堆排序(java)
目录
基础堆排序
一、概念及其介绍
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。
堆是一个近似 完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
二、适用说明
我们之前构造堆的过程是一个个数据调用 insert 方法使用 shift up 逐个插入到堆中,这个算法的时候时间复杂度是 O(nlogn),本小节介绍的一种构造堆排序的过程,称为 Heapify,算法时间复杂度为 O(n)。
三、过程图示
完全二叉树有个重要性质,对于第一个非叶子节点的索引是 n/2 取整数得到的索引值,其中 n 是元素个数(前提是数组索引从 1 开始计算)。
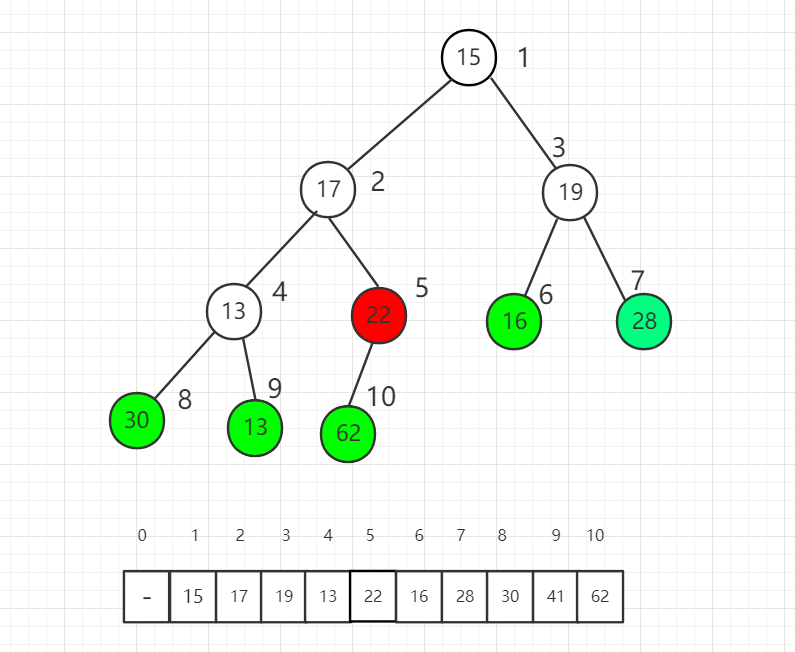
索引 5 位置是第一个非叶子节点,我们从它开始逐一向前分别把每个元素作为根节点进行 shift down 操作满足最大堆的性质。
索引 5 位置进行 shift down 操作后,22 和 62 交换位置。

对索引 4 元素进行 shift down 操作

对索引 3 元素进行 shift down 操作

对索引 2 元素进行 shift down 操作

最后对根节点进行 shift down 操作,整个堆排序过程就完成了。
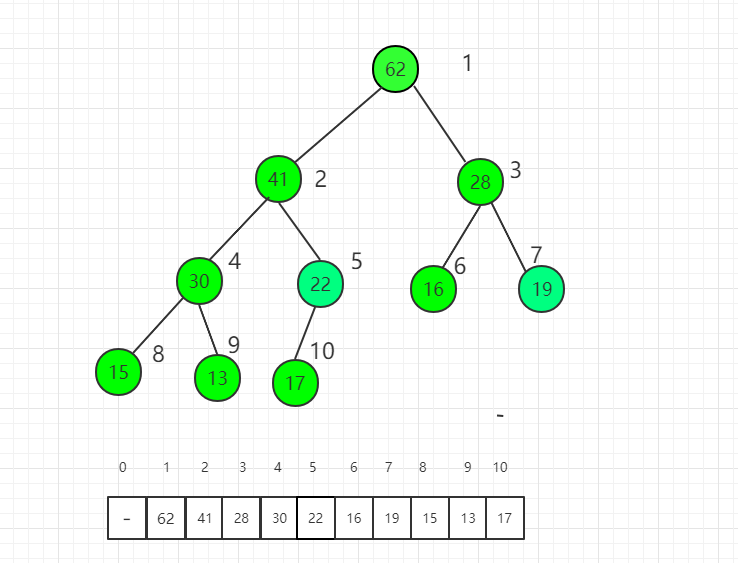
四、Java 实例代码
Heapify.java
/**
* 用heapify进行堆排序
*/
public class Heapify<T extends Comparable> {
protected T[] data;
protected int count;
protected int capacity;
// 构造函数, 通过一个给定数组创建一个最大堆
// 该构造堆的过程, 时间复杂度为O(n)
public Heapify(T arr[]){
int n = arr.length;
data = (T[])new Comparable[n+1];
capacity = n;
for( int i = 0 ; i < n ; i ++ )
data[i+1] = arr[i];
count = n;
//从第一个不是叶子节点的元素开始
for( int i = count/2 ; i >= 1 ; i -- )
shiftDown(i);
}
// 返回堆中的元素个数
public int size(){
return count;
}
// 返回一个布尔值, 表示堆中是否为空
public boolean isEmpty(){
return count == 0;
}
// 像最大堆中插入一个新的元素 item
public void insert(T item){
assert count + 1 <= capacity;
data[count+1] = item;
count ++;
shiftUp(count);
}
// 从最大堆中取出堆顶元素, 即堆中所存储的最大数据
public T extractMax(){
assert count > 0;
T ret = data[1];
swap( 1 , count );
count --;
shiftDown(1);
return ret;
}
// 获取最大堆中的堆顶元素
public T getMax(){
assert( count > 0 );
return data[1];
}
// 交换堆中索引为i和j的两个元素
private void swap(int i, int j){
T t = data[i];
data[i] = data[j];
data[j] = t;
}
//********************
//* 最大堆核心辅助函数
//********************
private void shiftUp(int k){
while( k > 1 && data[k/2].compareTo(data[k]) < 0 ){
swap(k, k/2);
k /= 2;
}
}
private void shiftDown(int k){
while( 2*k <= count ){
int j = 2*k; // 在此轮循环中,data[k]和data[j]交换位置
if( j+1 <= count && data[j+1].compareTo(data[j]) > 0 )
j ++;
// data[j] 是 data[2*k]和data[2*k+1]中的最大值
if( data[k].compareTo(data[j]) >= 0 ) break;
swap(k, j);
k = j;
}
}
// 测试 heapify
public static void main(String[] args) {
int N = 100;
Integer[] arr = SortTestHelper.generateRandomArray(N, 0, 100000);
Heapify<Integer> heapify = new Heapify<Integer>(arr);
// 将heapify中的数据逐渐使用extractMax取出来
// 取出来的顺序应该是按照从大到小的顺序取出来的
for( int i = 0 ; i < N ; i ++ ){
arr[i] = heapify.extractMax();
System.out.print(arr[i] + " ");
}
// 确保arr数组是从大到小排列的
for( int i = 1 ; i < N ; i ++ )
assert arr[i-1] >= arr[i];
}
}SortTestHelper.java
public class SortTestHelper {
// SortTestHelper不允许产生任何实例
private SortTestHelper(){}
// 生成有n个元素的随机数组,每个元素的随机范围为[rangeL, rangeR]
public static Integer[] generateRandomArray(int n, int rangeL, int rangeR) {
assert rangeL <= rangeR;
Integer[] arr = new Integer[n];
for (int i = 0; i < n; i++)
arr[i] = new Integer((int)(Math.random() * (rangeR - rangeL + 1) + rangeL));
return arr;
}
// 打印arr数组的所有内容
public static void printArray(Object arr[]) {
for (int i = 0; i < arr.length; i++){
System.out.print( arr[i] );
System.out.print( ' ' );
}
System.out.println();
return;
}
优化堆排序
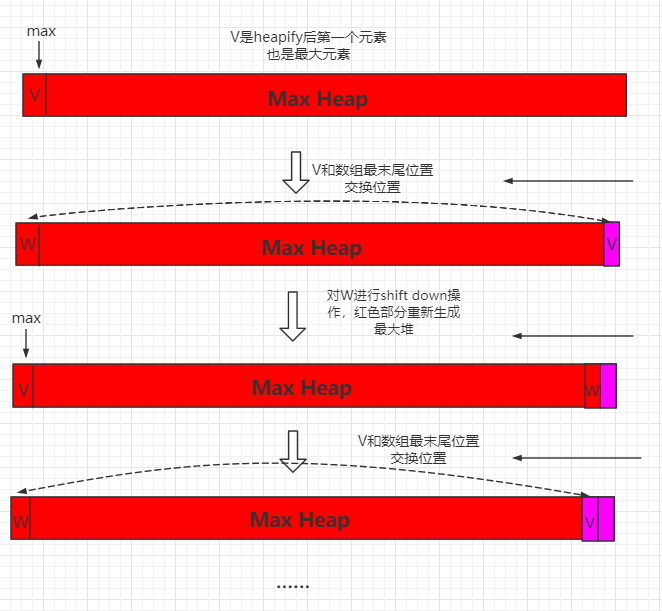
上一节的堆排序,我们开辟了额外的空间进行构造堆和对堆进行排序。这一小节,我们进行优化,使用原地堆排序。
对于一个最大堆,首先将开始位置数据和数组末尾数值进行交换,那么数组末尾就是最大元素,然后再对W元素进行 shift down 操作,重新生成最大堆,然后将新生成的最大数和整个数组倒数第二位置进行交换,此时到处第二位置就是倒数第二大数据,这个过程以此类推。
整个过程可以用如下图表示:
Java 实例代码
HeapSort.java
/**
* 原地堆排序
*/
public class HeapSort<T extends Comparable> {
public static void sort(Comparable[] arr) {
int n = arr.length;
// 注意,此时我们的堆是从0开始索引的
// 从(最后一个元素的索引-1)/2开始
// 最后一个元素的索引 = n-1
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
shiftDown(arr, n, i);
for (int i = n - 1; i > 0; i--) {
swap(arr, 0, i);
shiftDown(arr, i, 0);
}
}
// 交换堆中索引为i和j的两个元素
private static void swap(Object[] arr, int i, int j) {
Object t = arr[i];
arr[i] = arr[j];
arr[j] = t;
}
// 原始的shiftDown过程
private static void shiftDown(Comparable[] arr, int n, int k) {
while (2 * k + 1 < n) {
//左孩子节点
int j = 2 * k + 1;
//右孩子节点比左孩子节点大
if (j + 1 < n && arr[j + 1].compareTo(arr[j]) > 0)
j += 1;
//比两孩子节点都大
if (arr[k].compareTo(arr[j]) >= 0) break;
//交换原节点和孩子节点的值
swap(arr, k, j);
k = j;
}
}
// 测试 HeapSort
public static void main(String[] args) {
int N = 100;
Integer[] arr = SortTestHelper.generateRandomArray(N, 0, 100000);
sort(arr);
// 将heapify中的数据逐渐使用extractMax取出来
// 取出来的顺序应该是按照从大到小的顺序取出来的
for (int i = 0; i < N; i++) {
System.out.print(arr[i] + " ");
}
// 确保arr数组是从大到小排列的
for (int i = 1; i < N; i++)
assert arr[i - 1] >= arr[i];
}
}SortTestHelper.java
public class SortTestHelper {
// SortTestHelper不允许产生任何实例
private SortTestHelper(){}
// 生成有n个元素的随机数组,每个元素的随机范围为[rangeL, rangeR]
public static Integer[] generateRandomArray(int n, int rangeL, int rangeR) {
assert rangeL <= rangeR;
Integer[] arr = new Integer[n];
for (int i = 0; i < n; i++)
arr[i] = new Integer((int)(Math.random() * (rangeR - rangeL + 1) + rangeL));
return arr;
}
// 打印arr数组的所有内容
public static void printArray(Object arr[]) {
for (int i = 0; i < arr.length; i++){
System.out.print( arr[i] );
System.out.print( ' ' );
}
System.out.println();
return;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端