
二叉搜索树的顺序性
------------------siwuxie095
二叉搜索树的顺序性
二叉搜索树具有一定的顺序性,即 使用二叉搜索树可以回答很多
元素之间的和顺序相关的问题,如下:
(1)minimum 和 maximum
通过二叉搜索树可以非常容易地找到一组数据中最小的元素 minimum
和最大的元素 maximum
(2)predecessor 和 successor
通过二叉搜索树可以非常容易地找到一个元素的前驱 predecessor
和后继 successor
(3)floor 和 ceil
通过二叉搜索树还可以找到一个元素的 floor 相应的值
和 ceil 相应的值
floor 和 ceil 与 predecessor 和 successor 的最大的一个区别就是:
要想找到一个元素的前驱和后继,首先要保证这个元素真的存在
如果要找一个元素的 floor 和 ceil:
1)如果该元素存在,那么该元素的 floor 和 ceil 就是该元素本身
2)如果该元素不存在,那么该元素的 floor 和 ceil 也是存在的,
分别是最后一个比该元素小的值和第一个比该元素大的值,即 最
接近的两个值。当然,也有可能该元素并没有 floor 或 ceil
(4)rank 和 select
通过二叉搜索树还可以找到一个元素的排名 rank
和找到某排名(如:第 100 名)的元素 select
但遗憾的是一般的二叉搜索树并不能回答这两个问题,可做如下改动:
对二叉搜索树的每一个节点多添加一个属性(域),该属性用于存储
以当前节点为根的二叉搜索树一共有几个节点
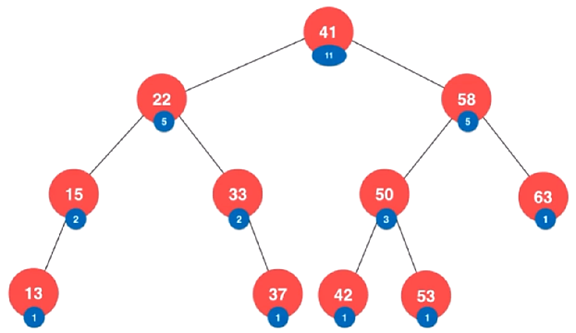
之后就可以利用二叉搜索树的性质:每个节点的键值都大于左孩子
和 每个节点的键值都小于右孩子,来实现 rank 和 select
注意:在给节点 Node 添加新属性后,编写 rank 和 select 这两个
函数并不难,难的是要在之前实现的 insert 和 remove 这两个函数
中同时维护新属性,使得当用户调用 rank 和 select 这两个函数时,
能够得到正确的结果
另外:
一般的二叉搜索树,是不支持整棵树中存在重复元素的,但在
有些情况下,需要二叉搜索树支持重复元素,该怎么做呢?
一个最简单的方法,就是直接让这棵树可以存在重复元素,即
把一个节点的左孩子,定义成是小于等于这个节点的元素,右
孩子是大于这个节点的元素
不过当存在大量重复元素时,这样做不够节省空间
为此,依然可以通过更改节点 Node 的结构来解决,具体如下:
对二叉搜索树的每一个节点多添加一个属性 count,该属性用于存储
当前节点所代表的元素在二叉搜索树中的个数
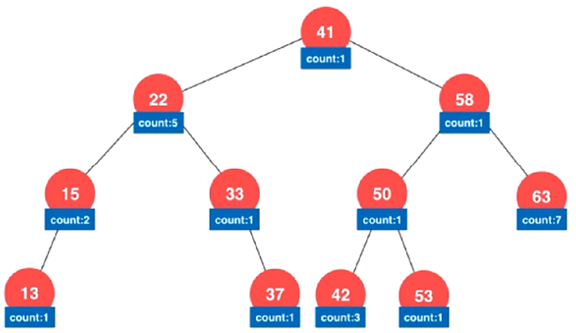
此时,构建出这样一棵二叉搜索树很容易,不过当每个节点都多出一个
count 属性后,相应的 insert 和 remove,以及 rank 和 select 等等都
要发生改变,以维护 count 属性
【made by siwuxie095】
posted on 2017-06-11 08:50 siwuxie095 阅读(330) 评论(0) 编辑 收藏 举报

