
1 写在前面
在实际的开发中,我们经常需要向任务传递数据参数,在之前的任务创建中,我们只能以 JobBuilder.newJob(DataJob.class) 的形式向建造器传递一个 class,实际上 JobDetail 接口规定了一个方法 getJobDataMap(),用于传递数据。
2 初探数据的传递
2.1 JobDataMap
通过阅读 JobDataMap 的源码,我们发现它是一个使用 String 作为 key 的 Map 的具体实现,同时具有一个 isDirty 字段。它具有 getCharacterFromString() 等方法,方法原理就是从 Map 中获取 Object,并且强制转换到 Character 类型,其他方法也类似。请注意其父类的泛型类别:

2.2 JobExecutionContext
如果 Job 在执行任务中需要获取数据,自然是从唯一的运行方法参数 JobExecutionContext 中获取,JobExecutionContext 的接口规定了 getJobDetail() 方法以获取 JobDetail,并且在 JobDetail 中存在一个获取 JobDataMap 的方法 getJobDataMap(), 按照这个思路,我们自然会想到数据的传递很大可能是在 JobBuilder 中完成的(在后边的分析中,我们发现在 Trigger 中也可以传递,当然这些都是后话)
2.3 方法 usingJobData
usingJobData 方法有多种签名,有 usingJobData(String dataKey, Boolean value),usingJobData(String dataKey, Double value),usingJobData(JobDataMap newJobDataMap) 不等,我们先查看其中一个方法

各种方法中的 dataKey 字段是 String 类型的,对应 DirtyFlagMap<String, Object> 的第一个泛型类型。
实际上 jobDataMap 字段就是 JobDataMap 类,该方法将数据传进去 jobDataMap 中,并在 build() 方法中将字段 jobDataMap 的值设置给了 JobDetail 中的 jobDataMap:
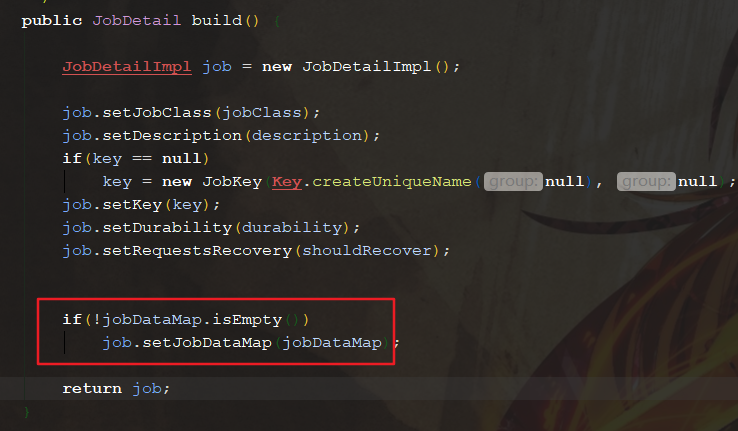
2.4 测试
根据上边的分析,我们可以简单的写出下边的测试类:
1 /** 2 * @author pancc 3 * @version 1.0 4 */ 5 public class DataJobDemo { 6 7 public static void main(String[] args) throws SchedulerException, InterruptedException { 8 JobDetail detail = JobBuilder.newJob(DataJob.class) 9 .withIdentity("data", "group0") 10 .usingJobData("data", "hello") 11 .build(); 12 13 Trigger trigger = TriggerBuilder.newTrigger() 14 .withIdentity("data_trigger") 15 .startNow() 16 .build(); 17 18 Scheduler scheduler = new StdSchedulerFactory().getScheduler(); 19 20 scheduler.start(); 21 scheduler.scheduleJob(detail, trigger); 22 /* 23 * 2 秒钟后关闭 24 */ 25 Thread.sleep(2_000); 26 scheduler.shutdown(); 27 } 28 29 public static class DataJob implements Job { 30 31 @Override 32 public void execute(JobExecutionContext context) { 33 String data = context.getJobDetail().getJobDataMap().getString("data"); 34 System.out.printf("get data {%s} from map\n", data); 35 36 } 37 } 38 }
这个程序任务成功的打印了如下语句:

3 再探数据的传递
根据官方描述,在 JobDataMap 中设置的值,会自动映射到 Job 类的字段中,这里有一个隐性要求,字段与 setter 方法必须遵循 JavaBean 规范。
这次我们不能像上边一样通过简单查看源码就能理解其中的设计,让我们通过一个实例,并且打断点来查看它的自动注入魔法。
3.1 简单测试
我们规定 Job 有一个 name 字段,并且符合 JavaBean 规范,并且我们向 JobDetail 传递一个 dataKey 为 name 的值:
1 /** 2 * @author pancc 3 * @version 1.0 4 */ 5 public class InjectDataDemo { 6 7 public static void main(String[] args) throws SchedulerException, InterruptedException { 8 JobDetail detail = JobBuilder.newJob(InjectData.class) 9 .withIdentity("inject", "group0") 10 .usingJobData("name", "Alex") 11 .build(); 12 13 Trigger trigger = TriggerBuilder.newTrigger() 14 .withIdentity("inject_trigger") 15 .startNow() 16 .build(); 17 18 Scheduler scheduler = new StdSchedulerFactory().getScheduler(); 19 20 scheduler.start(); 21 scheduler.scheduleJob(detail, trigger); 22 /* 23 * 2 秒钟后关闭 24 */ 25 Thread.sleep(2_000); 26 scheduler.shutdown(); 27 } 28 29 public static class InjectData implements Job { 30 31 private String name; 32 33 public void setName(String name) { 34 this.name = name; 35 } 36 37 @Override 38 public void execute(JobExecutionContext context) throws JobExecutionException { 39 System.out.printf("hello, my name is %s \n", name); 40 } 41 } 42 43 }
查看控制台,我们成功在 name 属性获取到了值:

3.2 探索注入原理
现在,在 this.name = name; 前打上断点,我们通过 debug 的调用栈来查看实际的过程。

分别有四个入口,这是
- 第一个入口: shell.initialize(qs); 从属于 QuartzSchedulerThread 线程中 run 方法,是启动 QuartzScheduler 时调用的。
- 第二个入口:job = sched.getJobFactory().newJob(firedTriggerBundle, scheduler); 这里实例化了一个任务。
- 第三个入口:setBeanProps(job, jobDataMap); 从方法名我们可以猜测它使用 jobDataMap 对 Bean 的字段值进行了设置。
- 第四个入口:setMeth.invoke(obj, new Object[]{ parm }); 从方法名我们可以猜测它通过反射调用了对应的字段的 setter 方法设置了值。
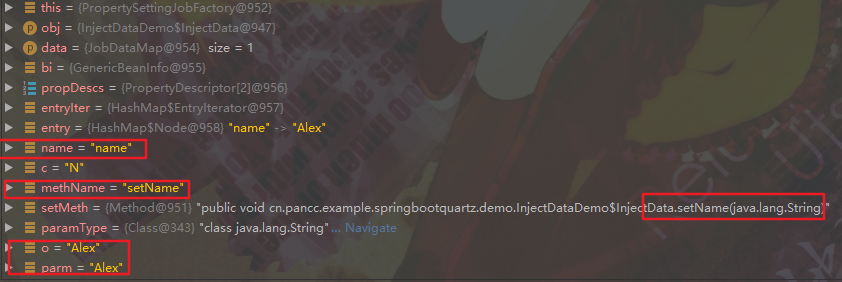
在第四个入口,我们通过 debug 的 variables 视图,可以观察到此时 它不断尝试从 jobDataMap 获取 key,尝试使用 datakey 的值在 InjectData 类中查找对应的 setter 方法,并且在实例上调用该 setter 方法设置值:
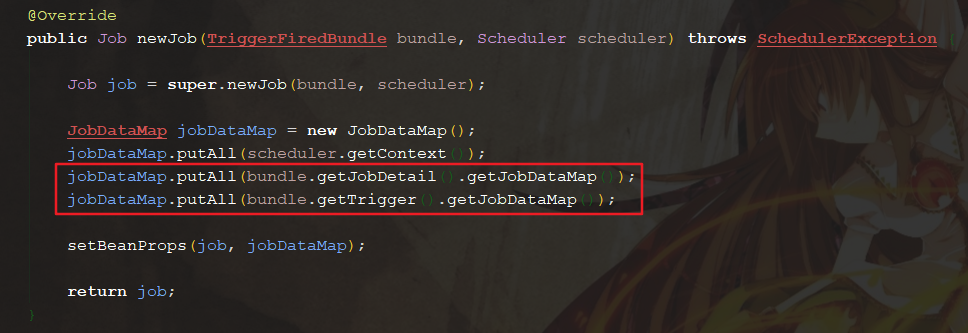
4 Trigger 的数据传递与数据合并
在 Trigger 的构建中,我们还观察到了与 JobBuilder 同样的方法 usingJobData ,如果此时往 Trigger 传递进去 重复的值与新的字段,会如何?在编写测试代码之前,我们回到上点分析中的 PropertySettingJobFactory 类中,仔细观察这个方法:
与 DirtyFlagMap 中的 Map 类型:
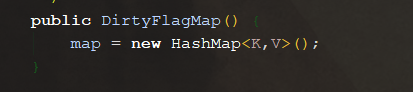
因此,我们的数据就像在合并两个 HashMap 一样,重复的键值对会发生覆盖,新的值覆盖旧的,不冲突的则保留
4.1 合并验证
1 /** 2 * @author pancc 3 * @version 1.0 4 */ 5 public class DuplicatedDataDemo { 6 7 public static void main(String[] args) throws SchedulerException, InterruptedException { 8 JobDetail detail = JobBuilder.newJob(DuplicatedData.class) 9 .withIdentity("inject", "group0") 10 .usingJobData("name", "Alex") 11 .build(); 12 13 Trigger trigger = TriggerBuilder.newTrigger() 14 .withIdentity("inject_trigger") 15 .usingJobData("name", "Alice") 16 .usingJobData("age",50) 17 .startNow() 18 .build(); 19 20 Scheduler scheduler = new StdSchedulerFactory().getScheduler(); 21 22 scheduler.start(); 23 scheduler.scheduleJob(detail, trigger); 24 /* 25 * 2 秒钟后关闭 26 */ 27 Thread.sleep(2_000); 28 scheduler.shutdown(); 29 } 30 31 public static class DuplicatedData implements Job { 32 33 private String name; 34 35 private Integer age; 36 37 public void setName(String name) { 38 this.name = name; 39 } 40 41 public void setAge(Integer age) { 42 this.age = age; 43 } 44 45 @Override 46 public void execute(JobExecutionContext context) throws JobExecutionException { 47 System.out.printf("hello, my name is %s , my age is %d \n", name, age); 48 } 49 } 50 }
可以观察到我们在 JonDetail 中设置的 name 被 Trigger 中的替代掉了,新的由 Trigger 持有的 age 值正确的传递到了 age 属性中:

4.2 我的 JobExecutionContext 究竟有什么
继续上边的代码,让我们在 execute 增加以下语句并打上断点:

让我们步入 org.quartz.core.JobRunShell#initialize 方法,这里根据 Scheduler,从 JobStore(此时是 RAMJobStore)获取到的 TriggerFiredBundle 实例与 方法内实例化的 Job 实例创建了一个 JobExecutionContext:


因此,当我们想要检测被覆盖的原有数据,可以用以下语句:
1 @Override 2 public void execute(JobExecutionContext context) throws JobExecutionException { 3 JobDataMap map = context.getJobDetail().getJobDataMap(); 4 JobDataMap mapMerged = context.getMergedJobDataMap(); 5 List<Map.Entry<String, Object>> duplicates = mapMerged.entrySet().stream().filter(en -> map.getWrappedMap().containsKey(en.getKey())).collect(Collectors.toList()); 6 System.out.printf("hello, my name is %s , my age is %d \n", name, age); 7 }
5 数据传递中的坑
类型安全性:在唤起对应字段的 setter 方法时,Quartz 通过类检查会保证数据的类型安全。
不可序列化错误:在唤起对应字段的 setter 方法时,Quartz 还检查了 setter 对应的参数类型是否为基本类型(Primitive),如果是则会报错。
数据覆盖:由于 JobDataMap 底层本质上使用 HashMap,所以后来的值会覆盖原来的值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号