
图 续3
------------------siwuxie095
程序 1:
1)使用邻接矩阵存储无向图
2)使用深度优先搜索(DFS)和广度优先搜索(BFS)进行遍历
Node.h:
|
#ifndef NODE_H #define NODE_H
class Node { public: //默认有参构造函数 Node(char data = 0);
char m_cData;
//标识当前节点有没有被访问过 //被访问过就置为true bool m_bIsVisited; };
#endif |
Node.cpp:
|
#include "Node.h"
Node::Node(char data) { m_cData = data; m_bIsVisited = false; } |
CMap.h:
|
#ifndef CMAP_H #define CMAP_H
#include "Node.h" #include <vector> using namespace std;
//之所以在Map前加个C,是因为Map本身是标准模板库的类名, //为了能够区分,就在前面加了一个C,叫做CMap class CMap { public: CMap(int capacity); ~CMap(); bool addNode(Node *pNode); //向图中加入顶点(节点) void resetNode(); //重置顶点:将每一个顶点设为未访问过
//为有向图设置邻接矩阵,默认权值为1 bool setValueToMatrixForDirectedGraph(int row, int col, int val = 1); //为无向图设置邻接矩阵,默认权值为1 bool setValueToMatrixForUndirectedGraph(int row, int col, int val = 1);
void printMatrix(); //打印邻接矩阵 void depthFirstTraverse(int nodeIndex); //深度优先遍历 void breadthFirstTraverse(int nodeIndex); //广度优先遍历
private: //从矩阵中获取权值(该函数不是公共使用的,而是内部使用的) bool getValueFromMatrix(int row, int col, int &val); //广度优先遍历实现函数 void breadthFirstTraverseImpl(vector<int> preVec);
private: int m_iCapacity; //图中最多可以容纳的顶点数 int m_iNodeCount; //已经添加的顶点(节点)个数 Node *m_pNodeArray; //用来存放顶点数组 int *m_pMatrix; //用来存放邻接矩阵 };
#endif |
CMap.cpp:
|
#include "CMap.h" #include <vector> #include <iostream> using namespace std;
CMap::CMap(int capacity) { m_iCapacity = capacity; m_iNodeCount = 0; m_pNodeArray = new Node[m_iCapacity]; //邻接矩阵--二维数组(实际上是用一维数组来表示二维数组) m_pMatrix = new int[m_iCapacity*m_iCapacity]; //memset()函数:进行内存的设定 //初始化邻接矩阵,将当前二维数组中的每一个元素都置为0 memset(m_pMatrix,0,m_iCapacity*m_iCapacity*sizeof(int));
////也可以采用for循环来初始化邻接矩阵 //for (int i = 0; i < m_iCapacity*m_iCapacity; i++) //{ // m_pMatrix[i] = 0; //} }
CMap::~CMap() { delete[]m_pNodeArray; m_pNodeArray = NULL; delete[]m_pMatrix; m_pMatrix = NULL; }
bool CMap::addNode(Node *pNode) { //判断传入进来的节点是否为空 if (NULL == pNode) { return false; } //顶点索引就是m_pNodeArray这个数组的下标 m_pNodeArray[m_iNodeCount].m_cData = pNode->m_cData; m_iNodeCount++; return true; }
//将图中所有节点的访问标识置为false void CMap::resetNode() { //将图中已经存放的所有顶点设为未被访问过 //不管之前是否被访问过 for (int i = 0; i < m_iNodeCount; i++) { m_pNodeArray[i].m_bIsVisited = false; } }
bool CMap::setValueToMatrixForDirectedGraph(int row, int col, int val) { if (row < 0 || row >= m_iCapacity) { return false; } if (col < 0 || col >= m_iCapacity) { return false; } //对于有向图的弧设定,只需设定行和列,并在相应位置设定权值即可 m_pMatrix[row*m_iCapacity + col] = val; return true; }
bool CMap::setValueToMatrixForUndirectedGraph(int row, int col, int val) { if (row < 0 || row >= m_iCapacity) { return false; } if (col < 0 || col >= m_iCapacity) { return false; } //对于无向图的边设定,不仅要设定行和列,在相应位置设定权值, //还要设定当前指定行和列的主对角线的对称位置的权值 m_pMatrix[row*m_iCapacity + col] = val; m_pMatrix[col*m_iCapacity + row] = val; return true; }
bool CMap::getValueFromMatrix(int row, int col, int &val) { if (row < 0 || row >= m_iCapacity) { return false; } if (col < 0 || col >= m_iCapacity) { return false; } //指定相应的行和列,查看邻接矩阵的相应位置的值 //如果为0,就说明当前的行和列所表示的顶点不相连, //如果不为0,就说明当前的行和列所表示的顶点相连, //至于它们相连的权值由邻接矩阵取得 val = m_pMatrix[row*m_iCapacity + col]; return true; }
void CMap::printMatrix() { for (int i = 0; i < m_iCapacity; i++) { for (int k = 0; k < m_iCapacity; k++) { cout << m_pMatrix[i*m_iCapacity + k] << " "; } cout << endl; }
}
//深度优先遍历: //图的深度优先遍历和二叉树的前序遍历非常相似 //首先是访问根,再访问左子树,最后访问右子树, //对于图来说,做深度优先遍历,要先访问根,然 //后访问第一棵子树,再访问第二棵子树,再访问 //第三棵子树...一直将所有子树访问结束之后,整 //个深度优先遍历就算结束了 // //深度优先遍历的特点: //将当前这个节点所连接的所有延展节点全部访问完毕之后, //才回到根,然后再从根往下延展第二棵子树,以此类推 void CMap::depthFirstTraverse(int nodeIndex) { //先访问当前传入进来的这个节点 cout << m_pNodeArray[nodeIndex].m_cData << " "; //将当前节点设置为已经访问过了 m_pNodeArray[nodeIndex].m_bIsVisited = true;
//定义一个value,将来从邻接矩阵中取值进行判断 int value = 0; //通过邻接矩阵判断当前这个顶点是否与其它顶点有连接 for (int i = 0; i < m_iCapacity; i++) { //因为是无向图,所以nodeIndex可以作为第一个 //参数,也可以作为第二个参数 getValueFromMatrix(nodeIndex,i,value); //如果取出的value值不为0,表明有其它顶点和当前顶点连接 if (value != 0) { //如果相连接的其它顶点已经被访问过,也pass掉 //进入到下一次循环中 if (m_pNodeArray[i].m_bIsVisited) { continue; } else { //如果没有被访问过,就进行递归 depthFirstTraverse(i); } } else { //如果等于0,即不存在其它顶点和当前顶点相连 continue; } }
}
//广度优先遍历:先给图进行分层,每一层都放到一个 //单独的数组中,然后一层一层的进行遍历 void CMap::breadthFirstTraverse(int nodeIndex) { //先访问当前传入进来的这个节点 cout << m_pNodeArray[nodeIndex].m_cData << " "; //将当前节点设置为已经访问过了 m_pNodeArray[nodeIndex].m_bIsVisited = true; //将当前节点保存到一个数组中,保存的不是 //节点本身,只保存索引即可 //这个数组使用标准模板库中的vector vector<int> curVec; curVec.push_back(nodeIndex); //调用实现函数来做进一步的遍历操作 breadthFirstTraverseImpl(curVec); }
void CMap::breadthFirstTraverseImpl(vector<int> preVec) { //定义一个value,将来从邻接矩阵中取值进行判断 int value = 0; //再定义一个数组来保存当前这一层的所有节点 vector<int> curVec;
//遍历上一层数组中保存的节点 //preVec.size()的返回值是size_type类型的,需强转为int for (int j = 0; j < (int)preVec.size(); j++) { //判断当前节点是否与其它节点是否有连接 for (int i = 0; i < m_iCapacity; i++) { getValueFromMatrix(preVec[j],i,value); //如果不等于0,则有连接 if (value != 0) { //如果相连接的点已经被访问过,就pass掉 if (m_pNodeArray[i].m_bIsVisited) { continue; } else { //如果没有被访问过,就先访问一下 cout << m_pNodeArray[i].m_cData << " "; //访问后,将其置为已访问过 m_pNodeArray[i].m_bIsVisited = true; //将这个节点的索引保存到curVec中 curVec.push_back(i); } } } }
//for循环全部完成,就意味着已经将preVec这一层顶点 //的下一层顶点全部都访问完了 // //判断本层是否存在刚被访问过的节点 //如果本层没有,那下边的层次就更不存在了 if (curVec.size() == 0) { return; } else { //如果本层还有节点,那下面的层次可能也 //还有节点,进行递归 breadthFirstTraverseImpl(curVec); } } |
main.cpp:
|
#include "CMap.h" #include "stdlib.h" #include <iostream> using namespace std;
/* 图的存储:使用邻接矩阵实现 A / \ B D / \ / \ C F G - H \ / E */
/* 共 8 个节点:分别是 A B C D E F G H 其中:A 和 B D 都相连,B 和 C F 都相连, C F 和 E 都相连,D G H 这三个节点都相连。
显然,它是一个无向图,且每条边没有加权值, 所以认为边的权值都为 1
无向图的邻接矩阵的主对角线是对称线,即上 半部分和下半部分是完全对称的 */
/* 图的遍历:
如果是从A点开始搜索: 深度优先搜索,顺序:A B C E F D G H 广度优先搜索,顺序:A B D C F G H E
无论是深度优先搜索,还是广度优先搜索,它搜索的层次 都是不确定的,可以通过递归的方式来解决这样的问题 */ int main(void) { CMap *pMap = new CMap(8);
Node nodeA('A'); Node nodeB('B'); Node nodeC('C'); Node nodeD('D'); Node nodeE('E'); Node nodeF('F'); Node nodeG('G'); Node nodeH('H');
//按照添加的顺序自动设定索引值 pMap->addNode(&nodeA);//0 pMap->addNode(&nodeB);//1 pMap->addNode(&nodeC);//2 pMap->addNode(&nodeD);//3 pMap->addNode(&nodeE);//4 pMap->addNode(&nodeF);//5 pMap->addNode(&nodeG);//6 pMap->addNode(&nodeH);//7
//只需设定无向图的主对角线的上半部分即可,且默认权值都为1 //这里共设定9条边,设定的顺序不限 pMap->setValueToMatrixForUndirectedGraph(0, 1); pMap->setValueToMatrixForUndirectedGraph(0, 3); pMap->setValueToMatrixForUndirectedGraph(1, 2); pMap->setValueToMatrixForUndirectedGraph(1, 5); pMap->setValueToMatrixForUndirectedGraph(3, 6); pMap->setValueToMatrixForUndirectedGraph(3, 7); pMap->setValueToMatrixForUndirectedGraph(6, 7); pMap->setValueToMatrixForUndirectedGraph(2, 4); pMap->setValueToMatrixForUndirectedGraph(4, 5);
pMap->printMatrix(); cout << endl;
pMap->depthFirstTraverse(0); cout << endl;
//在进行广度优先遍历之前,需要先重置一下, //因为之前深度优先遍历后,所有节点都已经 //标识为被访问过 pMap->resetNode(); pMap->breadthFirstTraverse(0); cout << endl;
delete pMap; pMap = NULL;
system("pause"); return 0; } |
运行一览:

程序 2:
1)使用邻接矩阵存储无向图
2)使用普里姆(Prime)算法和克鲁斯卡尔(Kruskal)算法求最小生成树
Node.h:
|
#ifndef NODE_H #define NODE_H
class Node { public: //默认有参构造函数 Node(char data = 0);
char m_cData;
//标识当前节点有没有被访问过 //被访问过就置为true bool m_bIsVisited; };
#endif |
Node.cpp:
|
#include "Node.h"
Node::Node(char data) { m_cData = data; m_bIsVisited = false; } |
Edge.h:
|
#ifndef EDGE_H #define EDGE_H
//不论是普里姆算法,还是克鲁斯卡尔算法, //它们所涉及的边的数据成员和成员函数大抵相似 class Edge { public: //默认有参构造函数 Edge(int nodeIndexA = 0, int nodeIndexB = 0, int weightValue = 0);
//连接这条边的两个顶点,并不需要强调它的起始和终结, //因为这里做的是无向图,并不是弧,而是一条边 //所以就平等的写成 A 和 B 这两个点 int m_iNodeIndexA; int m_iNodeIndexB;
//这条边的权值 int m_iWeightValue;
//标记这条边是否从待选边集合中被选择出来了 bool m_bSelected; };
#endif |
Edge.cpp:
|
#include "Edge.h"
Edge::Edge(int nodeIndexA, int nodeIndexB, int weightValue) { m_iNodeIndexA = nodeIndexA; m_iNodeIndexB = nodeIndexB; m_iWeightValue = weightValue; m_bSelected = false; } |
CMap.h:
|
#ifndef CMAP_H #define CMAP_H #include "Node.h" #include "Edge.h" #include <vector> using namespace std;
//之所以在Map前加个C,是因为Map本身是标准模板库的类名, //为了能够区分,就在前面加了一个C,叫做CMap class CMap { public: CMap(int capacity); ~CMap(); bool addNode(Node *pNode); //向图中加入顶点(节点) void resetNode(); //重置顶点:将每一个顶点设为未访问过
//为有向图设置邻接矩阵,默认权值为1 bool setValueToMatrixForDirectedGraph(int row, int col, int val = 1); //为无向图设置邻接矩阵,默认权值为1 bool setValueToMatrixForUndirectedGraph(int row, int col, int val = 1);
void printMatrix(); //打印邻接矩阵 void depthFirstTraverse(int nodeIndex); //深度优先遍历 void breadthFirstTraverse(int nodeIndex); //广度优先遍历 void primTree(int nodeIndex); //普里姆算法生成树 void kruskalTree(int nodeIndex); //克鲁斯卡尔算法生成树
private: //从矩阵中获取权值(该函数不是公共使用的,而是内部使用的) bool getValueFromMatrix(int row, int col, int &val); //广度优先遍历实现函数 void breadthFirstTraverseImpl(vector<int> preVec);
//获取最小边 int getMinEdge(vector<Edge> edgeVec); //判断顶点是否在点集合上 bool isInSet(vector<int> nodeSet, int target); //合并两个顶点集合 void mergeNodeSet(vector<int> &nodeSetA, vector<int> nodeSetB);
private: int m_iCapacity; //图中最多可以容纳的顶点数 int m_iNodeCount; //已经添加的顶点(节点)个数 Node *m_pNodeArray; //用来存放顶点数组 int *m_pMatrix; //用来存放邻接矩阵 Edge *m_pEdge; //用来存放最小生成树中的边 };
#endif |
CMap.cpp:
|
#include "CMap.h" #include <vector> #include <iostream> using namespace std;
CMap::CMap(int capacity) { m_iCapacity = capacity; m_iNodeCount = 0; m_pNodeArray = new Node[m_iCapacity]; //邻接矩阵--二维数组(实际上是用一维数组来表示二维数组) m_pMatrix = new int[m_iCapacity*m_iCapacity]; //memset()函数:进行内存的设定 //初始化邻接矩阵,将当前二维数组中的每一个元素都置为0 memset(m_pMatrix, 0, m_iCapacity*m_iCapacity*sizeof(int));
////也可以采用for循环来初始化邻接矩阵 //for (int i = 0; i < m_iCapacity*m_iCapacity; i++) //{ // m_pMatrix[i] = 0; //}
//最小生成树中的边的个数是顶点个数减1 m_pEdge = new Edge[m_iCapacity - 1]; }
CMap::~CMap() { delete[]m_pNodeArray; m_pNodeArray = NULL; delete[]m_pMatrix; m_pMatrix = NULL; delete []m_pEdge; m_pEdge = NULL; }
bool CMap::addNode(Node *pNode) { //判断传入进来的节点是否为空 if (NULL == pNode) { return false; } //顶点索引就是m_pNodeArray这个数组的下标 m_pNodeArray[m_iNodeCount].m_cData = pNode->m_cData; m_iNodeCount++; return true; }
//将图中所有节点的访问标识置为false void CMap::resetNode() { //将图中已经存放的所有顶点设为未被访问过 //不管之前是否被访问过 for (int i = 0; i < m_iNodeCount; i++) { m_pNodeArray[i].m_bIsVisited = false; } }
bool CMap::setValueToMatrixForDirectedGraph(int row, int col, int val) { if (row < 0 || row >= m_iCapacity) { return false; } if (col < 0 || col >= m_iCapacity) { return false; } //对于有向图的弧设定,只需设定行和列,并在相应位置设定权值即可 m_pMatrix[row*m_iCapacity + col] = val; return true; }
bool CMap::setValueToMatrixForUndirectedGraph(int row, int col, int val) { if (row < 0 || row >= m_iCapacity) { return false; } if (col < 0 || col >= m_iCapacity) { return false; } //对于无向图的边设定,不仅要设定行和列,在相应位置设定权值, //还要设定当前指定行和列的主对角线的对称位置的权值 m_pMatrix[row*m_iCapacity + col] = val; m_pMatrix[col*m_iCapacity + row] = val; return true; }
bool CMap::getValueFromMatrix(int row, int col, int &val) { if (row < 0 || row >= m_iCapacity) { return false; } if (col < 0 || col >= m_iCapacity) { return false; } //指定相应的行和列,查看邻接矩阵的相应位置的值 //如果为0,就说明当前的行和列所表示的顶点不相连, //如果不为0,就说明当前的行和列所表示的顶点相连, //至于它们相连的权值由邻接矩阵取得 val = m_pMatrix[row*m_iCapacity + col]; return true; }
void CMap::printMatrix() { for (int i = 0; i < m_iCapacity; i++) { for (int k = 0; k < m_iCapacity; k++) { cout << m_pMatrix[i*m_iCapacity + k] << " "; } cout << endl; }
}
//深度优先遍历: //图的深度优先遍历和二叉树的前序遍历非常相似 //首先是访问根,再访问左子树,最后访问右子树, //对于图来说,做深度优先遍历,要先访问根,然 //后访问第一棵子树,再访问第二棵子树,再访问 //第三棵子树...一直将所有子树访问结束之后,整 //个深度优先遍历就算结束了 // //深度优先遍历的特点: //将当前这个节点所连接的所有延展节点全部访问完毕之后, //才回到根,然后再从根往下延展第二棵子树,以此类推 void CMap::depthFirstTraverse(int nodeIndex) { //先访问当前传入进来的这个节点 cout << m_pNodeArray[nodeIndex].m_cData << " "; //将当前节点设置为已经访问过了 m_pNodeArray[nodeIndex].m_bIsVisited = true;
//定义一个value,将来从邻接矩阵中取值进行判断 int value = 0; //通过邻接矩阵判断当前这个顶点是否与其它顶点有连接 for (int i = 0; i < m_iCapacity; i++) { //因为是无向图,所以nodeIndex可以作为第一个 //参数,也可以作为第二个参数 getValueFromMatrix(nodeIndex, i, value); //如果取出的value值不为0,表明有其它顶点和当前顶点连接 if (value !=0) { //如果相连接的其它顶点已经被访问过,也pass掉 //进入到下一次循环中 if (m_pNodeArray[i].m_bIsVisited) { continue; } else { //如果没有被访问过,就进行递归 depthFirstTraverse(i); } } else { //如果等于0,即不存在其它顶点和当前顶点相连 continue; } }
}
//广度优先遍历:先给图进行分层,每一层都放到一个 //单独的数组中,然后一层一层的进行遍历 void CMap::breadthFirstTraverse(int nodeIndex) { //先访问当前传入进来的这个节点 cout << m_pNodeArray[nodeIndex].m_cData << " "; //将当前节点设置为已经访问过了 m_pNodeArray[nodeIndex].m_bIsVisited = true; //将当前节点保存到一个数组中,保存的不是 //节点本身,只保存索引即可 //这个数组使用标准模板库中的vector vector<int> curVec; curVec.push_back(nodeIndex); //调用实现函数来做进一步的遍历操作 breadthFirstTraverseImpl(curVec); }
void CMap::breadthFirstTraverseImpl(vector<int> preVec) { //定义一个value,将来从邻接矩阵中取值进行判断 int value = 0; //再定义一个数组来保存当前这一层的所有节点 vector<int> curVec;
//遍历上一层数组中保存的节点 //preVec.size()的返回值是size_type类型的,需强转为int //(其实转不转换类型都无所谓) for (int j = 0; j < (int)preVec.size(); j++) { //判断当前节点是否与其它节点是否有连接 for (int i = 0; i < m_iCapacity; i++) { getValueFromMatrix(preVec[j], i, value); //如果不等于0,则有连接 if (value != 0) { //如果相连接的点已经被访问过,就pass掉 if (m_pNodeArray[i].m_bIsVisited) { continue; } else { //如果没有被访问过,就先访问一下 cout << m_pNodeArray[i].m_cData << " "; //访问后,将其置为已访问过 m_pNodeArray[i].m_bIsVisited = true; //将这个节点的索引保存到curVec中 curVec.push_back(i); } } } }
//for循环全部完成,就意味着已经将preVec这一层顶点 //的下一层顶点全部都访问完了 // //判断本层是否存在刚被访问过的节点 //如果本层没有,那下边的层次就更不存在了 if (curVec.size() == 0) { return; } else { //如果本层还有节点,那下面的层次可能也 //还有节点,进行递归 breadthFirstTraverseImpl(curVec); } }
//普里姆算法是以点作为算法的核心 void CMap::primTree(int nodeIndex) { //取边,把边的权值保存到value中 int value = 0; //边的计数器 int edgeCount = 0; //数组nodeVec用来存放节点(点集合) //这里实际存放的是点的索引 vector<int> nodeVec; //数组edgeVec用来存放待选边(待选边集合) vector<Edge> edgeVec;
cout << m_pNodeArray[nodeIndex].m_cData << endl; nodeVec.push_back(nodeIndex); m_pNodeArray[nodeIndex].m_bIsVisited = true;
//算法的终结条件: //对于普里姆算法来说,最终拿到的边数如果已经 //等于当前点数减1,那么就到达了可以停止的条件 while (edgeCount < m_iCapacity - 1) { //先从nodeVec取出nodeIndex对应的点,拿着 //这个点把边找出来 // //nodeVec.back() 即从nodeVec中取出最尾部 //的那个元素,也就是nodeIndex int temp = nodeVec.back();
//for循环将所有与temp相连接的边都放入待选边集合中 for (int i = 0; i < m_iCapacity; i++) { getValueFromMatrix(temp, i, value); //如果权值不为0,则表明当前节点和其它节点有连接 if (value != 0) { //如果被访问过,就pass掉 if (m_pNodeArray[i].m_bIsVisited) { continue; } else { //如果没有被访问过,则这条边应该放入到待选边集合中 Edge edge(temp, i, value); edgeVec.push_back(edge); } } }
//从待选边集合中找到权值最小的边,同时把这条边 //的另一个顶点放入点集合中 int edgeIndex = getMinEdge(edgeVec); //将这条边标记为被选出 edgeVec[edgeIndex].m_bSelected = true;
cout << edgeVec[edgeIndex].m_iNodeIndexA << "->" << edgeVec[edgeIndex].m_iNodeIndexB << " #"; cout << edgeVec[edgeIndex].m_iWeightValue << endl;
//将这条边的索引存储到边集合中 m_pEdge[edgeCount] = edgeVec[edgeIndex]; edgeCount++;
//找到权值最小边的另一个顶点,作为下次循环时 //找与这顶点相连的边时使用 int nextNodeIndex = edgeVec[edgeIndex].m_iNodeIndexB; //并将这个点放入到点集合中 nodeVec.push_back(nextNodeIndex); //将这个点设为已被访问过 m_pNodeArray[nextNodeIndex].m_bIsVisited = true;
cout << m_pNodeArray[nextNodeIndex].m_cData << endl;
} }
int CMap::getMinEdge(vector<Edge> edgeVec) { //最小权值 int minWeight = 0; //边的索引 int edgeIndex = 0; int i = 0; //找出第一条没有被选中的边 for (; i < (int)edgeVec.size(); i++) { //如果这条边没有被选出来过 if (!edgeVec[i].m_bSelected) { //将权值赋值给minWeight minWeight = edgeVec[i].m_iWeightValue; edgeIndex = i; break; } }
if (minWeight == 0) { return -1; }
//拿着第一条没有被选中的边的权值去和 //其它没有被选中的边的权值进行比较 //找出最小权值的边 for (; i < (int)edgeVec.size(); i++) { //如果这条边被选出来过 if (edgeVec[i].m_bSelected) { continue; } else { if (minWeight>edgeVec[i].m_iWeightValue) { minWeight = edgeVec[i].m_iWeightValue; edgeIndex = i; } } }
return edgeIndex; }
//克鲁斯卡尔算法是以边作为算法的核心,它最终是要找出 //一个边的集合,让这个边的集合能够形成一棵最小生成树 // //需要分成两步来走: //第一步:找出所有的边, //第二步:从这些边中找出组成最小生成树的边集合 //(1)找到算法的结束条件 //(2)从边集合中找到最小边 //(3)找出最小边连接的点 //(4)找出点所在的点集合 //(5)根据点所在集合的不同做出不同处理 void CMap::kruskalTree(int nodeIndex) { //用来取边的权值的value int value = 0; //取出来的最小生成树的边的个数 int edgeCount = 0; //定义存放已涉及点的数组,也就是数组的数组 //这样定义的原因是:克鲁斯卡尔算法的点集合 //有可能不止一个,就拿本例来说,将来:A F B //C 会在一个集合,而 D E 在另一个集合,然后 //再把这两个集合合并成一个集合 vector<vector<int>> nodeSets; //存放待选边的数组 vector<Edge> edgeVec; //通过for循环将邻接矩阵中所有的关于边的表达 //都把它变成一个Edge对象,放入到edgeVec数组中 for (int i = 0; i < m_iCapacity; i++) { //从邻接矩阵的上半部分取边(不含主对角线) for (int k = i + 1; k < m_iCapacity; k++) { getValueFromMatrix(i, k, value); if (value != 0) { Edge edge(i,k,value); edgeVec.push_back(edge); } } }
while (edgeCount < m_iCapacity - 1) { int minEdgeIndex = getMinEdge(edgeVec); edgeVec[minEdgeIndex].m_bSelected = true;
int nodeAIndex = edgeVec[minEdgeIndex].m_iNodeIndexA; int nodeBIndex = edgeVec[minEdgeIndex].m_iNodeIndexB;
bool nodeAIsInSet = false; bool nodeBIsInSet = false;
//保存nodeA和nodeB所在集合的索引 int nodeAInSetLabel = -1; int nodeBInSetLabel = -1;
//分别判断nodeAIndex和nodeBIndex分别在哪个点集合中 for (int i = 0; i < (int)nodeSets.size(); i++) { nodeAIsInSet = isInSet(nodeSets[i],nodeAIndex); //如果nodeAIndex在nodeSets[i]中 //注意:不可能有点同时存在于两个集合中 if (nodeAIsInSet) { nodeAInSetLabel = i; }
nodeBIsInSet = isInSet(nodeSets[i], nodeBIndex); if (nodeBIsInSet) { nodeBInSetLabel = i; } }
//判断nodeAInSetLabel 和 nodeBInSetLabel的关系: // //(1)如果都为-1,即 A 和 B 都不在已有集合中, //需要放到一个全新的集合中 if (nodeAInSetLabel == -1 && nodeBInSetLabel == -1) { vector<int> vec; //显然,这是第一条最小权值的边,两个点都在同一集合中 vec.push_back(nodeAIndex); vec.push_back(nodeBIndex); //再将集合放入到集合的集合中 nodeSets.push_back(vec); } //(2)A为-1,B不为-1,即 A 没有在任何集合中,而 B 此时 //是归属于某一集合的,需要把 A 放到 B 所在的集合中 else if (nodeAInSetLabel == -1 && nodeBInSetLabel != -1) { nodeSets[nodeBInSetLabel].push_back(nodeAInSetLabel); } //(3)A不为-1,B为-1,同(2) else if (nodeAInSetLabel != -1 && nodeBInSetLabel == -1) { nodeSets[nodeAInSetLabel].push_back(nodeBInSetLabel); } //(4)A 和 B 分属于不同的集合,这说明要找的这条边是连接 //到了两个集合中的不同点,就要合并两个集合 else if (nodeAInSetLabel != -1 && nodeBInSetLabel != -1 && nodeAInSetLabel != nodeBInSetLabel) { //B所在集合合并到前面的A所在集合 mergeNodeSet(nodeSets[nodeAInSetLabel], nodeSets[nodeBInSetLabel]); //合并之后,将 B 所在集合从nodeSets去掉 for (int k = nodeBInSetLabel; k < (int)nodeSets.size()-1; k++) { nodeSets[k] = nodeSets[k + 1]; } } //(5)A 和 B 在同一集合中,这就使得已经选出来的边形成了 //回路,这条边就要放弃掉,直接continue else if (nodeAInSetLabel != -1 && nodeBInSetLabel != -1 && nodeAInSetLabel == nodeBInSetLabel) { continue; }
m_pEdge[edgeCount] = edgeVec[minEdgeIndex]; edgeCount++;
cout << edgeVec[minEdgeIndex].m_iNodeIndexA << "->" << edgeVec[minEdgeIndex].m_iNodeIndexB << " #"; cout << edgeVec[minEdgeIndex].m_iWeightValue << endl; } }
bool CMap::isInSet(vector<int> nodeSet, int target) { for (int i = 0; i < (int)nodeSet.size(); i++) { if (nodeSet[i] == target) { return true; } }
return false; }
//将nodeSetB合并到nodeSetA,使A这个集合壮大起来,之所以将nodeSetA加引用, //就是为了将来传进来的nodeSetA集合,未来还能把结果拿出去 void CMap::mergeNodeSet(vector<int> &nodeSetA, vector<int> nodeSetB) { //将nodeSetB中的每一个点取出来放到A点集合的后边即可 for (int i = 0; i < (int)nodeSetB.size(); i++) { nodeSetA.push_back(nodeSetB[i]); } } |
main.cpp:
|
#include "CMap.h" #include "stdlib.h" #include <iostream> using namespace std;
/* A / | \ B---F---E \ / \ / C---D
这张图中共6个顶点,并有编号: A B C D E F 0 1 2 3 4 5
而且边和边之间有一定的权值,共10条边: A-B 6 A-E 5 A-F 1 B-C 3 B-F 2 C-F 8 C-D 7 D-F 4 D-E 2 E-F 9 */ int main(void) { CMap *pMap = new CMap(6);
Node nodeA('A'); Node nodeB('B'); Node nodeC('C'); Node nodeD('D'); Node nodeE('E'); Node nodeF('F');
//按照添加的顺序自动设定索引值 pMap->addNode(&nodeA);//0 pMap->addNode(&nodeB);//1 pMap->addNode(&nodeC);//2 pMap->addNode(&nodeD);//3 pMap->addNode(&nodeE);//4 pMap->addNode(&nodeF);//5
//只需设定无向图的主对角线的上半部分即可, //这里共设定10条边,设定的顺序不限 pMap->setValueToMatrixForUndirectedGraph(0, 1, 6);//A-B pMap->setValueToMatrixForUndirectedGraph(0, 4, 5);//A-E pMap->setValueToMatrixForUndirectedGraph(0, 5, 1);//A-F* pMap->setValueToMatrixForUndirectedGraph(1, 2, 3);//B-C* pMap->setValueToMatrixForUndirectedGraph(1, 5, 2);//B-F* pMap->setValueToMatrixForUndirectedGraph(2, 5, 8);//C-F pMap->setValueToMatrixForUndirectedGraph(2, 3, 7);//C-D pMap->setValueToMatrixForUndirectedGraph(3, 5, 4);//D-F* pMap->setValueToMatrixForUndirectedGraph(3, 4, 2);//D-E* pMap->setValueToMatrixForUndirectedGraph(4, 5, 9);//E-F
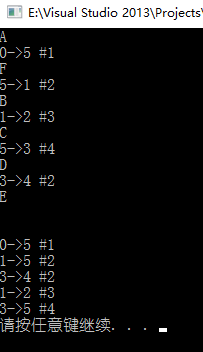
pMap->primTree(0); cout << endl << endl;
pMap->resetNode(); pMap->kruskalTree(0);
delete pMap; pMap = NULL;
system("pause"); return 0; } |
运行一览:
【made by siwuxie095】
posted on 2017-05-13 22:32 siwuxie095 阅读(198) 评论(0) 编辑 收藏 举报

