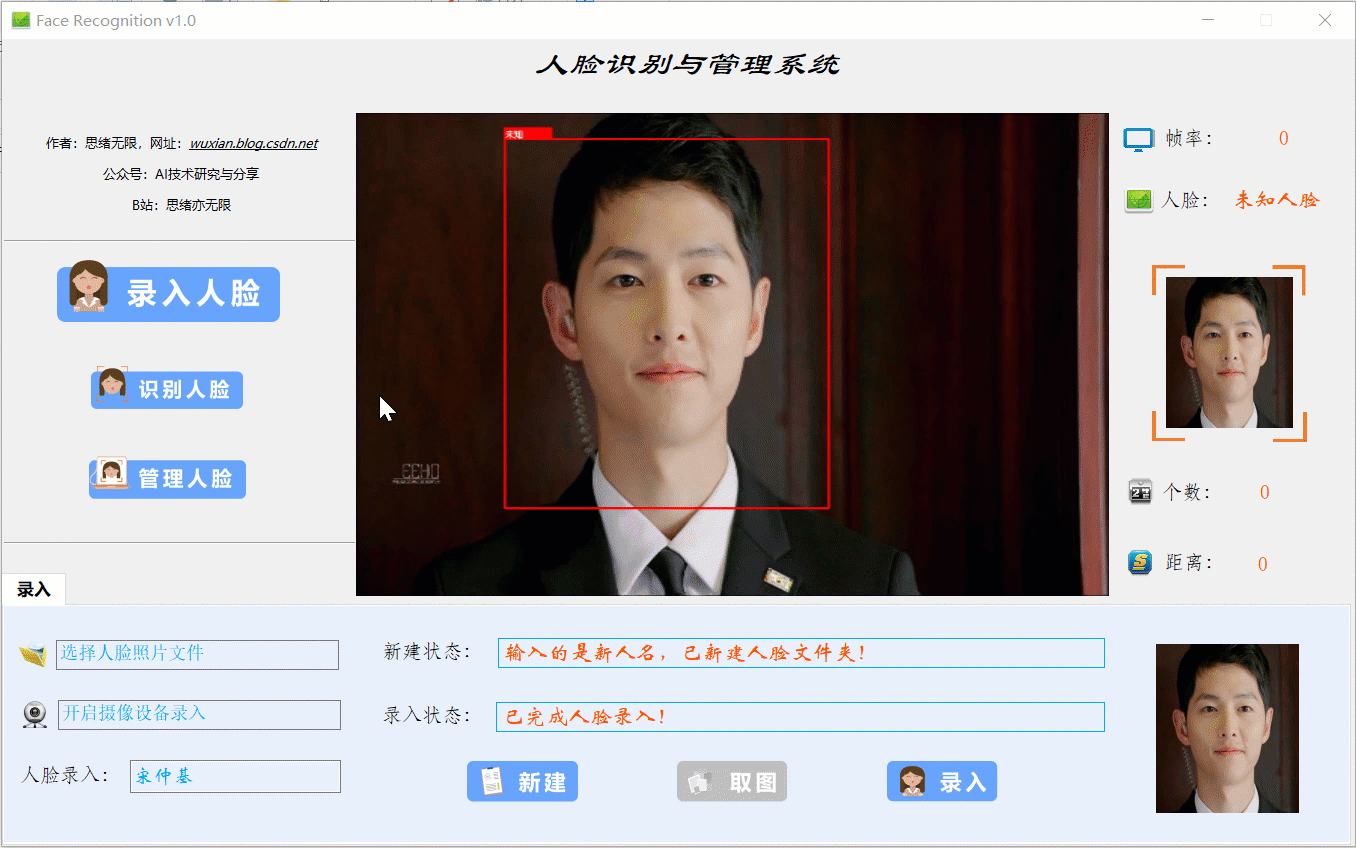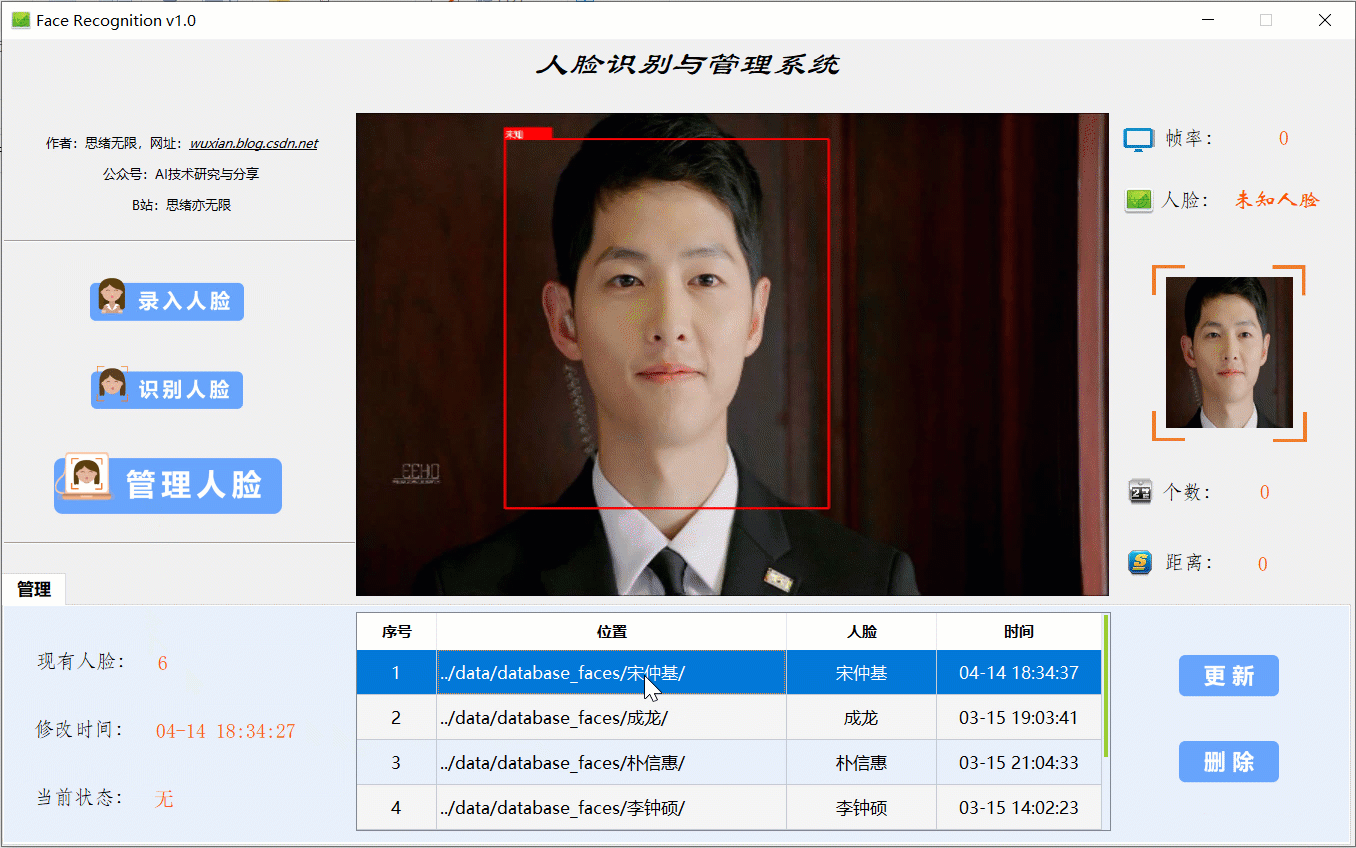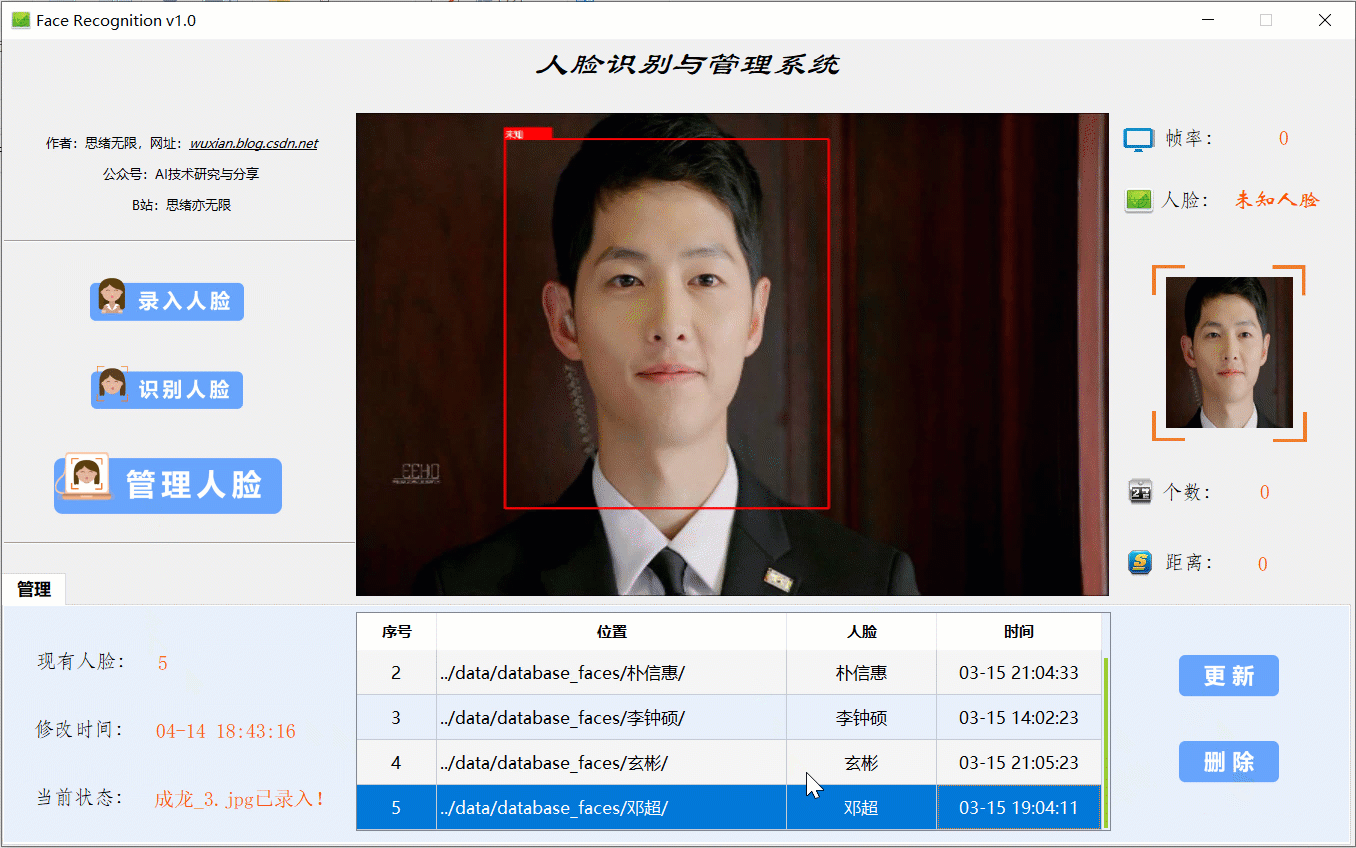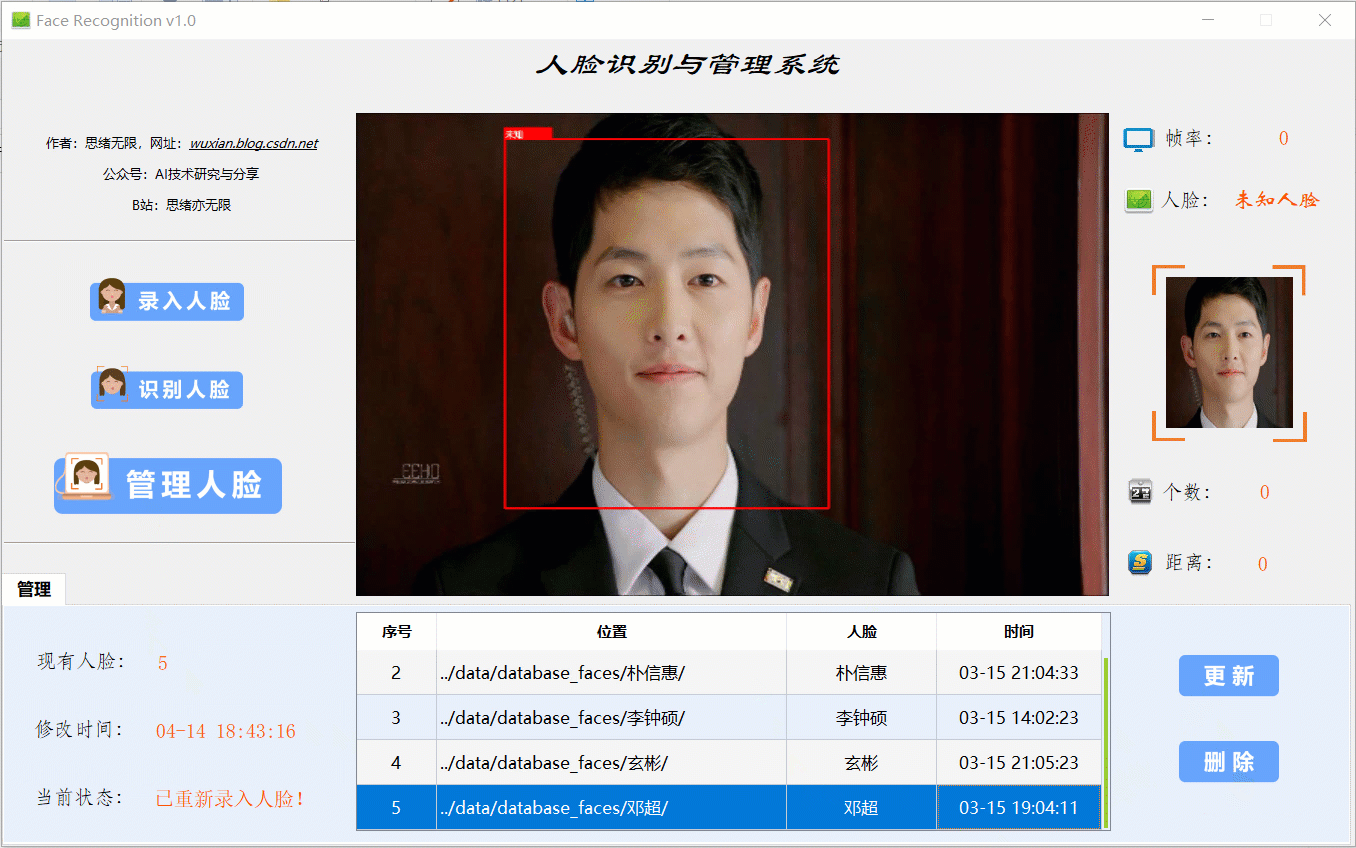
在识别某张特定人脸前,应该先在系统库中录入人脸信息,即送入一张人脸图像供系统提取特征,此过程可选择图片也可开启摄像头实时获取。至此系统的演示完毕,其实除了动图中演示的功能,当然还有许多细节功能无法一一演示,读者可以自行测试。
2. 人脸识别原理
如今机器学习、神经网络方法广泛应用于人脸识别领域,而后深度学习广泛应用于各种目标检测领域,2015年,Google团队的FaceNet在LFW数据集上得平均准确率达到了99.63%,基于深度学习的人脸识别的准确率已经高于人类本身,深度学习在人脸识别领域基本占据了统治地位。
Dlib是一个包含机器学习算法的C++开源工具包,目前已经被广泛的用在行业和学术领域,包括机器人,嵌入式设备,移动电话和大型高性能计算环境。作为人脸识别工具之一,Dlib在图像处理及人脸面部特征处理、分类、识别等方面具有计算简单、较容易实现的优点。
Dlib在人脸识别上的应用:(1)接受图像并将其加载到一个像素数组中进行处理;(2)使用局部二进制模式的人脸描述生成新的图像;(3)根据Dlib库中的scan_image_boxes等函数写入读取到的图片,进而计算人脸之间的特征向量;(4)与人脸数据库中的特征向量进行对比并利用全局函数threshold_image计算阈值,完成人脸识别[1]。
Dlib可通过Python调用,实现对图像预处理、提取特征向量、与人脸数据库中数据进行校验进而判别人物身份的流程。这里我们的人脸识别的过程有人脸检测(Face Detection)、人脸对齐(Face Alignment)、人脸表示(Face Representation)和人脸匹配(Face Matching),示意图如下图所示:

(1)人脸检测(Face Detection):首先利用Dlib的get_frontal_face_detector方法检测人脸区域并输出人脸矩形的四个坐标点。调用get_frontal_face_detector会返回 dlib 库中包含的预训练方向梯度直方图 (HOG)结合线性支持向量机(SVM)的人脸检测器,该检测器快速高效。由于方向梯度直方图 (HOG) 描述符的工作原理,它对图像几何的和光学的形变都能保持很好的不变性。
(2)人脸对齐(Face Alignment):这是人脸识别系统中的一种标准操作,即从人脸区域中检测到人脸特征点,并以特征点为依据对人脸进行归一化操作,使人脸区域的尺度和角度一致,方便特征提取与人脸匹配。一般通过旋转、平移与缩放将目标人脸区域放置在图像特定位置。这样做可以减小需要处理的人脸图像在空间分布上的差异。这里我们使用的是基于回归树的人脸对齐算法[2],该算法是Vahid Kazemi 和 Josephine Sullivan在CVPR2014上发表的One Millisecond Face Alignment with an Ensemble of Regression Trees算法(以下简称GBDT),这种方法通过建立一个级联的残差回归树(GBDT)来使人脸形状从当前形状一步一步回归到真实形状。每一个GBDT的每一个叶子节点上都存储着一个残差回归量,当输入落到一个节点上时,就将残差加到改输入上,起到回归的目的,最终将所有残差叠加在一起,就完成了人脸对齐的目的。此处我们使用shape_predictor方法载入shape_predictor_68_face_landmarks.dat模型实现。
(3)人脸表示(Face Representation):这一步我们从归一化的人脸区域中进行面部特征提取,采用深度神经网络方法得到具有128个特征的特征向量。这里利用Dlib中的残差学习深度神经网络(ResNet)[3]为待识别人脸创建128维特征向量。人脸的特征表示,最理想的情况是不同人脸的照片提取出的特征向量差异较大,而同一人脸在不同照片中可以提取出相似度高的特征向量。此处我们使用的是dlib库中的face_recognition_model_v1方法,使用预训练的dlib_face_recognition_resnet_model_v1.dat模型。
(4)人脸匹配(Face Matching):将待识别图片中提取的特征向量与比对图中的进行对比,通过评估方法计算两幅照片的相似度。可以根据相似得分,将得分高的判断为同一人,得分低的判断为不同人。这里我们使用欧式距离计算,两个人脸特征向量的欧式距离越小,则两张人脸越相似,若人脸图像与待识别人像之间的欧式距离小于设定的阈值(这里我设置为0.4)时,则判定为同一人。
3. 代码实现
原理介绍完毕,我们开始按照以上的步骤实现人脸识别过程。首先是导入几个需要用到的Python依赖包,我们使用的Python版本是3.8,其代码如下:
import dlib
import csv
import os
import cv2
import numpy as np
这里面值得要说的dlib这个依赖,是后面人脸识别算法需要用到的工具库,它的安装其实很简单,并不需要像网上说的安装Visual Studio 2015等软件(网上安装问题主要是dlib没有编译的安装包)。这里我将所有需要用到的依赖包都打包在了mylib文件夹中,并将依赖的版本号写入了requirements.txt文件中,如下图所示:
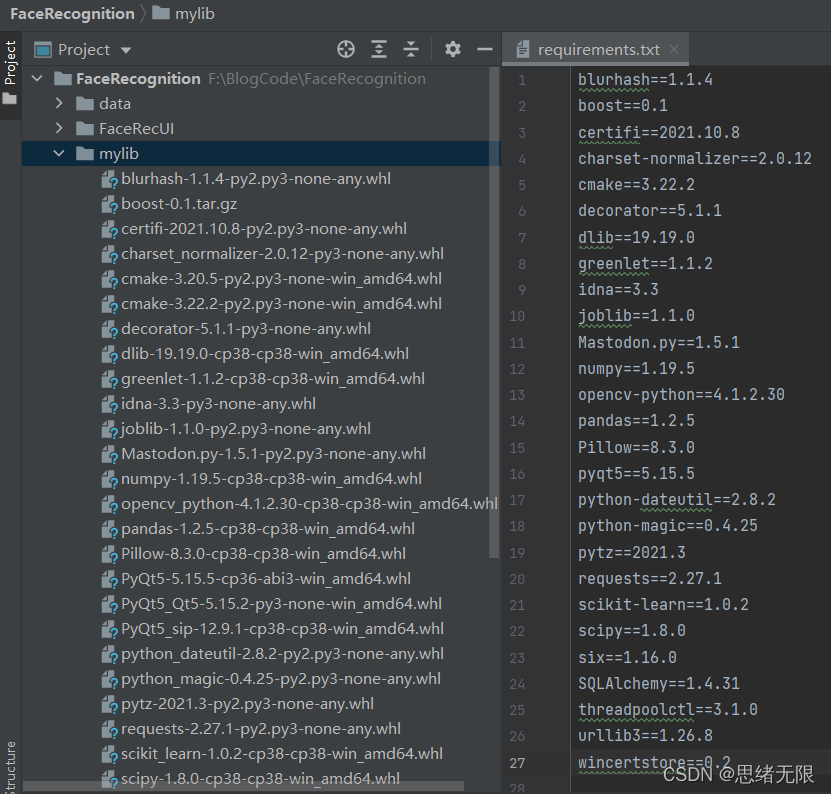
在安装有Python3.8的情况下,首先切换cmd的目录到mylib所在文件夹(requirements.txt也放在文件夹下),然后输入以下代码就可以完成依赖安装了。这样省去了版本不一致带来的出错或诸多麻烦,dlib也是优雅地安装好了。安装过程也可参考博主的B站视频,完整文件夹中有一键安装的bat文件可以帮助安装。
pip install -r requirements.txt --no-index --find-links=./mylib/
配置好环境和导入依赖后,可以正式开始代码的介绍了。首先我们载入dlib中的几个模型方法,其实现代码如下:
path_face_dir = "./data/database_faces/"
person_list = os.listdir(path_face_dir)
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('./data/data_dlib/shape_predictor_68_face_landmarks.dat')
face_reco_model = dlib.face_recognition_model_v1("./data/data_dlib"
"/dlib_face_recognition_resnet_model_v1.dat")
如上一章节介绍的,detector、predictor、face_reco_model分别是人脸检测器、人脸对齐方法、人脸表示(特征提取)模型。接下来我们写一个从图片中提取人脸特征的函数extract_features,该函数读取图片利用人脸检测器获取人脸位置,通过深度卷积神经网络Resnet进行特征提取,最终得到128维的特征向量。其代码如下:
def extract_features(path_img):
img_rd = cv2.imdecode(np.fromfile(path_img, dtype=np.uint8), -1)
faces = detector(img_rd, 1)
if len(faces) != 0:
shape = predictor(img_rd, faces[0])
face_descriptor = face_reco_model.compute_face_descriptor(img_rd, shape)
else:
face_descriptor = 0
return face_descriptor
我们将每个人脸的图像各建一个文件夹保存,将文件夹的名字作为该人脸的命名标识,如下图所示。每个文件夹下可放置一张或多张同类人脸图像,用以后面进行人脸特征提取,可自行收集人脸图像放置在对应文件夹下:
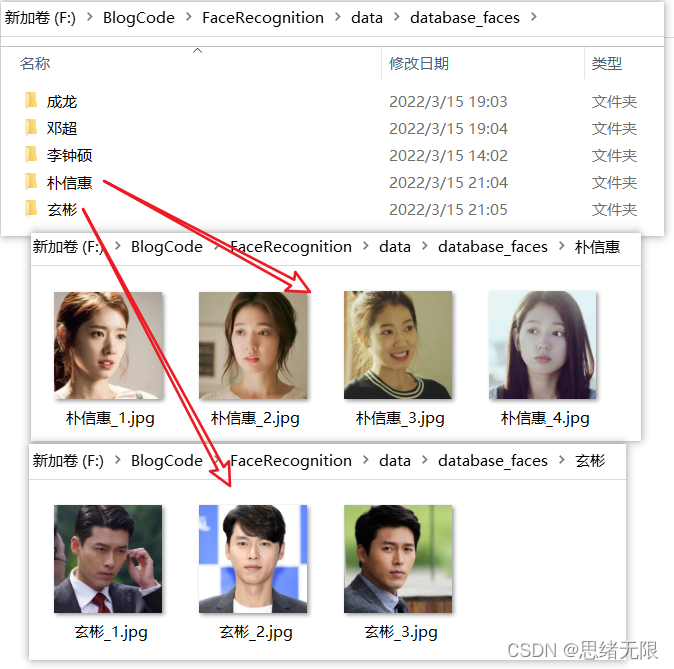
接下来就可以进行特征提取了,这样遍历上面目录中的每类人脸文件夹下的所有图像并提取特征,然后取均值保存在csv文件中即可完成特征提取并记录,该代码实现如下:
with open("./features_all_test.csv", "w", newline="") as csvfile:
writer = csv.writer(csvfile)
for person in person_list:
features_list = []
photos_list = os.listdir(path_face_dir + "/" + person)
if photos_list:
for photo in photos_list:
features_128D = extract_features(path_face_dir + "/" + person + "/" + photo)
print("图片" + photo + "已录入!")
if features_128D == 0:
continue
else:
features_list.append(features_128D)
if features_list:
features_mean = np.array(features_list).mean(axis=0)
else:
features_mean = np.zeros(128, dtype=int, order='C')
str_face = [person]
str_face.extend(list(features_mean))
writer.writerow(str_face)
print("已完成人脸录入!")
以上代码运行下来,提取到的人脸特征信息被写入csv文件中,部分信息如下图所示,每行的128个特征表示一个人脸信息,第一列为该人脸的名字:
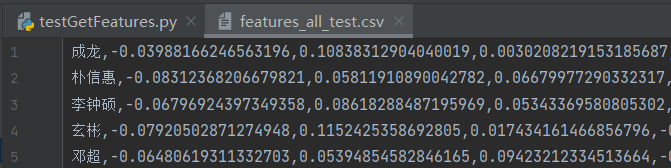
接下来利用提取到的特征进行人脸匹配,读取一张新的人脸图片然后判断其属于库中的那张人脸。同样的新建一个py文件,首先导入需要的依赖包,代码如下:
import os
import time
import warnings
import cv2
import dlib
import numpy as np
import pandas as pd
from PIL import Image, ImageDraw, ImageFont
由于后面需要在图像中显示中文,所以这里先利用PIL导入中文字体记为fontC,然后还是导入需要用到的三个模型,代码如下:
fontC = ImageFont.truetype("./FaceRecUI/Font/platech.ttf", 14, 0)
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('./data/data_dlib/shape_predictor_68_face_landmarks.dat')
face_reco_model = dlib.face_recognition_model_v1("./data/data_dlib"
"/dlib_face_recognition_resnet_model_v1.dat")
在匹配的过程中需要计算两个人脸特征向量间的距离(相似度),这里先定义一个计算特征向量的欧氏距离函数euclidean_distance,返回两个向量的距离值:
def euclidean_distance(feature_1, feature_2):
# 计算两个128D向量间的欧式距离
feature_1 = np.array(feature_1)
feature_2 = np.array(feature_2)
dist = np.sqrt(np.sum(np.square(feature_1 - feature_2)))
return dist
另外,检测和识别出的人脸结果需要标记在图像中,所以这里定义一个添加标记的函数drawRectBox,即利用OpenCV和PIL在人脸位置处绘制标记框和文字,其代码如下:
def drawRectBox(img, rect_pos, addText):
cv2.rectangle(img, (int(round(rect_pos[0])), int(round(rect_pos[1]))),
(int(round(rect_pos[2])), int(round(rect_pos[3]))),
(0, 0, 255), 2)
cv2.rectangle(img, (int(rect_pos[0] - 1), int(rect_pos[1]) - 16), (int(rect_pos[0] + 75), int(rect_pos[1])), (0, 0, 255), -1,
cv2.LINE_AA)
img = Image.fromarray(img)
draw = ImageDraw.Draw(img)
draw.text((int(rect_pos[0] + 1), int(rect_pos[1] - 16)), addText, (255, 255, 255), font=fontC)
image_x = np.array(img)
return image_x
函数准备就绪,开始主函数部分,首先读取一张人脸图片:
if __name__ == '__main__':
filePath = "./FaceRecUI/test_img/朴信惠-1.jpeg"
img_rd = cv2.imdecode(np.fromfile(filePath, dtype=np.uint8), -1)
从csv文件读取所有的人脸特征,将其保存在变量face_feature_exist中,用于后面的特征计算。这里读取时采用逐行遍历csv文件的方式,将每行的特征名和128维特征向量保存出来,空数据的标记为未知人脸。该部分代码如下:
face_feature_exist = []
face_name_exist = []
flag = False
# 读取已存入的人脸特征信息
if os.path.exists("./features_all_test.csv"):
path_features_known_csv = "./features_all_test.csv"
csv_rd = pd.read_csv(path_features_known_csv, header=None, encoding='gb2312')
for i in range(csv_rd.shape[0]):
features_someone_arr = []
for j in range(1, 129):
if csv_rd.iloc[i][j] == '':
features_someone_arr.append('0')
else:
features_someone_arr.append(csv_rd.iloc[i][j])
face_feature_exist.append(features_someone_arr)
if csv_rd.iloc[i][0] == '':
face_name_exist.append("未知人脸")
else:
face_name_exist.append(csv_rd.iloc[i][0])
exist_flag = True
else:
exist_flag = False
我们使用人脸检测器获取人脸位置,剪切出人脸区域;然后对人脸区域进行特征提取并将其与库中的特征进行比较,逐个计算欧几里得聚类,找出与之距离最小的库人脸;将最小距离与设定的阈值(0.4)进行比较,若小于0.4表示与该库人脸匹配,否则视为未知人脸。此流程的代码如下:
# 使用人脸检测器进行人脸检测
image = img_rd.copy()
faces = detector(image, 0)
if len(faces) > 0:
# 矩形框 / Show the ROI of faces
face_feature_list = []
face_name_list = []
face_position_list = []
start_time = time.time()
for k, d in enumerate(faces):
# 计算矩形框大小 / Compute the size of rectangle box
height = (d.bottom() - d.top())
width = (d.right() - d.left())
hh = int(height / 2)
ww = int(width / 2)
y2 = d.right() + ww
x2 = d.bottom() + hh
y1 = d.left() - ww
x1 = d.top() - hh
# 判断人脸区域是否超出画面范围
if y2 > img_rd.shape[1]:
y2 = img_rd.shape[1]
elif x2 > img_rd.shape[0]:
x2 = img_rd.shape[0]
elif y1 < 0:
y1 = 0
elif x1 < 0:
x1 = 0
# 剪切出人脸
crop_face = img_rd[x1: x2, y1: y2]
# 获取人脸特征
shape = predictor(img_rd, d)
face_feature_list.append(face_reco_model.compute_face_descriptor(img_rd, shape))
current_face = crop_face
if exist_flag: # 获取已存在人脸的特征
for k in range(len(faces)):
# 初始化
face_name_list.append("未知人脸")
# 每个捕获人脸的名字坐标
face_position_list.append(tuple(
[faces[k].left(), int(faces[k].bottom() + (faces[k].bottom() - faces[k].top()) / 4)]))
# 对于某张人脸,遍历所有存储的人脸特征
current_distance_list = []
for i in range(len(face_feature_exist)):
# 如果 person_X 数据不为空
if str(face_feature_exist[i][0]) != '0.0':
e_distance_tmp = euclidean_distance(face_feature_list[k],
face_feature_exist[i])
current_distance_list.append(e_distance_tmp)
else:
# 空数据 person_X
current_distance_list.append(999999999)
# 寻找出最小的欧式距离匹配
min_dis = min(current_distance_list)
similar_person_num = current_distance_list.index(min_dis)
if min_dis < 0.4:
face_name_list[k] = face_name_exist[similar_person_num]
end_time = time.time()
fps_rec = int(1.0 / round((end_time - start_time), 3))
for k, d in enumerate(faces):
# 计算矩形框大小 / Compute the size of rectangle box
height = (d.bottom() - d.top())
width = (d.right() - d.left())
hh = int(height / 2)
ww = int(width / 2)
rect = (d.left(), d.top(), d.right(), d.bottom())
image = drawRectBox(image, rect, face_name_list[k])
cv2.imshow('Stream', image)
c = cv2.waitKey(0) & 0xff
除了以上介绍的人脸匹配流程,这部分代码中还给出了识别出人脸后的标记过程。如果检测出人脸,则根据人脸的坐标未知绘制矩形框,根据识别结果在矩形框上方添加识别结果的文字,最后显示标记图像在窗口中。其运行结果如下图所示:

有了以上实现的基础,我们可以把这部分功能进行改进,添加进UI界面中方便我们选择图像和管理人脸库。打开QtDesigner软件,拖动以下控件至主窗口中,调整界面样式和控件放置,人脸识别系统的界面设计如下图所示:

控件界面部分设计好,接下来利用PyUIC工具将.ui文件转化为.py代码文件,通过调用界面部分的代码同时加入对应的逻辑处理代码。博主对其中的UI功能进行了详细测试,最终开发出一版流畅得到清新界面,就是博文演示部分的展示,完整的UI界面、测试图片视频、代码文件,以及Python离线依赖包(方便安装运行,也可自行配置环境),均已打包上传,感兴趣的朋友可以通过下载链接获取。
下载链接
若您想获得博文中涉及的实现完整全部程序文件(包括测试图片、视频,py, UI文件等,如下图),这里已打包上传至博主的面包多平台和CSDN下载资源。本资源已上传至面包多网站和CSDN下载资源频道,可以点击以下链接获取,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:

在文件夹下的资源显示如下,其中包含了Python的离线依赖包,读者可在正确安装Anaconda和Pycharm软件后,点击bat文件进行安装,详细演示也可见本人B站视频。
注意:本资源已经过调试通过,下载后可通过Pycharm运行;运行界面的主程序为runMain.py,测试图片脚本可运行testFaceDemo.py,测试人脸特征提取可运行testGetFeatures.py。为确保程序顺利运行,请配置Python版本:3.8,请勿使用其他版本,详见requirements.txt文件,如下:➷➷➷
blurhash == 1.1.4
boost == 0.1
certifi == 2021.10.8
charset-normalizer == 2.0.12
cmake == 3.22.2
decorator == 5.1.1
dlib == 19.19.0
greenlet == 1.1.2
idna == 3.3
joblib == 1.1.0
Mastodon.py == 1.5.1
numpy == 1.19.5
opencv-python == 4.1.2.30
pandas == 1.2.5
Pillow == 8.3.0
pyqt5 == 5.15.5
python-dateutil == 2.8.2
python-magic == 0.4.25
pytz == 2021.3
requests == 2.27.1
scikit-learn == 1.0.2
scipy == 1.8.0
six == 1.16.0
SQLAlchemy == 1.4.31
threadpoolctl == 3.1.0
urllib3 == 1.26.8
wincertstore == 0.2
完整资源下载链接1:https://mbd.pub/o/bread/mbd-YpmYlZtw
完整资源下载链接2:博主在CSDN下载频道的完整资源下载页
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。
徐怡彤, 王梅霞, 张培培. Dlib人脸识别在教师考勤中的应用[J]. 电脑编程技巧与维护, 2022(2):3. ↩︎
Kazemi V, Sullivan J. One millisecond face alignment with an ensemble of regression trees[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 1867-1874. ↩︎
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778. ↩︎
