

1 导读
本文从 Java 虚拟机出发,整体围绕内存区域,并发散到 Class 的文件结构,Class 的字节码解析及分析,难度中等,建议对各个相关的知识稍有涉猎

2 运行时数据区
Java 虚拟机定义了若干种程序运行期间会使用到的运行时数据区,其中有一些会随着虚拟机启动而创建,随着虚拟机退出而销毁。另外一些则是与线程一一对应的,这些与线程对应的数据区域会随着线程开始和结束而创建和销毁。
2.1 程序计数器
程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。在虚拟机的概念模型中,字节码解释器通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、线程恢复等都依赖该计数器。
由于Java 虚拟机的多线程是通过县城轮流切换并分配处理器时间的方式来实现的,在任何一个确定的时刻,一个逻辑处理器只会执行一条线程中的指令。为了线程切换后能够恢复到正确的执行位置,每个线程都有一个独立的程序计数器,各条线成之间计数器互不影响,这些是线程私有(隔离)的数据。
当线程正在执行的是一个 Java 方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;
当线程正在执行的是一个 Native 方法,这个计数器则为空。
这个内存区域是 Java 机内存规范中唯一没有规定任何 OutOfMemoryError 错误的区域。
2.2 Java 虚拟机栈
每一条 Java 虚拟机线程都有自己私有的 Java 虚拟机栈(Java Virtual Machine Stack),这个栈与线程同时创建,用于存储栈帧。栈帧用于储存局部变量表、操作数栈、动态链接、方法返回地址 和一些附加信息。每一个方法从调用到执行完成的过程就对应着一个栈帧在虚拟机中从入栈到出栈的过程。。
由于除了栈帧的出栈入栈之外,Java 虚拟机栈不会受到其他影响,所以栈帧的分配可以在堆中进行。
虚拟机栈会抛出的错误:
StackOverflowError:如果线程请求分配的栈容量超过 Java 虚拟机栈允许的最大容量时,Java 虚拟机将会抛出一 个 StackOverflowError 异常。
OutOfMemoryError:如果 Java 虚拟机栈可以动态扩展,并且扩展的动作已经尝试过,但是目前无法申请到足够的内存去完成扩展,或者在建立新的线程时没有足够的内存去创建对应的虚拟机栈,那 Java 虚 拟机将会抛出一个 OutOfMemoryError 异常。
2.2.1 局部变量表
每个栈帧内部都包含一组称为局部变量表(Local Variables)的变量列表。栈帧中局部变量表的长度由编译期决定,并且存储于类和接口的二进制表示之中,既通过方法的 Code 属性保存及提供给栈帧使用。在Java 程序编译为 Class 文件时,就在方法的 Code 属性的 max_locals 数据项中确定了该方法所需要分配的局部变量表的最大容量(参见Class 文件结构-属性表-Code属性)。
局部变量表的容量以变量槽(Variable Slot)为最小单位,Java 虚拟机规范并没有指明一个 Slot 应占的体积大小,只是指出:一个Slot可以保存一个类型为 boolean、byte、char、short、float、reference 和 returnAddress 的数据,两个 Slot 可以保存一个类型为 long 和 double 的数据。
一个 Slot 可以存放一个32位以内的数据类型(上述的前6种类型),对于64位的数据,虚拟机会以高位对其的方式为其分配两个连续的空间 { Slot[n], Slot[n+1] },reference 可能是32位的也可以是64位的,但是 long 和 double 是明确的64位数据类型。这种分配方式与内存模型中 “long 和 double 的非原子协定” 中把一次 long 和 double 数据类型读写分割为两次32位读写的做法有些类似,但是,由于局部变量表建立在线程的堆栈中,是线程私有数据,无论读写两个连续 Slot 是否为原子操作,都不会引起线程安全问题
局部变量使用索引来进行定位访问,第一个局部变量的索引值为零(如果执行的是实例,即非static方法,第0位索引的 slot 默认是用于传递方法所属对象实例的引用"this"),局部变量的索引值是从零至小于局部变量表最大容量的所有整数。
2.2.1.1 long/double 占用两个 Slot
举个例子,我们的类实例方法如下:
1 /** 2 * @author pancc 3 * @version 1.0 4 */ 5 public class TwoSlot { 6 public long g() { 7 long s = 6; 8 int i = 1; 9 return s+i; 10 } 11 }
以及它的 class 文件
1 public class TwoSlot { 2 public TwoSlot() { 3 } 4 5 public long g() { 6 long s = 6L; 7 int i = 1; 8 return s + (long)i; 9 } 10 }
解析的字节码部分为:
{ ...省略的常数池跟构造方法.... public long g(); Code: Stack=4, Locals=4, Args_size=1 0: ldc2_w #2; //将 long 6L 压入操作栈 3: lstore_1 //将 long 6L 从栈中储存到局部变量表的 slot(1) 4: iconst_1 //将 int 1 压入操作栈 5: istore_3 //将 int 1 从栈中储存到局部变量表的 slot(3) 6: lload_1 //将 局部变量表的 slot(1) 压入操作栈 7: iload_3 //将 局部变量表的 slot(3) 压入操作栈 8: i2l //对栈顶的 slot(3) 转换到 long 类型 9: ladd //对栈顶的 slot(1) 和 slot(3) 作和操作 10: lreturn //将栈顶的元素做 long 类型返回 LineNumberTable: line 10: 0 line 11: 4 line 12: 6 LocalVariableTable: Start Length Slot Name Signature 0 11 0 this Lclasses/jvm/TwoSlot; 4 7 1 s J 6 5 3 i I }
从以上的字节码可以看出,局部变量表的最大长度为 4 ,栈的最大深度为 4,表内容只有三个数据,其中 Slot(0) 存放的是类实例引用,Slot(3) 存放的是 int 类型的 i,Slot(1) 和 Slot(2) 存放的是 long 类型的 s。
实际上,在操作栈上 long/double 也是占用2个单位的栈容量。让我们假设下,当 long 与其他类型一样在栈中只占用一个单位容量,那么在上边的字节码操作中,我们只需要用到2个单位栈,而实际上编译器给当前局部变量表分配的是4个单位。
注:javap -v [ClassFile] 即可得到目标 Class 的字节码
2.2.1.2 局部变量复用对垃圾收集的影响
为了节省空间,局部变量表的 Slot 是可以重用的,方法体中定义的变量,其作用域不一定会覆盖整个方法体,如果当前字节码的程序计数器的值已经超过了某个变量的作用域(在代码中以花括号为界),那么这个变量对应的Slot就可以被其他变量使用。
在某些情况下, Slot 的复用会直接影响到系统的垃圾收集行为。以下是三种情况下的代码:
1 /** 2 * @author pancc 3 * @version 1.0 4 */ 5 public class SlotReuse { 6 public static void main(String[] args) { 7 byte[] bytes = new byte[64*1024*1024]; 8 System.gc(); 9 } 10 }
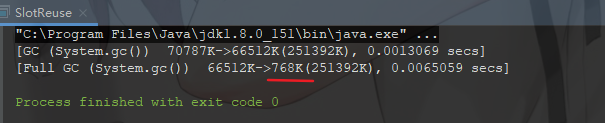
上边的代码很简单,我们向内存填充了 64MB 的数据,然后通知虚拟机进行垃圾收集。在理想状况下,垃圾收集应该能完美地进行。我们在虚拟机的运行参数中加上 “-verbose:gc” ,并观察gc 的过程,发现虚拟机并没有收集这 64MB 的内存。

没有回收 bytes 的所占内存是正常的,因为在执行 System.gc() 时,bytes 还处于作用于之内,虚拟机自然不敢回收 bytes 的内存。既然如此,让我们限定 bytes 的作用域,让 gc 发生在该域外:
1 public class SlotReuse { 2 public static void main(String[] args) { 3 { 4 byte[] bytes = new byte[64 * 1024 * 1024]; 5 } 6 System.gc(); 7 } 8 }
加了花括号之后,bytes 的作用于被限定在花括号之内,从逻辑上讲,在执行 gc 的时候,bytes 已经不可能被访问了,然而当执行代码的时候,这些内存还是没有被回收:

这很让人不解,在我们涉及其中原因之前,让我们尝试对 bytes 的 Slot 进行复用,看看情况会是如何:
1 public class SlotReuse { 2 public static void main(String[] args) { 3 { 4 byte[] bytes = new byte[64 * 1024 * 1024]; 5 } 6 int i = 2; 7 System.gc(); 8 } 9 }
运行上述的代码,这次的内存的确被正确回收了。
让我们观察该 Class 生成的字节码相关部分:
1 { 2 常量池... 3 构造方法... 4 public static void main(java.lang.String[]); 5 Code: 6 Stack=1, Locals=2, Args_size=1 7 0: ldc #2; //int 67108864 8 2: newarray byte 9 4: astore_1 10 5: iconst_2 11 6: istore_1 12 7: invokestatic #3; //Method java/lang/System.gc:()V 13 10: return 14 LineNumberTable: 15 line 11: 0 16 line 13: 5 17 line 14: 7 18 line 15: 10 19 20 LocalVariableTable: 21 Start Length Slot Name Signature 22 0 11 0 args [Ljava/lang/String; 23 7 4 1 i I 24 }
在上边的字节码中,我们看到 bytes 先被从栈存入 Slot[1],随后常量1被存入 Slot[1],然后发生了 gc。
在前一种代码中,bytes 被存入 Slot[1] 之后便发生了 gc,此时,作为 “GC Roots” 的一部分的局部变量表仍然通过 Slot[1] 保留着对 bytes 的关联,这种关联没有打破的情况下,bytes 被认为仍然是存活的,gc 将不会对其进行回收。
2.2.1.2 局部变量复用与垃圾回收
一般地,判断对象的存活有两种形式:
- 引用计数法:给引用添加一个计数器,每当有一个地方引用它时,计数器数值加1,当引用时,计数器减1;在任意时刻,计数器归零时该对象就是可以回收的。因为循环引用的存在(A.value = B; B.value = A; 此时双方的计时器永远不会归零),主流的 Java 虚拟机并没有选用该方法判断对象是否存活。
- 可达性分析算法:主流的商业程序语言(Java、C#)的主流实现中,都是选用该算法来判断对象是否存活的。这个算法的基本思路是通过一系列的 “GC Roots”的对象作为起始点,从这些节点开始向下搜索,所有走过的路径称为引用链(reference chain),当一个对象到 CG Roots 之间不存在任何引用链时(以图论的角度,对该对象而言,任何一个起点都是不可达节点),则证明该对象是不可用的,是可回收的。
如图所示,Object 7、Object 8、Object 9 虽然互相有关联,但是它们到 GC Roots 是不可达的,所以他们会被判定为可回收对象。

在 Java 中,可以作为 GC Roots 的对象包括:
- 虚拟机栈帧(局部变量表)中引用的对象;
- 方法区中类静态属性引用的对象;
- 方法区中常量引用的对象;
- 本地方法栈中 JNI (Native)引用的对象;
2.2.2 操作数栈
操作数栈(operand stack)也称为操作栈,它是一个 FIFO 栈。与局部变量表相似,操作数栈的最大深度 也在编译的时候写入Code 属性的 max_stack 项中。操作数栈可以存放任意的 java 类型,同上边例子描述的一样,long/double 类型占用的栈容量为 2。在方法的任何执行时刻,操作栈的深度都不会超过在 max_stack 数据项中设定的最大值。
一个方法刚开始执行的时候,方法的操作数栈是空的,在方法的执行过程中,会有各种字节码指令往栈写入和提取内容,既入栈/出栈。字节码指令通过操作数栈来执行算术运算,在调用其他方法时通过操作数栈来传递参数等。
例如,整数加法的指令 iadd 在运行的时候操作数栈中最接近栈顶的两个元素已经存入了两个 int 类型的数值,当执行这个指令时,会将这两个 int 值出栈相加,并将结果进栈。
1 public int add(final int a, final int b, final int c) { 2 return a + b + c; 3 }
1 public int add(int, int, int); 2 Code: 3 Stack=2, Locals=4, Args_size=4 4 0: iload_1 //将 Slot[1] 压入操作栈 5 1: iload_2 //将 Slot[2] 压入操作栈 6 2: iadd //取栈顶两个元素出栈相加,并将结果入栈 7 3: iload_3 //将 Slot[3] 压入操作栈 8 4: iadd //取栈顶两个元素出栈相加,并将结果入栈 9 5: ireturn //返回栈中结果 10 LineNumberTable: 11 line 13: 0 12 13 LocalVariableTable: 14 Start Length Slot Name Signature 15 0 6 0 this Lclasses/jvm/OperandStack; 16 0 6 1 a I 17 0 6 2 b I 18 0 6 3 c I
例如,通过操作数栈传递参数构建对象(#\\d 为对常量池的常量引用):
1 public File createdFileRef(final String path) { 2 return new File(path); 3 }
1 public java.io.File createdFileRef(java.lang.String); 2 Code: 3 Stack=3, Locals=2, Args_size=2 4 0: new #2; //class java/io/File //创建 File 类的实例 5 3: dup //复制栈顶数值,并压入栈顶 6 4: aload_1 //将 Slot[1] 压入栈顶 7 5: invokespecial #3; //Method java/io/File."<init>":(Ljava/lang/String;)V //调用 File 实例的 init(构造器)方法 8 8: areturn //返回栈中结果(File 实例) 9 LineNumberTable: 10 line 16: 0 11 12 LocalVariableTable: 13 Start Length Slot Name Signature 14 0 9 0 this Lclasses/jvm/OperandStack; 15 0 9 1 path Ljava/lang/String;
2.2.3 动态链接
每一个栈帧都包含一个指向运行时常量池中该栈帧所述方法的引用,持有这个引用是为了支持方法调用过程中的动态链接。
Class 文件的常量池中有大量的符号引用,字节码中的方法调用指令就以常量池中指向方法的符号位参数(如 2.2.2 中 File 实例的 init 方法)。这些符号引用一部分会在类加载阶段或者第一次直接使用的时候就转化为直接引用,这种方法为静态解析。另外一部分会在每次运行期间转化为直接引用(使用运行时常量池),这部分称为动态链接。
2.2.4 方法返回地址
当一个方法开始执行后,只有两种方式可以退出这个方法:
第一种是执行引擎遇到任意一个方法返回的指令,这时候可能会有返回值传递给上层的调用者(调用当前方法的方法),是否有返回值和返回值的类型将根据遇到何种方法返回指令来决定(比如 2.2.2 中返回的是 int 和 File 类型,2.2.1.2 中是 无返回类型),这种退出方式称为正常完成出口(Normal Method Invocation Completion)。
第二种是,在方法执行过程中遇到了异常,并且这个异常没有在方法体内得到处理(catch),无论是虚拟机内部产生的异常,还是代码中使用 athrow 字节码指令产生的异常,只要在本方法的异常表种没有搜索到匹配的异常处理器,就会导致方法退出,这种退出方式称为异常完成出口(Abrupt Method Invocation Completion)。
这两种方法退出之后都需要返回到方法被调用的位置,程序才能继续执行,方法返回时可能需要在栈帧保存一些信息,用来帮助恢复它的上层方法的执行状态。当方法正常完成时,调用者的 PC 计数器可以作为返回地址,栈帧种很可能会保存这个计数器值;当方法异常退出时,返回地址是要通过异常处理器表来确定的,栈帧中一般不会保存这部分信息。
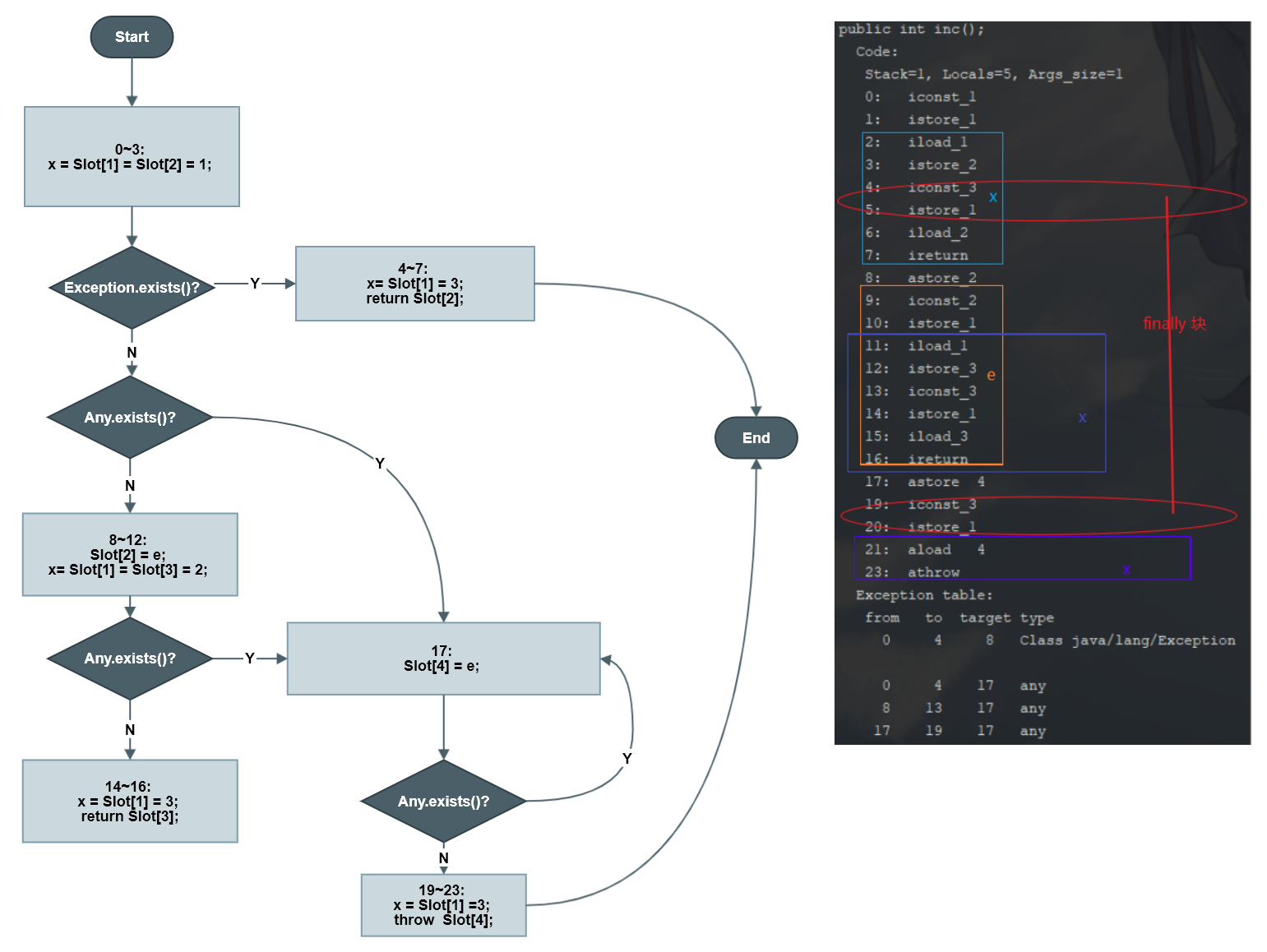
例:AbruptMethod#inc ,当没有异常发生时,返回值是 1;当出现了 Excption异常,返回值是 2;当出现了其他异常,方法非正常退出,没有返回值。无论如何,x在方法返回之前总会被赋值 3。
1 /** 2 * @author pancc 3 * @version 1.0 4 */ 5 public class AbruptMethod { 6 public int inc() { 7 int x; 8 try { 9 x = 1; 10 return x; 11 } catch (Exception e) { 12 x = 2; 13 return x; 14 } finally { 15 x = 3; 16 } 17 } 18 }
编译后的 字节码,局部变量表与异常表
1 public int inc(); 2 Code: 3 Stack=1, Locals=5, Args_size=1 4 0: iconst_1 //将常量 1 入栈 5 1: istore_1 //将栈顶元素出栈并存入 Slot[1],此时 Slot[1] = 1 6 2: iload_1 //将 Slot[1] 入栈 7 3: istore_2 //将栈顶元素出栈并存入 Slot[2],此时 Slot[2] = 1 8 4: iconst_3 //将常量 3 入栈 9 5: istore_1 //将栈顶出栈并存入 Slot[1],此时 Slot[1] = 3 10 6: iload_2 //将 Slot[2] 入栈 11 7: ireturn //返回栈顶元素,即2 12 8: astore_2 //给 catch 语句定义的 Exception e 赋值并存入 Slot[2],此时 Slot[2] = e 13 9: iconst_2 //将常量 2 入栈 14 10: istore_1 //将栈顶元素出栈并存入 Slot[1],此时 Slot[1] = 2 15 11: iload_1 //将 Slot[1] 入栈 16 12: istore_3 //将栈顶元素出栈并存入 Slot[3],此时 Slot[3] = 2 17 13: iconst_3 //将常量 3 入栈 18 14: istore_1 //将栈顶出栈并存入 Slot[1],此时 Slot[1] = 3 19 15: iload_3 //将 Slot[3] 入栈 20 16: ireturn //返回栈顶元素,即 2 21 17: astore 4 //将捕获的非Exception类错误 e 存入 Slot[4],此时 Slot[4] = e 22 19: iconst_3 //将常量 3 入栈 23 20: istore_1 //将栈顶元素出栈并存入 Slot[1],此时 Slot[1] = 3 24 21: aload 4 //将 Slot[4] 入栈 25 23: athrow //抛出异常 e 26 Exception table: 27 from to target type 28 0 4 8 Class java/lang/Exception 29 30 0 4 17 any 31 8 13 17 any 32 17 19 17 any 33 LineNumberTable: 34 line 12: 0 35 line 13: 2 36 line 18: 4 37 line 13: 6 38 line 14: 8 39 line 15: 9 40 line 16: 11 41 line 18: 13 42 line 16: 15 43 line 18: 17 44 45 LocalVariableTable: 46 Start Length Slot Name Signature 47 2 6 1 x I 48 9 8 2 e Ljava/lang/Exception; 49 11 6 1 x I 50 0 24 0 this Lclasses/jvm/AbruptMethod; 51 21 3 1 x I
编译器为这个方法生成了 4 条异常表记录,对应着 4 条可能出现的执行路径:
- 如果 try 语句块中出现了 属于 Exception 及其子类的异常,则转到 catch 语句块处理;
- 如果 try 语句块中出现了不属于 Exception 及其子类的异常,则转到 finally 块语句处理;
- 如果 catch 语句块中出现了任何异常,则转到 finally 语句块处理;
- 如果 finally 语句块中出现了任何异常,则继续捕获并抛出异常(循环);
让我们从字节码层面观察为何会有这样的返回结果:
- 0~3行,将整数 1 赋予Slot[1](x)并且将这个值复制一份保存在 Slot[2] 中。
- 1.1 如果这期间没有发生异常,则会走到 4~7 行,将 Slot[1] 赋值为 3 ,并将 Slot[2] 中的值 1 作整数返回;
- 1.2 如果这期间发生了 Exception 及其子类异常,PC 计数器的指针转到第 8 行,在8 ~13 行将捕获的 e 存入 Slot[2],将 2 赋值给 Slot[1](x) 并且复制到 Slot[3] ;
- 1.2.1 如果这期间没发生任何异常,则会走到 14~16 行将 3 赋值给 Slot[1],并将 Slot[3] 中的值 2 作整数返回;
- 1.2.2 如果这期间发生了任何异常,PC 计数器的指针转到第 17 行,捕获异常存入 Slot[4];
- 1.2.2.1 如果这期间没发生任何异常,则会走到结尾,将3 赋予 Slot[2],抛出 Slot[4] 中的异常;
- 1.2.2.2 如果这期间发生了任何异常,PC 计数器的指针转到第 17 行,重复上层步骤;
- 1.3 如果这期间发生非 Excetion 的任何异常,描述同 1.2.2;
- 1.3.1 如果这期间没发生任何异常,描述同 1.2.2.1;
- 1.3.2 如果如果这期间发生了任何异常,描述同 1.2.2.2;
- 程序结束
2.2.5 附加信息
虚拟机规范允许具体的虚拟机增加一些规范内描述的信息到栈帧中,比如调试信息。一般来说,会把动态链接、方法返回地址、其他附加信息归为一类,称为栈帧信息。
2.3 本地方法栈
与虚拟机栈的作用十分相似,其差异在于虚拟机栈为虚拟机执行 Java 方法,相对的,Java 虚拟机实现可能会使用到传统的栈(通常称之为“C Stacks”)来支持 native 方法 (指使用 Java 以外的其他语言编写的方法)的执行,这个栈就是本地方法栈(Native Method Stack)。
Sun Hot Spot 虚拟机将虚拟机栈与本地方法栈合二为一。
本地方法栈也会抛出 StackOverflowError 和 OutOfMemoryError。
2.4 Java 堆
在 Java 虚拟机中,堆(Heap)是可供各条线程共享的运行时内存区域,也是供所有类实例 和数组对象分配内存的区域。
Java 堆在虚拟机启动的时候就被创建,它存储了被自动内存管理系统(Automatic Storage Management System,也即是常说的“Garbage Collector(垃圾收集器)”)所管理的各种 对象,这些受管理的对象无需,也无法显式地被销毁。
Java 堆的容量可以是固定大小的,也可以随着程序执行的需求动态扩展(指定 -Xmx 与 -Xms),并在不需 要过多空间时自动收缩。Java 堆所使用的内存不需要保证是连续的。
Java 堆会抛出的错误:
OutOfMemoryError:实际所需的堆超过了自动内存管理系统能提供的最大容量,即堆中没有足够的内存完成实例分配并且堆也无法扩展。
2.4.1 直接内存
直接内存并不是运行时数据区的一部分,也并非 Java 虚拟机规范中定义的内存区域。
JDK 自 1.4 开始加入了新的 NIO 类,引入了基于通道与缓冲区的 I/O 方式,它使用 Native 函数库直接分配堆外内存,然后通过使用在 Java 堆中的 DirectByteBuffer 对象作为对这块内存的引用进行操作,避免了在 Java 堆和 Native 堆来回复制数据。与之相对的是 HeapByteBuffer,需要在 Java 堆和 Native 堆来回复制数据。
直接内存会抛出的错误:
OutOfMemoryError:当虚拟机各个内存区域(包括直接内存)的内存总和大于物理内存限制,在动态扩展时出现异常。
2.4.1.1 DirectByteBuffer
DirectByteBuffer 的访问标志是 package 的,我们通过构造其父类的静态方法 ByteBuffer#allocateDirect 获得一个实例
1 public static ByteBuffer allocateDirect(int capacity) { 2 return new DirectByteBuffer(capacity); 3 }
DirectByteBuffer 在底层使用的是 Native 方法,分配的地址在 堆外,即:实例在堆内,实际引用在堆外部的直接内存中
1 DirectByteBuffer(int cap) { // package-private 2 3 super(-1, 0, cap, cap); 4 // 堆内存是否按页分配对齐 5 boolean pa = VM.isDirectMemoryPageAligned(); 6 // 获取每页内存大小 7 int ps = Bits.pageSize(); 8 // 分配内存的大小,如果是按页对齐方式,需要再加一页内存的容量 9 long size = Math.max(1L, (long)cap + (pa ? ps : 0)); 10 // 保存总分配内存的大小和实际内存的大小 11 Bits.reserveMemory(size, cap); 12 13 long base = 0; 14 try { 15 // 指定内存大小获取堆外内存的基址 16 base = unsafe.allocateMemory(size); 17 } catch (OutOfMemoryError x) { 18 // 回滚 19 Bits.unreserveMemory(size, cap); 20 throw x; 21 } 22 unsafe.setMemory(base, size, (byte) 0); 23 // 计算堆外内存的地址 24 if (pa && (base % ps != 0)) { 25 // Round up to page boundary 26 address = base + ps - (base & (ps - 1)); 27 } else { 28 address = base; 29 } 30 cleaner = Cleaner.create(this, new Deallocator(base, size, cap)); 31 att = null; 32 33 }
2.4.1.2 HeapByteBuffer
HeapByteBuffer 的访问标志同样是 package 的,我们通过构造其父类的静态方法 ByteBuffer#allocate 获得一个实例
1 public static ByteBuffer allocate(int capacity) { 2 if (capacity < 0) 3 throw new IllegalArgumentException(); 4 return new HeapByteBuffer(capacity, capacity); 5 }
HeapByteBuffer 与 DirectByteBuffer 不同,实例与分配的空间在 Java 堆中
1 HeapByteBuffer(byte[] buf, int off, int len) { // package-private 2 3 super(-1, off, off + len, buf.length, buf, 0); 4 /* 5 hb = buf; 6 offset = 0; 7 */ 8 }
2.4.1.3 FileChannel
当我们使用 sun.nio.ch.FileChannelImpl#read(java.nio.ByteBuffer) 方法时,会检查传入的 ByteBuffer 是否是 DirectBuffer。
如果是,实际上最终只是调用了本地方法 sun.nio.ch.FileDispatcherImpl#read0
如果不是,需要将ByteBuffer 中维护的 byte[] hb 拷贝到堆外内存,然后调用本地方法 sun.nio.ch.FileDispatcherImpl#read0
其中的差异在于非 DirectBuffer 多了复制这一步。
2.4.1.4 内存的设置
-XX:MaxDirectMemorySize=1m
-XX:MaxDirectMemorySize=1024k
-XX:MaxDirectMemorySize=1048576
2.5 方法区
方法区(Method Area)是可供各条线程共享的运行时内存区域。它存储了每一个类的结构信息,例如运行时常量池(Runtime Constant Pool)、字段和方法数据、构造函数和普通方法的字节码内容、还包 括一些在类、实例、接口初始化时用到的特殊方法。
方法区在虚拟机启动的时候被创建,虽然方法区是堆的逻辑组成部分,但是简单的虚拟机实现可以选择在这个区域不实现垃圾收集。。方法区的容量可以是固定大小的,也可以随着程序执行的需求动态扩展,并在不需要过多空间时自动收缩。方法区在实际内存空间中可以是不连续的。
方法区会抛出的错误:
OutOfMemoryError:如果方法区的内存空间不能满足内存分配请求,那 Java 虚拟机将抛出一个 OutOfMemoryError 异常。
2.5.1 运行时常量池
运行时常量池(Runtime Constant Pool)是每一个类或接口的常量池(Constant_Pool)的运行时表示形式,它包括了若干种不同的常量:从编译期可知的数值字面量到必须运行期解析后才能获得的方法或字段引用。
每一个运行时常量池都分配在 Java 虚拟机的方法区之中,在类和接口被加载到虚拟机后,对应的运行时常量池就被创建出来。
运行时常量池会抛出的错误:
OutOfMemoryError:当创建类或接口的时候,如果构造运行时常量池所需要的内存空间超过了方法区所能提供的最大值,那 Java 虚拟机将会抛出一个 OutOfMemoryError 异常。
2.5.2 运行时常量池与 Class 文件常量池
除了保存 Class 文件中描述的符号引用,虚拟机还会把翻译出来的直接引用也放在运行时常量池中。
运行时常量池还具有常量池不具备的特性--动态性。Java 并不要求常量一定只有编译期才产生,既并非预置如 Class 文件常量池的内容才能进去方法区的运行时常量池,运行期间也可将新的常量放入池中,例: String#intern 。
3 手动触发异常
3.1 Java 堆中的 OutOfMemoryError
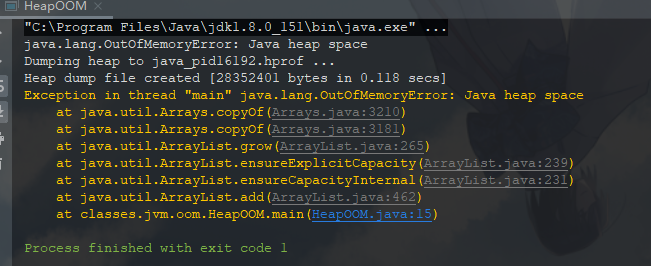
据 2.4 中描述,Java 堆用于存储对象实例,只要不断地创建新对象,并且保持 GC Roots 到对象之间是可达的从而避免 GC ,那么当堆容量不足以创建新的对象时,就会抛出内存溢出异常。
1 package classes.jvm.oom; 2 3 import java.util.ArrayList; 4 import java.util.List; 5 6 /** 7 * 8 * -Xms20m -Xmx20m -XX:+HeapDumpOnOutOfMemoryError 9 * @author pancc 10 */ 11 public class HeapOOM { 12 public static void main(String[] args) { 13 List<HeapOOM> list = new ArrayList<>(); 14 while (true) { 15 list.add(new HeapOOM()); 16 } 17 } 18 }
运行结果:
虚拟机设置:
-Xmssize
Sets the initial size (in bytes) of the heap. This value must be a multiple of 1024 and greater than 1 MB. Append the letter k or K to indicate kilobytes, m or M to indicate megabytes, g or G to indicate gigabytes.The following examples show how to set the size of allocated memory to 6 MB using various units:
-Xms6291456
-Xms6144k
-Xms6m-------------------------------------------------
-Xmxsize
Specifies the maximum size (in bytes) of the memory allocation pool in bytes. This value must be a multiple of 1024 and greater than 2 MB. Append the letter k or K to indicate kilobytes, m or M to indicate megabytes, g or G to indicate gigabytes. The default value is chosen at runtime based on system configuration. For server deployments, -Xms and -Xmx are often set to the same value. See the section "Ergonomics" in Java SE HotSpot Virtual Machine Garbage Collection Tuning Guide at http://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/index.html.The following examples show how to set the maximum allowed size of allocated memory to 80 MB using various units:
-Xmx83886080
-Xmx81920k
-Xmx80m
The -Xmx option is equivalent to -XX:MaxHeapSize.----------------------------------------------
-XX:+HeapDumpOnOutOfMemoryError
Enables the dumping of the Java heap to a file in the current directory by using the heap profiler (HPROF) when a java.lang.OutOfMemoryError exception is thrown. You can explicitly set the heap dump file path and name using the -XX:HeapDumpPath option. By default, this option is disabled and the heap is not dumped when an OutOfMemoryError exception is thrown.---------------------------------------------
-XX:HeapDumpPath=path
Sets the path and file name for writing the heap dump provided by the heap profiler (HPROF) when the -XX:+HeapDumpOnOutOfMemoryError option is set. By default, the file is created in the current working directory, and it is named java_pidpid.hprof where pid is the identifier of the process that caused the error. The following example shows how to set the default file explicitly (%p represents the current process identificator):-XX:HeapDumpPath=./java_pid%p.hprof
The following example shows how to set the heap dump file to C:/log/java/java_heapdump.log:-XX:HeapDumpPath=C:/log/java/java_heapdump.log
3.2 虚拟机栈跟本地方法栈中的 StackOverflowError
据 2.2 中描述:
如果线程请求分配的栈容量超过 Java 虚拟机栈允许的最大容量时,Java 虚拟机将会抛出一 个 StackOverflowError 异常。
如果 Java 虚拟机栈可以动态扩展,并且扩展的动作已经尝试过,但是目前无法申请到足够的内存去完成扩展,或者在建立新的线程时没有足够的内存去创建对应的虚拟机栈,那 Java 虚 拟机将会抛出一个 OutOfMemoryError 异常。
两个错误都是在内存不足的时候发生的,当栈空间无法继续分配时,是已经使用的栈内存太大,还是内存太少,实质上是同一种情况。
1 package classes.jvm.sof; 2 3 /** 4 * -Xss128K 5 * @author pancc 6 * @version 1.0 7 */ 8 public class VMStackSOF { 9 private int stackDepth = 1; 10 // private int shiftDepth = 1; 11 12 private void inc() { 13 stackDepth++; 14 // shiftDepth++; 15 inc(); 16 } 17 18 public static void main(String[] args) { 19 VMStackSOF vmStackSOF = new VMStackSOF(); 20 try { 21 vmStackSOF.inc(); 22 } catch (Throwable e) { 23 System.out.println("vmStackSOF.stackDepth = " + vmStackSOF.stackDepth); 24 // System.out.println("vmStackSOF.shiftDepth = " + vmStackSOF.shiftDepth); 25 throw e; 26 } 27 } 28 29 }
减少 -Xss 参数使用的栈内容容量。结果:抛出 StackOverflowError 异常,并且栈的深度减少;
打开注释,增加该方法帧中本地变量表的长度。结果:抛出 StackOverflowError 异常,并且栈的深度减少;
虚拟机设置:
-Xsssize:
Sets the thread stack size (in bytes). Append the letter k or K to indicate KB, m or M to indicate MB, g or G to indicate GB. The default value depends on virtual memory.
The following examples set the thread stack size to 1024 KB in different units:
-Xss1m
-Xss1024k
-Xss1048576
This option is equivalent to -XX:ThreadStackSize.
Appendix:
reference:一个对象实例的引用;虚拟机规范并未对其结构与长度作规定,只是要求虚拟机通过这个引用可以做到:1、从此引用中直接或者间接地查找到对象在 Java 堆中的数据存放到起始地址索引;2、此引用中直接或间接地查找到对象所属数据类型在方法区中存储的类型信息。↩
returnAddress:指向一条字节码指令的地址,为字节码指令 jsr、jsr_w、ret 服务(见Java虚拟机指令-控制转移指令-无条件分支);曾被古老的 Java虚拟机作异常处理,现已被异常表(exception_table)代替↩

 浙公网安备 33010602011771号
浙公网安备 33010602011771号