
十六进制字符E2 80 8B导致的字符串问题
0x00 最近在处理文本时发现一个奇怪的问题:
中国共产主义青年团
和
中国共产主义青年团
这两个字符串不相等。刚开始怀疑我自己的业务逻辑除了问题,后来发现不是,于是怀疑编码有问题,有不可见字符,挨个字符的处理才发现在上面那个字符串的“产”和“主”之间有个不可见字符:E2 80 8B。
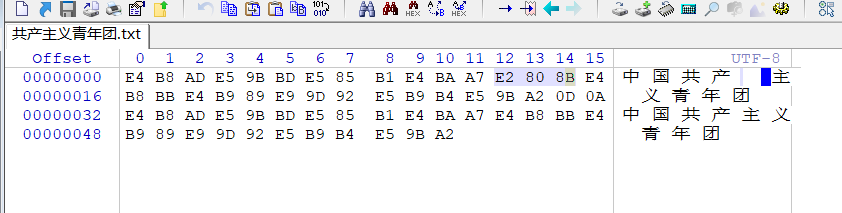
如下图所示:
于是在网上搜索发现竟然有很多人遇到这个问题。参考了这篇文章:
https://blog.sciencenet.cn/home.php?mod=space&uid=1213210&do=blog&id=1198408
怕博客丢失,转发到下面:
前段时间发现一个有意思的现象,从SCIFinder检索的CA文本信息复制到Chemfinder数据库中文本控件内,有些字符之间出现了奇怪的空格。如果试图删除这些空格,会把空格之前的一个字符删掉,与平时的操作大相径庭。把含有这些奇怪空格的字串复制到UltraEdit中切换到十六进制显示,研究了一番之后发现,是三个字节E2 80 8B导致的。这三个字节切换到文本状态时是看不到的。
下面我演示一下实际的效果,它的十六进制值(在UltraEdit中查看)

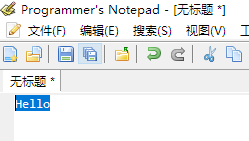
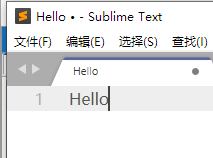
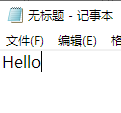
切换到文本模式中查看是正常的(复制到Word,记事本,Sublime Text 3,Programmer's notepad等编辑器中查看也是正常的)


但是在VBA的文本框控件(放在窗体中),或者在ChemFinder的文本框控件中,包含了此特殊字符的文本显示奇怪的现象,如下:
")

出现了这样的奇怪字符,当然我要去除(或过滤/替换/删除)它们。尝试了用VBA中的Replace函数,多次尝试也不行。那么用正则表达式来匹配会怎么样呢? 由于我在用正则表达式解析这些文本以提取信息,因此就想到了用正则表达式的替换功能把它除去。很显然这是一个非常规的字符,应该是特殊的Unicode字符,于是我尝试先把它用正则表达式匹配出来。研究了下Unicode的表示方式,在PowerGrep中进行试验(有人说PowerGrep是Windows下最强大的正则查找工具,支持的语法十分丰富,就先用它试试)。然而试验结果十分意外,不论如何表达如何拆分,所有我想到的表达方式都试过了,(无论\uE280, \u{E2808B}, 甚至\uE2808B) 都完全没有办法匹配到。明显这个小小的字符就在那里,可无论如何就是匹配不上;既然匹配不到,当然也就无法删除了。真是让人着急又无解。
无奈之下,我想到了请教《正则指南》的作者余晟,在微信公众号上给他留言,果然他功力深厚,两天之后,他发给一个网络链接,打开一看,原来别人也问过相同问题,为了匹配这个E2 80 8B这个字符,解答中说要用\u200B去搜索。虽然不明白原因,我一尝试就找到了匹配,果然成功了。哦耶!
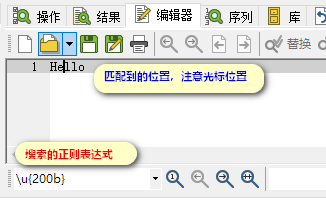
这又是为什么呢? 问答里面没有讲得太清楚。我再回过头来查《正则指引》的第2版,正好这一版里面增加了对Unicode的值与传输的编码的关系,才算是弄清楚了缘故。
原来,我的小程序是在C#中写的,C#中的字符串,都是用Unicode值存储的,因此正则引擎匹配的也是字符串的Unicode值。Unicode可以说我不陌生,但一直搞不清与UTF-8是什么关系什么来源。借机学习一下弄明白了,就再说一说。
Unicode和UCS
Unicode是国际标准组织发明的一种编码方案,包括UCS(Universal Character Set 通用字符集)和UTF(Unicode Transformation Format Unicode变换格式),也就是一个超大的字符集的码值和 对码值进行存储/传输时的编码方式。从字符集看,整个UCS设计了17个平面,每个平面有65536个编码空间,码值从0到1114111共一百多万个,可以容纳全世界的各书写语言的各种字符和符号。最前面的一个平面(从码值0到65535)称为基本多语言平面(BMP),日常用到的绝大多数文字字符都包含在这里面。目前到2019.9最新的Unicode标准是12.1,编码最大的到2FA1D。
UTF-8编码方式
但是Unicode字符在存储或传输时,并不是直接传输Unicode编码的,而是用UTF-8 或UTF-16这类编码方法编码之后再传输的。目前最常用的是UTF-8这种编码方式。
比如,当我在UltraEdit中查看E2 80 8B这个字符时,编辑器它默认是用UTF-8编码,也就是我看到的特殊字符并不是这个字符真正的Unicode码值(英文Code Point),而是它的码值经过UTF-8编码方式处理之后的值。在正则表达式的匹配中,要匹配的是它的码值(code point),因此必须把这个(编码过的)UTF-8编码还原成Unicode字符的码值Code Point才能正确匹配。这也是为什么我一直基于UTF-8编码来匹配字串无法命中的原因。
我们先来看一下,Unicode码值是怎么转变成UTF-8编码的呢?
对于一个Unicode码值,UTF-8编码后得到的结果可能是1个到3个字节,与码值的范围有关。
处理时要将码值转化成二进制来处理比较直观。(U+表示这是一个Unicode码值,用16进制表示)
1)码值U+0 ~ U+7F → 0xxxxxxx (x为码值的二进制数值,一个x表示1个二进制位(0或1),不足时高位补0)
2)码值U+80 ~ U+7FF →110xxxxx 10xxxxxx(将原码值二进制从右到左取6位,放到10之后;再向左取剩下的位数,高位补0到5位,放到110之后;新构成的数即为UTF-8编码)
3)码值U+800 ~ U+FFFF →1110xxxx 10xxxxxx 10xxxxxx(操作方法同上。大部分汉字编码在U+4E00~ U+9FFF范围之内,因此UTF-8中用三字节来表示)
4)码值U+10000~U+1FFFFF →11110xxx 10xxxxxx 10xxxxxx 10xxxxxx(操作方法同上。这里码值从十进制的65536即\u10000, 到21位全部用完即\u1FFFF(十进制2097151)有两百多万个值,完全可以满足Unicode码值个数的要求,也就是说最多用四个字节就可以给任何一个Unicode码值进行UTF-8编码)。
经过以上改造,每个部分都是8位。以8位为一个单位进行传输,这也是UTF-8中8的来源。
对英文等大部分字符只要一个字节就可以表示一个字符,比较节省空间。但对汉字来讲,基本上每个汉字要用三个字节。这种表示方法比GBK方案(每个汉字用2个字节表示)要体积要大一点。
也许有人要问,为什么不直接用Unicode编码存储或传输呢?我的理解是,因为Unicode是连续编码的,它自身无法区分前后两个字符是如何截取的。所以要借助编码方法来进行一定的区分。
上面还可以总结出来一个规律,除了码值在127以下的Unicode字符(主要是最早的ASCII字符)其UTF-8编码用一个字节表示,高位为0外;其它2~4字节表示的UTF-8码值,其最高位是N个连续的1(后面跟一个0), 就表示这个编码是N个字节的,很方便读取数值。
理解了上述处理过程之后,再来看看E2 80 8B是什么样的Unicode字符编码得到这个UTF-8编码。
E2 80 8B写成二进制11100010 10000000 10001011(红色部分为编码时加上去的“前缀“)
高位是3个1连续,后面接一个0.表示这个是三字节,没错。对照上述的处理结果,三字节的第一个字节去掉高位的1110, 第2个字节去掉高位的10, 第3个也去掉高位的10,剩下来是0010 000000 001011,合并起来得到 0010000000001011,将这两个再转换成十六进制,即200B这两个码值。
也就是说,我们在UTF-8编码下看到的E2 80 8B这个特殊字符,它其实本身是Unicode码值为十六进制200B的字符。
由于我们太习惯于所见即所得的编辑方式,就误以为所有情景下都是如此。实际上,在文本处理上,用正常的文本作为字串或正则表达式的内容,系统会自动按照编码方案将其文本还原成其Unicode码值,正则式和被查找字串都做过相同的处理,结果当然就能符合。但如果你是用十六进制来指定直接UTF-8编码结果而不是Unicode码值,系统就没有为你做“UTF-8编码→Unicode码值“ 这个操作,正则式与字串两个地方的编码方案都没有统一,对汉字这种Unicode码值与UTF-8编码不一样的情况来讲,匹配不上才是正常的!
再回过头来看,这个十六进制值为200B的字符是什么东西呢?查找Unicode Charts, 可以知道这是一个叫Zero Width Space的特殊字符,即零宽度字符。一般的空格即码值为\u20的空格是占有一定宽度的,这个字符则是分隔单词但又不占用宽度,在实际文本中应该是不显示的。


由于它是零宽度字符,如果你在PowerGrep中用正则表达式\u200B去搜索,匹配后可以看到光标停留在这个位置。说明它确实是存在的(PowerGrep的文本显示也正常)。
但在某些控件中,它不能正确识别这个特殊字符(有可能它的编码不支持或许没有配置到UTF-8),把它当成了二个或三个字符(取决于编码方案的识别,在ASCII方案中,E2是一个可见字符a,80和8B是不可见的控制字符),因此就出现了奇怪的空白。
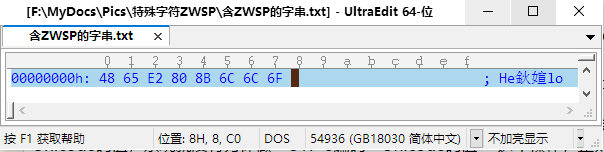
如果你观察仔细的话,还可以看到有一个例子中显示的不是空白而是"鈥媗",这又是什么原因呢?
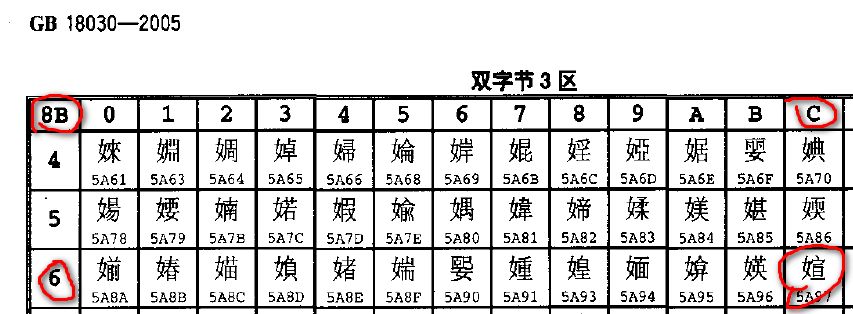
推测是该控件用GB18030标准来解析文本。E2 80 8B后面跟的小写l字母编码是6C,它把E2 80 当成一个汉字,8B
6C又是一个汉字,它吃掉了后面一个l字母,还原出来就是GB18030标准中的"鈥媗"两个汉字(见下图)。
注意: GB18030是我国的标准,与ISO发布的Unicode的码值是不一样的,并不兼容。

在UTF-8编码的文本中,还存在着一种带BOM和不带BOM的区别,与这个话题也有点关系,顺便补充一下,引用网上的一段解释,如下(有修改) :
UTF-8有BOM和无BOM的区别 (by change_any_time)
本文链接:https://blog.csdn.net/change_any_time/article/details/79572370
BOM——Byte Order Mark,就是字节序标记
在UCS 编码中有一个名称为"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF。


还有一个码值(code piont)是FFFE的,在UCS中是不存在的字符,不应该出现在实际传输中。

UCS规范建议我们在传输字节流前,先传输字符
"ZERO WIDTH NO-BREAK
SPACE"。如果接收者收到FEFF,就表明这个字节流是大字节序的;如果收到FFFE,就表明这个字节流是小字节序的。因此字符"ZERO
WIDTH NO-BREAK SPACE"又被称作BOM。
UTF-8编码本身不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF BB BF, 如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
对比一下可以发现,存为UTF-8 带有BOM的,前三个字节是EF BB BF;存为UTF-8无BOM的,就把前三个字节删掉了,后面的内容是一样的。
不过删除含有E2 80 8B这个特殊字符时的奇怪行为,我还不太理解是什么原因,估计是特殊字符误导了控件对文本长度和位置指示的结果导致显示异常。既然是少数情况下的BUG,也就懒得深究了。
后来,我就用以下一句把多余的E2 80 8B字符给删掉了,问题解决。
srcString=Regex.Replace(srcString, @"\u200B","");
////////////////////////////////
////////Sixi. Let it be.../////
//////////////////////////////


 浙公网安备 33010602011771号
浙公网安备 33010602011771号