
linux三剑客
- grep 文本过滤工具(过滤,查找文本内容)
- sed stream editor 流编辑器 文本编辑工具(取行,修改文件内容)
- awk 文本分析工具 格式化文本输出(取列,统计计算)
1. linux正则表达式
regual expression regexp
此处使用 grep 命令来学习正则表达式(grep命令可过滤匹配模式的内容)
grep命令基本语法:grep pattern filenamepattern 是匹配的模式
linux通配符和正则表达式
- 通配符是对文件进行匹配的;由shell解析,如
ls、cp、mv、find等命令 - 正则表达式是对文件内容进行匹配的;正则表达式一般结合
grep、sed、awk使用
常见通配符
| 符号 | 描述 |
|---|---|
| * | 匹配任意长度的任意字符 |
| ? | 匹配任意单个字符 |
| [] | 匹配指定范围内任意单个字符 |
| [^] | 匹配指定范围外任意单个字符 |
| [[:upper:]] | 所有大写字母,等价于[A-Z] |
| [[:lower:]] | 所有小写字母,等价于[a-z] |
| [[:alpha:]] | 所有字母,等价于[a-zA-Z] |
| [[:digit:]] | 所有数字,等价于[0-9] |
| [[:alnum:]] | 所有数字和字母,等价于[0-9a-zA-Z] |
| [[:space:]] | 所有空白字符 |
| [[:punct:]] | 所有标点符号 |
[0-9]表示任意一个数字
[a-z]表示任意一个小写字母
[A-Z]表示任意一个大写字母
[0-9a-zA-Z] 表示任意一个数字或字母
文件test.txt内容如下
[root@localhost ~]# cat test.txt
You and me.
xxx is a hanhan. ^_^
longzhaoqianwowudunjiu.
He can speak english.
Are you kidding?
I think ...
youoy abba ccccc ddd
My phone number is 1872272****.
vvv
通配符示例:
# 查找当前目录下以数字命名的文件
[root@localhost ~]# find . -name [0-9]
[root@localhost ~]# find . -name [[:digit:]]
# 查找test.txt中包含数字的内容
[root@localhost ~]# grep '[[:digit:]]' test.txt
# 查找test.txt中标点符号以外的内容
[root@localhost ~]# grep '[^[:punct:]]' test.txt
基础元字符
| 元字符 | 含义 |
|---|---|
| ^ | ^a 以a开头的内容 |
| $ | a$ 以a结尾的内容 |
| ^$ | 空行(在linux的文本中,每一行的末尾会有默认的$符号 使用cat -E file可以看到) |
| . | 任意一个字符 (非空行) |
| \ | 转义字符,让有特殊含义的字符脱掉马甲 |
| * | 之前的字符连续0次或多次 |
| .* | 任意多个字符(匹配全部内容) |
| ^.* | 以任意多个字符串开头,具有贪婪性 |
| [ab] | 包含中括号中的任意一个字符(a或b) |
| [^ab] | 不包含^后的任意字符(a或b),对[ab]的取反 |
| \< | 词首 |
| \> | 词尾 |
| \ | 重复前面字符n次 |
| \ | 重复前面字符最少n次 |
| \ | 重复前面字符最多m次 |
| \ | 重复前面字符n次到m次(最少n次,最多m次) |
基本正则表达式示例:
# 查找所有以'Y'开头的行
[root@localhost ~]# grep '^Y' test.txt
# 查找以'g'结尾的行
[root@localhost ~]# grep 'g$' test.txt
# 查找所有空行
[root@localhost ~]# grep '^$' test.txt
# 查找非空行
[root@localhost ~]# grep '.' test.txt
# 查找以'.'结尾的行
[root@localhost ~]# grep '\.$' test.txt
# 查找连续出现0个或多个d的内容
[root@localhost ~]# grep 'd*' test.txt
# 查找全部内容
[root@localhost ~]# grep '.*' test.txt
# 以任意字符串开头并且包含d的内容 (贪婪匹配,会匹配到每行文本的最后一个d)
[root@localhost ~]# grep '^.*d' test.txt
# 匹配l或x
[root@localhost ~]# grep '[lx]' test.txt
# 不匹配l和x
[root@localhost ~]# grep '[^lx]' test.txt
# 匹配l或x开头
[root@localhost ~]# grep '^[lx]' test.txt
# 匹配单词speak
[root@localhost ~]# grep '\<speak\>' test.txt
# 匹配空格开头的内容
[root@localhost ~]# grep '^[[:space:]]' test.txt
[root@localhost ~]# grep '^[ ]' test.txt
扩展元字符
| 元字符 | 含义 |
|---|---|
| + | 重复前一个字符1次或多次(至少1次),取出连续的字符或文本 |
| ? | 重复前一个字符0次或1次(最多1次) |
| | | 表示或者同时过滤多个字符 |
| () | 分组,将()里的内容当成一个整体,\n(n是一个数字) 表示引用第几个括号里的内容 |
扩展正则表达式示例:
在基本表达式中,扩展正则表达式需要在前面使用 \ 进行转义
使用
egrep或grep -E来使用扩展正则表达式不需要使用\转义
# 包含连续一个或多个d
[root@localhost ~]# grep 'd\+' test.txt
[root@localhost ~]# egrep 'd+' test.txt
[root@localhost ~]# grep -E 'd+' test.txt
# 包含0次或1次d
[root@localhost ~]# grep -E 'd?' test.txt
# 匹配a或b
[root@localhost ~]# grep -E 'a|b' test.txt
# 匹配 'and' 或 'abb'
[root@localhost ~]# grep -E 'a(nd|bb)' test.txt
# 匹配两个相同的字母
[root@localhost ~]# grep -E '([a-z])\1' test.txt
# 重复d字符最少1次,最多2次
[root@localhost ~]# grep -E 'd{1,2}' test.txt
扩展:perl支持的其他常用元字符
| 元字符 | 解释 |
|---|---|
| \d | 数字 |
| \D | 非数字 |
| \w | 数字,字母,下划线 |
| \W | 非 数字、字母、下划线 |
| \s | 空字符 |
| \S | 非空字符 |
大多数编程语言都支持以上元字符,linux不支持,使用 grep -P 可以支持 perl 正则表达式
(不过我试了一下,有部分还是支持的 ^_^)
示例:
# 匹配所有的单词
[root@localhost ~] # grep -P '\w+' test.txt
# 匹配所有的非数字
[root@localhost ~] # grep -P '\D' test.txt
2. grep 文本过滤工具
-
grep(global search regular expression(RE)and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。用于过滤搜索的特定字符。可使用正则表达式,能多种命令配合使用,使用上十分灵活。 -
语法:
grep [OPTION...] PATTERNS [FILE...]
grep [OPTION...] -e PATTERNS ... [FILE...]
grep [OPTION...] -f PATTERN_FILE ... [FILE...]
grep 命令选项
| 选项 | 作用 |
|---|---|
| -c | 统计文件中匹配的行数 |
| -i | 忽略模式中的字母大小写 |
| -n | 列出所有的匹配行,并显示行号 |
| -v | 列出没有匹配模式的行,取反 |
| -e | 多个选项间的逻辑或 |
| -o | 只显示被模式匹配到内容 |
| -l | 列出带有匹配内容的文件名 |
| -w | 匹配整个单词 |
| -q | 静默模式,不输出任何信息 |
| -r | 递归搜索 |
| -f | 根据文件内容匹配多个(文件中逐行写出要匹配的内容) |
| -A | after,后n行(被匹配到的行及后n行) |
| -B | before,前n行(被匹配到的行及前n行) |
| -C | context,前后各n行(被匹配到的行及前后各n行) |
| -E | 使用扩展的正则表达式,相当于 egrep |
| -F | 相当于fgrep,不支持正则表达式 |
| -P | 使用 perl 正则表达式 |
使用帮助命令可查看全部选项(grep --help 或 man grep)
grep使用“标准正则表达式”作为匹配标准
egrep扩展的grep命令,相当于grep -E,使用扩展正则表达式作为匹配标准
fgrep简化版的grep命令,不支持正则表达式,但搜索速度快,系统资源使用率低
grep命令示例
# 统计空行的行数
[root@localhost ~]# grep -c '^$' test.txt
# 包含字符h的行(不区分大小写)
[root@localhost ~]# grep -i 'h' test.txt
# 列出所有空行 并显示行号
[root@localhost ~]# grep -n '^$' test.txt
# 列出所有非空行
[root@localhost ~]# grep -v '^$' test.txt
# 列出所有以S开头的行和空行
[root@localhost ~]# grep -e '^$' -e '^S' test.txt
# 过滤所有的数字 只显示被匹配到的内容
[root@localhost ~]# grep -o '[0-9]' test.txt
# 列出内容包含a的文件名
[root@localhost ~]# grep -l 'a' demo.txt test.txt pwd.txt
# 匹配包含单词you的行
[root@localhost ~]# grep -w 'you' test.txt
# 根据file里面的范文进行匹配
[root@localhost ~]# grep -f file test.txt
# 列出包含can的行以及其后三行
[root@localhost ~]# grep -A3 'can' test.txt
# 列出包含can的行以及其前三行
[root@localhost ~]# grep -B3 'can' test.txt
# 列出包含can的行以及其前后各三行
[root@localhost ~]# grep -C3 'can' test.txt
# 重复d字符最少2次
[root@localhost ~]# grep -E 'd{2,}' test.txt
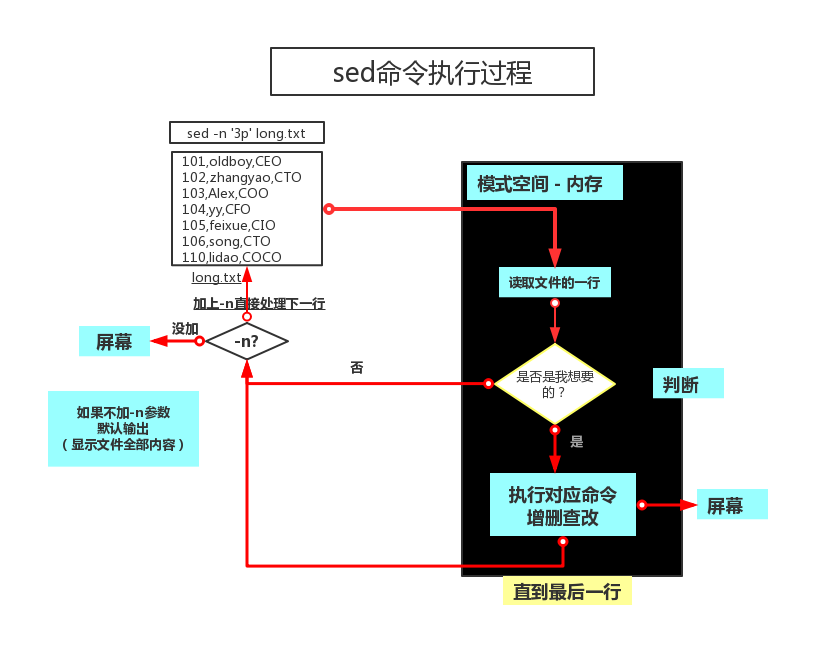
3. sed 流编辑器
-
Sed是一种流编辑器,它是文本处理中非常重要的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末
尾。文件内容并没有改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。 -
语法:
sed [OPTION]... {script-only-if-no-other-script} [input-file]...
sed命令选项
| 选项 | 作用 |
|---|---|
| -n | 取消默认 sed 输出,只输出处理后的结果,通常与 p 动作一起使用 |
| -r | 支持使用扩展正则表达式 |
| -i | 直接编辑文件,不使用 -i ,修改的只是缓冲区的内容 |
| -e | 多次编辑,和管道符作用一样 |
| -f | 运行sed脚本中的编辑命令 |
sed编辑命令
| 动作 | 描述 |
|---|---|
| a\ | 新增,在当前行下面插入文本 (用 \ 或者空格都可以) |
| i\ | 插入,在当前行上面插入文本 |
| c\ | 修改,把选定行修改为新的文本 |
| d | 删除,删除选定行 |
| p | 打印,打印匹配的内容,通常与 -n 选项一起使用 |
| s | 替换,匹配内容并进行替换,支持正则 |
| n | 读取下一个输入行,然后执行下一个命令 |
| w | 保存模式匹配的行至指定文件 |
| r | 读取指定文件的文本至模式空间中匹配到的行后 |
| = | 为模式空间中的行打印行号 |
| ! | 模式空间中匹配行取反处理 |
sed替换标记
| 符号 | 描述 |
|---|---|
| g | 行内全部替换,不写默认替换每行第一个,ng 表示替换第 n 次开始匹配到的内容 |
| \n | 子字符串匹配标记;\n表示第几个分组里的内容 |
| & | 已匹配字符串标记 |
s 替换命令说明:
定界符
- 替换命令中,常用
/作为定界符,也可以使用自定义的定界符,如:、#、@等- 定界符出现在内部时,需要进行转义,如
sed 's:[0-9]:\::' test.txt使用:作为定界符,将所有数字替换成:组合多个表达式
- sed 替换命令可以结合其他命令一起使用,例如将第一行所有小写字母替换成
#并进行打印:sed '1s/[a-z]/#/gp' test.txt- 其他命令也可以组合多个表达式使用,可以有以下三种写法(在同一行里执行多个命令,受先后顺序影响)
sed '表达式1' | sed '表达式2'sed '表达式1; 表达式2'sed -e '表达式1' -e '表达式2'子字符串匹配(反向引用)
- 作用是匹配给定模式中的一部分,配合
()分组使用,\n就表示匹配第几个分组的结果已匹配字符串
- 使用
&来表示匹配到的每一个内容,也可以使用子字符串匹配来实现
sed匹配范围
| 范围 | 解释 |
|---|---|
| 全文 | 全文处理 |
| 指定行 | 指定文件的某一行 ;'1p' 表示打印第一行 |
| 指定模式 | /pattern/ 被模式匹配到的每一行; '/^H/' 表示H开头的行 |
| 指定范围区间 | 范围内的每一行;'1,3' 表示第1行到第3行;'1,+2' 表示第1行和后两行;'$'表示最后一行 |
| 指定步长 | 根据步长匹配行;'1~2' 表示 1,3,5,7,... 奇数行; '2~2' 表示2,4,6,8...偶数行 |
行范围和模式范围可以组合成范围区间使用
sed命令示例
# 打印第5行
[root@localhost ~]# sed -n '5p' test.txt
# 在每一行下面添加文本"day day up"(不修改原文件)
[root@localhost ~]# sed 'a day day up' test.txt
# 在第1行上面添加两行 "abcde" 和 "ABCDE"
[root@localhost ~]# sed -i '1i abcde\nABCDE' test.txt
# 把最后一行更改为"66666"
[root@localhost ~]# sed -i '$c 66666' test.txt
# 把所有的字符'A'修改为'a'
[root@localhost ~]# sed -i 's/A/a/g' test.txt
# 删除前2行
[root@localhost ~]# sed -i '1,2d' test.txt
# 将'H'开头的行写入文件 file.txt
[root@localhost ~]# sed -n '/^H/w file.txt' test.txt
# 将file.txt文件里的内容写入第5行下面
[root@localhost ~]# sed -i '5r file.txt' test.txt
# 删除'l'开头的下一行
[root@localhost ~]# sed -i '/^l/{n;d;}' test.txt
# 打印2-5行之外的行
[root@localhost ~]# sed -n '2,5!p' test.txt
# 将所有出现一次以上的字母'b'修改成数字'8'打印出来
[root@localhost ~]# sed -nr 's/b+/8/gp' test.txt
# 在第6行的内容删除 然后修改所有'*'为'#'
[root@localhost ~]# sed -i -e '5d' -e 's/*/#/g' test.txt
# 新建文件file.sed里面书写sed脚本 将test.txt文件中第一行到'?'结尾的行打印出来
[root@localhost ~]# echo "/1,/^A/p" > file.sed
[root@localhost ~]# sed -n -f file.sed test.txt
## 后向引用
-- 先保护后使用
# 将 "hello world" 改成 "[hello] [world]"
[root@localhost ~]# echo "hello world" | sed -r 's/(\w+)/[\1]/g'
[root@localhost ~]# echo "hello world" | sed -r 's/\w+/[&]/g'
# 将每一行第一次连续出现3次的字符串替换成 ‘嗯哼~’
[root@localhost ~]# sed -r -i 's/([a-z])\1\1/嗯哼~/' test.txt
# 获取linux的ip地址
[root@localhost ~]# ip a s eth0
9: eth0: <> mtu 1500 group default qlen 1
link/ether d8:c4:97:92:73:08
inet 169.254.248.50/16 brd 169.254.255.255 scope global dynamic
valid_lft forever preferred_lft forever
inet6 fe80::5219:3165:3e7d:41fb/64 scope link dynamic
valid_lft forever preferred_lft forever
[root@localhost ~]# ip a s eth0 | sed -nr '3s/(^.*t )(.*)(\/.*$)/\2/gp'
# 使用sed命令将任意3个小写字母倒置 例如:'abc'改为'cba'
[root@localhost ~]# echo "abc“ | sed -n 's/([a-z])([0-z])(a-z)/\3\2\1/p'
4. awk 文本分析工具
-
awk是一种编程语言,用于在linux/uniⅸ下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk有很多内置的功能,比如数组
函数等,这是它和C语言的相同之处,灵活性是awk最大的优势。 -
语法
awk [option] 'PATTERN{ACTION STATEMENTS}' FILE

awk程序结构
| 结构 | 解释 |
|---|---|
| BEGIN | 可省略,里面的内容在awk读取文件之前执行 |
| /pattern/ | 可省略,对于输入的每一行,都会执行一次该部分代码,可以添加 /parttern/ 对输入行进行过滤 |
| END | 可省略,里面的内容在awk读取文件完毕之后执行 |
示例:
# 准备如下文本内容
[root@localhost ~]# cat emp.txt
001 张三 1000 10
002 李四 2000 10
003 王五 3000 10
004 赵六 2000 20
005 小红 1800 30
006 小丽 800 20
# 用awk命令输出文本内容
[root@localhost ~]# awk '{print}' emp.txt
# 输出文本内容,添加表头和表的结尾(-------------------)
[root@localhost ~]# awk 'BEGIN{print "编号 姓名 工资 部门"}{print}END{print "-------------------"}' emp.txt
编号 姓名 工资 部门
001 张三 1000 10
002 李四 2000 10
003 王五 3000 10
004 赵六 2000 20
005 小红 1800 30
006 小丽 800 20
-------------------
awk命令选项
| 选项 | 含义 |
|---|---|
| -F fs | 指定输入文件分隔符(默认是空白字符),fs是一个字符串或者是一个正则表达式 |
| -v var=value | 赋值一个用户定义变量 |
| -f scriptfile | 从脚本文件中读取awk命令 |
awk使用方式:
命令行使用:直接在命令行里执行awk命令
awk '{print}' emp.txtawk脚本使用:将awk代码写在文件里(一般以.awk为文件扩展名),通过 -f 选项执行
awk -f file.awk emp.txtshell脚本使用:将awk命令写到shell脚本里,执行shell脚本
awk模式和操作
| 模式 | 含义 |
|---|---|
| /parttern/ | 正则表达式 |
| 关系表达式 | 使用运算符进行操作 |
| 模式匹配表达式 | ~ (匹配) !~ (不匹配) |
- 操作由一个或多个命令、函数、表达式组成,之间有换行符或分号隔开
awk 正则范围:
- /start/,/end/
- NR==1,NR==5 从第1行开始第5行结束
示例:
# 输出emp.txt包含'小'字的行
[root@localhost ~]# awk '/小/' emp.txt
# 输出从包含'张'的行开始到包含'赵'的行结束
[root@localhost ~]# awk '/张/,/赵/' emp.txt
# 输出前三行
[root@localhost ~]# awk 'NR<=3' emp.txt
[root@localhost ~]# awk 'NR==1,NR==3' emp.txt
[root@localhost ~]# awk 'NR>=1 && NR<=3' emp.txt
# 模式匹配则输出
[root@localhost ~]# awk '666 ~ /[0-9]+/' emp.txt
当使用模式后,如果只是输出行,awk语句部分可省略
awk变量
内置变量(预定义变量)
| 变量 | 含义 |
|---|---|
| $0 | 执行过程中当前行的内容 |
| $n | 当前记录的第n个字段(分割后的第n列) |
| NF | 当前行的字段数,$NF 表示一行中最后一个字段 |
| NR | 当前行的行号 |
| FS | 输入字段分隔符(默认是空白字符,可使用-v指定) |
| OFS | 输出字段分隔符(默认是一个空格,可使用-v指定) |
| RS | 输入记录分隔符(默认是一个换行符,可使用-v指定) |
| ORS | 输出记录分隔符(默认是一个换行符,可使用-v指定) |
| FILENAME | 当前文件的文件名 |
自定义变量
-
使用-v选项定义:
-v var=value -
在awk程序中定义:
awk 'BEGIN{var=value}'
传递外部变量
- 使用-v选项可以给awk命令传递一个外部变量
- 在命令最后使用var=value也可以传递一个外部变量
示例:
# 打印emp.txt每一行的内容、行号和字段数
[root@localhost ~]# awk '{print $0,NR,NF}' emp.txt
# 打印第1列、最后一列和倒数的2列的内容
[root@localhost ~]# awk '{print $1,$NF,$(NF-1)}' emp.txt
# 将文本内容按照 "部门 编号 姓名 工资" 的顺序输出
[root@localhost ~]# awk '{print $4,$1,$2,$3}' emp.txt
# 输出第3行的第2个字段
[root@localhost ~]# awk 'NR==3{print $2}' emp.txt
# 统计每个部门的人数
[root@localhost ~]# awk '{print $NF}' emp.txt | uniq -c
# 将输出字段分隔符修改为':' 并把输出结果写入emp.txt.bak文件
[root@localhost ~]# awk -v OFS=":" '{print $1,$2,$3,$4}' emp.txt > emp.bak.txt
[root@localhost ~]# awk -v OFS=":" 'NF=NF' emp.txt > emp.bak.txt
# 针对emp.txt.bak文件每一行数据,输出: "编号:xxx,姓名:xxx,工资:xxx"
[root@localhost ~]# awk -F: '{print "编号:"$1",姓名:"$2",工资:"$3}' emp.bak.txt
# 自定义变量
# 方式一
[root@localhost ~]# echo | awk -v a=100 '{print a}'
# 方式二
[root@localhost ~]# echo | awk 'BEGIN{b=100;print b}'
# 传递外部变量
[root@localhost ~]# a='aaa'
[root@localhost ~]# b='bbb'
# 方式一
[root@localhost ~]# echo | awk -v v1=$a -v v2=$b '{print v1,v2}'
# 方式二
[root@localhost ~]# echo | awk '{print v1,v2}' v1=$a v2=$b
print 的参数以逗号分隔时,打印时以空格作为分隔符;awk中print语句的引号被作为拼接符使用
要使OFS变量生效,必须对字段进行操作(可以设置 NF=NF,NF+=0,$1=$1)
格式化打印(printf)
-
使用方式和C语言的printf一样
-
print显示结果时以逗号分隔,结果会自动将这些内容用分隔符进行分隔,并且不需要添加换行符;printf可以控制某一个字段的输出格式,需要手动添加换行符
常用格式替换符:
| 符号 | 解释 |
|---|---|
| %s | 字符串 |
| %f | 浮点数 |
| %d | 十进制整数 |
| %c | ASCII字符 |
| %% | %本身 |
常用转义字符:
| 符号 | 解释 |
|---|---|
| \n | 换行 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \r | 回车 |
| \b | 后退 |
| \f | 换页 |
| \a | 警告字符 |
| \\ | \本身 |
5. awk编程
awk运算符
算术运算符
| 运算符 | 描述 |
|---|---|
| + - * / % | 加 减 乘 除 取余 |
| ^ ** | 求幂 |
| ++ -- | 自增 自减 (可作为前缀或后缀) |
赋值运算符
| 运算符 | 描述 |
|---|---|
| = += -= *= /= %= ^= **= | 赋值语句(a+=b 等价于 a=a+b,其他类似) |
关系运算符
| 运算符 | 描述 |
|---|---|
| > < >= <= != == | 比较语句(成立返回真,不成立返回假) |
逻辑运算符
| 运算符 | 描述 |
|---|---|
| || | 逻辑或(有真则真) |
| && | 逻辑与(有假则假) |
| ! | 逻辑非(真变假,假变真) |
正则表达式运算符
| 运算符 | 描述 |
|---|---|
| ~ | 匹配正则表达式 |
| !~ | 不匹配正则表达式 |
其他运算符
| 运算符 | 描述 |
|---|---|
| $ | 字段引用 |
| 空格 | 字符串连接符 |
| in | 数组成员迭代符(一般和for循环一起,用于遍历数组) |
| ? : | 三目运算符(和C语言一样: 表达式 ? 语句1 : 语句2 表达式成立,执行语句1,否则执行语句2) |
awk流程控制语句
这里就不详细讲了,所有编程语言基本都这样
条件判断语句
# if
if(表达式)
语句
# if-else
if(表达式)
语句1
else
语句2
# if-else-if
if(表达式)
语句1
else if (表达式2)
语句2
else
语句3
awk分支结构允许嵌套,为了方便判断和阅读,可以将多个语句用{}括起来
循环语句
- 三大循环语句
# while循环
while(表达式){
语句
}
# for循环
# 格式1
for(初始变量;循环判断语句;循环遍历递增/递减语句){
语句
}
# 格式2
for(变量 in 数组){
语句
}
# do-while循环
do{
语句
} while(条件)
- 三大循环流程改变语句
break;退出循环continue;退出本次循环exit status_code;exit语句用于停止就脚本的执行(若有END则是转移到END),接受一个整数作为参数作为awk进程的退出状态码,如未提供参数,则默认为0($?可以查看)
awk数组
数组是awk的灵魂,处理文本中常常会用到数组处理
awk数组特性:
- awk数组的下标可以是数字,也可以是字符串,因此,awk中数组是关联数组
- 在内部,awk数组的索引全都是字符串,即使是数值索引在使用时内部也会转换成字符串
- awk的数组元素的顺序和元素插入时的顺序不一定相同
- awk中的数组不必提前声明,也不用声明大小
- 数组元素会根据上下文使用0或空字符串来初始化
创建(添加、修改)数组
语法:数组名[下标] = 值
- 给数组添加/修改元素的语法和创建数组一样
访问数组元素
语法:数组名[下标]
删除数组元素
语法:delete 数组名[下标]
- 删除不存在的元素不会报错
delete 数组名可以直接删除数组所有元素
数组相关函数
-
length(arr)获取数组长度 -
asort(arr)对数组进行排序,并返回数组长度 -
split(str,arr,sep)分割字符串为数组,并返回数组长度生成的awk数组下标从1开始,和C语言数组不一样
[root@localhost ~]# awk 'BEGIN{str="a,b,c,d";len=split(str,arr,",");print len,length(arr),asort(arr),arr[1]}'
4 4 4 a
遍历数组
# 方式1
[root@localhost ~]# awk 'BEGIN{
str="a,b,c,d";
len=split(str,arr,",");
for(i in arr){
print i,arr[i];
}
}'
1 a
2 b
3 c
4 d
# 方式2 (awk数组是关联数组,该方式可以保证有序遍历)
[root@localhost ~]# awk 'BEGIN{
str="a,b,c,d";
len=split(str,arr,",");
for(i=1;i<=len;i++){
print i,arr[i];
}
}'
1 a
2 b
3 c
4 d
# 判断数组中是否包含某个key
if(key in arr)
# 检测arr是否是数组
isarray(arr) 如果arr是数组,返回1,否则返回0
typeof(arr) 返回数据类型,如果arr是数组,返回 'array'
我觉得学到这里已经够用了,后面的了解一下就行,用到再学吧~ (练习别忘了)
多维数组
- awk只支持一维数组,我们可以使用一维数组来模拟多维数组
# 有如下 3*3 的二维数组arr:
1 2 3
4 5 6
7 8 9
在C语言中,arr[0][0] = 100;在awk中,我们可以令arr[0,0] = 100,以此类推:arr[0,1]、arr[0,2]...arr[3,3];
实际上,0,1 0,2 3,3 只是一个字符串索引
内置函数
算术函数
| 函数 | 描述 |
|---|---|
| sin(expr) | 返回expr的正弦值 |
| cos(expr) | 返回expr的余弦值 |
| atan2(y,x) | 返回y/x的反切值 |
| log(expr) | 返回expr的自然对数 |
| exp(expr) | 返回以e为底,expr的指数值 |
| sqrt(expr) | 返回expr的平方根 |
| int(expr) | 返回expr截断至整数的值 |
| rand() | 返回任意数字n,其中 0<=n<1 |
| srand([expr]) | 把rand函数的种子值设置为expr参数的值,如果省略参数,则使用某天的时间 |
# 获取0-99之间的随机整数
[root@localhost ~]# awk 'BEGIN{srand();randint=int(100*rand());print randint}'
字符串函数
| 函数 | 描述 |
|---|---|
| asort(arr [, d ]) | 按 ASCII 字符顺序对数组 arr 的值进行排序 |
| asorti(arr [, d]) | 按 ASCII 字符顺序对数组 arr 的键进行排序 |
| gsub(regexp, sub, str) | 在一个字符串中查找指定的模式匹配的全部字符串,找到之后都替换为另一个字符串 |
| sub(search, sub, str) | 在一个字符串中查找指定的字符串,找到之后则替换为另一个字符串。只会替换一次 |
| index(str, sub) | 查找一个字符串在另一个字符串中的位置。如果找到则返回找到的位置,否则返回0 |
| length(str) | 返回一个字符串的长度 |
| match(str, regexp) | 查找匹配模式的第一个最长子串位置。如果没找到则返回 0,找到则返回最长子串的开始位置 |
| split(str, arr, regexp) | 把一个字符串根据给定的模式分割成多个子串。如果没有传递模式则会使用变量 FS 的值 |
| printf(format, expr-list) | 根据给定的字符串格式和传递的变量构造字符串并输出到标准输出 |
| strtonum(str) | 用于检查一个字符串是否数字并将它转换为十进制数字 |
| substr(str, start, len) | 用于返回字符串 str 中的从 start 的位置开始,长度为 len 的子串 |
| tolower(str) | 用于将指定的字符串中的大写字母转换为小写字母 |
| toupper(str) | 用于将指定的字符串中的小写字母转换为大写字母 |
示例:
# asort(arr[,d]) arr-->数组 d-->数组,如果传了该参数,就不会修改arr,而是把arr中所有元素拷贝到d,然后对d进行排序
[root@localhost ~]# awk 'BEGIN{
arr[11]=800;
arr[22]=200;
arr[33]=300;
arr[44]=100;
for(i in arr){
print i,arr[i];
}
asort(arr);
print;
for(j in arr){
print j,arr[j];
}
}'
11 800
22 200
33 300
44 100
1 100
2 200
3 300
4 800
# asorti
[root@localhost ~]# awk 'BEGIN{
arr[11]=800;
arr[22]=200;
arr[33]=300;
arr[44]=100;
for(i in arr){
print i,arr[i];
}
asorti(arr);
print;
for(j in arr){
print j,arr[j];
}
}'
11 800
22 200
33 300
44 100
1 11
2 22
3 33
4 44
# gsub(regexp, sub, str)
[root@localhost ~]# awk 'BEGIN{
str="hello world";
gsub("[o|l]","*",str);
print str;
}'
he*** w*r*d
# sub(search, sub, str)
[root@localhost ~]# awk 'BEGIN{
str="hello world";
sub("[o|l]","*",str);
print str;
}'
he*lo world
# index(str, sub)
[root@localhost ~]# awk 'BEGIN{
str="hello world";
idx=index(str,"l");
print idx;
}'
3
# match(str, regexp)
[root@localhost ~]# awk 'BEGIN{
str="hello world hi haaaaaa";
idx=match(str,"h*");
print idx;
}'
1
# strtonum(str)
[root@localhost ~]# awk 'BEGIN{
str="01010";
res=strtonum(str);
print res;
}'
520
# substr(str, start, len)
[root@localhost ~]# awk 'BEGIN{
str="hello world";
res=substr(str,7,5);
print res;
}'
world
# tolower(str)
[root@localhost ~]# awk 'BEGIN{
str="HAHAHA";
res=tolower(str);
print res;
}'
hahaha
# tolupper(str)
[root@localhost ~]# awk 'BEGIN{
str="hello world";
res=toupper(str);
print res;
}'
HELLO WORLD
时间函数
| 函数 | 描述 |
|---|---|
| systime() | 返回当前时间戳 |
| mktime(datespec) | 将指定格式的时间字符串(YYYY MM DD HH MM SS)转换为时间戳 |
| strftime([format [, timestamp]]) | 将一个时间戳格式的时间根据指定的时间格式化符转成字符串形式表示 |
示例:
# systime()
[root@localhost ~]# awk 'BEGIN{print systime()}'
1672448348
# mktime(datespec)
[root@localhost ~]# awk 'BEGIN{print mktime("2022 12 31 09 00 00")}'
1672448400
# strftime([format [, timestamp]])
[root@localhost ~]# awk 'BEGIN{print strftime("%c",systime())}'
Sat Dec 31 09:03:53 2022
时间格式化符
| 格式符 | 说明 |
|---|---|
| %a | 本地化的星期几,例如 星期四 |
| %A | 本地化的星期几缩写,例如 四 |
| %b | 本地化的月份所写,例如 5月 |
| %B | 本地化的月份,例如 五月 |
| %c | C语言中的 %A %B %d %T %Y 的格式,例如 2019年05月30日 星期四 21时08分37秒 |
| %C | 本年度的世纪部分。也就是四位数字年份的前两位,例如 2019 年中的 20 |
| %d | 当月中的第几天,范围为 01-31,例如 30 |
| %D | 格式 %m/%d/%y 的简写,例如 05/30/19 |
| %e | 当月中的第几天,范围为 1-31,如果小于 10 则在前面补空格,如 1 补全为 1 |
| %F | ISO 8601 日期格式中的 %Y-%m-%d 的别名 |
| %g | ISO 8601 日期格式中的周数除以 100 的值,范围 00-99 例如1993 年 1 月 1 日是1992年的第53周 |
| %G | IOS 周数制下的完整年费,类似于四位数年份,例如 2019 |
| %h | 格式 %b 的别名 |
| %H | 24小时制的当前时间的时,范围为 00–23 |
| %I | 12小时制的当前时间的时,范围为 01–12 |
| %j | 一年中的第几天,范围为 001–366 |
| %m | 当前时间的月,范围为 01–12 |
| %M | 当前时间的分,范围为 00–59 |
| %n | 换行符 \n |
| %p | 本地化的 12 小时制时间格式中的 AM 或 PM,也就是本地化的上午或下午表示形式 |
| %r | 本地化的 12 小时制时间格式,类似于C语言中的 %I:%M:%S %p |
| %R | 格式 %H:%M 的缩写 |
| %S | 当前时间的秒,范围为 00-60 。60 主要考虑闰秒 |
| %t | 制表符 \t |
| %T | 格式 %H:%M:%S 的缩写 |
| %u | 一周中的第几天,也就是星期几,范围为 1–7。每周以星期一开始 |
| %U | 一年中的第几周,范围为 00-53。第一周从第一个星期日开始 |
| %V | 一年中的第几周,范围为 01-53。第一周从第一个星期一开始 |
| %w | 一周中的第几天,也就是星期几,范围为 0–6。每周以星期日开始 |
| %W | 一年中的第几周,范围为 00-53。第一周从第一个星期一开始 |
| %x | 本地化的完整日期表示,类似于 %A %B %d %Y,例如 星期四 五月 30 2019 |
| %X | 本地化的完整时间表示,类似于C语言中的 %T ,例如 07:06:05 |
| %y | 两位十进制年份,即取年份的后两位,范围为 00-99,比如 2019 则返回 19 |
| %Y | 完整的 4 位十进制年份,例如 2019 |
| %z | 以 +HHMM 格式的时区偏移。是 RFC 822 或 RFC 1036 日期格式中的组成部分。 |
| %Z | 时区名称或时区名称缩写。如果没有时区则返回空字符串 '' |
其他函数
| 函数 | 描述 |
|---|---|
| close(expr) | 用于关闭已经打开的文件或管道 |
| system(command) | 执行系统脚本命令,并返回脚本执行的退出状态 |
| getline | 读取下一行 |
| next | 处理下一行 |
| nextfile | 处理下一个文件 |
示例:
# close(expr)
[root@localhost ~]# awk 'BEGIN{while("cat emp.txt" | getline){print $0}close("emp.txt")}'
# system(command)
[root@localhost ~]# awk 'BEGIN{system("ls -l")}'
# getline
[root@localhost ~]# awk '{getline;print}' emp.txt
002 李四 2000 10
004 赵六 2000 20
006 小丽 800 20
[root@localhost ~]# awk 'BEGIN{print "输入:";getline name;print name}'
输入:
123
123
# next
[root@localhost ~]# awk '{if($3<2000)next;print}' emp.txt
002 李四 2000 10
003 王五 3000 10
004 赵六 2000 20
# nextfile
[root@localhost ~]# awk '{if($3==2000) nextfile;print}' emp.txt file
001 张三 1000 10
xxx is a hanhan. ^_^
are you kidding?
I think ...
My phone number is 1872272****.
自定义函数
- 函数定义
function 函数名(参数1, 参数2, ...) {
函数体
}
函数名必须以字母开始,可以由字母、数字、下划线组成,不能使用保留字
函数体语句之间必须以分号分隔
函数可以有返回值,也可以没有,如果需要返回值,则必须在大括号里使用
return关键字
- 函数调用
# 调用无参函数
fun_name
# 调用有参数的函数
fun_name(arg1[,arg2...])
# 调用有返回值的函数
var = fun_name([arg1...])
函数在BEGIN,主体,END中均可调用
示例:
# 无参数函数
[root@localhost ~]# awk 'BEGIN{
fun1()
}
function fun1(){
print "this is a function!"
}'
this is a function!
# 有参数函数
[root@localhost ~]# awk 'BEGIN{
fun2(10,20)
}
function fun2(num1,num2){
print "函数执行的结果是:"num1+num2
}'
函数执行的结果是:30
# 有返回值函数
[root@localhost ~]# awk 'BEGIN{
res = fun3(10,20);
print "num1+num2的和是:"res
}
function fun3(num1,num2){
return num1+num2
}'
num1+num2的和是:30
6.检测一下成果
(1) 用awk命令输出1-100的偶数和
(2) 打印文件中第20列之后的内容
(3) 去除文件中的空行(分别使用grep、sed、awk命令实现)
[root@localhost ~]# cat file.txt
You and me.
xxx is a hanhan. ^_^
longzhaoqianwowudunjiu.
He can speak english.
Are you kidding?
I think ...
youoy abba ccccc ddd
My phone number is 1872272****.
vvv
(4) 打印文件中的空行的行号
[root@localhost ~]# cat file.txt
a
b
c
d
e
f
(5) 去除文件中的重复行
[root@localhost ~]# cat file.txt
You and me.
xxx is a hanhan. ^_^
xxx is a hanhan. ^_^
xxx is a hanhan. ^_^
longzhaoqianwowudunjiu.
He can speak english.
Are you kidding?
He can speak english.
youoy abba ccccc ddd
My phone number is 1872272****.
xxx is a hanhan. ^_^
(6) 统计文件中第二列出现的次数大于1的次数和科目
[root@localhost ~]# cat file.txt
01 python 99
02 go 80
03 c++ 88
04 java 77
05 go 88
06 shell 89
07 java 70
08 java 88
# 结果示例:
2 go
3 java
(7) 统计文件中每个单词出现的次数
[root@localhost ~]# cat file.txt
you and you
you and me
hello
# 结果示例:
you: 3
and: 2
hello: 1
(8) 统计文件中每一行数字出现的次数和整个文件中数字出现的总数
[root@localhost ~]# cat file.txt
a123
wo4r2d0
ab8cd
sss
# 结果示例:
line1: 3
line2: 3
line3: 1
line4: 0
total: 7
(9) 将文件中的列转置成行
[root@localhost ~]# cat file.txt
job salary
c++ 13
java 14
php 12
# 结果示例:
job c++ java php
salary 13 14 12
(10) 将文件中的内容按照结果示例输出
[root@localhost ~]# cat file.txt
111:13443
222:13211
111:13643
333:12341
222:12123
# 结果示例:
[111]
13443
13643
[222]
13211
12123
[333]
12341
题目有一半是牛客网的题,好好研究

 浙公网安备 33010602011771号
浙公网安备 33010602011771号