
深度解读AI在数字档案馆中的创新应用:高效识别与智能档案管理
一、项目背景介绍
在信息化浪潮推动下,基于OCR技术的纸质档案电子化方案成为解决档案管理难题的有效途径。该方案通过先进的OCR技术,能够统一采集各类档案数据,无论是手写文件、打印文件、复古文档还是照片或扫描的历史资料,都能实现高效识别。利用文档智能分析技术,我们对电子化后的档案进行规范化归档,结合档案管理模块,实现对档案的分类、编目和元数据提取,从而提高档案检索的效率和准确性。思通数科的AI能力平台在此过程中发挥了关键作用,它支持多种格式的批量识别,智能纠错与校对,确保档案内容的准确性,同时注重数据安全与隐私保护,为档案馆提供了一个全面、高效的电子化管理解决方案。
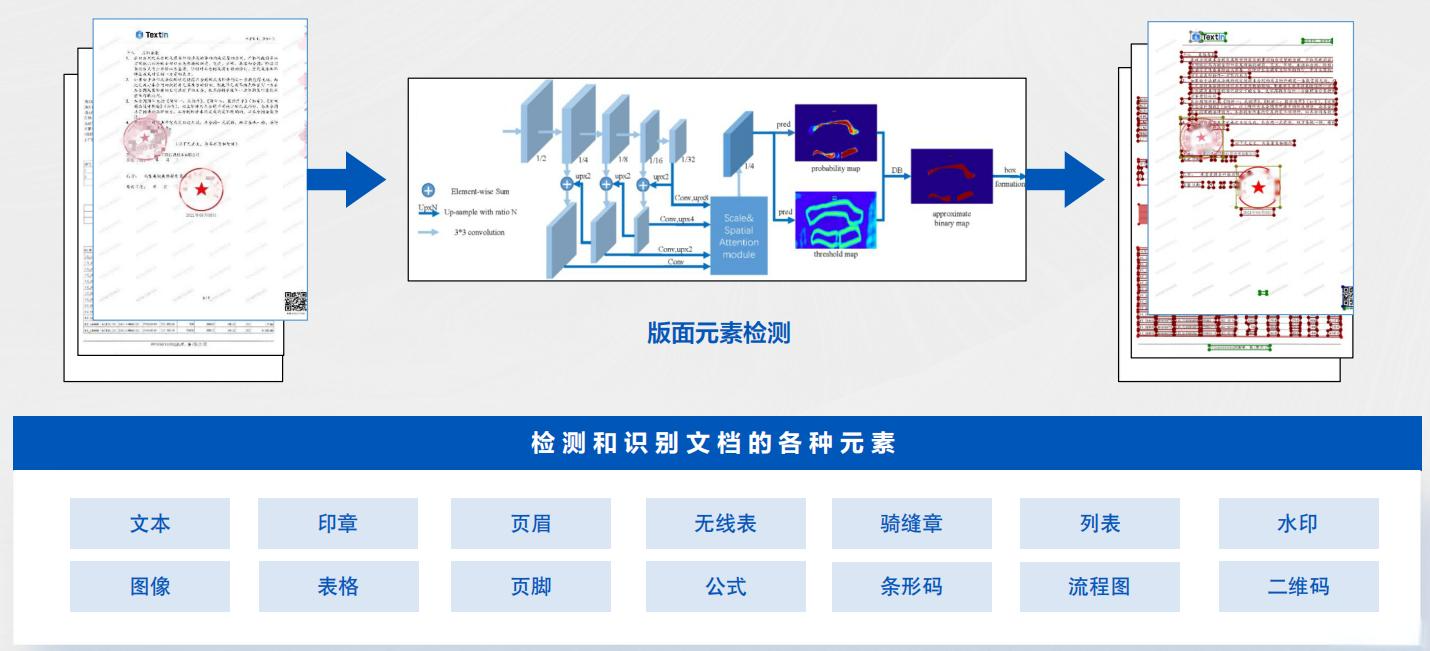
这一方案的实施,不仅极大提升了档案管理的工作效率,降低了录入难度,还使得档案馆能够更好地服务于公众,提供便捷的查询服务。通过电子化处理,档案资源得到了更好的保存和利用,避免了因时间流逝导致的档案损坏和丢失,为保护历史资料、传承文化遗产提供了有力保障。同时,统一的解决方案也为档案馆带来了长远的发展前景,使得档案管理工作更加规范化、智能化,适应了现代信息社会的需求。思通数科的AI能力平台利用先进的算法支持多种格式的批量识别,
为档案馆提供了一个统一的解决方案:
二、技术方案介绍
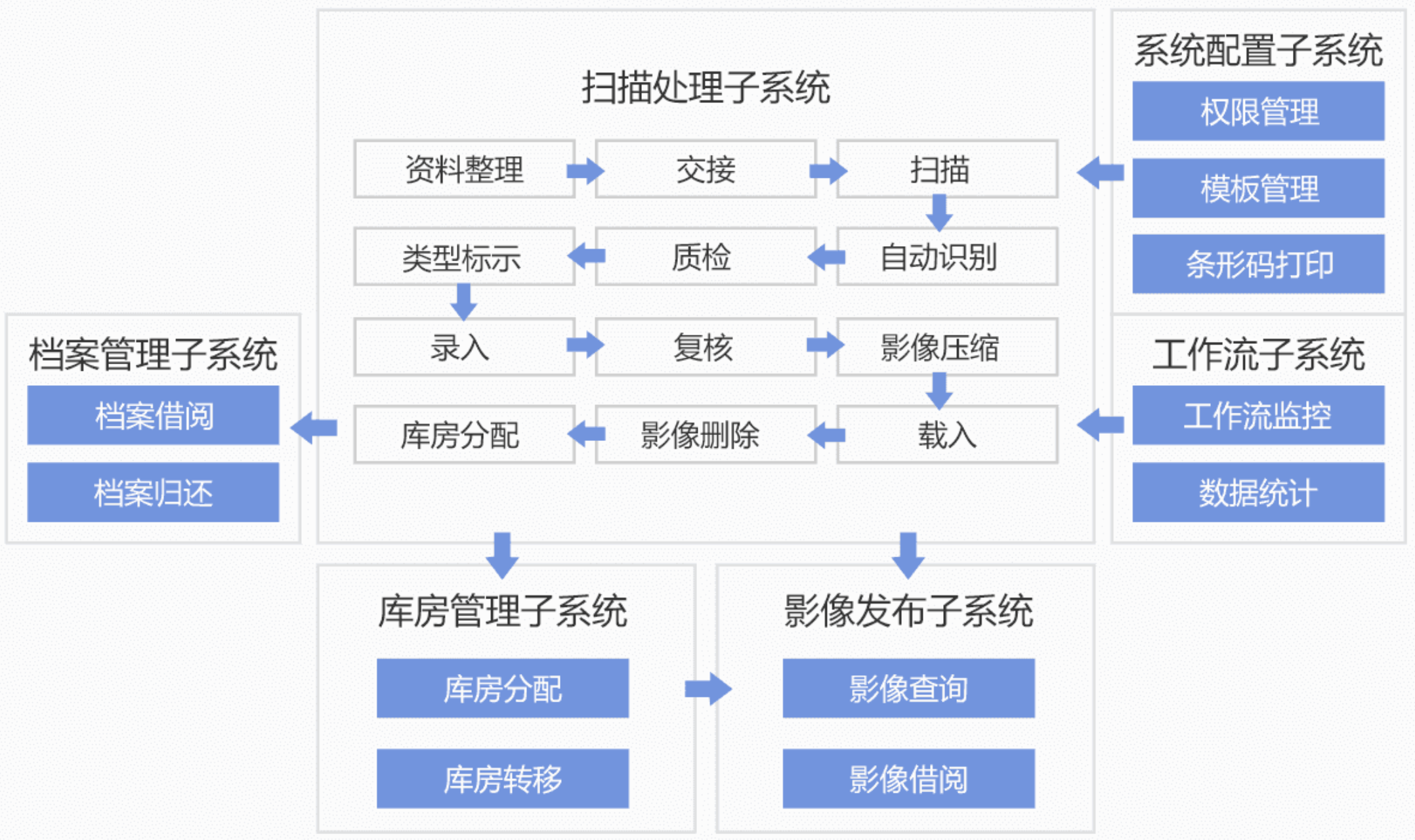
多种档案的特征训练
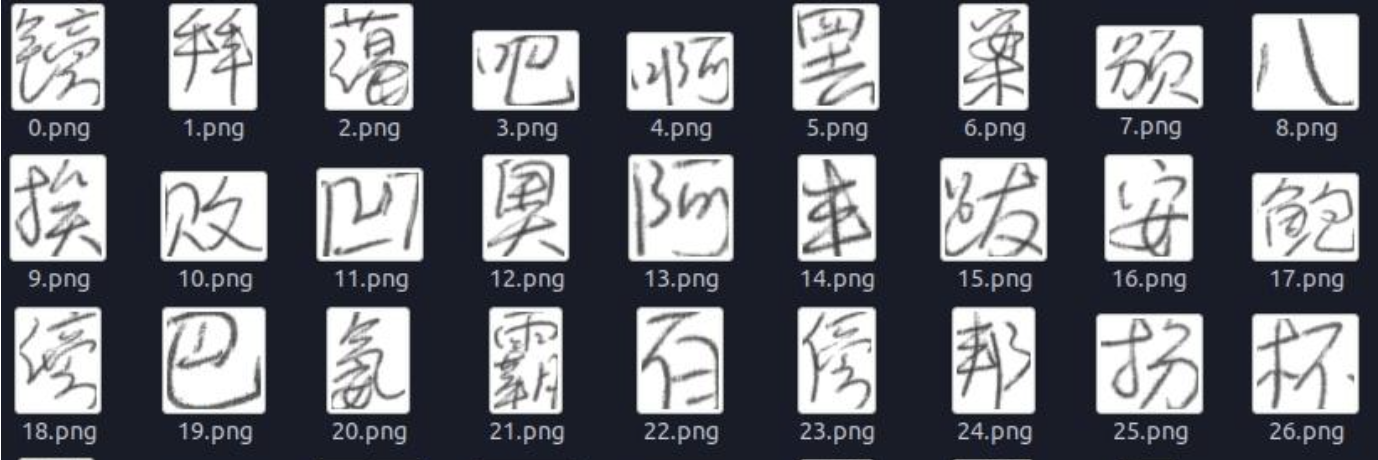
AI平台的OCR识别算法通过大量的手写字体、复古字体、打印字体样本训练,从而具备识别各种复杂文档的能力。对于手写文件,系统会通过深度学习训练不同书写风格的样本,使得识别模型能在手写识别中实现较高的准确度。对于复古字体或古籍档案,则采用自适应字体识别技术,识别出历史文献中常见的字体样式。

看到这么密密麻麻的文字相信连人类都.... 开始头疼了,这些复杂的文字能够通过思通数据的AI能力平台来识别出来??答案是肯定的....
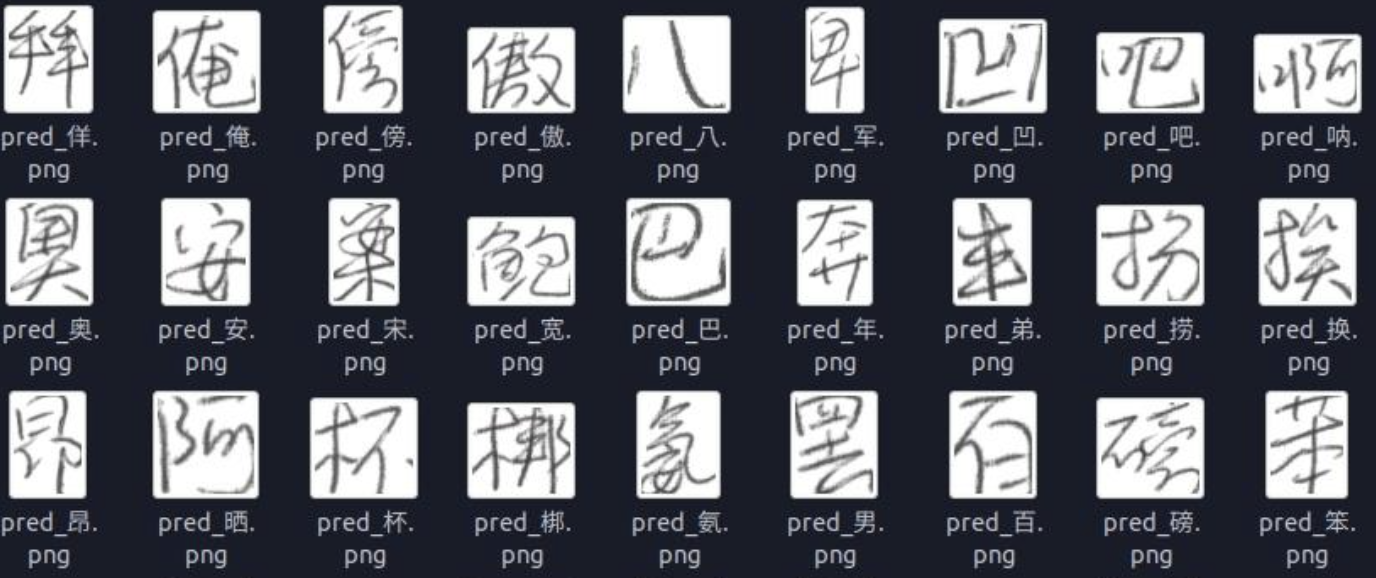
上面的部分文字识别出来的结果是这样的:

自动格式识别与适配
系统可以先识别文档的格式类型(手写、打印、复古图片等),再选择最适合的OCR模型进行处理。针对不同类型的文件,平台会采用不同的OCR模型,以达到更高的识别精度。
例如,对复古文档可以先进行图像增强处理,对照片类文件则会过滤掉多余的背景噪声,从而有效提升识别准确度。
批量处理与并行任务
档案馆中存储的历史文件可能成千上万,思通数科AI平台可以利用批量处理功能,设定并行化任务队列,对这些文档分批次地进行自动识别和转化。批量处理支持同时识别多个文件类型,可以自动根据文档类型分发到不同的OCR模型中处理,从而提高识别效率。此外,通过并行计算,可以在短时间内处理完大量文档,极大地节省人力和时间成本。
格式兼容与数据导出
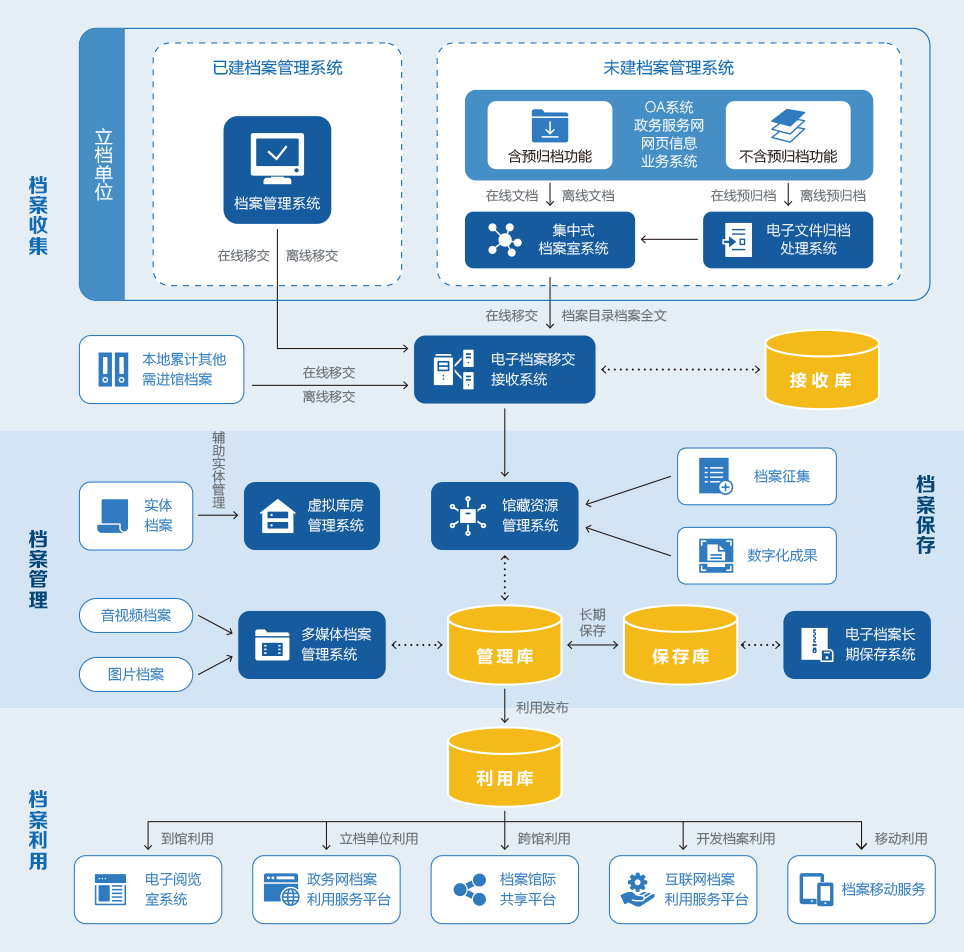
在档案管理中各个子系统协同工作,扫描处理子系统则承担着将实体档案转化为数字格式的重任,它负责资料的整理、交接、扫描,并通过自动识别和质检技术确保影像的准确性和清晰度。影像压缩、载入和删除功能进一步优化了存储和检索过程。
在数据导出方面,处理后的文本信息可以导出为多种格式,如PDF、TXT、DOC、XML等,便于不同用户需求的调用。例如,对于需要进行文本分析的部门,可以选择结构化数据导出(如XML或CSV),便于后续统计分析;而对于需要阅读的用户,则可以选择可视化效果更好的PDF格式输出。
多语种与跨文档识别
许多档案馆中不仅包含中文档案,还有其他语种的文献资料,AI平台支持多语种OCR识别,自动识别并处理中文、英文、法文、日文等多种语言。识别结果会根据文档的语种属性自动分配存储,并按语言分类,从而便于档案馆的跨文化文档管理。

三、产品体验与联系我们
思通数科AI多模态能力平台,产品体验地址:https://nlp.stonedt.com/
我们致力于为档案管理领域提供最先进的数字化解决方案,欢迎档案管理专家与资深人士与我们探讨交流。欢迎添加产品经理微信


