从网页中通过正则表达式获取标题、URL和发表时间
为了从几个网站抽取内容,聚合到一起。我于2012年写了一个程序,从多个网站通过结构化方法抽取内容。然后写入数据库,形成一个网站。
(1)正则表达式抽取
首先,从数据库中读取内容抽取规则:
ArrayList<RuleBean> rbList = ruleDao.QueryAllRule();
抽取规则的表结构如下:
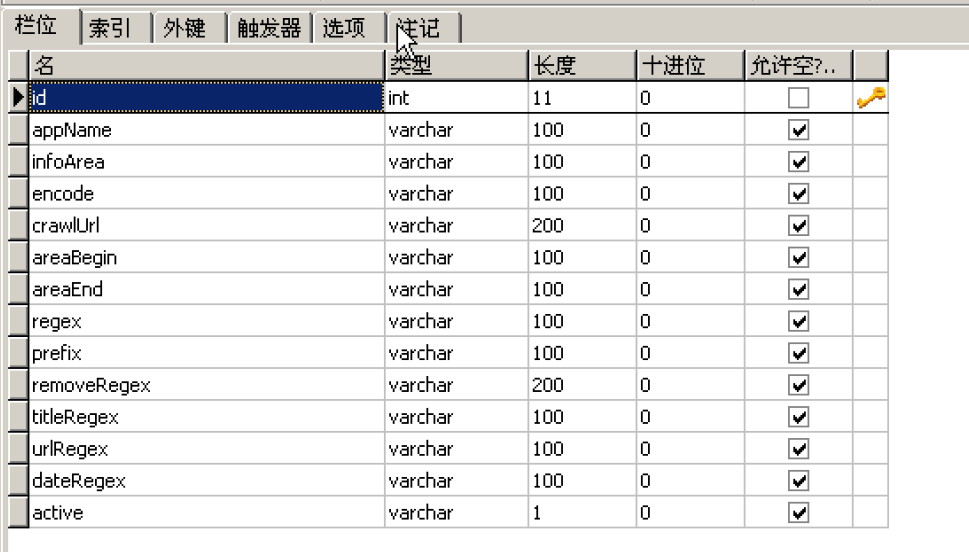
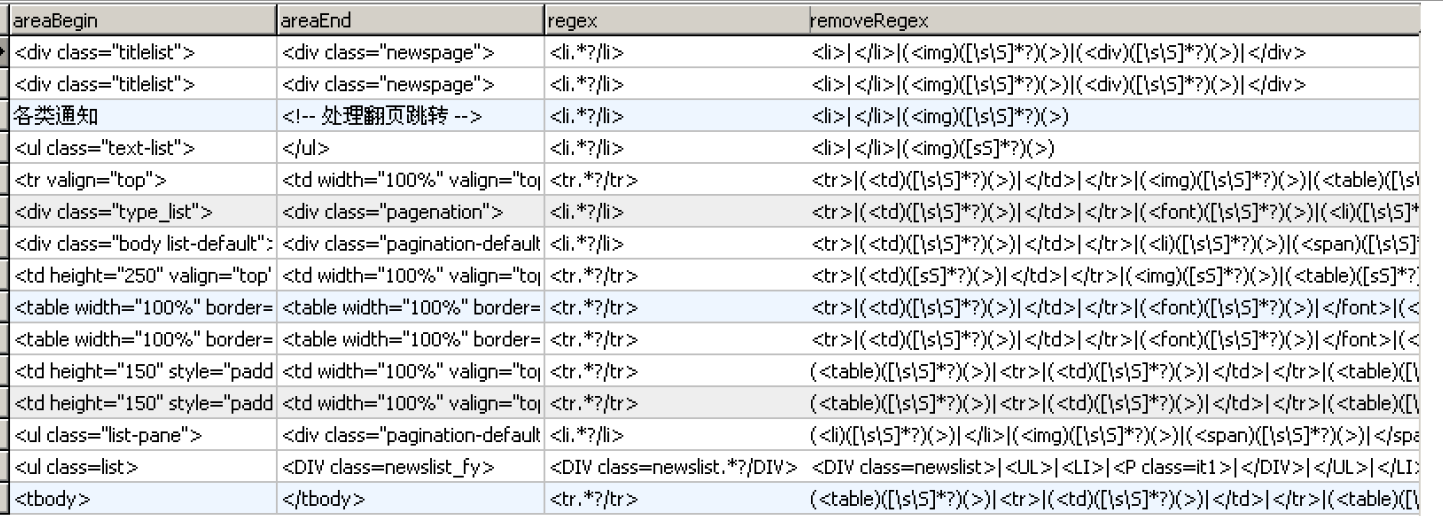
配置的抽取规则如下:
其次,读取网页内容,并通过起始标签抽取出内容,然后通过正则表达式读取出网址URL、标题和发表时间。
直接上代码如下:


1 private static void doCrawl(RuleBean rb) { 2 String urlContent = getUrlContent(rb.getCrawlUrl(),rb.getEncode()); 3 if("error".equalsIgnoreCase(urlContent)){ 4 return; 5 } 6 String contentArea = getContentArea(urlContent, rb.getAreaBegin(), 7 rb.getAreaEnd()); 8 9 Pattern pt = Pattern.compile(rb.getRegex()); 10 Matcher mt = pt.matcher(contentArea); 11 12 TitleAndUrlBean tuBean; 13 while (mt.find()) { 14 tuBean = new TitleAndUrlBean(); 15 tuBean.setAppName(rb.getAppName()); 16 tuBean.setInfoArea(rb.getInfoArea()); 17 18 String rowContent = mt.group(); 19 rowContent = rowContent.replaceAll(rb.getRemoveRegex(), ""); 20 21 // 获取标题 22 Matcher title = Pattern.compile(rb.getTitleRegex()).matcher( 23 rowContent); 24 while (title.find()) { 25 String s = title.group().replaceAll("<u>|</u>|>|</a>|\\[.*?\\]|</l>",""); 26 if(s ==null || s.trim().length()<=0){ 27 s = "error"; 28 } 29 tuBean.setTitle(s); 30 31 } 32 33 // 获取网址 34 Matcher myurl = Pattern.compile(rb.getUrlRegex()).matcher( 35 rowContent); 36 while (myurl.find()) { 37 String u = myurl.group().replaceAll( 38 "href=|\"|>|target=|_blank|title", ""); 39 u = u.replaceAll("\'|\\\\", ""); 40 41 if(u!=null && (u.indexOf("http://")==-1)){ 42 tuBean.setUrl(rb.getPrefix() + u); 43 }else{ 44 tuBean.setUrl(u); 45 } 46 } 47 if(tuBean.getUrl() ==null){ 48 tuBean.setUrl("error"); 49 } 50 51 // 获取时间 52 Matcher d = Pattern.compile(rb.getDateRegex()).matcher(rowContent); 53 while (d.find()) { 54 tuBean.setDeliveryDate(d.group()); 55 } 56 57 boolean r = TitleAndUrlDAO.Add(tuBean); 58 59 if (r){ 60 log.info("crawl add " + tuBean.getAppName() + "_" 61 + tuBean.getInfoArea()+"_"+tuBean.getTitle()); 62 63 if(tuBean.getAppName().contains("jww")){ 64 Cache cTeach = CacheManager.getCacheInfo("index_teach"); 65 if(cTeach!=null){ 66 teachList = (List<TitleAndUrlBean>) cTeach.getValue(); 67 } 68 69 teachList.add(tuBean); 70 if(teachList.size()>5){ 71 teachList.remove(0); 72 } 73 cTeach.setValue(teachList); 74 cTeach.setTimeOut(-1); 75 CacheManager.putCache("index_teach", cTeach); 76 } 77 } 78 } 79 System.out.println("end crawl "+rb.getCrawlUrl()); 80 }
(2) dwr返回内容的抽取
在当时dwr是比较流行的技术,为了抽取dwr的内容,着实花了一番功夫。
首先通过httpClient获取内容
1 public static void startCrawl() throws Exception{ 2 System.out.println("begin crawl xb"); 3 DefaultHttpClient httpclient = new DefaultHttpClient(); 4 HttpResponse response = null; 5 HttpEntity entity = null; 6 httpclient.getParams().setParameter(ClientPNames.COOKIE_POLICY, 7 CookiePolicy.BROWSER_COMPATIBILITY); 8 HttpPost httpost = new HttpPost( 9 "http://xxxxxx/Tzgg.getMhggllList.dwr"); 10 11 //公告公示 nvps.add(new BasicNameValuePair("c0-e3", "string:03")); 12 13 List<NameValuePair> nvps = new ArrayList<NameValuePair>(); 14 15 16 nvps.add(new BasicNameValuePair("callCount", "1")); 17 nvps.add(new BasicNameValuePair("page", "/tzggbmh.do")); 18 nvps.add(new BasicNameValuePair("c0-scriptName", "Tzgg")); 19 nvps.add(new BasicNameValuePair("c0-methodName", "getMhggllList")); 20 nvps.add(new BasicNameValuePair("c0-id", "0")); 21 nvps.add(new BasicNameValuePair("c0-e1", "string:0")); 22 nvps.add(new BasicNameValuePair("c0-e2", "string:0")); 23 24 nvps.add(new BasicNameValuePair("c0-e4", "string:%20%20")); 25 nvps.add(new BasicNameValuePair("c0-e5", "string:rsTable")); 26 nvps.add(new BasicNameValuePair( 27 "c0-param0", 28 "Array:[reference:c0-e1,reference:c0-e2,reference:c0-e3,reference:c0-e4,reference:c0-e5]")); 29 nvps.add(new BasicNameValuePair("c0-e6", "number:20")); 30 nvps.add(new BasicNameValuePair("c0-e7", "number:1")); 31 nvps.add(new BasicNameValuePair("c0-param1", 32 "Object_Object:{pageSize:reference:c0-e6, currentPage:reference:c0-e7}")); 33 nvps.add(new BasicNameValuePair("batchId", "0")); 34 35 int infoArea = 1; 36 while(infoArea <4){ 37 nvps.add(new BasicNameValuePair("c0-e3", "string:0"+infoArea)); 38 39 httpost.setEntity(new UrlEncodedFormEntity(nvps)); 40 41 response = httpclient.execute(httpost); 42 entity = response.getEntity(); 43 try { 44 String responseString = null; 45 if (response.getEntity() != null) { 46 responseString = EntityUtils.toString(response.getEntity()); 47 if(1 == infoArea){ 48 extractData(responseString,"事务通知"); 49 infoArea = 3; 50 } 51 52 } 53 } finally { 54 55 } 56 57 58 59 } 60 61 System.out.println("end crawl xb"); 62 httpclient.getConnectionManager().shutdown(); 63 }
然后通过正则表达式抽取
1 private static void extractData(String content,String infoArea) throws Exception{ 2 TitleAndUrlDAO tuDao = new TitleAndUrlDAO(); 3 TitleAndUrlBean tuBean; 4 5 Pattern pt = Pattern.compile("llcs.*?a>"); 6 Matcher mt = pt.matcher(content); 7 8 Cache c = new Cache(); 9 while (mt.find()) { 10 tuBean = new TitleAndUrlBean(); 11 tuBean.setAppName("info_xb"); 12 tuBean.setInfoArea(infoArea); 13 14 String s2 = mt.group(); 15 16 // 获取标题 17 Matcher title = Pattern.compile("title.*?>").matcher(s2); 18 while (title.find()) { 19 String s = title.group().replaceAll("title=|>", ""); 20 21 tuBean.setTitle(unicodeToString(s)); 22 } 23 24 // 获取网址 25 Matcher myurl = Pattern.compile("ID=.*?;").matcher(s2); 26 while (myurl.find()) { 27 String prefix = "http://XXXX/tzggbmh.do?theAction=view¶meter.id="; 28 // System.out.println("网址:" + prefix 29 // + myurl.group().replaceAll("ID=|;|\"", "")); 30 31 tuBean.setUrl(prefix + myurl.group().replaceAll("ID=|;|\"", "")); 32 } 33 34 // 获取时间 35 Matcher d = Pattern.compile("[0-9]{4}-[0-9]{2}-[0-9]{1,2}") 36 .matcher(s2); 37 while (d.find()) { 38 tuBean.setDeliveryDate(d.group()); 39 } 40 41 boolean r = tuDao.Add(tuBean); 42 43 if (r){ 44 log.info("crawl add " + tuBean.getAppName() + "_" 45 + tuBean.getInfoArea()+"_"+tuBean.getTitle()); 46 47 Cache cNotice = CacheManager.getCacheInfo("index_notice"); 48 if(cNotice!=null){ 49 xb_noticeList = (List<TitleAndUrlBean>) cNotice.getValue(); 50 } 51 52 xb_noticeList.add(tuBean); 53 if(xb_noticeList.size()>5){ 54 xb_noticeList.remove(0); 55 } 56 57 c.setValue(xb_noticeList); 58 c.setTimeOut(-1); 59 CacheManager.putCache("index_notice", c); 60 } 61 } 62 }
本文使用的抽取方法代码,写于2012年,每次网站结构变化的时候需要重新配置规则。
不知道这么多年过来,是否有智能的方法获取网站这种半结构化数据。
如果有,请留言告知,谢谢!
所有文章,坚持原创。如有转载,敬请标注出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号